



taro_rich_text 是Taro小程序框架下使用的跨端的Markdown解析组件,目前测试在微信小程序端和H5端的Markdown解析的正常的
-
如果需要在微信小程序端使用wxParse解析HTML,则需要在开发者中心添加wxParse插件,添加方式参考wxParse-plugin
-
本组件提供了不包含wxParse插件的版本,则可引用
TaroRichTextNoWxParse组件,使用方式和参数同TaroRichText此时会默认使用RichText来解析HTML富文本import { TaroRichTextNoWxParse } from 'taro_rich_text';
-
在
Taro 1.3.0-beta.5之前包括1.3.0-beta.5的版本,在解析函数式组件的分支逻辑的时候存在bug,所以taro_rich_text 1.0.4包括1.0.4之前的版本对此做了特殊处理,所以- Taro版本 > 1.3.0-beta.5 则对应使用 taro_rich_text > 1.0.4
- Taro版本 <= 1.3.0-beta.5 则对应使用 taro_rich_text <= 1.0.4
- 如果想在
Taro 1.3.0-beta.5之前的版本使用 > 1.0.4 版本的本组件,参考该commit进行修改
-
首先用npm安装
npm install --save taro_rich_text
-
引入组件库
import { TaroRichText } from 'taro_rich_text'; -
在项目配置文件
config/index.js中添加如下配置h5: { esnextModules: ['taro_rich_text'] }
该配置的作用是,在H5端使用本库的时候,对应的单位会进行转换(
px=>rem) -
在代码中使用
<TaroRichText raw={false} type='markdown' richText={richText} />
| 参数名 | 参数类型 | 参数说明 |
|---|---|---|
| richText | string | 富文本(Markdown文本) |
| raw | boolean | 是否显示无格式文本(如果为true,则组件显示的内容会只包含文字,不包含格式,一般用于显示Markdown富文本的简介) |
| rawMaxLength | number | raw为true时本参数有效,表示最多显示多少个文字,超出部分显示成省略号(...) |
| type | 'markdown' | 'html' | 富文本类型,Markdown支持跨端,目前html主要是针对微信小程序端,使用微信小程插件wxParse来实现 |
| omImageClick | (image: XbRichTextImageClickCallbackData) => void | Markdown中图片被点击的回调 |
| onLinkClick | (src: string) => void | Markdown中链接被点击的回调 |

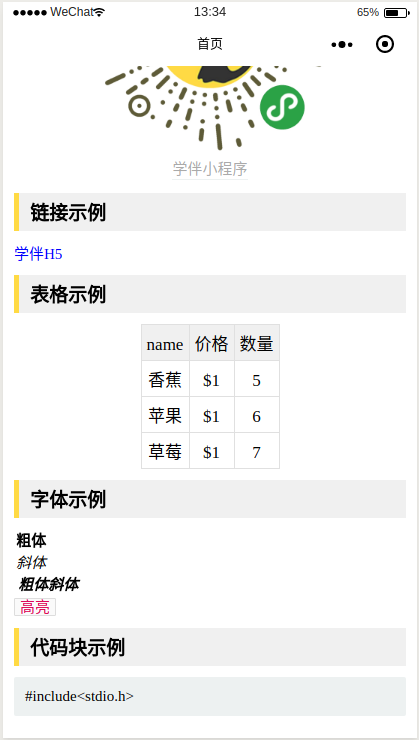
如果用起来觉得不错,那就,“打发点咯”
