Run Datasette on AWS as a serverless application:
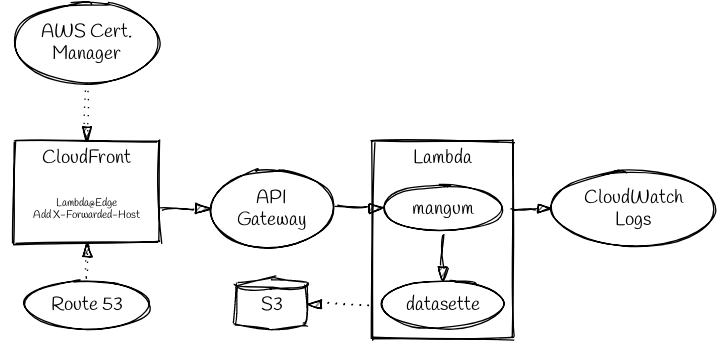
Sufficiently small databases (unzipped size up to ~250 MB, zipped size up to ~50 MB) will be inlined in the Lambda deployment package. Others will be published to S3 and fetched on Lambda startup.
You can see a demo using Datasette's fixtures db here: https://datasette-demo.code402.com/
Clone the repo and run ./update-stack <stack-name> [flags] <sqlite.db> [<sqlite.db> ...], e.g.:
git clone https://github.com/code402/datasette-lambda.git
cd datasette-lambda
./update-stack northwinds northwinds.db`Some Datasette flags are supported:
--config key:value, to set config options--cors, to enableAccess-Control-Allow-Origin: *headers on responses--metadata <metadata.json>, to provide metadata
And some non-Datasette flags are supported:
--domain example.comor--domain subdomain.example.com, ifexample.comis a hosted zone in Route 53- register a
CNAMErecord that points to the CloudFront distribution - register an SSL certificate for the domain (you'll have to ack a confirmation email from Amazon)
- associate that certificate to the CloudFront distribution
- register a
--prefix some/path, to mount the Datasette app at a path other than the root
A CloudFormation stack will be created (or updated) with an S3 bucket.
The stub code and SQLite database(s) will be uploaded to the S3 bucket.
A second CloudFormation stack will then be created (or updated) with the necessary IAM roles, CloudFront, API Gateway and Lambda entities to expose your Datasette instance to the web.
./tail-logs <stack-name> will watch the CloudWatch logs for the Lambda (NB: not the API Gateway) service - this can be useful for debugging runtime errors in Datasette itself.
Run ./delete-stack <stack-name> to tear down the infrastructure.
Note: AWS has a rough edge with deleting Lambda@Edge functions. You will need to run delete-stack, then wait a period of time, and run it again for the entire stack to be successfully removed. Ref: AWS docs
- Downloads from S3 should use an atomic fetch/rename to be robust against transient errors
- We should embed the DB in the Lambda package itself, when possible, to avoid the coldstart S3 fetch
- Repeated calls of update-stack should be robust against template-not-changed errors
- Fix issue with
base_urlnot always being respected in generated URLs (maybe issue in how we use Mangum?) - Be able to host multiple DBs
- Use the passed-in name of the DB as the DB name
- Create a CloudFront distribution
- Optionally be able to use a custom domain name on CloudFront
- Parity: Support CORS flag
- Parity: Support metadata flag
- Parity: Support config options
- Fix wrong absolute URLs for facets/next page (ds.absolute_url)
- Use API Gateway's faster/cheaper HTTP APIs instead of REST APIs (requires erm/mangum #94)
Maybe:
- Be able to customize the "mount" point of the CloudFront distribution
- Add support into core datasette's
publishcommand, fixing #236