The StackOnlyJsonParser combines the System.Text.Json library with C# 9 code generators to allow for fast and GC-friendly JSON deserialization.
It's intended mostly for the low latency and real time systems that have to deal with big data flows under a requirement of a small memory footprint.
A short write up of the project can be found on my blog.
This library depends on the C# 9 code generators available with the .NET 5.0.
<PropertyGroup>
...
<TargetFramework>net5.0</TargetFramework>
...
</PropertyGroup>
To install the package in your project simply use the following command:
dotnet add package StackOnlyJsonParser
The StackOnlyJsonParser will not cooperate with just any class. In fact it requires you to define each entity as a readonly ref partial struct (that's a mouthful). Only this way it can ensure that the deserialization process can be performed without unnecessary allocations.
This requirement implies that deserialized objects cannot be persisted and have to be "consumed" immediately (either by copying their state to a pre-allocated memory or by performing the data processing in place). This limitation should be the main factor when deciding if the StackOnlyJsonParser is a good fit for your project.
Each entity you want to be able to deserialize has to be marked with the [StackOnlyJsonType] attribute.
[StackOnlyJsonType]
internal readonly ref partial struct Product
{
public int Id { get; }
public string Name { get; }
public double Price { get; }
}The code generator will automatically create a corresponding partial struct that contains constructors used for the data deserialization:
public Product(ReadOnlySpan<byte> jsonData);
public Product(ReadOnlySequence<byte> jsonData);
public Product(ref System.Text.Json.Utf8JsonReader jsonReader);It's important to note that the StackOnlyJsonParser only supports Utf8-encoded data sources.
With that code being auto-generated for us, we can deserialize new object in the following way:
ReadOnlySpan<byte> data = ...
var product = new Product(data);By default, when deserializing the data, the StackOnlyJsonParser will only look for an exact match between the JSON field name and the model property name (case sensitive). If no match is found, the StackOnlyJsonParser will skip the field during the deserialization process.
To specify custom JSON field names one can use the [StackOnlyJsonField] attribute:
[StackOnlyJsonType]
internal readonly ref partial struct Product
{
[StackOnlyJsonField("product-name", "productName", "ProductName")]
public string ProductName { get; }
...
}Entities can hold not only fields of standard types, but also fields of custom types:
[StackOnlyJsonType]
internal readonly ref partial struct Price
{
public decimal Value { get; }
public string Currency { get; }
}
[StackOnlyJsonType]
internal readonly ref partial struct Product
{
public int Id { get; }
public string Name { get; }
public Price Price { get; }
}It's not required for the type of a nested message to use the [StackOnlyJsonType] attribute. The only requirement is for that type to define a constructor that accepts a single ref System.Text.Json.Utf8JsonReader parameter.
It's even possible to combine the StackOnlyJsonParser with the System.Text.Json library to deserialize persistable objects, while avoiding the allocation of an underlying collection.
All fields of basic types can be made nullable by using the standard ? notation.
[StackOnlyJsonType]
internal readonly ref partial struct Product
{
public int? Id { get; }
...
}In that case, the field will be given the default value of null and will be able to handle a null value in the deserialized data.
Unfortunately, as ref structs cannot be used as generic type parameters, the language prohibits us from making them nullable. Because of that, apart from constructors, the StackOnlyJsonParser also adds a HasValue field to the generated partial struct code. If false, the field of a given type was either not present or was explicitly set to null.
If the HasValue property comes into a conflict with one of the existing fields, the conflicting field should be renamed and the [StackOnlyJsonField("HasValue")] attribute used to assign it the proper serialization name.
As the List<> and the Dictionary<,> types do not follow the requirements mentioned before, they cannot be used as field types.
Instead, each collection type has to be defined separately using the [StackOnlyJsonArray] or the [StackOnlyJsonDictionary] attributes.
[StackOnlyJsonType]
internal readonly ref partial struct Price
{
public decimal Value { get; }
public string Currency { get; }
}
[StackOnlyJsonDictionary(typeof(string), typeof(Price))]
internal readonly ref partial struct RegionPriceDictionary
{ }
[StackOnlyJsonArray(typeof(int))]
internal readonly ref partial struct Sizes
{ }
[StackOnlyJsonType]
internal readonly ref partial struct Product
{
public string Name { get; }
public RegionPriceDictionary Prices { get; }
public Sizes Sizes { get; }
}Similarly to the [StackOnlyJsonType] attribute, the [StackOnlyJsonDictionary] and the [StackOnlyJsonArray] attributes will enrich the given types with a proper constructors allowing for data deserialization.
They will also provide an implementation of the GetEnumerator and the Any methods, allowing for easy enumeration over elements using the standard foreach statement:
var product = new Product(data);
foreach (var price in product.Prices)
Console.WriteLine($"Region: {price.Key}, Price: {price.Value.Value} {price.Value.Currency}");
foreach (var size in product.Sizes)
Console.WriteLine($"Size: {size}");The collection types can also be used to directly deserialize the data, if the outer type of that data is of a collection type:
var data = Encode("[1, 2, 3]");
var sizes = new Sizes(data);If limiting the number of allocations is of the utmost importance to you, instead of using the System.String type when defining your models, you can use the StackOnlyJsonParser.StackOnlyJsonString type instead. It's a non-allocating wrapper over the Utf8JsonReader that allows you to easily compare the stored string data with a provided value.
Considering that string values in your deserialized data will most likely be very short lived objects, and that creation of the StackOnlyJsonString requires making a copy of the Utf8JsonReader (which is a relatively big struct), using the StackOnlyJsonString can have a negative performance impact as compared to the standard string. Nevertheless, it can help you achieve a truly zero-allocation memory profile.
By definition structs cannot have cycles in their layouts as that would lead to them having an infinite size. Nevertheless, the StackOnlyJsonParser allows for defining recursive models by the use of lazy loading. It works similarly to the collections - you might think of lazy loaders as collections with only one element. To define a lazy loader use the [StackOnlyJsonLazyLoader] attribute:
[StackOnlyJsonType]
internal readonly ref partial struct RecursiveType
{
public int Id { get; }
public RecursiveTypeLazyLoader Internal { get; }
}
[StackOnlyJsonLazyLoader(typeof(RecursiveType))]
internal readonly ref partial struct RecursiveTypeLazyLoader
{ }Now you can deserialize the data in the following way:
internal void Process(RecursiveType model)
{
Console.WriteLine(model.Id);
if (model.Internal.HasValue)
Process(model.Internal.Load());
}var data = Encode(@"{ ""Id"": 1, ""Internal"": { ""Internal"": { ""Id"": 3 }, ""Id"": 2 } }");
Process(new RecursiveType(data));The Load method creates and deserializes the new object ad hoc based on the previously cached position of the json tokenizer.
The deserialization of simple and custom message types is rather straightforward. The generated constructors use the provided Utf8JsonReader as a token provider for field deserialization.
The real clue of the idea behind this library comes in a form of collections. Whenever one of them is encountered, the deserialization code skips the entire block, only remembering its bounds. The consecutive elements will be deserialized ad-hoc within the foreach loop when requested. Thanks to this only one element of the collection is alive at one time and the entire process can be performed entirely on the stack with no heap allocations. That can be especially important in case of big collections, which if allocated, could travel across GC generations.
An example of a generated array deserializer:
using System;
using System.Buffers;
using System.Text.Json;
namespace StackOnlyJsonParser.Example
{
internal readonly ref partial struct ProductArray
{
private readonly Utf8JsonReader _jsonReader;
public readonly bool HasValue { get; }
public ProductArray(ReadOnlySpan<byte> jsonData) : this(new Utf8JsonReader(jsonData, new JsonReaderOptions { CommentHandling = JsonCommentHandling.Skip }))
{}
public ProductArray(ReadOnlySequence<byte> jsonData) : this(new Utf8JsonReader(jsonData, new JsonReaderOptions { CommentHandling = JsonCommentHandling.Skip }))
{}
private ProductArray(Utf8JsonReader jsonReader) : this(ref jsonReader)
{}
public ProductArray(ref Utf8JsonReader jsonReader)
{
if (jsonReader.TokenType != JsonTokenType.StartArray && jsonReader.TokenType != JsonTokenType.Null) jsonReader.Read();
switch (jsonReader.TokenType)
{
case JsonTokenType.StartArray:
HasValue = true;
_jsonReader = jsonReader;
_jsonReader.Read();
jsonReader.Skip();
break;
case JsonTokenType.Null:
HasValue = false;
_jsonReader = default;
break;
default:
throw new JsonException($""Expected '[', but got {jsonReader.TokenType}"");
}
}
public bool Any() => HasValue && _jsonReader.TokenType != JsonTokenType.EndArray;
public Enumerator GetEnumerator() => new Enumerator(_jsonReader);
public ref struct Enumerator
{
private Utf8JsonReader _jsonReader;
public Enumerator(in Utf8JsonReader jsonReader)
{
_jsonReader = jsonReader;
Current = default;
}
public Product Current { get; private set; }
public bool MoveNext()
{
if (_jsonReader.TokenType == JsonTokenType.EndArray || _jsonReader.TokenType == JsonTokenType.None) return false;
Current = new Product(_jsonReader);
_jsonReader.Read();
return true;
}
}
}
}Below you can find the results of the performance tests defined in the StackOnlyJsonParser.PerformanceTests project.
In short, each framework was given a serialized json data containing a list of objects with the following definition:
internal class Product
{
public string Name { get; set; }
public DateTime ProductionDate { get; set; }
public Size BoxSize { get; set; }
public int AvailableItems { get; set; }
public List<string> Colors { get; set; }
public Dictionary<string, Price> Regions { get; set; }
}
internal class Size
{
public double Width { get; set; }
public double Height { get; set; }
public double Depth { get; set; }
}
internal class Price
{
public string Currency { get; set; }
public decimal Value { get; set; }
}In case of the StackOnlyJsonParser and the System.Text.Json library, the data was encoded as a UTF8 byte array. The Newtonsoft parser was provided with a string representation.
As the StackOnlyJsonParser loads the data ad hoc, the test included a simple data aggregation task that was performed on data generated by each library.
The StackOnlyJsonParser was profiled with both the standard string type, as well as the StackOnlyJsonString type as the underlying text representation.
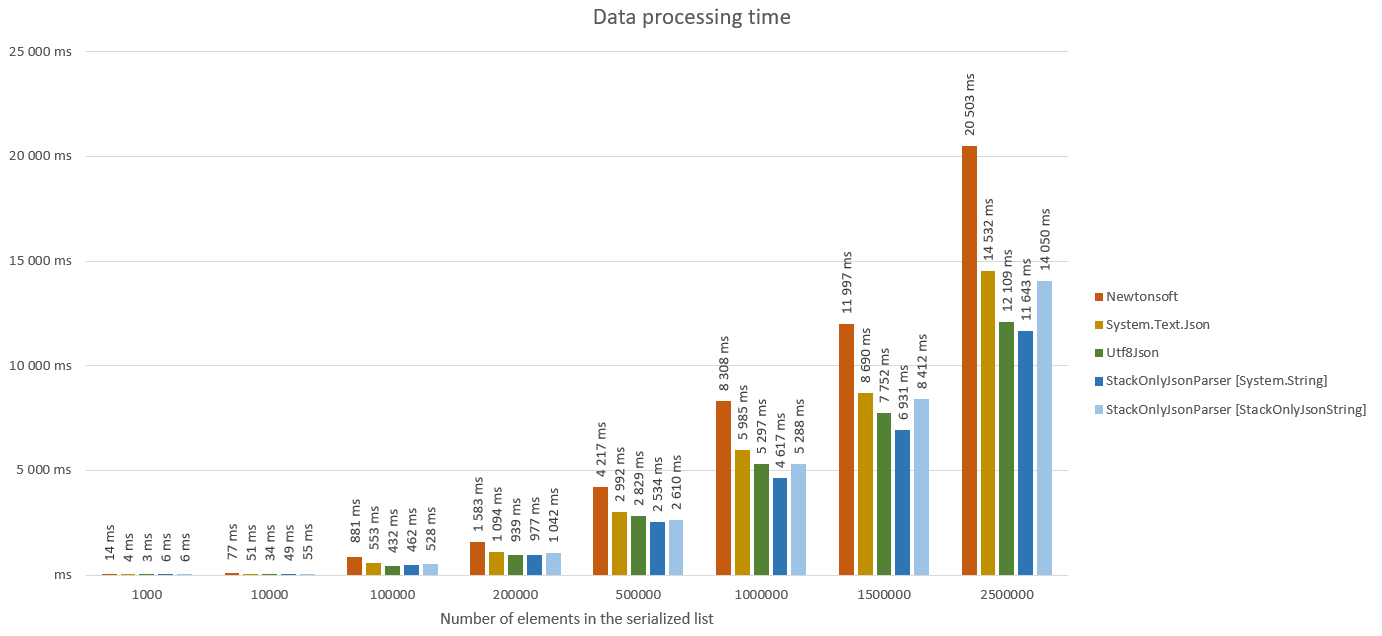
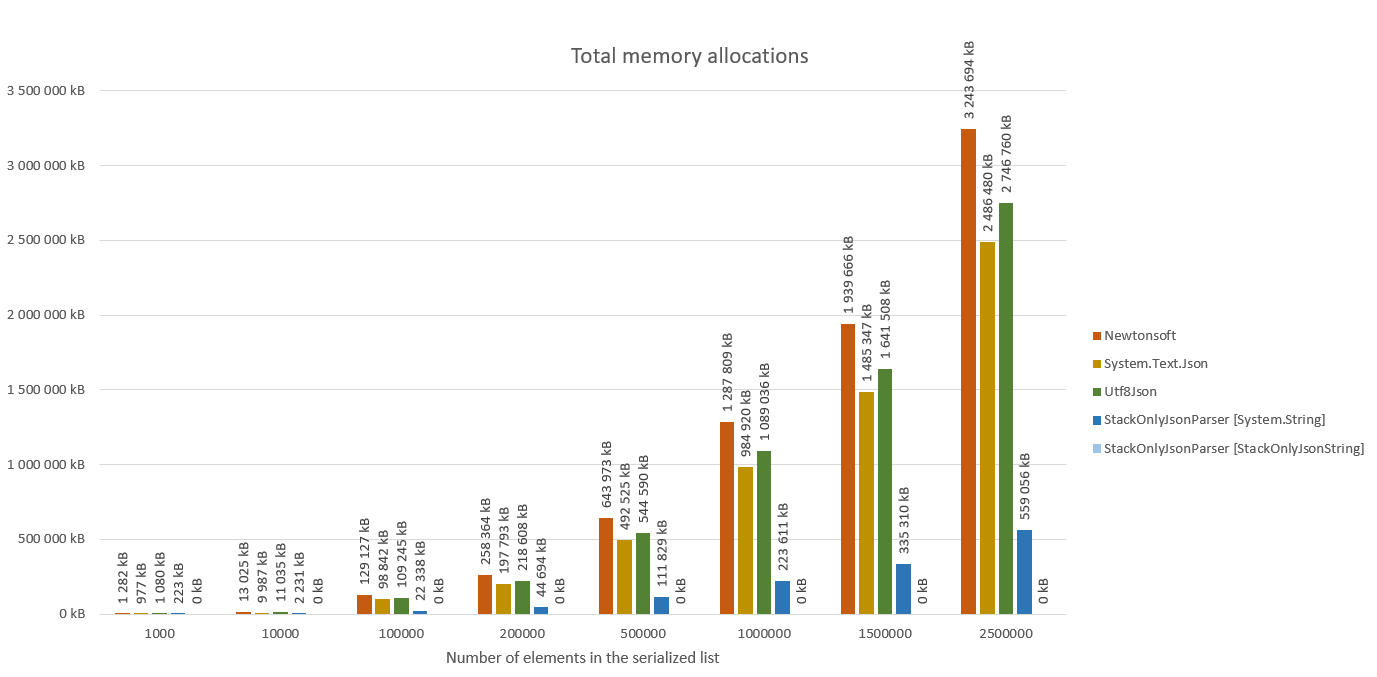
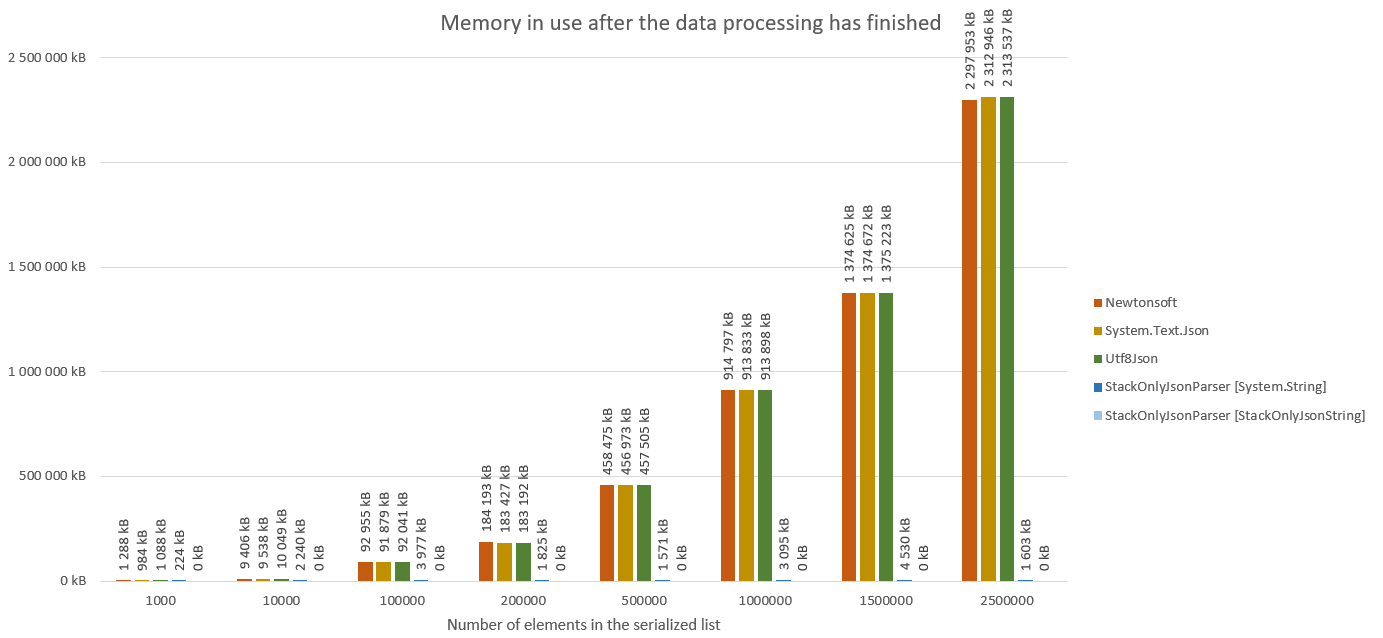
Please note that the processing time of small messages is higher for the StackOnlyJsonParser than for alternative libraries. After all the StackOnlyJsonParser needs to iterate through the entire message multiple times in order to perform lazy loading of arrays and dictionaries. The performance gain when processing bigger messages comes mostly from the fact that the StackOnlyJsonParser doesn't have to perform additional allocations when creating those collections. So if performance in processing of small messages is your main concern, you might want to consider using alternative parsers. But if you main focus is on the memory footprint of the deserialization process in case of big messages, the StackOnlyJsonParser might be a good choice for you.