{kind=link}
This project hosts the code for my thesis Quote Attribution and Character Networks in Novels. The thesis is available from here: http://hdl.handle.net/20.500.11956/127970.
The project has been developed and tested with Python 3.6.
This program does three things:
- Extract the list of characters from a novel.
- Attribute the speaker to every utterance.
- Create multiple types of character networks.
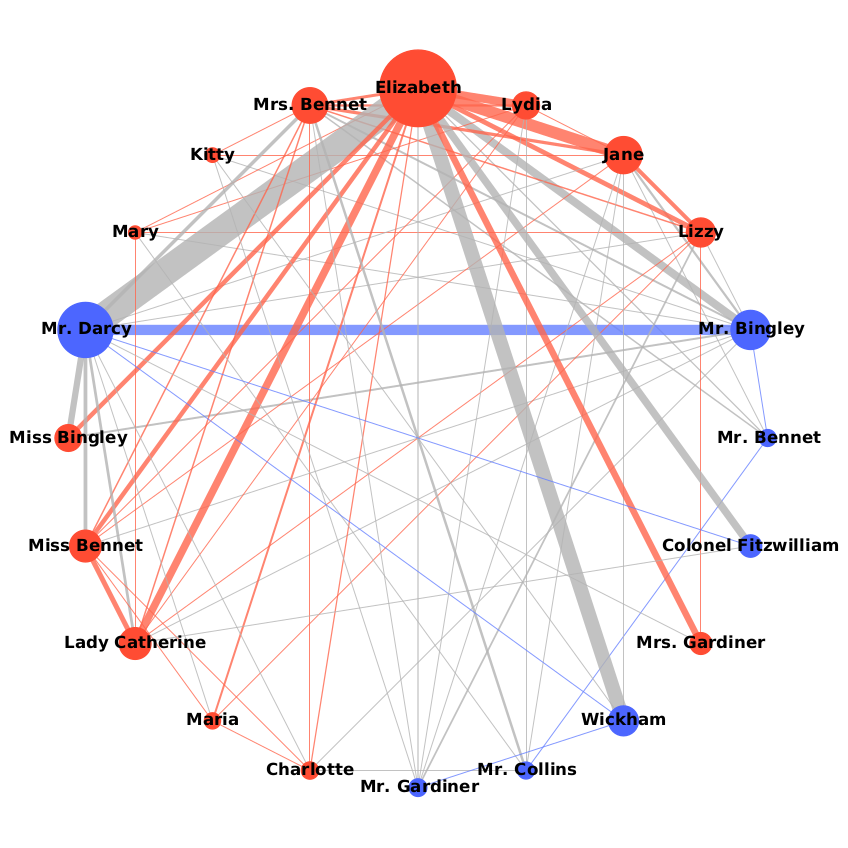
Based on the text of Pride and Prejudice, this program can generate a graph showing how often characters talk to each other:
Clone the repository for resolving coreference (using the current commit 3571ec3fc11e48f488e4cc54fc56b3e8508a058a).
git clone https://github.com/shtoshni92/long-doc-coref.git
Download the LB-MEM coreference model from here and place it in the correct folder:
pip install gdown
gdown --id 1PKlFab387j_1GnYA9E4lq-8nQ9csEeAL -O models/coref.pth
Install the requirements for this project.
pip install -r requirements.txt
python3 -m spacy download en_core_web_trf
The program has four modes of execution:
$ python3 src/main.py --help
usage: main.py [-h] {run,collect,train,evaluate} ...
The mode run with no arguments annotates a sample story A Scandal in Bohemia, finds the speakers and outputs a co-occurence and a conversational network, and the character list.
The arguments let the user specify the book to process, the output folder, the model for predicting character name equality and two of its settings. Setting --removelimit=0 is the NO_REMOVAL approach from the thesis, setting --maxprob=1 is the ALL_EDGES approach.
The -n option prohibits saving of the annotated file which is otherwise done automatically.
The last two options allow to use the program with the golden characters instead of the extracted ones, or create a conversational network with the correctly attributed speakers.
$ python3 src/main.py run --help
usage: main.py run [-h] [--book BOOK] [--out OUT] [--model MODEL]
[--maxprob MAXPROB] [--removelimit REMOVELIMIT] [-n]
[--goldcharacters GOLDCHARACTERS] [--goldxml GOLDXML]
...
The mode collect annotates all books in the specified folder and prepares the data for training the model in mode train.
The mode evaluate evaluates the accuracy of the extracted characters or of the attributed speakers, depending on the given arguments.
I did not include the lists of golden characters by Vala et al. and the annotated speakers by Muzny et al. in this repository. If you are interested in this data, you can get in touch with me or with the original authors.