{kind=link}
{kind=link}
A final project for Comp 541 Deep Learning Course By Deniz Yuret. This projectreplicates Dependency-based Convolutional Neural Networks for Sentence Embedding's results in Julia using Knet .
https://www.overleaf.com/read/smdkjvwbkzkp
In sentence modeling and classification, convolutional neural network approaches have recently achieved state-of-the-art results, but all such efforts process word vectors sequentially and neglect long-distance dependencies. To combine deep learning with linguistic structures, a dependency-based convolution approach was proposed, making use of tree-based n-grams rather than surface ones, thus utilizing non-local interactions between words. The model improves sequential baselines on all four sentiment and question classification tasks and achieves the highest published accuracy on TREC.
git clone https://github.com/alabrashJr/DCNN-Julia
cd DCNN-Julia && git clone https://github.com/chentinghao/download_google_drive.git
pip install tqdm
python download_google_drive/download_gdrive.py 1YWl_p2FtzOWhknwVxAzFD5740hnUhwe0 ./google_w2v.bin
python download_google_drive/download_gdrive.py 1cUpzjy9ASH1pJQeJkM1KoKMcdBwe9kDT ./Data.zip
unzip Data.zip -d ./
rm Data.zip
julia process_TREC.jl
julia dcnn.jl
The input to most NLP tasks is sentences or documents represented as a matrix. Each row of the matrix corresponds to one token, typically a word, but it could be a character. That is, each row is a vector that represents a word. Typically, these vectors are word embeddings (low dimensional representations), but they could also be one-hot vectors that index the word into a vocabulary. For a 10 word sentence using a 300-dimensional embedding, we would have a 300x10 matrix as our input. In computer vision, the filters slide over local patches of an image, but in NLP filters slide over full rows of the matrix (words). Thus, the height of the filters is usually the same as the height of the input matrix. The width, or region size, may vary but sliding. In order to capture the long-distance dependencies the dependency based convolution model (DCNN) is proposed.
Dependency tree of an example sentence from the TREC data set andarray representation

Model Structure

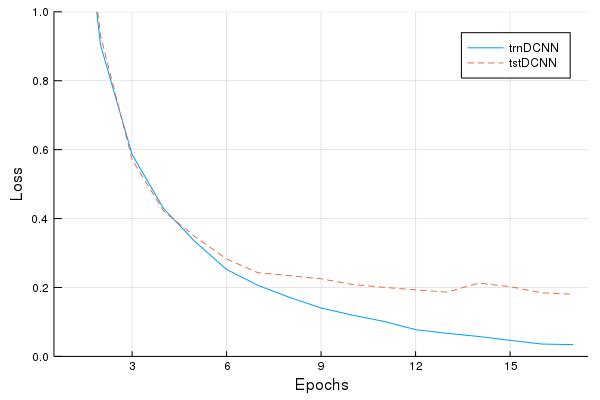
Loss Plot
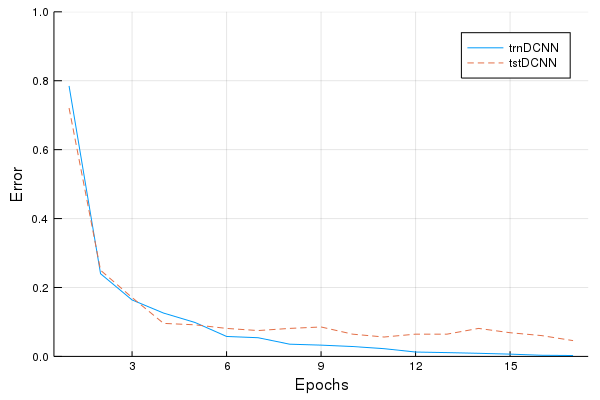
Error Plot
models accuracies : https://drive.google.com/file/d/13azo5E8JSoapbbLf6mXIBG3kfKqh7rnZ/view?usp=sharing
Setup : https://docs.google.com/document/d/1lyTPLovvrCkhU1NIUpxNmgOyKWNYgQzCQG1Cdv-tveg/
Research Log: https://docs.google.com/spreadsheets/d/1yE3PwbQjsSqPG3YOr9sSb0x6-JGEXnobi3ct-RZUu2w/
persentation: https://docs.google.com/presentation/d/1qJo4AgcP2QQR0ZApQaDPRO0RO7Xo89BwLULUVSMdHGE
Datasheet: https://docs.google.com/spreadsheets/d/1vkZVL3cdjIBhrTeOTqbaTDuQXeHW_J6rP7MCSOOSj3A