
In the last three posts I have explained Generative Adversarial Network, its problems and an extension of the Generative Adversarial Network called Conditional Generative Adversarial Network to solve the problems in the successful training of the GAN.
As claimed earlier in the last post, Image to Image translation is one of the tasks, which can be done by Conditional Generative Adversarial Networks (CGANs) ideally.
In the task of Image to Image translation, an image can be converted into another one by defining a loss function which is extremely complicated. Accordingly, this task has many applications like colorization and making maps by converting aerial photos. Figures above show great example of Image to Image translation.
Pix2Pix network was developed based on the CGAN. Some of the applications of this efficient method include object reconstruction from edges, photos synthesis from label maps, and image colorization [source].
As mentioned above, Pix2Pix is based on conditional generative adversarial networks (CGAN) to learn a mapping function that maps an input image into an output image. Pix2Pix like GAN, CGAN is also made up of two networks, the generator and the discriminator. Figure below indicates a very high-level view of the Image to Image architecture from the Pix2Pix paper.
]](https://cdn-images-1.medium.com/max/2028/1*0WR3FWWyLdcHwXduGN7kFQ.png)
The generator goal is to take an input image and convert it into the desired image (output or ground truth) by implementing necessary tasks. There are two types of the generator, including encoder-decoder and U-Net network. The latter difference is to have skip connections.
Encoder-decoder networks translate and compress input images into a low-dimensional vector presentation (bottleneck). Then, the process is reversed, and the multitudinous low-level information exchanged between the input and output can be utilized to execute all necessary information across the network. In order to circumvent the bottleneck for information, they added a skip connection between each layer i and n-i where i is the total number of the layers. It should be noted that the shape of the generator with skip connections looks like a U-Net network. Those images are shown below.
]](https://cdn-images-1.medium.com/max/2032/1*bh5b5JmdgpZJupqIhVydrg.png)
As seen in the U-Net architecture, the information from earlier layers will be integrated into later layers and because of using skip connections, they don’t need any size changes or projections.
The task of the discriminator is to measure the similarity of the input image with an unknown image. This unknown image either belongs to the dataset (as a target image) or is an output image provided by the generator.
The PatchGAN discriminator in Pix2Pix network is employed as a unique component to classify individual (N x N) patches within the image as real or fake.
As the authors claim, since the number of PatchGAN discriminator parameters is very low, the classification of the entire image runs faster. The PatchGAN discriminator’s architecture is shown in figure below.
]](https://cdn-images-1.medium.com/max/2970/1*Ko9dmOP1cc5q3J8ggLxEbg.png)
The reason for calling this architecture as “PatchGAN” is that each pixel of the discriminator’s output (30 × 30 image) corresponds to the 70×70 patch of the input image. Also, it’s worth noting that according to the fact the input images size is 256×256, the patches overlay considerably.
It is well known that there are many segmentation networks, which can segment objects, but the most important thing that they do not consider is to have segmentation networks that their segmented objects look like ground truths from the perspectives of shapes and edges and contours . To make the topic more clear, an example from one of the own practical projects that was carried out is presented below.

As shown in figure above, the right figure represents the result for building footprint segmentation, and the middle figure shows the corresponding ground truth. The model can detect where buildings are located but fails to reflect the boundaries, which are present in the ground truth and edges and contours of the segmented buildings doesn’t match exactly the ground truth.
As known, how buildings look like, depends on how the contours of the building are drawn. The most crucial information of an object is the object boundary and the shape and edges of a segmented building can be controlled or improved with the help of contours (the object boundary). Based on this assumption, the extracted contours of each ground truth were added to the corresponding ground truth again to reinforce the shape and edges of a segmented building for further research.

As seen in figures above, contours were added again to objects of the ground truths after extracting them with the OpenCV library.
After adding corrsponding contours again to objects of the ground truths (on the fly in the code), Satellite images and ground truths with overlaid contours (An example shown in the following) form the dataset used in the training of Pix2Pix network.
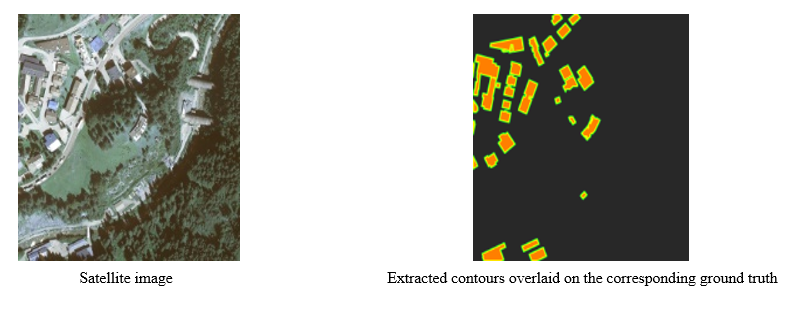
After defining th dataset, the weights of Pix2Pix network are adjusted in two steps.
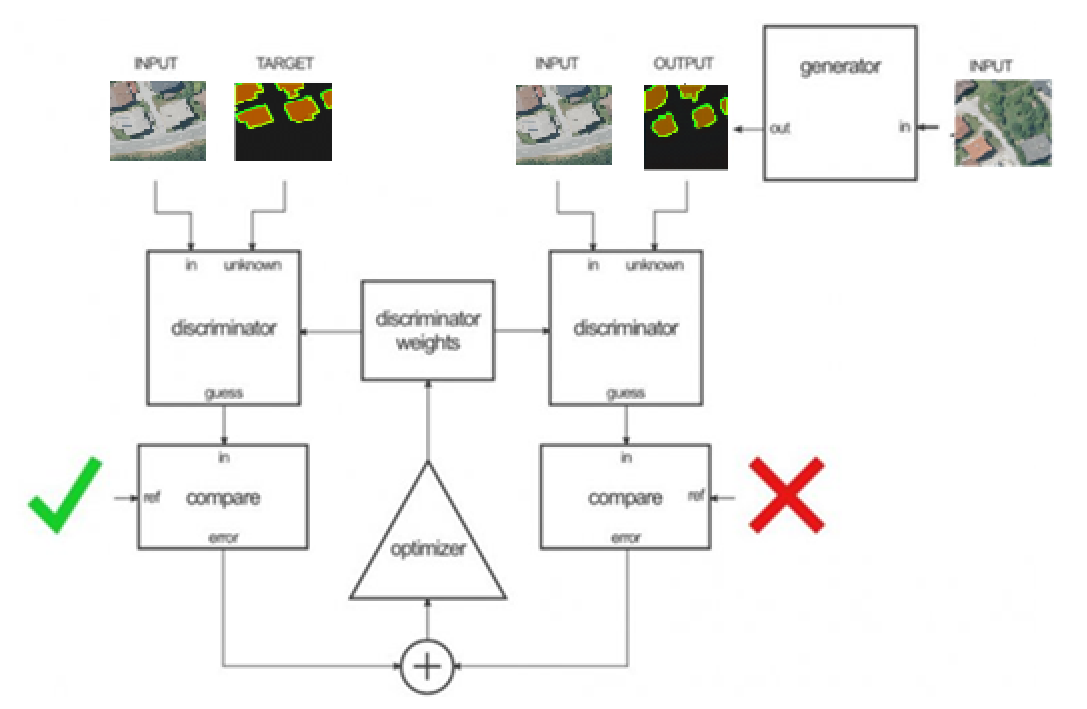
In the first step, The discriminator (figure below) takes the input (Satellite image)/target (ground truths with overlaid contours) and then input (Satellite image)/output (generator’ output) pairs, to estimate how realistic they look like. Then the adjustment of the discriminator’s weights is done according to the classification error of the mentioned pairs.
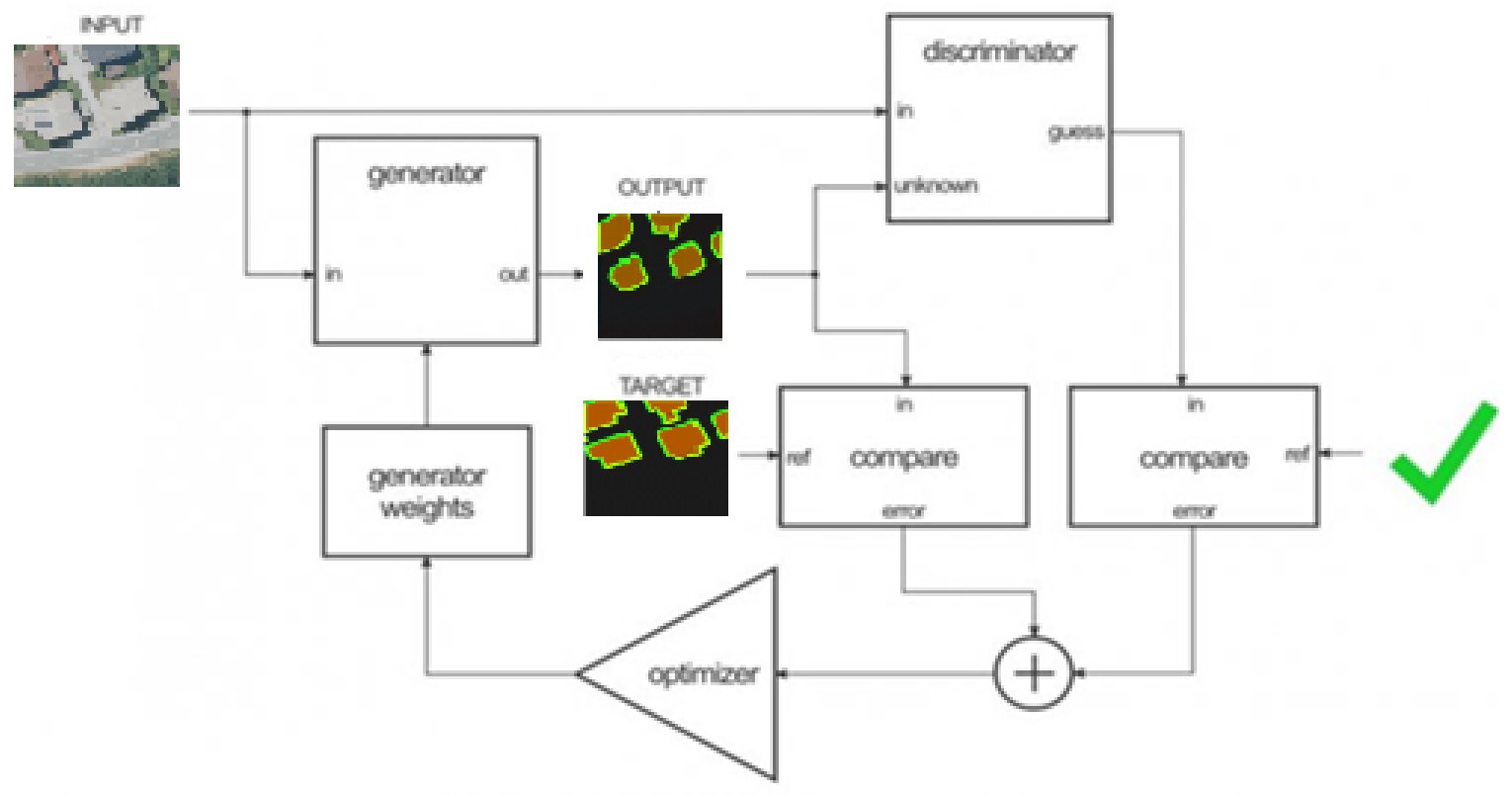
In the second step, The generator’s weights(figure below) adjust by using the discriminator’s output and the difference between the output and target images.
Based on the paper, the objective function can be expressed as follow:
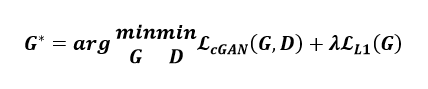
The Authors of Pix2Pix used and added the loss function L1 measuring the standard distance between the generated output and the target.
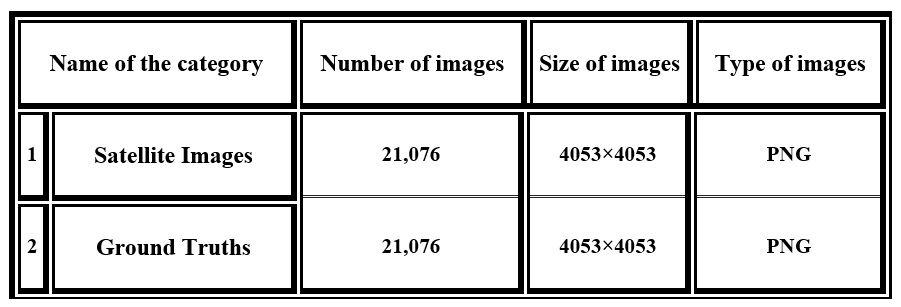
In this section, the characteristics of the Orthofoto Tirol dataset will be explained. This dataset consists of two categories which are shown in Table below.
As known, all pixels of an image are important when each pixel is used by a segmentation model with a specific size of the input. Therefore, the data (pixels) will be lost from the image and the size of the image will be much smaller if the number of pixels have to reduce to meet this specific size of the input. It can be crucial to retain more information about images when it comes to resizing an image without losing quality.
The images of the the Orthofoto Tirol dataset have to cut into 256×256 because Pix2Pix only takes in 256×256 images. In the first attempt, the size of the satellite and corresponding ground truth images was reduced all at once to 256×256, which leads to losing 158.488.281 pixels. According to the fact that each pixel plays an important role in detecting each edge of a building, many pixels got lost. For this reason, a process was designed to select and cut images:
1. Due to lack of time and processing power, images with a high building density are selected from the entire dataset.
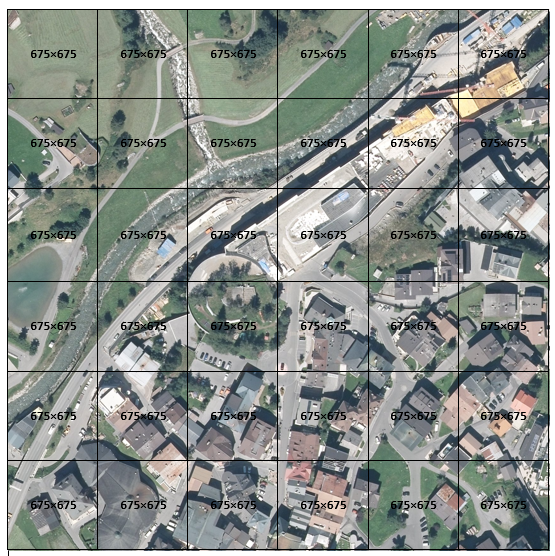
2. The size (4053×4053 pixels) of each selected image from the dataset (Satellite images and ground truths with overlaid contours) is changed to 4050×4050 pixels (see example blow).

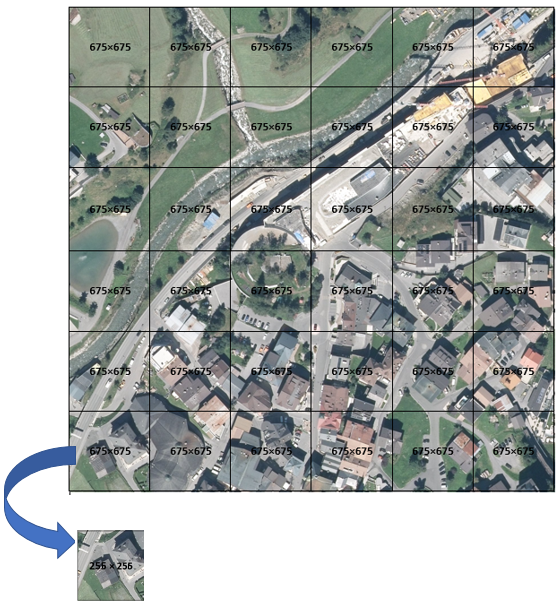
3. Images from the last step cropped to the size of 675×675 pixels (see example blow).
4. The size of all cropped images resized to 256 × 256 pixels, which means that little information is lost (approx. 2.636.718 pixels, which is little compared to 158.488.281 pixels).
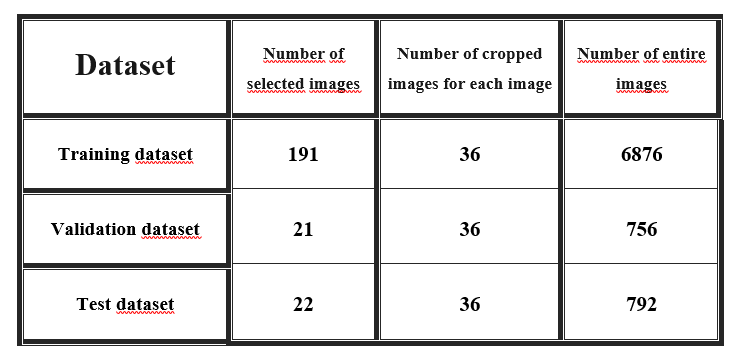
The described process is repeated for all Images (Satellite images and ground truths with overlaid contours) to create the training, validation, and test datasets and the properties of each created dataset are indicated in Table below.
A validation dataset will be needed to evaluate the model in the duration of training. The validation dataset can be employed for training goals to find and optimize the best model. In this experiment, the validation dataset can be employed for overfitting minimization and hyper-parameter fine-tuning.
After training Pix2Pix on the training dataset, as shown below and tested on the validation and test datasets, the generator of Pix2Pix trying to improve the results and makes predictions which look like ground truths from the perspective of contours and edges.
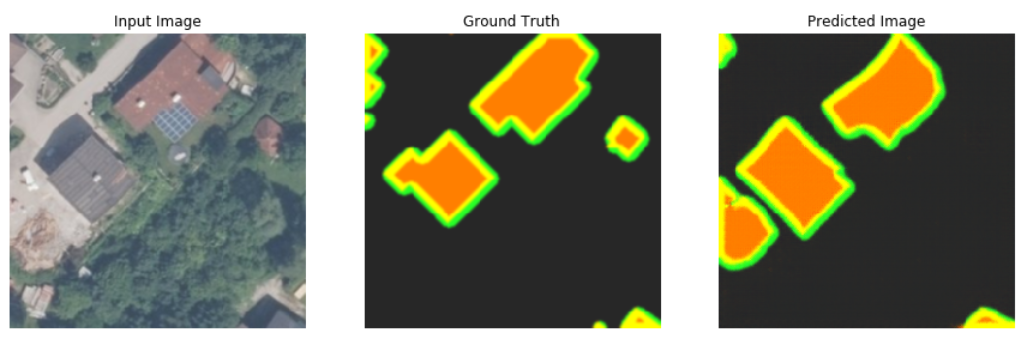

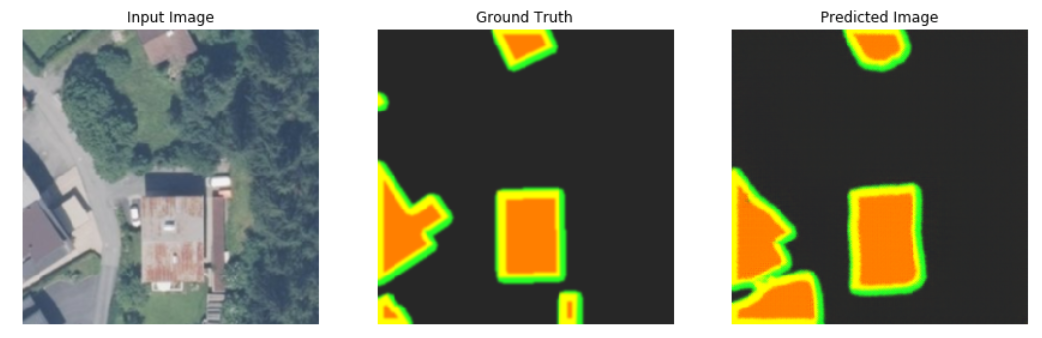
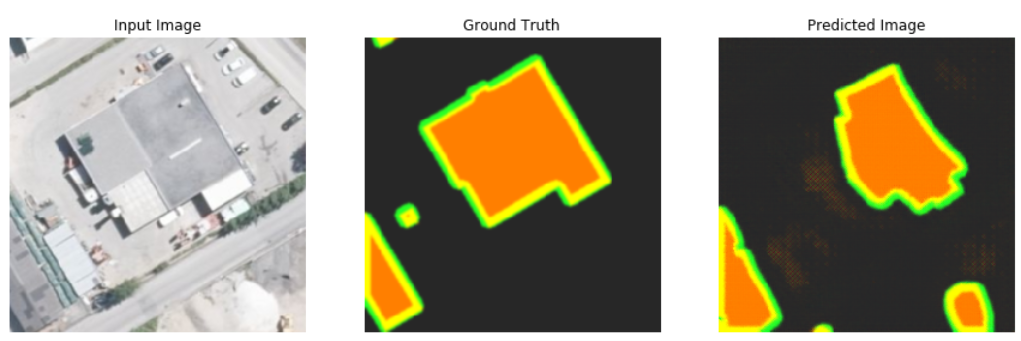
Evaluating the segmentation quality is very important for image processing, particularly in security cases, including autonomous vehicles. There are many evaluation criteria developed for segmentation evaluation so that researchers can make a choice based on their needs. In this post on my github you can read the evaluation criteria of segmentation networks.
Since the field of computer vision is significantly influenced by artificial neural intelligence and especially deep learning, many researcher and developers are interested in the implementation of a suitable deep learning architecture for building footprint segmentation. One of the most important issues in the field of segmentation are inefficient and inaccurate segmentation networks which output shapes differing from the shape of ground truth.
The presented experiment aims at using Pix2Pix network to segment the building footprint. The results of Pix2Pix on the test dataset seem to be good, but there is still much room for improvement of segmentation quality.