Technical Overview
This document is intended to provides a technical overview of Axiom.
Axiom consists of three tiers, which are a slightly modified version of the traditional three-tier architecture.
The traditional three-tier architecture has data, logic and presentation tiers. In Axiom we "upgrade" the data tier to an information tier and "downgrade" the logic tier to a mere gateway tier.
The three tiers communicate by passing events from one to the other. We will therefore start our discussion by describing Axiom's event-sourcing approach.
Event sourcing is a common design pattern in applications. An event-sourcing system will typically not store state, but rather store changes to state, in the form of events. When state is required, it can be obtained by "playing" stored events. State can also be cached as an optimization, but only as such. Events are the "single source of truth" in such a system.
Usually, when system architects choose event-sourcing as a pattern for maintaining state in their application, they do so decrease latencies and increase availability in a highly-distributed system.
Maintaining state the traditional way is bound to the limitations of the CAP Theorem. Event sourcing allows us to create events for updating the state without knowing the absolute state at the time of the update. All that is required for such mechanism to work is a consistent algorithm for constructing state based on "played" events, such that no matter what events we got and in which order, the same collection of events will always lead to the same state.
Axiom is a distributed system, so designing it as an event-sourcing system makes sense. However, in Axiom, the need for event sourcing is more profound than in most system, as we will explain next.
As an event-sourcing system, all communications between Axiom's different components is done through events. Events are also the payload stored in Axiom's database.
Almost all the events used by Axiom follow the same structure. They are Clojure maps containing the following keys:
-
:kind: Either:fact, if this event represent a change to a fact, or:ruleif it represents a change to a rule. Other values are also possible for special control events. -
:name: A string representing the name of the stream this event belongs to. See fact-table for details. -
:key: The key of the fact or the rule. See here for more details. -
:ts: For facts, the time (in milliseconds since EPOCH) in which this event was created. For rules this is a unique ID constructed from the:tsvalues of the facts that contributed to this rule. -
:data: The data tuple representing a fact, or the state of a rule, excluding the key. -
:change: A number representing the change. Typically, 1 represents addition, and -1 represents removal. -
:writers: The event's writer-set, represented as an interset. -
:readers: The event's reader-set, represented as an interset. -
:removed(optional): If exists, account for an additional event that is identical to the original one, but with:data=:removed, and:change= -:change.
In the phylosiphical sense, events represent axioms, while the facts and rules they reference represent statements. This distinction is a key component behind Axiom's design -- so important that Axiom received its name from this.
Consider a fact like:
[:weather [:new-york [:date 3 :sep 2017]] :rain 18 23]depicting the weather forcast for New-York on September the 3rd 2017.
Is this fact an axiom? Can we take it as true? The answer is no. This was the forecast provided by one website on September the 2nd -- one day before. We can, however, take this fact as a statement made by the website on that particular day and time.
However, if this fact came to our knowledge through an event, some of the event's paramters can provide us with context that allows us to better refer to this information.
For example, the :writers set will tell us that this fact came from that website.
The :ts parameter will tell us when this forecast was stated.
The :change parameter will tell us whether the website stated this forecast at that time (a value of 1), or retracted it (-1).
If we properly check the contents of these fields before allowing them in our system (e.g., check that this fact was indeed stated by the website and not by an imposter), we can treat the event as an axiom -- this is indeed what the website claimed the weather was going to be.
This distinction between statements and axioms is a key component in how Axiom works, and in particular, in how it manages access control.
The Data/Information/Knowledge/Wisdom (DIKW) Pyramid describes data (the lowest level in the pyramid) as a collection of symbols (bits, numbers, strings, etc), that is given without a way to reason upon them. The next level -- information, is described as adding the ability to ask interogatory questions about the data.
Traditional three-tier applications store data in their data-tier. The data-tier is therefore unaware of the meaning of this data, and the logic-tier is responsible for maintaining it.
Axiom "upgrades" the data-tier to create an information-tier. This tier stores both the data, in the form of facts, rules for processing the facts. It can therefore apply these rules to allow queries to be made based on the facts and the rules.
By giving the information-tier semantic knowledge over the data allows it to solve problems typically solved in the logic-tier, such as:
- Access control,
- Denormalization, and
- Data migration.
Axiom's information-tier consists of three major subsystems, which we discuss next.
Axiom uses an event broker (RabbitMQ) to pass events (mostly :fact events) through its componets.
Any event that is produced by any part of Axiom (typically, by the front-end or by rules), is published on the event broker.
Subscribers across Axiom can subscribe to specific kinds of events (e.g., events with a certain :name or a certain :name and :key combination).
This subscribers will then receive events matching their requirements.
The rabbitmq-microservices library provides the interface to RabbitMQ by providing the abstraction of a microservice.
By our definition, a microservice is a function that subscribes to a subset of the events flowing through Axiom, and does something with them. This "something" may include publishing other events.
One of these microservices is the store-fact service, which stores all :fact events to the database.
Other users will be described next.
Axiom uses Apache Storm as its event processor.
Axiom uses Storm to apply rules to fact events as they arrive. To do so, Axiom's storm library creates, for each rule (or clause), a Storm topology of the following structure:
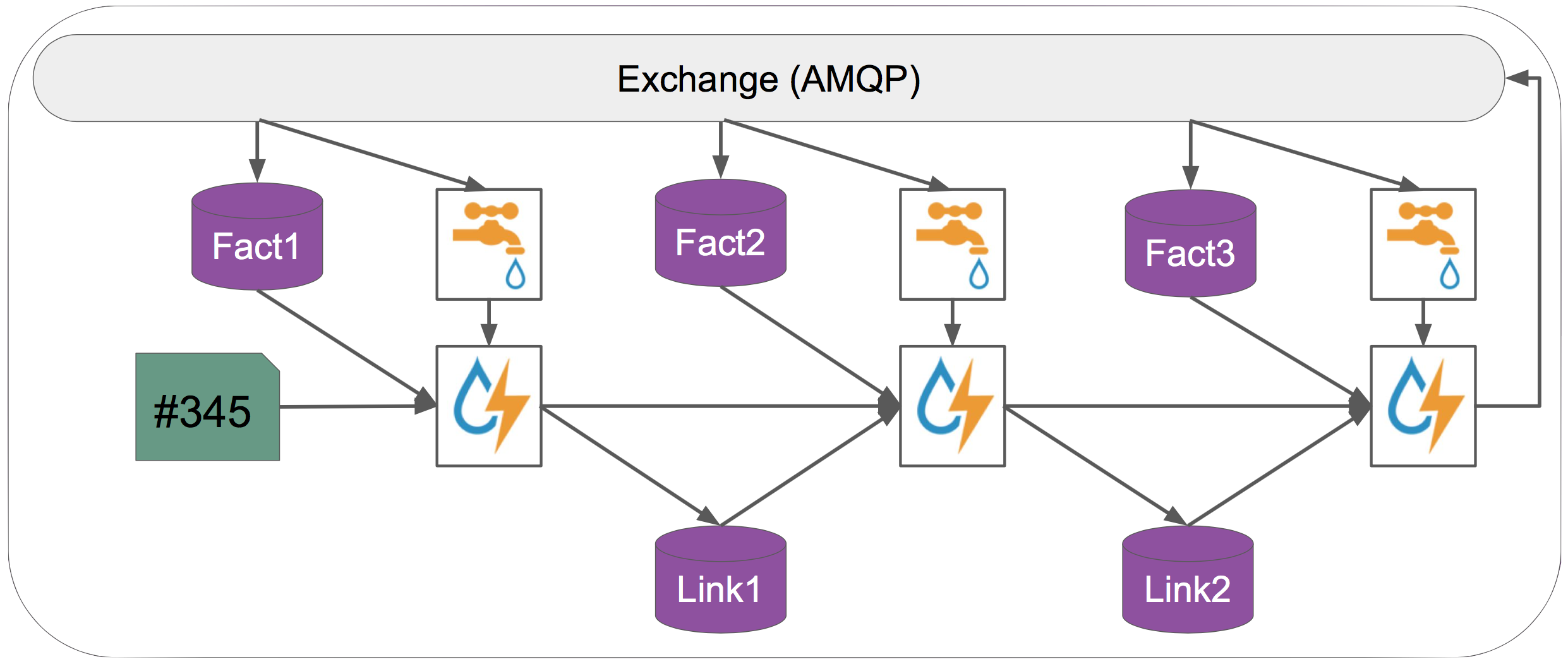
The number of links depends on the rule. Rules that depend on 3 facts, for example, map to topologies with 3 links.
The first link of each topology is special in that it only depends on fact events. The other links depend on both fact and rule events.
To receive fact events, the fact spouts (the parts of the topology responsible for tapping fact events) subscribe to fact events with a certain :name on the event broker.
Rule events, on the other hand, are created by the initial link and propagate through the topology.
Links other than the first one can receive events from either the previous link (rule events) or (fact events) from the fact spout that is attached to them. Each such link uses an event matcher to process these events.
An event matcher, when given a :fact event, will go to the database and look-up all matching :rule events.
Similarly, when given a :rule event, it will go to the database and look-up all matching :fact events.
The event processor part of Axiom is designed to only process new events. However, when a new version of an app is deployed, there is a need to go through all existing fact events and process them using the new rules.
The migrator is responsible for this.
It consists of microservices that subscribe to special control events of the namespace axiom.
One such event, axiom/app-version, is triggerred every time a new version of an app is deployed.
The microservice handling this event uses git to retrieve the new version, and then, through a sequence of events, another microservice starts the migration process for all new rules.
The migration process is a distributed batch process, which executes in order every link of every new rule, according to a topological sort of the rules.
Axiom uses its own framework for batch processing -- zk-plan, which uses Zookeeper to coordinate any number of workers competing on processing subsets of the facts that need processing.
The migration process works by scanning the database, looking for all events with a certain :name,
in a sharded manner to allow parallelism.