Combining a CNN and LSTM In 2014, researchers from Google released a paper, Show And Tell: A Neural Image Caption Generator. At the time, this architecture was state-of-the-art on the MSCOCO dataset. It utilized a CNN + LSTM to take an image as input and output a caption.
A CNN-LSTM Image Caption Architecture source
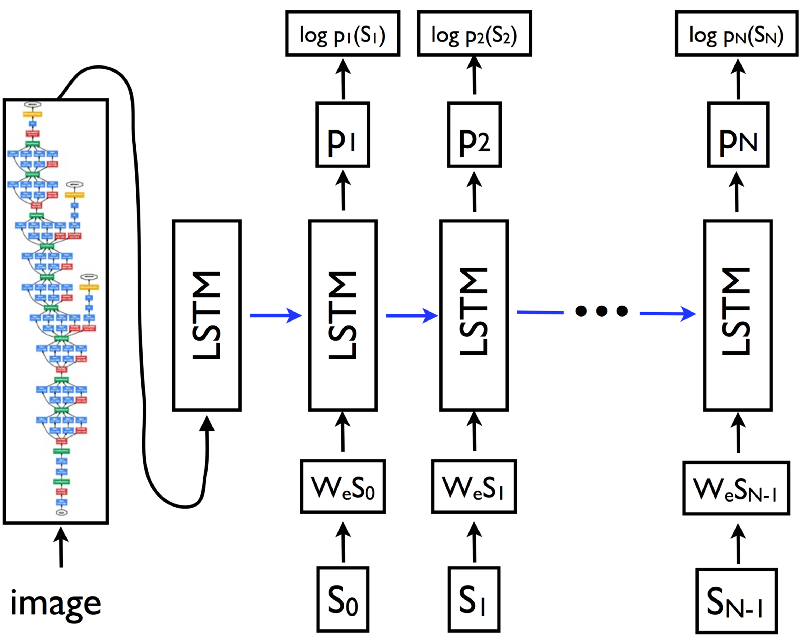
Using a CNN for image embedding A convolutional neural network can be used to create a dense feature vector. This dense vector, also called an embedding, can be used as feature input into other algorithms or networks.
For an image caption model, this embedding becomes a dense representation of the image and will be used as the initial state of the LSTM.
Mapping input to embedding source LSTM An LSTM is a recurrent neural network architecture that is commonly used in problems with temporal dependences. It succeeds in being able to capture information about previous states to better inform the current prediction through its memory cell state.
An LSTM consists of three main components: a forget gate, input gate, and output gate. Each of these gates is responsible for altering updates to the cell’s memory state.
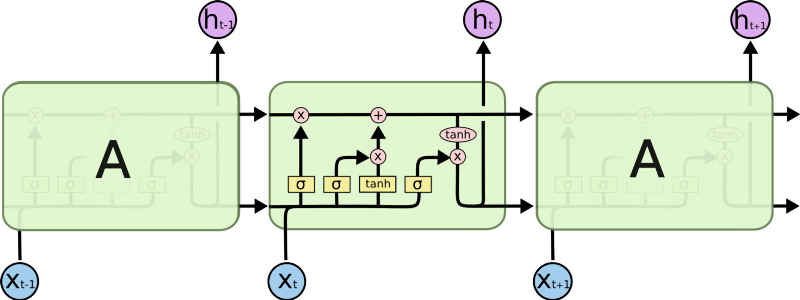
An unrolled LSTM source For a deeper understanding of LSTM’s, visit Chris Olah’s post.
Prediction with image as initial state In a sentence language model, an LSTM is predicting the next word in a sentence. Similarly, in a character language model, an LSTM is trying to predict the next character, given the context of previously seen characters.
Sentence and character model predictions source In an image caption model, you will create an embedding of the image. This embedding will then be fed as initial state into an LSTM. This becomes the first previous state to the language model, influencing the next predicted words.
At each time-step, the LSTM considers the previous cell state and outputs a prediction for the most probable next value in the sequence. This process is repeated until the end token is sampled, signaling the end of the caption.
The Dataset which I used for this project is MS-COCO which is widey used dataset for image captioning and can also be applied in this case.