ESiWACE optimization project 2020
These are notes for setting up Dales and running benchmarks by Fredrik Jansson, primarily for the ESiWACE optimization project 2020.
proposed starting branch: to4.3_Fredrik (which is planned to be released as 4.3 in the near future).
Installation notes and dependencies, for different systems: https://github.com/dalesteam/dales/wiki/Installation-notes
I have mostly used the GNU Fortran compiler. The compiler options are specified in the top level CMakeLists.txt for different setups, selected with the environment variable SYST. I mostly use the setting SYST=gnu-fast.
The Intel Fortran compiler also works well in general. Performance wise, it is close to GNU.
Please let us know where the documentation is insufficient or wrong.
Benchmark cases are provided in dales/cases/benchmark/ . See the file README.md in this directory for details of the cases.
For this project, we propose focusing on the following benchmarks:
small large notes
rico 144x144 1728x672 light physics
ruisdael 96x96 1728x672 heavier physics - more computation per grid point
GOAMAZON14 36x36 - atmospheric chemistry enabled - much more computation per grid point
consider the benchmark cases themselves to be a beta version at this point, if problems are found in them they may change.
The "small" cases run well on one core or one node, and will be good for profiling and optimizing the calculations.
The "large" cases are suitable for multiple nodes (and may not run on a single node due to the memory requirement). They are suitable for scaling tests and optimizing the MPI communication. The rico large variant scales well up to at least 144 cores on Cartesius.
The GOAMAZON14 case has atmospheric chemistry enabled, which adds a large amount of calculations per grid point. Profiling it is interesting, but we should discuss before investing effort in optimizing it.
The cases have generally been set up to run for a few minutes of wall-clock time. This can be adjusted with the variable runtime, in the namelist &RUN.
The number of MPI tasks in the x and y direction are controlled with nprocx, nprocy. These must be divisors of the total domain size itot, jtot respectively. The benchmark cases have sizes that are multiples of 2 and 3.
The domain size in x and y can easily be adjusted with itot, jtot. I suggest adjusting the domain size (xsize and ysize, in meters) as well, to keep the resolution constant. The number of cells in z is more difficult to adjust, since the input files have to match it.
The full documentation of the namelist options is here: https://github.com/dalesteam/dales/blob/master/utils/doc/input/Namoptions.pdf
For a small number of MPI tasks Ntot <= 8 it is often best to set nprocx=1, nprocy=Ntot . For larger Ntot, I generally pick nprocx and nprocy of similar size, but with nprocx < nprocy.
When running on multiple nodes, I try to make the x direction fit inside a single node, so that inter-node communication happens only in y. This means that an integer number of rows should fit in one node, or that tasks per node should be a multiple nprocx. I have not tested the impact of this rigorously.
Limited testing with AVX2 instructions enabled showed that the optimal configuration shift towards even smaller nprocx, probably because AVX2 benefits from longer vectors.
DALES expects to find its input files in the current directory.
See cases/benchmark/README.md for instructions for obtaining the files rrtmg_{lw,sw}.nc which are required when using the RRTMG radiation module.
cd work-directory
mpiexec -n <Nproc> /path/to/dales namoptions.001
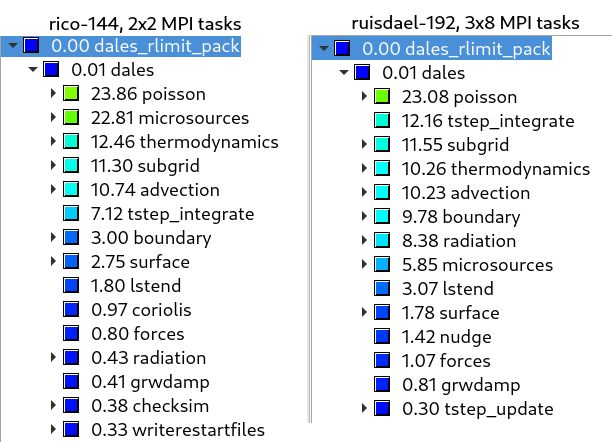
Profiling on Cartesius (version 4.2.1-108-gda3b78-dirty) by Jisk. Both cases simulated 3000 s. For both rico and ruisdael, the Poisson solver is at the top of the profile. Rico uses bulk microphysics, which takes a larger fraction of the total time than simpleice2 in Ruisdael. Radiation in ruisdael takes a surprisingly small fraction of the total time. Ruisdael spends more time in boundary, possibly because it uses higher-order advection schemes and thus has more ghost cells to exchange.