
👉 T2I-Adapter for [SD-1.4/1.5], for [SDXL]


Official implementation of T2I-Adapter: Learning Adapters to Dig out More Controllable Ability for Text-to-Image Diffusion Models based on Stable Diffusion-XL.
The diffusers team and the T2I-Adapter authors have been collaborating to bring the support of T2I-Adapters for Stable Diffusion XL (SDXL) in diffusers! It achieves impressive results in both performance and efficiency.

-
✅ Sep. 8, 2023. We collaborate with the diffusers team to bring the support of T2I-Adapters for Stable Diffusion XL (SDXL) in diffusers! It achieves impressive results in both performance and efficiency. We release T2I-Adapter-SDXL models for sketch, canny, lineart, openpose, depth-zoe, and depth-mid. We release two online demos:
and
.
-
✅ Aug. 21, 2023. We release T2I-Adapter-SDXL, including sketch, canny, and keypoint. We still use the original recipe (77M parameters, a single inference) to drive StableDiffusion-XL. Due to the limited computing resources, those adapters still need further improvement. We are collaborating with HuggingFace, and a more powerful adapter is in the works.
-
✅ Jul. 13, 2023. Stability AI release Stable Doodle, a groundbreaking sketch-to-image tool based on T2I-Adapter and SDXL. It makes drawing easier.
-
✅ Mar. 16, 2023. We add CoAdapter (Composable Adapter). The online Huggingface Gadio has been updated
-
✅ Mar. 16, 2023. We have shrunk the git repo with bfg. If you encounter any issues when pulling or pushing, you can try re-cloning the repository. Sorry for the inconvenience.
-
✅ Mar. 3, 2023. Add a color adapter (spatial palette), which has only 17M parameters.
-
✅ Mar. 3, 2023. Add four new adapters style, color, openpose and canny. See more info in the Adapter Zoo.
-
✅ Feb. 23, 2023. Add the depth adapter t2iadapter_depth_sd14v1.pth. See more info in the Adapter Zoo.
-
✅ Feb. 15, 2023. Release T2I-Adapter.

| SD-V1.4/1.5 | SD-XL | T2I-Adapter | T2I-Adapter-SDXL | |
|---|---|---|---|---|
| Parameters | 860M | 2.6B | 77 M | 77/79 M |
- Lineart-guided
Model from TencentARC/t2i-adapter-lineart-sdxl-1.0

- Keypoint-guided
Model from openpose_sdxl_1.0

- Sketch-guided
Model from TencentARC/t2i-adapter-sketch-sdxl-1.0

- Canny-guided Model from TencentARC/t2i-adapter-canny-sdxl-1.0

- Depth-guided
Depth guided models from TencentARC/t2i-adapter-depth-midas-sdxl-1.0 and TencentARC/t2i-adapter-depth-zoe-sdxl-1.0 respectively

- Python >= 3.8 (Recommend to use Anaconda or Miniconda)
- PyTorch >= 2.0.1
pip install -r requirements.txtAll models will be automatically downloaded. You can also choose to download manually from this url.
Here we take sketch guidance as an example, but of course, you can also prepare your own dataset following this method.
accelerate launch train_sketch.py --pretrained_model_name_or_path stabilityai/stable-diffusion-xl-base-1.0 --output_dir experiments/adapter_sketch_xl --config configs/train/Adapter-XL-sketch.yaml --mixed_precision="fp16" --resolution=1024 --learning_rate=1e-5 --max_train_steps=60000 --train_batch_size=1 --gradient_accumulation_steps=4 --report_to="wandb" --seed=42 --num_train_epochs 100We train with FP16 data precision on 4 NVIDIA A100 GPUs.
Inference requires at least 15GB of GPU memory.
Quick start with diffusers
To get started, first install the required dependencies:
pip install git+https://github.com/huggingface/diffusers.git@t2iadapterxl # for now
pip install -U controlnet_aux==0.0.7 # for conditioning models and detectors
pip install transformers accelerate safetensors- Images are first downloaded into the appropriate control image format.
- The control image and prompt are passed to the
StableDiffusionXLAdapterPipeline.
Let's have a look at a simple example using the LineArt Adapter.
- Dependency
from diffusers import StableDiffusionXLAdapterPipeline, T2IAdapter, EulerAncestralDiscreteScheduler, AutoencoderKL
from diffusers.utils import load_image, make_image_grid
from controlnet_aux.lineart import LineartDetector
import torch
# load adapter
adapter = T2IAdapter.from_pretrained(
"TencentARC/t2i-adapter-lineart-sdxl-1.0", torch_dtype=torch.float16, varient="fp16"
).to("cuda")
# load euler_a scheduler
model_id = 'stabilityai/stable-diffusion-xl-base-1.0'
euler_a = EulerAncestralDiscreteScheduler.from_pretrained(model_id, subfolder="scheduler")
vae=AutoencoderKL.from_pretrained("madebyollin/sdxl-vae-fp16-fix", torch_dtype=torch.float16)
pipe = StableDiffusionXLAdapterPipeline.from_pretrained(
model_id, vae=vae, adapter=adapter, scheduler=euler_a, torch_dtype=torch.float16, variant="fp16",
).to("cuda")
pipe.enable_xformers_memory_efficient_attention()
line_detector = LineartDetector.from_pretrained("lllyasviel/Annotators").to("cuda")- Condition Image
url = "https://huggingface.co/Adapter/t2iadapter/resolve/main/figs_SDXLV1.0/org_lin.jpg"
image = load_image(url)
image = line_detector(
image, detect_resolution=384, image_resolution=1024
)
- Generation
prompt = "Ice dragon roar, 4k photo"
negative_prompt = "anime, cartoon, graphic, text, painting, crayon, graphite, abstract, glitch, deformed, mutated, ugly, disfigured"
gen_images = pipe(
prompt=prompt,
negative_prompt=negative_prompt,
image=image,
num_inference_steps=30,
adapter_conditioning_scale=0.8,
guidance_scale=7.5,
).images[0]
gen_images.save('out_lin.png')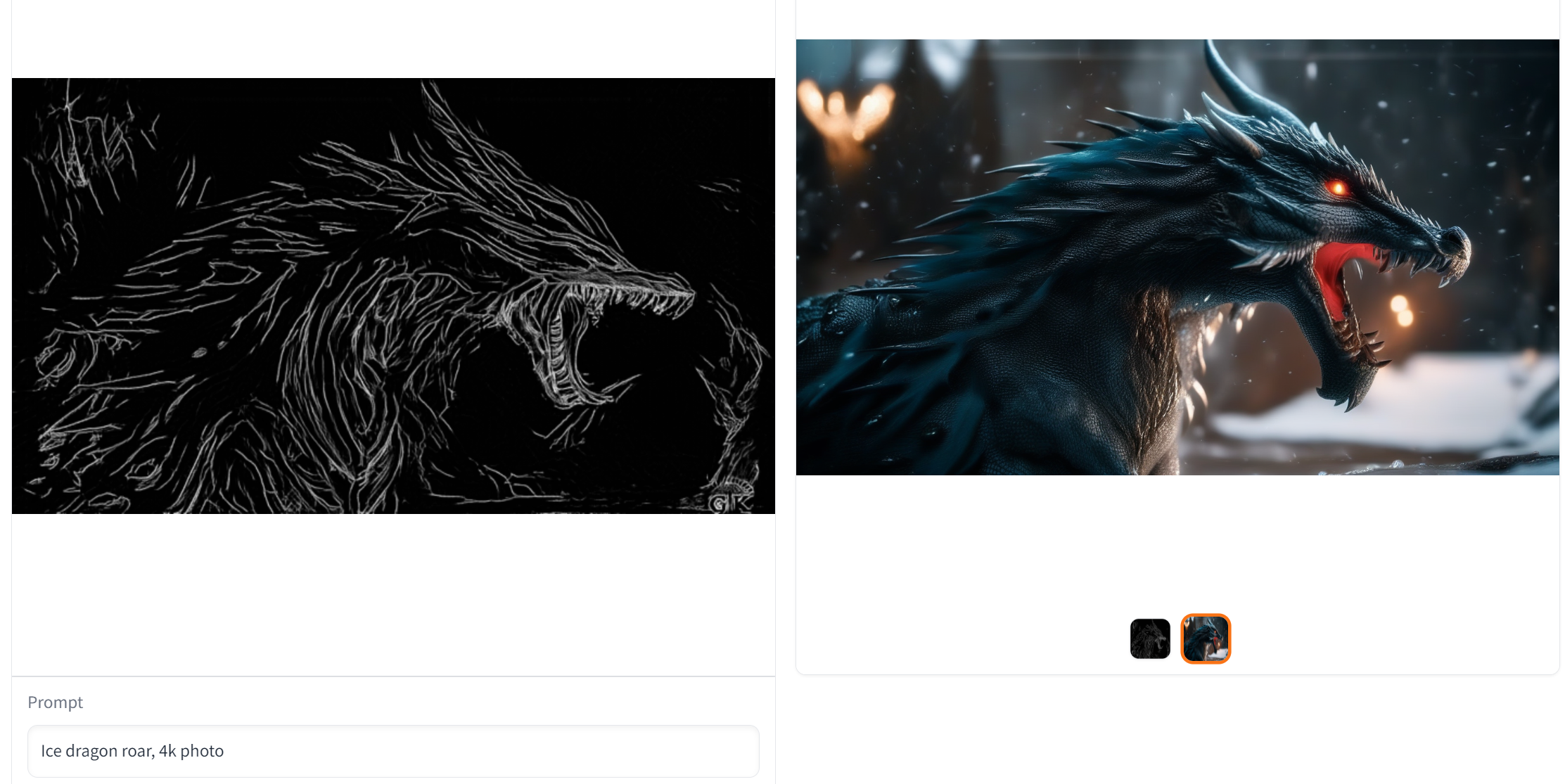

- Sketch: https://huggingface.co/TencentARC/t2i-adapter-sketch-sdxl-1.0
- Canny: https://huggingface.co/TencentARC/t2i-adapter-canny-sdxl-1.0
- Lineart: https://huggingface.co/TencentARC/t2i-adapter-lineart-sdxl-1.0
- Openpose: https://huggingface.co/TencentARC/t2i-adapter-openpose-sdxl-1.0
- Depth-mid: https://huggingface.co/TencentARC/t2i-adapter-depth-midas-sdxl-1.0
- Depth-zoe: https://huggingface.co/TencentARC/t2i-adapter-depth-zoe-sdxl-1.0
...
Jul. 13, 2023. Stability AI release Stable Doodle, a groundbreaking sketch-to-image tool based on T2I-Adapter and SDXL. It makes drawing easier.
doodle.mp4
- Thanks to HuggingFace for their support of T2I-Adapter.
- T2I-Adapter is co-hosted by Tencent ARC Lab and Peking University VILLA.
@article{mou2023t2i,
title={T2i-adapter: Learning adapters to dig out more controllable ability for text-to-image diffusion models},
author={Mou, Chong and Wang, Xintao and Xie, Liangbin and Wu, Yanze and Zhang, Jian and Qi, Zhongang and Shan, Ying and Qie, Xiaohu},
journal={arXiv preprint arXiv:2302.08453},
year={2023}
}