{kind=link}
This project hosts the code for our NIPS 2015 paper.
- Cesc Chunseong Park and Gunhee Kim. Expressing an Image Stream with a Sequence of Natural Sentences. In NIPS 2015 [pdf]
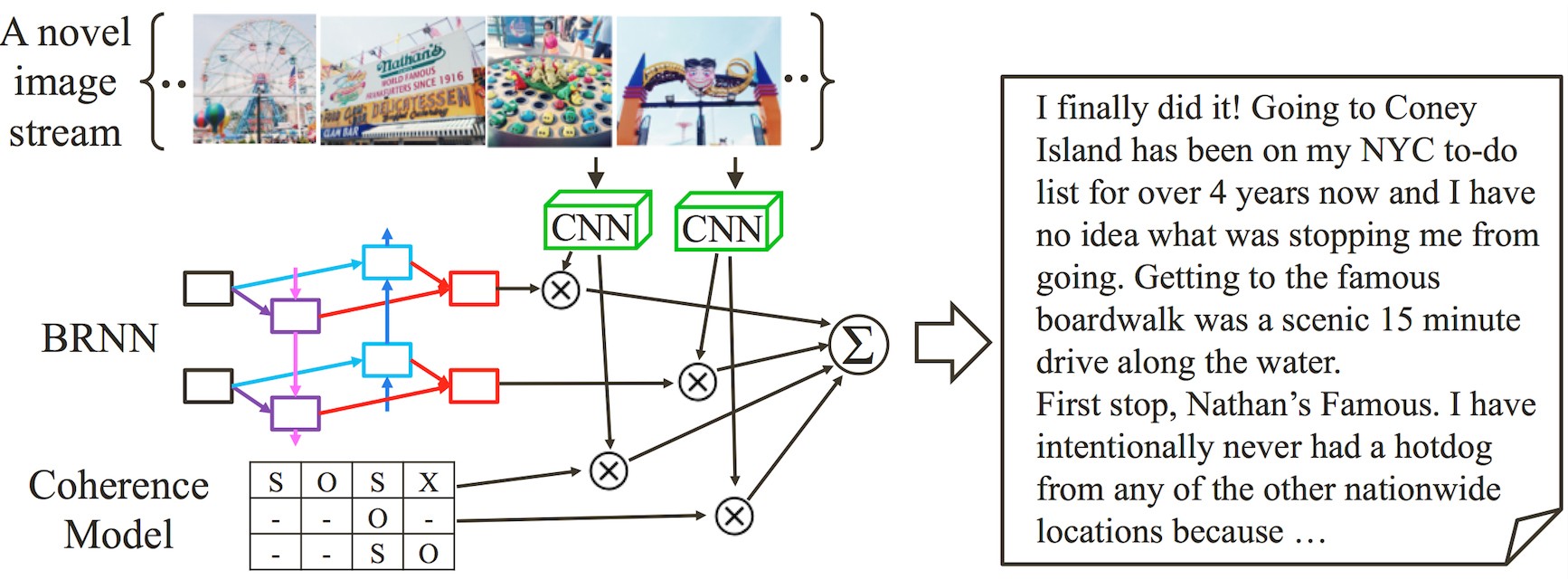
The CRCN stands for Coherent Recurrent Convolutional Networks. It integrates (i) convolutional networks for image description, (ii) bidirectional recurrent networks for the language model, and (iii) local coherence model for a smooth flow of multiple sentences.
The main objective of our model is, given a photo stream, to generate (retrieve) a coherent sequence of natural sentences. For example, if you visit New York City and takes lots of pictures, it can write a travelogue for your photo album. While almost all previous studies have dealt with the relation between a single image and a single natural sentence, our work extends both input and output dimension to a sequence of images and a sequence of sentences.
If you use this code as part of any published research, please acknowledge the following paper.
@inproceedings{Cesc:2015:NIPS,
author = {Cesc Chunseong Park and Gunhee Kim},
title = "{Expressing an Image Stream with a Sequence of Natural Sentences}",
booktitle = {NIPS},
year = 2015
}
git clone https://github.com/cesc-park/CRCN.git crcn
-
Install Stanford NLP
Download
stanford-parser.jar,stanford-parser-3.5.2-models.jarandenglishPCFG.caseless.ser.gz.wget http://nlp.stanford.edu/software/stanford-parser-full-2015-04-20.zip wget http://nlp.stanford.edu/software/stanford-corenlp-full-2015-04-20.zip unzip stanford-parser-full-2015-04-20.zip unzip stanford-corenlp-full-2015-04-20.zip mv stanford-parser-full-2015-04-20 stanford-parser mv stanford-corenlp-full-2015-04-20 stanford-core cd stanford-parser jar xvf stanford-parser-3.5.2-models.jar -
Install Brown courpus
We need the
browncourpusandwordnetpackages to extract entity features.sudo apt-get install wordnet-dev wget https://bitbucket.org/melsner/browncoherence/get/d46d5cd3fc57.zip -O browncoherence.zip unzip browncoherence.zip mv melsner-browncoherence-d46d5cd3fc57 browncoherence cd browncoherence mkdir lib64 mkdir bin64We have to change some lines in Makefile.
vim MakefileChange the followings from top to bottom.
WORDNET = 1 WORDNET = 0CFLAGS = $(WARNINGS) -Iinclude $(WNINCLUDE) $(TAO_PETSC_INCLUDE) $(GSLINCLUDE) CFLAGS = $(WARNINGS) -Iinclude $(WNINCLUDE) $(TAO_PETSC_INCLUDE) $(GSLINCLUDE) -fpermissiveWNLIBS = -L$(WNDIR)/lib -lWN WNLIBS = -L$(WNDIR)/lib -lwordnetThen build TestGrid.
make TestGrid cd .. -
Install python modules of all dependencies.
for req in $(cat python_requirements.txt); do pip install $req; done
-
Prepare dataset. Check out the data format.
less json_data_format.txt -
Create parsed trees. We use the
StanfordCoreNLPtool written in java to extract parsed trees.cd tree python spliter_for_parser.py javac -d . -cp .:./json-simple-1.1.1.jar:../stanford-core/stanford-corenlp-3.5.2.jar:../stanford-core/xom.jar:../stanford-core/stanford-corenlp-3.5.2-models.jar:../stanford-core/joda-time.jar:../stanford-core/jollyday.jar: StanfordCoreNlpTreeAdder.java java -cp .:./json-simple-1.1.1.jar:../stanford-core/stanford-corenlp-3.5.2.jar:../stanford-core/xom.jar:../stanford-core/stanford-corenlp-3.5.2-models.jar:../stanford-core/joda-time.jar:../stanford-core/jollyday.jar: parser.StanfordCoreNlpTreeAdder python merger_for_parser.py
Make directory for training
mkdir model
-
Doc2Vec. Train the doc2vec model.
python doc2vec_training.py -
RCN. Train the RCN model. If you want to use GPU (in this example device is 0), execute the below code.
CUDA_VISIBLE_DEVICES=0 THEANO_FLAGS=mode=FAST_RUN,device=gpu,floatX=float32 python rcn_training.pyIf you want to use CPU, run the below instead of the above.
python rcn_training.py -
CRCN. Train the CRCN model. If you want to use GPU (In this example device is 0), execute the below code.
CUDA_VISIBLE_DEVICES=0 THEANO_FLAGS=mode=FAST_RUN,device=gpu,floatX=float32 python crcn_training.pyIf you want to use CPU, run the below instead of the above.
python crcn_training.py
Generating output is easy. The following script loads training and test datasets, then automatically produces outputs.
python generate_output.py
We implement our model using keras package. Thanks for keras developers. :)
Cesc Chunseong Park and Gunhee Kim,
Vision and Learning Lab,
Seoul National University
MIT license