master solicitor
SPDX-License-Identifier: Apache-2.0
Today’s software projects often make use of large amounts of Open Source software. Being compliant with the license obligations of the used software components is a prerequisite for every such project. This results in different requirements that the project might need to fulfill. Those requirements can be grouped into two main categories:
-
Things that need to be done to actually fulfill license obligations
-
Things that need to be done to monitor / report fulfillment of license obligations
Most of the above activities share common points:
-
The need to have an inventory of used (open source) components and their licenses
-
Some rule based evaluation and reporting based on this inventory
While working on these easy looking tasks, they might get complex due to various aspects:
-
The number of open source components might be quite large (>> 100 for a typical webapplication based on state of the art programming frameworks)
-
Agile development and rapid changes of used components result in frequent changes of the inventory
-
Open Source usage scenarios and license obligations might be OK in one context (e.g. in the relation between a software developer and his client) but might be completely unacceptable in another context (e.g. when the client distributes the same software to end customers)
-
Legal interpretation of license conditions often differ from organization to organization and result in different compliance rules to be respected.
-
License information for components is often not available in a standardized form which would allow automatic processing
-
Tools for supporting the license management processes are often specific to a technology or build tool and do not support all aspects of OSS license management.
Of course there are specific commercial tool suites which address the IP rights and license domain. But due to high complexity and license costs those tools are out of reach for most projects - at least for permanent use.
Solicitor tries to address some of the issues highlighted above. In its initial version it is a tool for programmatically executing a process which was originally defined as an Excel-supported manual process.
When running Solicitor three subsequent processing steps are executed:
-
Creating an initial component and license inventory based on technology specific input files
-
Rule based normalization and evaluation of licenses
-
Generation of output documents
|
Warning
|
Solicitor comes with a set of sample rules for the normalization and evaluation of licenses.
Even though these included rules are not "intentionally wrong" they are only samples and you should never rely on these builtin rules without checking and possibly modifying their content and consulting your lawyer.
Solicitor is a tool for technically supporting the management of OSS licenses within your project.
Solicitor neither gives legal advice nor is a replacement for a lawyer.
|
The Solicitor code and accompanying resources (including this userguide) as stored in the GIT Repository https://github.com/devonfw/solicitor are licensed as Open Source under Apache 2 license (https://www.apache.org/licenses/LICENSE-2.0).
|
Important
|
Specifically observe the "Disclaimer of Warranty" and "Limitation of Liability" which are part of the license. |
|
Important
|
The executable JAR file which is created by the Maven based build process includes numerous other Open Source components which are subject to different Open Source licenses. Any distribution of the Solicitor executable JAR file needs to comply with the license conditions of all those components.
If you are running Solicitor from the executable JAR you might use the -eug option to store detailed license information as file solicitor_licenseinfo.html in your current working directory (together with a copy of this user guide).
|
The following picture show a business oriented view of Solicitor.

Raw data about the components and attached licenses within an application is gathered by scanning with technology and build chain specific tools. This happens outside Solicitor.
The import step reads this data and transforms it into a common technology independent internal format.
In the normalization step the license information is completed and unified. Information not contained in the raw data is added. Where possible the applicable licenses are expressed by SPDX-IDs.
Many open source components are available via multi licensing models. Within qualification the finally applicable licenses are selected.
In the legal assessment the compliance of applicable licenses will be checked based on generic rules defined in company wide policies and possibly project specific project specific extensions. Defining those rules is considered as "legal advice" and possibly needs to be done by lawyers which are authorized to do so. For this step Solicitor only provides a framework / tool to support the process here but does not deliver any predefined rules.
The final export step produces documents based on the internal data model. This might be the list of licenses to be forwarded to the customer or a license compliance report. Data might also be fed into other systems.
A more technical oriented view of Solicitor is given below.
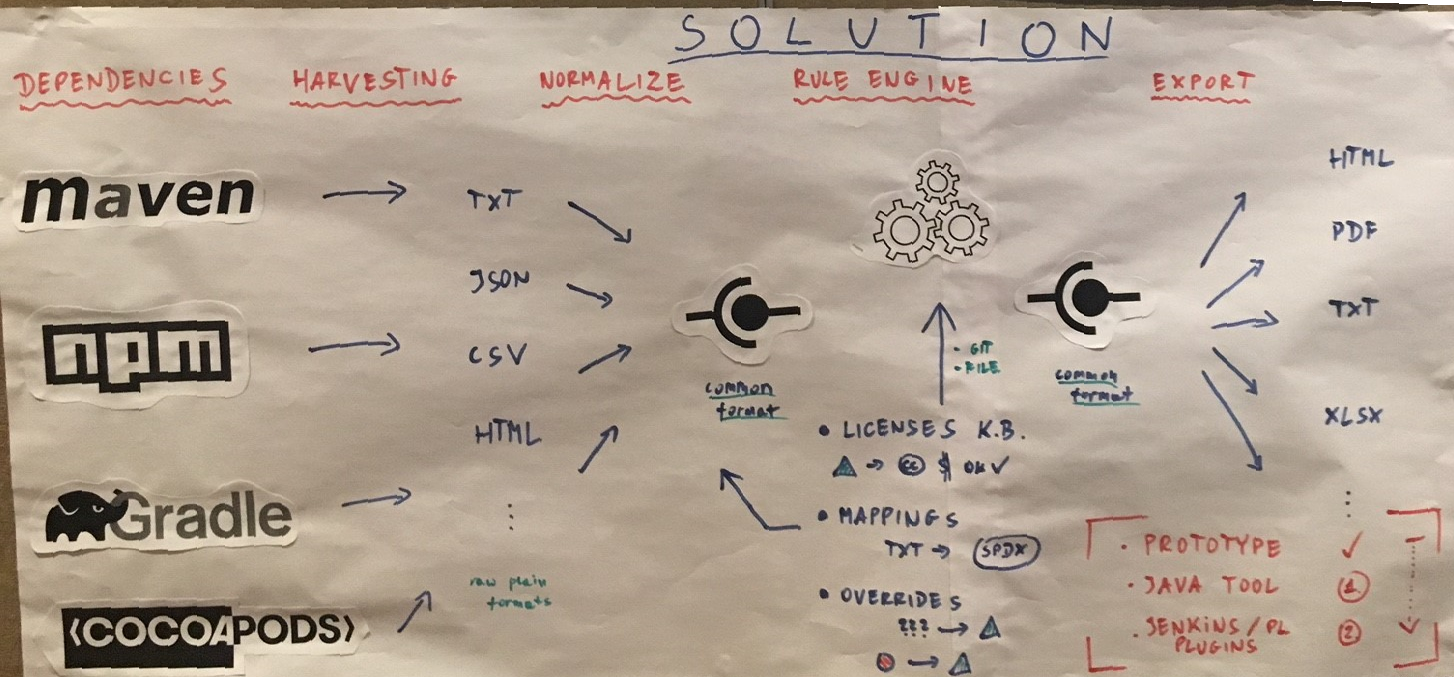
There are three major technical components: The reader and writer components are performing import and export of data. The business logic - doing normalization, qualification and legal assessment is done by a rule engine. Rules are mainly defined via decision tables. Solicitor comes with a starting set of rules for normalization and qualification but these rulesets need to be extended within the projects. Rules for legal evaluation need to be completely defined by the user.
Solicitor is working without additional persisted data: When being executed it generates the output directly from the read input data after processing the business rules.
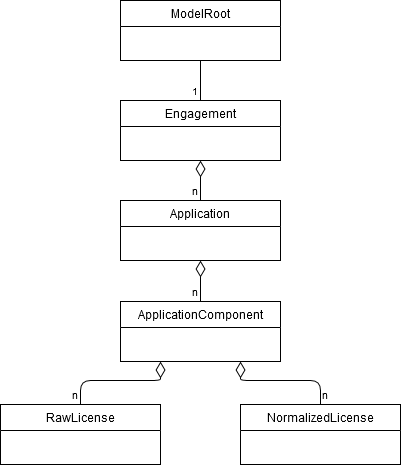
The internal business data model consists of 6 entities:
-
ModelRoot: root object of the business data model which holds metadata about the data processing -
Engagement: the masterdata of the overall project -
Application: a deliverable within theEngagement -
ApplicationComponent: component within anApplication -
RawLicense: License info attached to anApplicationComponentas it is read from the input data -
NormalizedLicense: License info attached to anApplicationComponentprocessed by the business rules
| Property | Type | Description |
|---|---|---|
modelVersion |
int |
version number of the data model |
executionTime |
String |
timestamp when the data was processed |
solicitorVersion |
String |
Solicitor version which processed the model |
solicitorGitHash |
String |
buildnumber / GitHash of the Solicitor build |
solicitorBuilddate |
String |
build date of the Solicitor build |
extensionArtifactId |
String |
artifactId of the active Solicitor Extension ("NONE" if no extension) |
extensionVersion |
String |
Version of the active Extension (or "NONE") |
extensionGitHash |
String |
Buildnumber / GitHash of the Extension (or "NONE") |
extensionBuilddate |
String |
build date of the Extension (or "NONE") |
reportingGroup |
String |
name of the reporting group currently being processed; the value is volatile/changing and is only defined when processing writers; see Reporting Groups |
| Property | Type | Description |
|---|---|---|
engagementName |
String |
the engagement name |
engagementType |
EngagementType |
the engagement type; possible values: INTERN, EXTERN |
clientName |
String |
name of the client |
goToMarketModel |
GoToMarketModel |
the go-to-market-model; possible values: LICENSE |
contractAllowsOss |
boolean |
does the contract explicitly allow OSS? |
ossPolicyFollowed |
boolean |
is the companies OSS policy followed? |
customerProvidesOss |
boolean |
does the customer provide the OSS? |
| Property | Type | Description |
|---|---|---|
applicationName |
String |
the name of the application / deliverable |
releaseId |
String |
version identifier of the application |
releaseDate |
Sting |
release data of the application |
sourceRepo |
String |
URL of the source repo of the application (should be an URL) |
programmingEcosystem |
String |
programming ecosystem (e.g. Java8; Android/Java, iOS / Objective C) |
reportingGroups |
String |
concatenated list of reporting groups this application is assigned to within Solicitor; used to create reports for subsets of Applications; see Reporting Groups |
| Property | Type | Description |
|---|---|---|
usagePattern |
UsagePattern |
possible values: DYNAMIC_LINKING, STATIC_LINKING, STANDALONE_PRODUCT |
ossModified |
boolean |
is the OSS modified? |
ossHomepage |
String |
URL of the OSS homepage |
sourceRepoUrl |
String |
URL of the Source-Code-Repo |
groupId |
String |
component identifier: maven group |
artifactId |
String |
component identifier: maven artifactId |
version |
String |
component identifier: Version |
repoType |
String |
component identifier: RepoType |
packageType |
String |
component identifier: PackageType |
packageUrl |
String |
the Package URL as an technology neutral component identifier |
noticeFileUrl |
String |
URL referencing a NOTICE file to be included in the attributions (optional, see Experimental Scancode Integration) |
noticeFileContent |
String |
resolved content of noticeFileUrl (optional, see Experimental Scancode Integration) |
copyrights |
String |
Copyright statements found in the components metadata / code (optional, see Experimental Scancode Integration) |
packageDownloadUrl |
String |
URL for downloading the component (optional, see Experimental Scancode Integration) |
sourceDownloadUrl |
String |
URL for downloading the sources of the component (optional, see Experimental Scancode Integration) |
dataStatus |
String |
Optional status of the data associated with the component. See dataStatus values of the Scancode integration for values used by the Scancode integration. Extensions (see Extending Solicitor) might use different values. |
traceabilityNotes |
String |
Optional notes for tracing the information about this component back to its origin. |
| Property | Type | Description |
|---|---|---|
declaredLicense |
String |
name of the declared license |
licenseUrl |
String |
URL of the declared license |
declaredLicenseContent |
String |
license text as provided in the input data |
trace |
String |
detail info of history of this data record |
origin |
String |
origin of the raw license data; either the lowercase classname of the Reader or "scancode" if licensedata was taken from scancode results |
specialHandling |
boolean |
(for controlling rule processing) |
| Property | Type | Description |
|---|---|---|
declaredLicense |
String |
name of the declared license (copied from RawLicense) |
licenseUrl |
String |
URL of the declared license (copied from RawLicense |
declaredLicenseContent |
String |
resolved content of licenseUrl |
normalizedLicenseType |
String |
type of the license, see License types |
normalizedLicense |
String |
name of the license in normalized form (SPDX-Id) or special "pseudo license id", see Pseudo License Ids |
normalizedLicenseUrl |
String |
URL pointing to a normalized form of the license |
normalizedLicenseContent |
String |
resolved content of normalizedLicenseUrl |
normalizedLicenseType |
String |
type of the license, see License types |
effectiveNormalizedLicenseType |
String |
type of the effective license, see License types |
effectiveNormalizedLicense |
String |
effective normalized license (SPDX-Id) or "pseudo license id"; this is the information after selecting the right license in case of multi licensing or any license override due to a component being redistributed under a different license |
effectiveNormalizedLicenseUrl |
String |
URL pointing to the effective normalized license |
effectiveNormalizedLicenseContent |
String |
resolved content of effectiveNormalizedLicenseUrl |
legalPreApproved |
String |
indicates whether the license is pre approved based on company standard policy |
copyLeft |
String |
indicates the type of copyleft of the license |
licenseCompliance |
String |
indicates if the license is compliant according to the default company policy |
licenseRefUrl |
String |
URL to the reference license information (TBD) |
licenseRefContent |
String |
resolved content of licenseRefUrl |
includeLicense |
String |
does the license require to include the license text ? |
includeSource |
String |
does the license require to deliver source code of OSS component ? |
reviewedForRelease |
String |
for which release was the legal evaluation done? |
comments |
String |
comments on the component/license (mainly as input to legal) |
legalApproved |
String |
indicates whether this usage is legally approved |
legalComments |
String |
comments from legal, possibly indicating additional conditions to be fulfilled |
trace |
String |
detail info of history of this data record (rule executions) |
guessedLicenseUrl |
String |
guessed (possibly improved) URL of the effective normalized license (deprecated) |
guessedLicenseUrlAuditInfo |
String |
audit info which documents how the guessedLicenseUrl was guessed (deprecated) |
guessedLicenseContent |
String |
resolved content of guessedLicenseUrl (deprecated) |
For the mechanism how Solicitor resolves the content of URLs and how the result might be influenced see Resolving of License URLs.
For a description of the URL guessing mechanism (deprecated) see Guessing of license URLs.
Defines the type of license
-
OSS-SPDX- An OSS license which has a corresponding SPDX-Id -
OSS-OTHER- An OSS license which has no SPDX-Id -
SCANCODE- A reference to a license represented by aLicenseRef-Id originating from Scancode. -
COMMERCIAL- Commercial (non OSS) license; this might also include code which is owned by the project -
UNKNOWN- License is unknown -
IGNORED- License will be ignored. If set onnormalizedLicenseType(andeffectiveNormalizedLicenseType) this indicates that the underlying RawLicense does not represent license information which is relevant in the given analysis. (E.g. a Contributor License Agreement might be qualified to be out of scope). If only set oneffectiveNormalizedLicenseTypethis indicates that the license does not apply here - specifically due to selecting an alternative license in a multilicensing situation.
A "normalized" license id might be either a SPDX-Id, a LicenseRef-Id or a "pseudo license id" which is used to indicate a specific situation. The following pseudo license ids are used:
-
OSS specific- a nonstandard OSS license which could not be mapped to a SPDX-Id -
PublicDomain- any form of public domain which is not represented by an explicit SPDX-Id -
Ignored- license will be ignored (see above) -
NonOSS- commercial license, not OSS
Solicitor is a standalone Java (Spring Boot) application. Prerequisite for running it is an existing Java 11 runtime environment. If you do not yet have a the Solicitor executable JAR (solicitor.jar) you need to build it as given on the project GitHub homepage https://github.com/devonfw/solicitor .
Solicitor is executed with the following command:
java -jar solicitor.jar -c <configfile>
where <configfile> is to be replaced by the location of the Project Configuration File.
To get a first idea on what Solicitor does you might call
java -jar solicitor.jar -c classpath:samples/solicitor_sample.cfg
This executes Solicitor with default configuration on it own list of internal components and produces sample output.
To get an overview of the available command line options use
java -jar solicitor.jar -h
For unique addressing of resources to be read (configuration files, input data, rule templates and decision tables) Solicitor makes use of the Spring ResourceLoader functionality, see https://docs.spring.io/spring-framework/docs/current/spring-framework-reference/core.html#resources-resourceloader . This allows to load from the classpath, the filesystem or even via http get.
If you want to reference a file in the filesystem you need to write it as follows: file:path/to/file.txt
Note that this only applies to resources being read. Output files are addressed without that prefix.
The project configuration of Solicitor is done via a configuration file in JSON format. This configuration file defines the engagements and applications master data, configures the readers for importing component and license information, references the business rules to be applied and defines the exports to be done.
The config file has the following skeleton:
{
"version" : 1,
"comment" : "Sample Solicitor configuration file",
"engagementName" : "devonfw", (1)
.
.
.
"applications" : [ ... ], (2)
"rules" : [ ... ], (3)
"writers" : [ ... ], (4)
"additionalWriters" : [ ...] (5)
}
-
The leading data defines the engagement master data, see Header and Engagement Master Data
-
applicationsdefines the applications within the engagement and configures the readers to import the component/license information, see Applications -
rulesreferences the rules to apply to the imported data, see Business Rules -
writersconfigures how the processed data should be exported, see Writers and Reporting -
additionalWritersdefines optional additional project specific writers without overwriting already defined writers, see Writers and Reporting
|
Note
|
The following section describes all sections of the Solicitor configuration file format. Often the configuration of writers and especially rules will be identical for projects. To facilitate the project specific configuration setup Solicitor internally provides a base configuration which contains reasonable defaults for the rules and writers section. If the project specific configuration file omits the rules and/or writers sections then the corresponding settings from the base configuration will be taken. For details see Default Base Configuration.
|
|
Warning
|
If locations of files are specified within the configuration files as relative
pathnames then this is always evaluated relative to the current working directory (which
might differ from the location of the configuration file). If some file location
should be given relative to the location of the configuration file this might be done
using the special placeholder ${cfgdir} as described in the following.
|
Within certain parts of the configuration file (path and filenames) special placeholders might be used to parameterize the configuration. These areas are explicitly marked in the following description.
These placeholders are available:
-
${project}- A simplified project name (taking the engagement name, removing all non-word characters and converting to lowercase). -
${cfgdir}- If the config file was loaded from the filesystem this denotes the directory where the config file resides,.otherwise. This can be used to reference locations relative to the location of the config file.
The leading section of the config file defines some metadata and the engagement master data.
"version" : 1, (1) "comment" : "Sample Solicitor configuration file", (2) "engagementName" : "devonfw", (3) "engagementType" : "INTERN", (4) "clientName" : "none", (5) "goToMarketModel" : "LICENSE", (6) "contractAllowsOss" : true, (7) "ossPolicyFollowed" : true, (8) "customerProvidesOss" : false, (9)
-
version of the config file format (currently needs to be 1)
-
is a free text comment (no further function at the moment)
-
the engagement name (any string)
-
the engagement type; possible values: INTERN, EXTERN
-
name of the client (any string)
-
the go-to-market-model; possible values: LICENSE
-
does the contract explicitly allow OSS? (boolean)
-
is the companies OSS policy followed? (boolean)
-
does the customer provide the OSS? (boolean)
Within this section the different applications (=deliverables) of the engagement are defined. Furthermore, for each application at least one reader needs to be defined which imports the component and license information.
"applications" : [ {
"name" : "Devon4J", (1)
"releaseId" : "3.1.0-SNAPSHOT", (2)
"sourceRepo" : "https://github.com/devonfw/devon4j.git", (3)
"programmingEcosystem" : "Java8", (4)
"reportingGroups" : [ (5)
"default",
"web app"
],
"readers" : [ { (6)
"type" : "maven", (7)
"source" : "classpath:samples/licenses_devon4j.xml", (8) (11)
"usagePattern" : "DYNAMIC_LINKING", (9)
"repoType" : "maven" (10)
"packageType" : "maven" (12)
} ]
} ],
-
The name of the application / deliverable (any string)
-
Version identifier of the application (any string)
-
URL of the source repo of the application (string; should be an URL)
-
programming ecosystem (any string; e.g. Java8; Android/Java, iOS / Objective C)
-
optional definition of the reporting groups this Application will be assigned to; if not defined then the Application will be assigned to the reporting group
default; see Reporting Groups -
multiple readers might be defined per application
-
the type of reader; for possible values see Reading License Information with Readers
-
location of the source file to read (ResourceLoader-URL)
-
usage pattern; possible values:
DYNAMIC_LINKING,STATIC_LINKING,STANDALONE_PRODUCT; see description below -
repoType:
repoTypeto be set in theApplicationComponent. This parameter is deprecated and should no longer be used, see List of Deprecated Features. The value ofrepoTypeinApplicationComponentwill otherwise be determined from the type info in the PackageURL of the component. -
placeholder patterns might be used here
-
packageType: type of the packages in the input data. Must be a valid packageUrl type (see https://github.com/package-url/purl-spec/blob/master/PURL-TYPES.rst). Relevant when using the CSV reader.
The usage pattern describes how the ApplicationComponents (libraries, packages) which are read in via the Reader are linked (in)to the Applications executable. The kind of linking might affect the legal evaluation of the license compliance.
-
DYNAMIC_LINKING- The component is dynamically linked and is separated/separable from the rest of the executable and might be exchanged. This specifically covers two cases:-
The component is not included in the executable but is either already existing on the target system or is deployed separately from the executable. Exchanging the component can be done by replacing the component without touching the executable / other components of the application.
-
The component is included in the executable and is linked into the executable in a way that allows it to clearly distinguish it from the other components. It is possible to separate the component from the rest of the executable and to replace the component with a modified version of the component just using common tooling.
-
-
STATIC_LINKING- The component is linked into the executable in a way that makes it (practically) impossible to separate it from the rest of the executable. In case that this single component needs to be replaced the linking process has to be re-executed based on the (unlinked) components. De facto this means that separating and/or exchanging the single components with only the executable at hand is practically impossible. -
STANDALONE_PRODUCT- The component is not linked to other components. It is executed in its own process.
|
Warning
|
The semantics of DYNAMIC_LINKING and STATIC_LINKING within Solicitor might differ from the common software engineers technical understanding of dynamic and static linking.
The main characteristics important in this context are given above.
As the legal evaluation of OSS license compliance might rely on the correct specification of the usage pattern you should consult the person being responsible for the legal evaluation if you are not sure about the right value. (Or in case that you are responsible for the legal evaluation: Make sure that the understanding of the possible usage pattern values corresponds to the legal evaluation rules you have defined.)
|
The different readers are described in chapter Reading License Information with Readers.
Business rules are executed within a Drools rule engine. They are defined as a sequence of rule templates and corresponding XLS (or CSV) files which together represent decision tables.
"rules" : [ {
"type" : "dt", (1)
"optional" : false, (2)
"ruleSource" : "classpath:samples/LicenseAssignmentV2Sample.xls", (3) (9)
"templateSource" : "classpath:com/.../rules/rule_templates/LicenseAssignmentV2.drt", (4) (9)
"ruleGroup" : "LicenseAssignmentV2", (5)
"description" : "setting license in case that no one was detected", (6)
"deprecationWarnOnly" : true, (7)
"deprecationDetails" : "This decision table should be migrated to ..." (8)
},
.
.
.
,{
"type" : "dt",
"optional" : false,
"ruleSource" : "classpath:samples/LegalEvaluationSample.xls",
"templateSource" : "classpath:com/.../rules/rule_templates/LegalEvaluation.drt",
"ruleGroup" : "LegalEvaluation",
"description" : "final legal evaluation based on the rules defined by legal"
} ],
-
type of the rule; only possible value:
dtwhich stands for "decision table" -
if set to
truethe processing of this group of rules will be skipped if the XLS/CSV with table data (given byruleSource) does not exist; if set tofalsea missing XLS/CSV table will result in program termination -
location of the tabular decision table data. This might either point directly to the XLS or CSV file or only give the resource name without suffix. In this case Solicitor will dynamically test for existing resources by appending suffixes xls and csv.
-
location of the drools rule template to be used to define the rules together with the decision table data
-
id of the group of rules; used to reference it e.g. when doing logging
-
some textual description of the rule group
-
flag to control which level of deprecation (see Feature Deprecation) applies to this rule group; optional and only applicable if
deprecationDetailsis also defined. -
optional value; if set then the use of the defined decision table is deprecated; the given string will be given as part of the log message
-
placeholder patterns might be used here
When running, Solicitor will execute the rules of each rule group separately and in the order given by the configuration. Only if there are no more rules to fire in a group Solicitor will move to the next rule group and start firing those rules.
Normally a project will only customize (part of) the data of the decision tables and thus will only change the ruleSource and the data in the XLS/CSV.
All other configuration (the different templates and processing order) is part of the Solicitor application itself and should not be changed by end users.
See Working with Decision Tables and Standard Business Rules for further information on the business rules.
The writer configuration defines how the processed data will be exported and/or reported.
"writers" : [ {
"type" : "xls", (1)
"templateSource" : "classpath:samples/Solicitor_Output_Template_Sample.xlsx", (2) (7)
"target" : "OSS-Inventory-devonfw${-reportingGroup}.xlsx", (3) (7) (8)
"description" : "The XLS OSS-Inventory document", (4)
"enableReportingGroups" : true, (5)
"dataTables" : { (6)
"ENGAGEMENT" : "classpath:com/devonfw/tools/solicitor/sql/allden_engagements.sql",
"LICENSE" : "classpath:com/devonfw/tools/solicitor/sql/allden_normalizedlicenses.sql"
}
} ]
-
type of writer to be selected; possible values:
xls,velo -
path to the template to be used
-
location of the output file
-
some textual description
-
flag which enables use of reporting groups for this writer (optional, see Reporting Groups)
-
reference to SQL statements used to transform the internal data model to data tables used for reporting
-
placeholder patterns might be used here
-
for the
targetvalue special additional placeholders are available to handle reporting group information. See Using Reporting Group Information in Report Filename.
If a writers section is defined in the project configuration then it will replace the writer configuration given in the
builtin default configuration.
If you want to just add additional project specific writers then you might define them in the (optional)
additionalWriters section of the project configuration file. These get processed
additionally to the default writers. The section additionalWriters has the same attributes as the standard writers configuration.
"additionalWriters" : [ {
"type" :
...
"dataTables" : {
...
}
} ]
For details on the writer configuration see Reporting and Creating output documents.
To simplify setting up a new project Solicitor provides an option to create a project starter configuration in a given directory.
java -jar solicitor.jar -wiz some/directory/path
Besides the necessary configuration file this includes also empty XLS or CSV files for defining project
specific rules which amend the builtin rules. Furthermore, a sample license.xml file is provided to
directly enable execution of solicitor and check functionality.
This configuration then serves as starting point for project specific configuration.
When working with Solicitor it might be necessary to get access to the builtin base configuration, e.g. for reviewing the builtin sample rules or using builtin reporting templates as starting point for the creation of own templates.
The command
java -jar solicitor.jar -ec some/directory/path
will export all internal configuration to the given directory. This includes:
-
The base configuration file, which defines standard settings inherited by the Project Configuration File
-
The Drools Rule Templates
-
The builtin decision tables which are referenced in the base configuration, see Standard Business Rules
-
The SQL statements which are used for SQL transformation and filtering
-
The referenced templates for the Velocity Writer and Excel Writer
Besides the project configuration done via the above described file there are a set of technical settings in Solicitor which are done via properties. Solicitor is implemented as a Spring Boot Application and makes use of the standard configuration mechanism provided by the Spring Boot Platform which provides several ways to define/override properties.
The default property values are given in Built in Default Properties.
In case that a property shall be overridden when executing Solicitor this can easiest be done via the command line when executing Solicitor. In case that the property value contains whitespaces it needs to be enclosed in double quotes:
java -Dsome.property.name1=value -Dsome.property.name2="another value with spaces" -jar solicitor.jar <any other arguments>
Different Readers are available to import raw component / license information for different technologies. This chapter describes how to setup the different build / dependency management systems to create the required input and how to configure the corresponding reader.
For the export of the licenses from a maven based project the license-maven-plugin is used, which can directly be called without the need to change anything in the pom.xml.
To generate the input file required for Solicitor the License Plugin needs to be executed with the following command:
mvn org.codehaus.mojo:license-maven-plugin:1.14:aggregate-download-licenses -Dlicense.excludedScopes=test,provided
The generated output file named licenses.xml (in the directory specified in the
plugin config) should look like the following:
link:files/licenses.xml[role=include]
In Solicitor the data is read with the following reader config:
"readers" : [ {
"type" : "maven",
"source" : "file:target/generated-resouces/licenses.xml",
"usagePattern" : "DYNAMIC_LINKING"
} ]
(the above assumes that Solicitor is executed in the maven projects main directory)
The CSV input is normally manually generated and should look like this:
link:files/csvlicenses.csv[role=include]In Solicitor the data is read with the following part of the config
"readers" : [ {
"type" : "csv",
"source" : "file:path/to/the/file.csv",
"usagePattern" : "DYNAMIC_LINKING",
"packageType": "maven"
} ]
The following 5 columns need to be contained in order (separated with ";"):
-
groupId
-
artifactId
-
version
-
license name
-
license URL
Additionally, an optional configuration can be set in order to customize the given structure of the csv file e.g.:
"readers" : [ {
"type" : "csv",
"source" : "file:path/to/the/file.csv",
"usagePattern" : "DYNAMIC_LINKING",
"configuration" : {
"charset" = "UTF-8",
"artifactId" : "0",
"version" : "1",
"format" : "EXCEL",
"skipHeaderRecord" : "true",
"delimiter" : ";"
}
} ]
The minimum of following 2 configuration settings need to be contained:
-
artifactId
-
version
With these settings one can specify the position of the value within the csv file. Additional positional settings include:
-
groupId
-
license
-
licenseUrl
If a charset needs to be specified, one can use the following option:
-
charset (string, specified charset for reader e.g. UTF-8)
Furthermore, one can configure a range of other csv structure options based on the Apache Commons CSV API:
-
allowDuplicateHeaderNames (boolean)
-
allowMissingColumnNames (boolean)
-
autoFlush (boolean)
-
commentMarker (char)
-
delimiter (string)
-
escape (char)
-
ignoreEmptyLines (boolean)
-
ignoreHeaderCase (boolean)
-
ignoreSurroundingSpaces (boolean)
-
nullString (string)
-
quote (char)
-
recordSeparator (string)
-
skipHeaderRecord (boolean)
-
trailingDelimiter (boolean)
-
trim (boolean)
These configurations may also be used to overwrite options of a predefined format, which can be set with:
-
format (string, predefined format e.g. EXCEL)
Important: In case that a component has multiple licenses attached, there needs to be a separate line in the csv file for each license.
For NPM based projects, the NPM License Checker (https://www.npmjs.com/package/license-checker) plugin can be used. The NPM License Crawler plugin is deprecated.
To install the NPM License Checker the following command needs to be executed.
npm i license-checker -g
To get the licenses, the checker needs to be executed like the following example. We require JSON output here with "--json" and developer dependencies can/should be excluded with "--production".
license-checker --production --json > /path/to/licenses.json
The export should look like the following
link:files/licensesNpmLicenseChecker.json[role=include]In Solicitor the data is read with the following part of the config
"readers" : [ {
"type" : "npm-license-checker",
"source" : "file:path/to/licenses.json",
"usagePattern" : "STATIC_LINKING"
} ]
|
Warning
|
This reader is deprecated and should no longer be used. It requires a specific dependency (license-checker) which is not available on official npm repositories anymore and scans additional developer dependencies. Use NPM License Checker (with --production option) instead. See List of Deprecated Features. |
To install the NPM License Crawler the following command needs to be executed.
npm i npm-license-crawler -g
To get the licenses, the crawler needs to be executed like the following example
npm-license-crawler --dependencies --csv licenses.csv
The export should look like the following (The csv file is "," separated)
link:files/licenses.csv[role=include]In Solicitor the data is read with the following part of the config
"readers" : [ {
"type" : "npm-license-crawler-csv",
"source" : "file:path/to/licenses.csv",
"usagePattern" : "STATIC_LINKING"
} ]
To generate the input file required for Solicitor, yarn needs to be executed with the following command within the directory that contains the project’s package.json (we require JSON output here):
yarn licenses list --json > /path/to/yarnlicenses.json
The export should look like the following
link:files/yarnlicenses.json[role=include]In Solicitor the data is read with the following part of the config
"readers" : [ {
"type" : "yarn",
"source" : "file:path/to/yarnlicenses.json",
"usagePattern" : "STATIC_LINKING"
} ]
In Yarn Modern the functionality to create a licenses report can be achieved with a separate component: https://github.com/mhassan1/yarn-plugin-licenses
To generate the input file required for Solicitor, the plugin needs to be executed with the following command within the directory that contains the project’s package.json (we require JSON output here):
yarn licenses list --production --recursive --json > /path/to/yarnmodernlicenses.json
The export should look like the following
link:files/yarnmodernlicenses.json[role=include]In Solicitor the data is read with the following part of the config
"readers" : [ {
"type" : "yarn-modern",
"source" : "file:path/to/yarnmodernlicenses.json",
"usagePattern" : "STATIC_LINKING"
} ]
To generate the input file required for Solicitor, one has to follow two steps:
-
Capsulate software with all relevant dependencies/requirements in a virtual environment (venv)
-
Install the pip-licenses plugin within this virtual environment
After that, we execute following command within the virtual environment to extract the input file (we require JSON output here):
pip-licenses --from=all --format=json --with-urls --with-license-file > piplicenses.json
The export should look like the following
link:files/piplicenses.json[role=include]In Solicitor the data is read with the following part of the config
"readers" : [ {
"type" : "pip",
"source" : "file:path/to/piplicenses.json",
"usagePattern" : "DYNAMIC_LINKING"
} ]
In order to use the analyzer library of ORT, one must first install the software and run it to generate the result file. The detailed way on installing ORT can be found here and a tutorial on how to run the analyzer library can be found here.
Usually, the command to run the analyzer and get extract the result file from a project looks like this:
docker run -v C:\\path\\to\\project/:/project ort --info analyze -f JSON -i /project -o /project/ort/analyzer
Note that this command only works for the installation via Docker and that we require JSON as the output format. For other installation methods, you need to adjust the command accordingly.
It might also be necessary to set up a customized configuration for the analyzer. This can be achieved through a configuration file. The default path for that is the .ort/config/ directory below the current user’s home directory. We can place a ort.conf file there, in which we can declare various configurations e.g. allowing dynamic versions in npm components via
analyzer {
allowDynamicVersions = true
}
Further information about the configuration file can be found here.
The result file should look like the following
link:files/analyzer-result.json[role=include]In Solicitor the data is read with the following part of the config
"readers" : [ {
"type" : "ort",
"source" : "file:path/to/analyzer-result.json",
"usagePattern" : "DYNAMIC_LINKING"
} ]
|
Warning
|
The ORT reader currently does not yet fill the attribute licenseUrl. Any functionality/reporting based on this attribute will be disfunctional for data read by the ORT reader.
|
For Gradle two alternative plugins exist to create input data for Solicitor:
-
Gradle License Report
-
Gradle License Plugin (usage of this plugin with Solicitor is discouraged and deprecated)
Pick the correct version of the Gradle License Report plugin depending on your Gradle version. Add the plugin to the list of plugins in your build.gradle file:
Gradle v7+:
plugins {
id 'com.github.jk1.dependency-license-report' version '2.9'
}
Gradle v1.x to v6.x:
plugins {
id 'com.github.jk1.dependency-license-report' version '1.17'
}
Add also the following to the build.gradle file to configure the plugin:
import com.github.jk1.license.render.*
licenseReport {
configurations = ['runtimeClasspath', 'releaseRuntimeClasspath']
renderers = [new JsonReportRenderer('dependencies.json', false)]
}
Execute the plugin:
gradle generateLicenseReport
The report is stored at $projectfolder/build/reports/dependency-license/dependencies.json and should look like this:
link:files/gradleLicenseReport.json[role=include]
In Solicitor the Data is read with the following part of the config
"readers" : [ {
"type" : ""type" : "gradle-license-report-json",",
"source" : "file:$/input/dependencies.json",
"usagePattern" : "DYNAMIC_LINKING"
} ]
|
Warning
|
The Gradle License Plugin does not include dependencies into the result if they have no license info declared. This might result in incomplete data in the Solicitor output. The usage of this plugin is therefore discouraged and the 'gradle2' reader is deprecated (stage 2). Use the Gradle License Report instead. |
For the export of the licenses from a Gradle based project the Gradle License Plugin might be used.
To install the plugin some changes need to be done in build.gradle, like following example
buildscript {
repositories {
maven { url 'https://oss.jfrog.org/artifactory/oss-snapshot-local/' }
}
dependencies {
classpath 'com.jaredsburrows:gradle-license-plugin:0.8.5-SNAPSHOT'
}
}
apply plugin: 'java-library'
apply plugin: 'com.jaredsburrows.license'
Afterwards execute the following command in the console:
For Windows (Java Application)
gradlew licenseReport
The Export should look like this:
link:files/licenses.json[role=include]
In Solicitor the data is read with the following part of the config
"readers" : [ {
"type" : "gradle2",
"source" : "file:path/to/licenses.json",
"usagePattern" : "DYNAMIC_LINKING"
} ]
|
Warning
|
The Gradle License Plugin does not include dependencies into the result if they have no license info declared. This might result in incomplete data in the Solicitor output. The usage of this plugin is therefore discouraged and the 'gradle2' reader is deprecated (stage 2). Use the Gradle License Report instead. |
For the export of the the Licenses from a Gradle based Android Projects the Gradle License Plugin might be used.
To install the Plugin some changes need to be done in the build.gradle of the Project, like following example
buildscript {
repositories {
jcenter()
}
dependencies {
classpath 'com.jaredsburrows:gradle-license-plugin:0.8.5'
}
}
Also there is a change in the build.gradle of the App. Add the line in the second line
apply plugin: 'com.android.application'
Afterwards execute the following command in the Terminal of Android studio: For Windows(Android Application)
gradlew licenseDebugReport
The Export is in the following folder
$Projectfolder\app\build\reports\licenses
It should look like this:
link:files/licenseDebugReport.json[role=include]
In Solicitor the Data is read with the following part of the config
"readers" : [ {
"type" : "gradle2",
"source" : "file:$/input/licenses.json",
"usagePattern" : "DYNAMIC_LINKING"
} ]
The CycloneDX reader can read SBOMs in CycloneDX 1.4 or 1.5 format (https://cyclonedx.org/specification/overview/). CDXGEN (https://github.com/CycloneDX/cdxgen) is one tool which can create an SBOM in the required format.
To install CDXGEN, the following command needs to be executed.
sudo npm install -g @cyclonedx/cdxgen
To run CDXGEN, change into the project directory containing the build file (i.e. pom.xml, package.json). For npm projects, execute "npm-install" before running CDXGEN to create a package-lock.json.
Set the FETCH_LICENSE environmental variable, to fetch the declared licenses.
export FETCH_LICENSE=true
Then execute the following command:
cdxgen -o sbom.json
The export should look like the following
link:files/sbom.json[]
In Solicitor, the data is read with the following part of the config
"readers" : [ {
"type" : "cyclonedx",
"source" : "file:$/input/sbom.json",
"usagePattern" : "DYNAMIC_LINKING"
} ]
|
Note
|
Currently, Solicitor only has packageUrlHandlers for maven, npm, R and pip. For all other package types, some functionality (like determining URLs for downloading the package archive and corresponding source archives) will be unavailable. |
Solicitor uses the Drools rule engine to execute business rules. Business rules are defined as "extended" decision tables. Each such decision table consists of two artifacts:
-
A rule template file in specific drools template format
-
An Excel 97 (XLS) table or CSV table which defines the decision table data.
When processing, Solicitor will internally use the rule template to create one or multiple rules for every record found in the Excel (or CSV) sheet. The following points are important here:
-
Rule templates:
-
Rule templates should be regarded as part of the Solicitor implementation and should not be changed on an engagement level.
-
-
Excel decision table data
-
The file needs to be in Excel 97 format. File suffix needs to be xls.
-
The Excel tables might be extended or changed on a per project level.
-
The rules defined by the tabular data will have decreasing "salience" (priority) from top to bottom
-
In general multiple rules defined within a table might fire for the same data to be processed; the definition of the rules within the rule template will normally ensure that once a rule from the decision table was processed no other rule from that table will be processed for the same data
-
The excel tables contain header information in the first row which is only there for documentation purposes; the first row is completely ignored when creating rules from the xls
-
The rows starting from the second row contain decision table data
-
The first "empty" row (which does not contain data in any of the defined columns) ends the decision table
-
Decision tables might use multiple condition columns which define the data that a rule matches. Often such conditions are optional: If left free in the Excel table the condition will be omitted from the rule conditions. This allows to define very specific rules (which only fire on exact data patterns) or quite general rules which get activated on large groups of data. Defining general rules further down in the table (with lower salience/priority) ensures that more specific rules get fired earlier. This even allows to define a default rule at the end of the table which gets fired if no other rule could be applied.
-
-
CSV decision table data
-
The file suffix needs to be csv.
-
The same points as for the Excel decision table data apply here.
-
The CSV has to use a comma as delimiter.
-
All values in the CSV need to be surrounded by double quotation marks to escape the comma character.
-
-
rule groups: Business rules are executed within groups. All rules resulting from a single decision table are assigned to the same rule group. The order of execution of the rule groups is defined by the sequence of declaration in the config file. Processing of the current group will be finished when there are no more rules to fire in that group. Processing of the next group will then start. Rule groups which have been finished processing will not be resumed even if rules within that group might have been activated again due to changes of the facts.
By default any conditions given in the fields of decision tables are simple textual comparisons: The condition is true if the property of the model is identical to the given value in the XLS (or CSV) sheet.
Depending on the configuration of the rule templates for some fields, an extended syntax might be available. For those fields the following syntax applies:
-
If the given value of the XLS (or CSV) field starts with the prefix
NOT:then the outcome of the remaining condition is logically negated, i.e. this field condition istrueif the rest of the condition is NOT fulfilled. -
A suffix of
(REGEX)indicates that the remainder of the field defines a Java Regular Expression. For the condition to become true the whole property needs to match the given regular expression. -
The prefix
RANGE:indicates that the remainder of the field defines a Maven Version Range. Using this makes only sense on the artifact version property. -
If no such prefix is detected, then the behavior is identical to the normal (verbatim) comparison logic
Fields which are subject to this extended syntax are marked explicitly in the following section.
|
Note
|
The former prefix notation of REGEX: is deprecated and should no longer be used. See List of Deprecated Features.
|
The processing of business rules is organized in different phases. Each phase might consist of multiple decision tables to be processed in order.
In this phase the license data imported via the readers is cleaned and normalized. At the end of this phase the internal data model should clearly represent all components and their assigned licenses in normalized form.
The phase itself consists of two decision tables / rule groups:
With this decision table is is possible to explicitly assign NormalizedLicenses to components. This will be used if the imported RawLicense data is either incomplete or incorrect. Items which have been processed by rules of this group will not be reprocessed by the next rule group.
Decision table data: LicenseAssignmentV2*.xls/csv
-
LHS conditions:
-
Engagement.clientName -
Engagement.engagementName -
Application.applicationName -
ApplicationComponent.groupId[magic] -
ApplicationComponent.artifactId[magic] -
ApplicationComponent.version[magic] -
RawLicense.origin[magic] (new with "V2" version of rules) -
RawLicense.declaredLicense[magic] -
RawLicense.url[magic]
-
-
RHS result:
-
NormalizedLicense.normalizedLicenseType -
NormalizedLicense.normalizedLicense -
NormalizedLicense.normalizedLicenseUrl -
NormalizedLicense.comment
-
[magic]: On these fields the Extended comparison syntax might be used
All RawLicenses which are in scope of fired rules will be marked so that they do not get reprocessed by the following decision table.
|
Note
|
With the "V2" version of rules the additional field/condition origin was introduced.
This can be used to fire rules only if the raw license data was obtained from a specific data source.
Its primary intention is to distinguish between data obtained via normal readers or from Scancode data.
Decision table data for the new data structure is named LicenseAssignmentV2*.xls/csv.
The old decision table structure LicenseAssignment*.xls/csv is deprecated but for compatibility reasons still supported.
|
With this decision table the license info from the RawLicense is mapped to the NormalizedLicense. This is based on the name and/or URL of the license as imported via the readers.
Decision table data: LicenseNameMapping*.xls/csv
-
LHS conditions:
-
RawLicense.declaredLicense[magic] -
RawLicense.url[magic]
-
-
RHS result:
-
NormalizedLicense.normalizedLicenseType -
NormalizedLicense.normalizedLicense
-
[magic]: On these fields the Extended comparison syntax might be used
Within this phase the actually applicable licenses will be selected for each component.
This phase consists of two decision tables.
This group of rules has the specialty that it might match to a group of NormalizedLicenses associated to an ApplicationComponent. In case that multiple licenses are associated to an ApplicationComponent one of them might be selected as "effective" license and the others might be marked as Ignored.
Decision table data: MultiLicenseSelection*.xls/csv
-
LHS conditions:
-
ApplicationComponent.groupId[magic] -
ApplicationComponent.artifactId[magic] -
ApplicationComponent.version[magic] -
NormalizedLicense.normalizedLicense(licenseToTake; mandatory) -
NormalizedLicense.normalizedLicense(licenseToIgnore1; mandatory) -
NormalizedLicense.normalizedLicense(licenseToIgnore2; optional) -
NormalizedLicense.normalizedLicense(licenseToIgnore3; optional)
-
-
RHS result
-
licenses matching "licenseToIgnoreN" will get
IGNOREDassigned toeffectiveNormalizedLicenseTypeIgnoredassigned toeffectiveNormalizedLicense
-
[magic]: On these fields the Extended comparison syntax might be used
It is important to note that the rules only match, if all licenses given in the conditions actually exist and are assigned to the same ApplicationComponent.
The second decision table in this group is used to define the effectiveNormalizedLicense (if not already handled by the decision table before).
Decision table data: LicenseSelection*.xls/csv
-
LHS conditions:
-
ApplicationComponent.groupId[magic] -
ApplicationComponent.artifactId[magic] -
ApplicationComponent.version[magic] -
NormalizedLicense.normalizedLicenseType -
NormalizedLicense.normalizedLicense
-
-
RHS result:
-
NormalizedLicense.effectiveNormalizedLicenseType(if empty in the decision table then the value ofnormalizedLicenseTypewill be taken) -
NormalizedLicense.effectiveNormalizedLicense(if empty in the decision table then the value ofnormalizedLicensewill be taken) -
NormalizedLicense.effectiveNormalizedLicenseUrl(if empty in the decision table then the value ofnormalizedLicenseUrlwill be taken)
-
[magic]: On these fields the Extended comparison syntax might be used
The third phase is the legal evaluation of the licenses and the check, whether OSS usage is according to defined legal policies. Again this phase comprises two decision tables.
Within the pre evaluation the license info is checked against standard OSS usage policies. This roughly qualifies the usage and might already determine licenses which are OK in any case or which need to be further evaluated. Furthermore, they qualify whether the license text or source code needs to be included in the distribution. The rules in this decision table are only based on the effectiveNormalizedLicense and do not consider any project, application of component information.
Decision table data: LegalPreEvaluation*.xls/csv
-
LHS condition:
-
NormalizedLicense.effectiveNormalizedLicenseType -
NormalizedLicense.effectiveNormalizedLicense
-
-
RHS result:
-
NormalizedLicense.legalPreApproved -
NormalizedLicense.copyLeft -
NormalizedLicense.licenseCompliance -
NormalizedLicense.licenseRefUrl -
NormalizedLicense.includeLicense -
NormalizedLicense.includeSource
-
The decision table for final legal evaluation defines all rules which are needed to create the result of the legal evaluation. Rules here might be general for all projects or even very specific to a project if the rule can not be applied to other projects.
Decision table data: LegalEvaluation*.xls/csv
-
LHS condition:
-
Engagement.clientName -
Engagement.engagementName -
Engagement.customerProvidesOss -
Application.applicationName -
ApplicationComponent.groupId[magic] -
ApplicationComponent.artifactId[magic] -
ApplicationComponent.version[magic] -
ApplicationComponent.usagePattern -
ApplicationComponent.ossModified -
NormalizedLicense.effectiveNormalizedLicenseType -
NormalizedLicense.effectiveNormalizedLicense
-
-
RHS result:
-
NormalizedLicense.legalApproved -
NormalizedLicense.legalComments
-
[magic]: On these fields the Extended comparison syntax might be used
The standard process as described before consists of 6 decision tables / rule groups to be processed in sequence. When using the builtin default base configuration all those decision tables use the internal sample data / rules as contained in Solicitor.
To use your own rule data there are three approaches:
-
Include your own
rulessection in the project configuration file (so not inheriting from the builtin base configuration file) and reference your own decision tables there. -
Create your own "Solicitor Extension" which might completely redefine/replace the builtin
Solicitorsetup including all decision tables and the base configuration file. See Extending Solicitor for details. -
Make use of the optional project specific decision tables which are defined in the default base configuration: For every builtin decision table there is an optional external decision table (expected in the filesystem) which will be checked for existence. If such external decision table exists it will be processed first - before processing the builtin decision table. Thus is it possible to amend / override the builtin rules by project specific rules. When you create the starter configuration of your project as described in Starting a new project, those project specific decision tables are automatically created.
After applying the business rules the resulting data can can be used to create reports and other output documents.
Creating such reports consists of three steps:
-
transform and filter the model data by using an embedded SQL database
-
determining difference to previously stored model (optional)
-
Template based reporting via
-
Velocity templates (for textual output like e.g. HTML)
-
Excel templates
-
After the business rules have been processed (or a Solicitor data model has been loaded via
command line option -l) the model data is stored in a dynamically created internal SQL database.
-
For each type of model object a separate table is created. The tablename is the name of model object type written in uppercase characters. (E.g. type
NormalizedLicensestored in tableNORMALIZEDLICENSE) -
All properties of the model objects are stored as strings in fields named like the properties within the database table. Field names are case sensitive (see note below for handling this in SQL statements).
-
An additional primary key is defined for each table, named
ID_<TABLENAME>. -
For all model elements that belong to some parent in the object hierarchy (i.e. all objects except
ModelRoot) a foreign key field is added namedPARENT_<TABLENAME>which contains the unique key of the corresponding parent
Each Writer configuration (see Writers and Reporting) includes a section which references SQL select statements that are applied on the database data. The result of the SQL select statements is made accessible for the subsequent processing of the Writer via the dataTable name given in the configuration.
Before the result of the SQL select statement is handed over to the Writer the following postprocessing is done:
-
a
rowCountcolumn is added to the result which gives the position of the entry in the result set (starting with 1). -
Columns named
ID_<TABLENAME>are replaced with columns namedOBJ_<TABLENAME>. The fields of those columns are filled with the corresponding original model objects (java objects).
|
Warning
|
The result table column OBJ_<TABLENAME> gives access to the native Solicitor data model (java objects), e.g. in the Velocity writer. As this breaks the decoupling done via the SQL database using this feature is explicitly discouraged. It should only be used with high caution and in exceptional situations. The feature might be discontinued in future versions without prior notice.
|
When using the command line option -d Solicitor can determine difference information between two different data models (e.g. the difference between the licenses of the current release and a former release.) The difference is calculated on the result of the above described SQL statements:
-
First the internal reporting database is created for the current data model and all defined SQL statements are executed
-
Then the internal database is recreated for the "old" data model and all defined SQL statements are executed again
-
Finally for each defined result table the difference between the current result and the "old" result is calculated
To correctly correlate corresponding rows of the two different versions of table data it is necessary to define explicit correlation keys for each table in the SQL select statement.
It is possible to define up to 10 correlation keys named CORR_KEY_X with X in the range from 0 to 9. CORR_KEY_0 has highest priority, CORR_KEY_9 has lowest priority.
The correlation algorithm will first try to match rows using CORR_KEY_0. It will then attempt to correlate unmatched rows using CORR_KEY_1 e.t.c.. Correlation will stop, when
-
all correlations keys
CORR_KEY_0toCORR_KEY_9have been processed OR -
the required correlation key column does not exist in the SQL select result OR
-
there are no unmatched "new" rows OR
-
there are no unmatched "old" rows
The result of the correlation / difference calculation is stored in the reporting table data structure. For each row the status is accessible if
-
The row is "new" (did not exist in the old data)
-
The row is unchanged (no changes in the field values representing the properties of the Solicitor data model)
-
The row is changed (at least one field corresponding to the Solicitor data model changed)
For each field of "changed" or "unchanged" rows the following status is available:
-
Field is "changed"
-
Field is "unchanged"
For each field of such rows it is further on possible to access the new and the old field value.
The following shows a sample SQL statement showing some join over multiple tables and the use of correlations keys.
link:files/allden_normalizedlicenses.sql[role=include]|
Note
|
Above example also shows how the case sensitive column names have to be handled within the SQL |
|
Note
|
The handling of reporting groups as included in the above statement (a."reportingGroups" LIKE '%#reportingGroup#%') is described in Evaluation of the Reporting Group in SQL.
|
The above described SQL processing is identical for all Writers. Writers only differ in the way how the output document is created based on a template and the reporting table data obtained by the SQL transformation.
The Velocity Writer uses the Apache Velocity Templating Engine to create text based reports. The reporting data tables created by the SQL transformation are directly put to the into Velocity Context.
For further information see the
-
Velocity Documentation
-
The Solicitor JavaDoc (which also includes details on how to access the diff information for rows and fields of reporting data tables)
-
The samples included in Solicitor
Within Excel spreadsheet templates there are two kinds of placeholders / markers possible, which control the processing:
The templating logic searches within the XLSX workbook for fields containing the names of the reporting data tables as defined in the Writer configuration like e.g.:
-
#ENGAGEMENT# -
#LICENSE#
Whenever such a string is found in a cell this indicates that this row is a template row. For each entry in the respective resporting data table a copy of this row is created and the attribute replacement will be done with the data from that reporting table. (The pattern #…# will be removed when copying.)
Within each row which was copied in the previous step the templating logic searches for the string pattern $someAttributeName$ where someAttributeName corresponds to the column names of the reporting table. Any such occurrence is replaced with the corresponding data value.
In case that a difference processing (new vs. old model data) was done this will be represented as follows when using the XLS templating:
-
For rows that are "new" (so no corresponding old row available) an Excel note indicating that this row is new will be attached to the field that contained the
#…#placeholder. -
Fields in non-new rows that have changed their value will be marked with an Excel note indicating the old value.
The Generic Excel Writer exists purely for debugging purposes. This writer writes the contents of the dataTables defined in the writer configuration to an Excel file. Each dataTable will be available in a separate Excel sheet. To use this writer, an additionalWriter (see Writers and Reporting ) needs to be set in the solicitor.cfg. Example:
"additionalWriters" : [ {
"type" : "genericxls",
"templateSource" : "", (1)
"target" : "${cfgdir}/output/GenericXLS.xlsx",
"description" : "Excel workbook with a separate sheet for each defined dataTable",
"dataTables" : {
"ENGAGEMENT" : "classpath:com/devonfw/tools/solicitor/sql/allden_engagements.sql",
"APPLICATIONCOMPONENT" : "classpath:com/devonfw/tools/solicitor/sql/allden_applicationcomponents.sql",
"LICENSE" : "classpath:com/devonfw/tools/solicitor/sql/allden_normalizedlicenses.sql",
"OSSLICENSES" : "classpath:com/devonfw/tools/solicitor/sql/ossapplicationcomponents.sql",
...
}
} ]
-
This is unused and can be left empty.
Reporting Groups is an advanced reporting feature which might be used to create reports for defined subsets of the Applications defined in the project configuration. This might be useful if e.g. separate and dedicated attribution documents need to be created for some of the applications which might then be included into each of those applications.
Without any dedicated configuration each Application is assigned to the reporting group default. Each defined report (defined in the writers or additionalWriters section of the configuration) will then be written for the default reporting group. The templating mechanism for determining the reports target file includes some special handling so that the reporting group name default is not propagated to the final filename. Overall the introduction of the feature "Reporting Groups" (with Solicitor 1.28.0) does not change any report output unless reporting groups are explicitly defined.
Reporting groups are implicitly created by assigning Applications to them. So in case that an Application
shall be assigned to reporting groups default and web app then an additional reportingGroups node has to be defined within the configuration of the Application, see the configuration example in Applications. Note that in this case it is also required to explicitly include the default reporting group if the Application shall be assigned to it.
Reporting Group names might only consist of US-ASCII uppercase (A-Z) and lowercase characters (a-z), digits (0-9), hyphens ("-"), underscores ("_") and spaces (" "). The name must start with an alphanumeric character.
Due to compatibility reasons with prior Solicitor configurations it is required to explicitly enable support for reporting groups for each configured writer/report. This is done by setting property enableReportingGroups to true in the configuration as shown in the configuration snippet in Writers and Reporting.
|
Note
|
All writers/reports which are predefined in the Solicitor base configuration are enabled for reporting groups. |
Besides enabling/activating the reporting group feature within the writer configuration it is also required to adopt the SQL statements and target filename pattern to support reporting groups as given in the following.
Reporting groups are used to write reports for a subset of the defined Applications or even for single Applications. To do so it is normally required to include specific selection criteria into the SQL statements which limit the selected data to only those Applications which belong to the reporting group currently processed. To enable this the Application entity includes the field reportingGroups which stores the list of reporting groups this Application is assigned to. The list is stored as concatenated string, where # is used as prefix, suffix and delimiter, which results in #default#wepp app# in the above case.
Within the WHERE clause of the SQL statement the following snippet can be used to limit the selection of data to only those Applications which belong to the currently processed reporting group (see Sample SQL statement for the complete sample).
a."reportingGroups" LIKE '%#reportingGroup#%'`
Writers/Reports which are enabled for reporting group processing will replace any occurrence of #reportingGroup# in the SQL with the current value of the reporting group (resulting in #default# and #web app# in the above example). Writers where the reporting group processing is not enabled will replace #reportingGroup# with #default#.
|
Note
|
All SQL statements which are included in the Solicitor built in configuration are supporting reporting groups. |
If writing the same report for different reporting groups it is required to control the target filename depending on the reporting group being processed. To support this a set of special placeholders is available for the target property of the writer configuration if the writer is enabled for reporting groups (see also sample in Writers and Reporting).
| Placeholder | Replacement for reporting group default
|
Replacement for other reporting groups (using web app as sample value); spaces in the reporting group name will be repaced by "_") |
|---|---|---|
|
empty String |
|
|
empty String |
|
|
empty String |
|
|
empty String |
|
These placeholders allow to include the reporting groups name also with leading hyphen, underscore or slash, which will be omitted in case of the "default" reporting group. This enables to preserve the prior naming scheme for the "default" reporting group. It also allows to store the report of non default reporting groups to dedicated subdirectories.
The reporting group currently being processed is accessible via the property reportingGroup of entity ModelRoot, see ModelRoot.
When defining and processing additional reporting groups the execution time of Solicitor increases as well as the number of generated report files. Often it not required or desired to always create reports for all reporting groups. The application property solicitor.reportinggroups.filterpattern is used to define a (java) regular expression pattern which must be matched by the name of a reporting group for this reporting group to be processed. The default is
solicitor.reportinggroups.filterpattern=.*
which matches any processing group. In the above sample this might e.g. be changed to
solicitor.reportinggroups.filterpattern=web app
to only generate reports of this reporting group. The property might also be defined on command line (see Configuration of Technical Properties) to change it for a single execution of Solicitor.
The below given excerpt from a project configuration file illustrates the interaction of writer configurations and reporting group definitions of Applications.
{
.
.
.
"applications" : [ (1)
{
"name" : "App1",
"reportingGroups" : [
"deliverableA",
"web app"
]
},{
"name" : "App2",
"reportingGroups" : [
"default",
"deliverableA",
"backend"
]
},{
"name" : "App3" (2)
}
],
.
.
.
"additionalWriters" : [ (1) (3)
{
"target" : "out${/reportingGroup}/report1${-reportingGroup}.txt",
"enableReportingGroups" : true
},{
"target" : "out/report2.txt" (4)
}
]
}
-
parameters which might be required but are not relevant for the sample are omitted here
-
no reporting groups defined here
-
this sample makes use of the
additionalWriterssection; same applies forwriters. -
enableReportingGroupsnot set here
The following table shows the reporting groups and corresponding application assignments resulting from this configuration:
default |
deliverableA |
web app |
backend |
|
App1 |
X |
X |
||
App2 |
X |
X |
X |
|
App3 |
X |
Assuming the setting
solicitor.reportinggroups.filterpattern=default|deliverableA|backend
the following reports will be created:
| Reporting Group | Report File | Applications contained in Report |
|---|---|---|
default |
out/report1.txt |
App2, App3 |
default |
out/report2.txt |
App2, App3 |
deliverableA |
out/deliverableA/report1-deliverableA.txt |
App1, App2 |
backend |
out/backend/report1-backend.txt |
App2 |
Resolving of the content of license texts which are referenced by the URLs given in NormalizedLicense.effectiveNormalizedLicenseUrl and NormalizedLicense.licenseRefUrl is done in the following way:
-
If the content is found as a resource in the classpath under
licensesthis will be taken. (The Solicitor application might include a set of often used license texts and thus it is not necessary to fetch those via the net.) If the classpath does not contain the content of the URL the next step is taken. -
If the content is found as a file in subdirectory
licensesof the current working directory this is taken. If no such file exists the content is fetched via the net. The result will be written to the file directory, so any content will only be fetched once. (The user might alter the files in that directory to change/correct its content.) A file of length zero indicates that no content could be fetched.
The determined content is available as NormalizedLicense.effectiveNormalizedLicenseContent and NormalizedLicense.licenseRefContent
When creating the resource or filename for given URLs in the above steps the following encoding scheme will be applied to ensure that always a valid name can be created:
-
If the scheme is
httpsit will be replaced withhttp. -
All "non-word" characters (i.e. characters outside the set
[a-zA-Z_0-9]) are replaced by underscores (“_”). -
In case that the resulting filename exceeds a length of 250 it will be replaced by a new name concatenated from
-
the first 40 characters of the (too) long filename
-
two underscores
-
a sha256 (hex encoded) of the (too) long filename
-
two underscores
-
the last 40 characters of the (too) long filename
-
|
Warning
|
This feature is deprecated and will be removed soon. |
Fetching the license content NormalizedLicense.effectiveNormalizedLicenseContent based on the URL in NormalizedLicense.effectiveNormalizedLicenseUrl will often result in content which is in HTML format instead of plain text and is not properly rendered when included in reports.
Sometimes the URL even does not point to the license text itself but just the homepage of the project.
In general it is possible to manually correct this by editing the downloaded and cached content as described in the previous section. This approach might require a lot of manual work. Solicitor therefore includes a mechanism named license url guessing which tries to guess an alternative license URL which should point to a representation of the content better suited for rendering.
Currently license URL guessing is based solely on the URL given in NormalizedLicense.effectiveNormalizedLicenseUrl. It will try the following approaches:
-
If the original URL is a Github-URL and matches patterns which are known to return HTML-formatted content then the URL is rewritten to point to a raw version of the content.
-
If the original URL points to a Github project page (not to a file), then the algorithm will try different typical locations (like e.g. looking for file
LICENSE). If found it will return this URL as result. -
If no "better" URL could be guessed it will return the original URL.
The result of the license URL guessing is available via three attributes:
-
NormalizedLicense.guessedLicenseUrl: The (possibly) improved URL pointing to the license text. -
NormalizedLicense.guessedLicenseUrlAuditInfo: A text which gives info how the guessed url was determined (available for auditing purposes). -
NormalizedLicense.guessedLicenseContent: The content downloaded from the guessed URL
|
Note
|
Downloading the license content (also including the checking if a certain resource is available when trying different possible filenames) is done using the same (caching) mechanisms as downloading the content for other URLs, see the previous section. |
The information about guessed URLs for given original URLs (also including the audit info on the guessing process) uses a caching mechanism which is mainly identical to the caching of downloaded content. The files containing the cached data are stored in directory licenseurls (instead of licenses for the content itself).
The file content looks as follows:
https://raw.githubusercontent.com/some/project/master/LICENSE (1) ------------------------- (2) URL changed from https://github.com/some/project/blob/master/LICENSE to https://raw.githubusercontent.com/some/project/master/LICENSE (3)
-
the guessed URL
-
a line of dashes as separator
-
the audit info (might be multiple lines)
It is possible to manually change this cached information and thus correct it - similar to manually correcting the license text as described above.
|
Warning
|
From version 1.23.0 on the license guessing logic is deprecated. No standard report will use the guessed properties. |
To use license guessing in a template, an additionalWriter (see Writers and Reporting ) needs to be set in the solicitor.cfg. Example:
"additionalWriters" : [ {
"type" : "velo",
"templateSource" : "classpath:com/devonfw/tools/solicitor/templates/Solicitor_Output_Template_Sample_v2.vm",
"target" : "${cfgdir}/output/OSS-Report_${project}_v2.html",
"description" : "The HTML OSS-Report",
"dataTables" : {
"MODELROOT" : "classpath:com/devonfw/tools/solicitor/sql/modelroot.sql",
"ENGAGEMENT" : "classpath:com/devonfw/tools/solicitor/sql/allden_engagements.sql",
"OSSLICENSES" : "classpath:com/devonfw/tools/solicitor/sql/ossapplicationcomponents_guessedlicenses.sql",
"UNIQUELICENSES" : "classpath:com/devonfw/tools/solicitor/sql/uniqueguessedlicenses.sql"
}
} ]
Within the lifecycle of the Solicitor development features might be discontinued due to various reasons. In case that such discontinuation is expected to break existing projects a two stage deprecation mechanism is used:
-
Stage 1: Usage of a deprecated feature will produce a warning only giving details on what needs to be changed.
-
Stage 2: When a deprecated feature is used Solicitor by default will terminate with an error message giving information about the deprecation.
By setting the property solicitor.deprecated-features-allowed to true
(e.g. via the command line, see Configuration of Technical Properties), even in second stage
the feature will still be available and only a warning will be logged. The project setup should in any
case ASAP be changed to no longer use the feature as it might soon be removed without further
notice.
|
Important
|
Enabling the use of deprecated feature via the above property should only be a temporary workaround and not a standard setting. |
|
Note
|
If usage of a feature should be discontinued immediately (e.g. because it might lead to wrong/misleading output) the first stage of deprecation will be skipped. |
The following features are deprecated via the above mechanism:
-
Reader of type "npm-license-crawler-csv" (use Reader of type "npm-license-checker" instead); Stage 2 from Version 1.24.0 on; see https://github.com/devonfw/solicitor/issues/125 and https://github.com/devonfw/solicitor/issues/263
-
Reader of type "npm"; Stage 2 from Version 1.24.0 on; see https://github.com/devonfw/solicitor/issues/62 and https://github.com/devonfw/solicitor/issues/263
-
"REGEX:" prefix notation in rule templates (use "(REGEX)" suffix instead); Stage 2 from Version 1.24.0 on; see https://github.com/devonfw/solicitor/issues/78 and https://github.com/devonfw/solicitor/issues/263
-
Use of
LicenseAssignmentProject.xlsdecision table (useLicenseAssignmentV2Project.xlsinstead); Stage 2 from Version 1.24.0 on; see https://github.com/devonfw/solicitor/issues/263 -
Use of
repoTypein the configuration of readers, see Applications; Stage 2 from Version 1.24.0 on; see https://github.com/devonfw/solicitor/issues/190 and https://github.com/devonfw/solicitor/issues/263 -
Running Solicitor on Java 8; Stage 1 from Version 1.22.0 on; see https://github.com/devonfw/solicitor/issues/247
-
LicenseUrl guessing; Stage 1 from Version 1.23.0 on; see https://github.com/devonfw/solicitor/issues/255
-
Reader of type "gradle2" (use Gradle License Report and Reader of type "gradle-license-report-json" instead); Stage 2 from Version 1.27.0 on; see https://github.com/devonfw/solicitor/issues/283
Starting from version 1.4.0 Solicitor can be integrated with the tool ScanCode to include detailed information gathered from the "deep license scan" performed by ScanCode. This includes detected Licenses, Copyrights and Notice-Files.
|
Warning
|
The current integration with ScanCode is experimental: The used ScanCode parameters, interfacing and curations logic and all parts of the data persistence are experimental and thus might result in insufficient quality of results. The current workflow and implementation is subject to change in future versions without further notice. |
The general workflow when integrating with ScanCode consists of the following 3 steps:
-
Execute Solicitor in a "classic" way i.e. just based on the data provided via the Readers as described in Reading License Information with Readers. Besides the normal reports/documents generated this will also create scripts for downloading the needed OSS source codes and run Scancode.
-
Download source codes and run ScanCode by executing the generated scripts. The downloaded sources and ScanCode results will be saved to a directory tree in the local filesystem.
-
Execute Solicitor a second time. For all ApplicationComponents where ScanCode information is available (stored in the local directory tree) the license data as obtained from the Readers is replaced by this information. The data model is enriched with the found copyright and notice file information. Reports (see Reporting and Creating output documents) are now based on the ScanCode data (where available).
The scripts generated by Solicitor to download sources and run ScanCode are in Bash syntax. So either run it on a system using natively Bash (linux) or install an appropriate environment (e.g. Git Bash) if you are using a windows environment.
Download and install ScanCode (Solicitor is assuming version 32, tested with 32.2.1) from https://github.com/nexB/scancode-toolkit/releases. Make sure that the executable is included in the search PATH for executables.
As the ScanCode integration is still experimental it is currently deactivated by default.
To enable it set system property solicitor.feature-flag.scancode=true.
(See Built in Default Properties for information how to do so.)
If this feature flag is not activated then Solicitor will not try to attempt to read ScanCode information from the local file system.
Execute Solicitor in a classic way. As part of the report creation step this will generate two scripts:
-
output/scancode_PROJECTNAME.sh(for downloading the sources, also callsscancodeScan.sh) -
output/scancodeScan.sh(for running ScanCode on the downloaded sources)
Scripts will include all ApplicationComponents with exception of those where normalizedLicenseType was set to COMMERCIAL.
Change to directory output and execute sh scancode_PROJECTNAME.sh.
This will download all sources and process them via ScanCode.
This might take several hours to complete.
Results are stored in subdirectory Source of the directory output and is organized in a tree structure given by the PackageURL of the ApplicationComponents.
The Scancode integration scripts try to download ApplicationComponent sources from default URLs derived from the PackageUrl (e.g. Maven Central). In cases where the sources are not available at these locations, the download will fail (and the subsequent source scan will be skipped). In this case it is possible to manually download the sources from some other location and store it in the directory structure. Restarting the Scancode integration script might then perform the source scan.
To be able to document the (non default) origin of the ApplicationComponent sources a file origin.yaml is created in the components directory in the file system. If the failed source download has been performed manually it is possible to edit this file and correct the data given in this file.
# This file contains metadata about the orgin of the package and the sources.
# This file was automatically created but might manually be edited if the contained data is not correct
sourceDownloadUrl: https://url/pointing/to/the/source/archive.jar (1)
packageDownloadUrl: https://url/pointing/to/the/binary/archive.jar (2)
# note: to add comments: write them here and remove the hash at the beginning of the line (not yet processed by Solicitor)-
URL for downloading the sources - will be available as property
ApplicationComponent.sourceDownloadUrlin the Solicitor data model. -
URL for downloading the binaries - will be available as property
ApplicationComponent.packageDownloadUrlin the Solicitor data model.
The content of the file origin.yaml currently just affects the above given two properties, it does not affect the downloading of sources by the scripts.
Execute Solicitor a second time.
After reading the component/license information from the Readers (but before starting the rule engine)
Solicitor will try to look up ScanCode information from the directory tree in output/Sources for all processed ApplicationComponents. If information is found for an ApplicationComponent the following is done:
-
License information (including URL of license text) as obtained from the Readers is replaced by the license info found by ScanCode
-
Copyrights are taken from ScanCode results
-
Info on NOTICE file is taken from the ScanCode results
-
If the ScanCode results contain information about project URLs this is stored as
sourceRepoUrland/orossHomepage -
sourceDownloadUrlandpackageDownloadUrlare set to the values given in fileorigin.yaml
Main target of the additional information obtained from ScanCode is currently the new report Attributions_PROJECTNAME.html which lists
-
all ApplicationComponents (excluding those which are not OSS licensed)
-
with all found copyrights
-
and all licenses
-
including all different license texts
-
and contents of all found NOTICE files
When using the Scancode integration the following values are used for field ApplicationComponent.dataStatus:
| Value | Description |
|---|---|
|
No data available. Scancode integration disabled. License info from reader was preserved. |
|
No data available. No scan results existing and no indication that attempting download/scanning has failed. License info from reader was preserved. |
|
No data available. No scan results existing. Processing (downloading or scanning) had failed. License info from reader was preserved. |
|
Data available but did not contain any license information. Issues were detected in the data which probably need to be curated. License info from reader was preserved. |
|
Data available but did not contain any license information. No curations applied. No issues were detected (despite the fact that no license info was found). License info from reader was preserved. |
|
Data available but did not contain any license information. Curations were applied. No issues were detected (despite the fact that no license info was found). License info from reader was preserved. |
|
Data available (including licenses). Issues were detected in the data which probably need to be curated. |
|
Data available (including licenses). No curations applied. No issues were detected. |
|
Data available (including licenses). Curations were applied. No issues were detected. |
Within the normal workflow NormalizedLicense objects are created from RawLicense objects via the rules given in the different LicenseAssignment and LicenseNameMapping decision tables, see Phase 1: Determining assigned Licenses. The "raw" license data obtained from Scancode represents licenses either by SPDX-IDs or (if licenses
are detected which do not have a corresponding SPDX-IDs) via LicenseRef-scancode-XXXXX qualifiers. This is an improved data quality as compared to RawLicenses obtained from normal Readers. (See Reading License Information with Readers.) Solicitor makes use of this improved data quality and by default performs an automatic mapping of RawLicense data to NormalizedLicense s in this case:
-
If the raw license matches a SPDX-ID then a
NormalizedLicenseis created withnormalizedLicenseTypeset toOSS-SPDX. -
If the raw license starts with
LicenseRef-scancode-then aNormalizedLicenseis created withnormalizedLicenseTypeset toSCANCODE. -
If the raw license matches a given "ignorelist" (see below), then a
NormalizedLicenseis created withnormalizedLicenseTypeset toIGNOREandnormalizeLicenseset toIgnore. -
If the raw license does not match any of the above criteria or matches a "blacklist" (see below) then no automatic mapping is done.
The ignorelist allows to automatically map licenses so that they are ignored in the further evaluation. The blacklist allows suppressing the automatic mapping of specific licenses. Both lists are configured via properties and are represented by a comma separated list of regular expressions.
The default is:
solicitor.scancode.automapping.blacklistpatterns=.*unknown.*,.*proprietary.* solicitor.scancode.automapping.ignorelistpatterns=
This prohibits automatic mapping of licenses ids which are ambiguous. No ignore mapping is done by default.
The data obtained from ScanCode might be affected by false positives (wrongly detected a license or copyright) or false negatives (missed to detect a license or copyright). To compensate such defects there are two mechanisms: Applying Curation information from a "curations" file or changing the license information via the decision table rules.
To define curations you might create a file output/curations.yaml containing the following structure:
artifacts:
- name: pkg/npm/@somescope/somepackage/1.2.3 (1)
url: https://github.com/foo/bar (2)
licenseCurations: (3)
- operation: REMOVE
path: "sources/package/readme.md"
ruleIdentifier: "proprietary-license_unknown_13.RULE"
matchedText: ".* to be paid .*"
comment: "just a generic remark, not a license"
- operation: ADD
newLicense: "Apache-2.0"
comment: "License as given on website"
copyrightCurations: (4)
- operation: REMOVE
path: "sources/package/lib/test.js"
oldCopyright: "(c) R.apv"
comment: "some minified code fragment, not a copyright"
excludedPaths: (5)
- "sources/src" (6)
- name: pkg/npm/@anotherscope/anotherpackage/4.5.6 (7)
.
.
.-
Path of the package information as used in the file tree. Derived from the PackageURL.
-
URL of the project, will be stored as
sourceRepoUrl. (Optional: no change if not existing.) -
Rules for curating license findings, see below.
-
Rules for curation copyright findings, see below.
-
Excluded paths to be set. Optional. If defined then all scanned files, whose path prefix contain any given string here, are excluded from the ScanCode information.
-
A single path prefix. All scanned files starting with this path prefix are excluded from the Scancode information.
-
Further packages to follow.
Curating licenses is done by REMOVING (i.e. ignoring) specific license findings from ScanCode, by REPLACING the detected license with another one or by ADDING license findings either to specific files or on top level (not related to specific file of the package sources). In addition to the conditions/data which is specific for any of the below described operations it is always possible to define a comment which is intended to be included in any audit trail log for documentation purposes (not yet used/implemented).
Removing found licenses is done by defining rules which result in ignoring the license finding(s) of scancode rules in files within the scanned codebase. The following "conditions" are used for defining the rule
-
pathof the file within the sources (defined as a regular expression; matches tofiles[].pathin the scancode json file) -
ruleIdentifierof the rule (defined as a regular expression; matches tofiles[].licenses[].matched_rule.identifierin the scancode json file) -
matchedTextof the finding (defined as a regular expression; matches tofiles[].licenses[].matched_textin the scancode json file) -
oldLicenseof the finding (defined as regular expression; matches tofiles[].licenses[].spdx_license_key
The first three conditions can uniquely identify any license finding listed in the scancode json file. The oldLicense condition can be used to select findings to be ignored based on the found license instead of the ruleIdentifier.
All conditions are optional but at least one needs to be defined. By using RegEx syntax the curations can be written very flexible. By using solely oldLicense as a condition it is e.g. possible to remove all findings of a specific license.
Instead of removing licenses (ignoring the finding) they might be replaced with a different license key and/or URL pointing to the license text. The conditions are the same as for REMOVE, the replacement is defined as follows
Data:
-
newLicenseis the key / id of the license to use instead (replacingfiles[].licenses[].spdx_license_key) -
urlis the url pointing to the license text
At least one of the two parameters has to be set.
Adding new licenses is done by defining rules which add new license info (to the licenses found in a source file) - or "on top level".
Conditions:
-
pathof the file within the sources to which the license should be added (defined as a regular expression; matches tofiles[].pathin the scancode json file). Note that this will only work if there arefiles[].pathin the scancode json for which this conditions matches.
It is not possible to associate licenses to files which are not listed in scancode json. The path condition might be omitted which results in the given license to be added to the result without any relation to a specific path.
Data:
-
newLicense: the key/SPDX-ID of the license to add -
url: URL to the license text
Curating copyrights is based on the same principles as curation of licenses, providing REMOVE, REPLACE and ADD operations.
REMOVING found copyrights is done by defining rules which result in ignoring the copyright finding(s) in files within the scanned codebase. The following "conditions" are used for defining the rule
-
pathof the file within the sources (defined as a regular expression; matches tofiles[].pathin the scancode json file) -
oldCopyrightthe found copyright text to ignore (defined as a regular expression; matches tofiles[].copyrights[].copyrightin the scancode json file)
At least one of the conditions has to be defined.
This follows the above principles. It uses the same conditions as REMOVE and uses a parameter to define the copyright to use instead:
Data:
* newCopyright: The copyright entry to use instead of the originally found copyright
Adding new copyrights is done by defining rules which add new copyright info (to the copyrights found in a source file) - or "on top level".
Conditions:
-
pathof the file within the sources (defined as a regular expression; if omitted the copyright will be applied on "top level"). Note that it is again only possible to add copyrigts to paths which are listed in the scancode json
Data:
-
newCopyright: the copyright string to add
Instead of curating license / copyrights on a "per finding" level as given above it is alternatively possible to completely replace the list of found licenses and/or copyrights with a new list.
|
Important
|
Up to version 1.23.0 this was the only way of doing license / copyright curations. Use of this way of curating data is still possible but discouraged and might be deprecated/removed soon. |
The file output/curations.yaml looks as follows when doing curations this way:
artifacts:
- name: pkg/npm/@somescope/somepackage/1.2.3 (1)
url: https://github.com/foo/bar (2)
licenses: (3)
- license: MIT (4)
url: https://raw.githubusercontent.com/foo/bar/LICENSE (5)
copyrights: (6)
- (c) 2021 Donald Duck (7)
- "(c) 2019 Mickey Mouse <http://mickey.mouse>" (8)
excludedPaths: (9)
- "sources/src" (10)
- name: pkg/npm/@anotherscope/anotherpackage/4.5.6 (11)
.
.
.-
Path of the package information as used in the file tree. Derived from the PackageURL.
-
URL of the project, will be stored as
sourceRepoUrl. (Optional: no change if not existing.) -
Licenses to set. Optional. If defined then all found licenses will be replaced by the list of licenses given here.
-
SPDX identifier of license.
-
URL pointing to license text.
-
Copyrights to set. Optional. If defined then all found copyrights will be replaced by the list of copyrights given here.
-
A single copyright.
-
Another copyright. Note that due to YAML syntax any string containing
:needs to be enclosed with parentheses -
Excluded paths to be set. Optional. If defined then all scanned files, whose path prefix contain any given string here, are excluded from the ScanCode information.
-
A single path prefix. All scanned files starting with this path prefix are excluded from the Scancode information.
-
Further packages to follow.
Different version of a package/component or even different packages/components within the same namespace often require mostly the same curations to be applied. To avoid being forced to redefine curations for every single version it is possible to define curations by just specifying a prefix part in the name attribute.
Example of available levels/prefixes for pkg:/maven/ch.qos.logback/[email protected]
-
pkg -
pkg/maven -
pkg/maven/ch -
pkg/maven/ch/qos -
pkg/maven/ch/qos/logback -
pkg/maven/ch/qos/logback/logback-classic -
pkg/maven/ch/qos/logback/logback-classic/1.2.3
The complete tree will be checked for curations. Any found curations will be merged
-
Attribute
name: latest encountered in the hierarchy will be taken -
Attribute
notewill be joined using delimiter " / " -
Attribute
url: latest encountered in the hierarchy will be taken -
Attribute
copyrights(old style of curations): Lists will be merged -
Attribute
licenses(old style of curations): Lists will be merged -
Attribute
excludedPaths: Lists will be merged -
Attribute
licenseCurations: License curation rule lists (REMOVE/REPLACE/ADD) will be merged; order is more specific ones first; when evaluating for a specific license finding in the scancode json only the first matching curation rule will be taken. -
Attribute
copyrightCurations: Copyright curation rule lists (REMOVE/REPLACE/ADD) will be merged; order is more specific ones first; when evaluating for a specific copyright finding in the scancode json only the first matching curation rule will be taken.
The resulting curation will then be applied to the scancode data of the component.
As for license information obtained from the Readers the license information from ScanCode can also be altered using decision table rules. A new attribute origin was introduced in the RawLicense entity as well as condition field in decision table LicenseAssignmentV2*.xls/csv. The origin attribute in Rawlicense either contains the string scancode if the license information came from ScanCode or it contains the (lowercase) class name of the used Reader.
Using the Extended comparison syntax it is possible to qualify whether a rule should apply for licenses found by ScanCode or not:
| Value of condition Origin | rule applies for … |
|---|---|
|
… licenses obtained from ScanCode information |
|
… licenses obtained from normal Readers |
(empty) |
… in both cases |
Due the automatic mapping of scancode based RawLicenses to NormalizedLicenses (see Automatic mapping of RawLicense data obtained from Scancode to NormalizedLicense) such explicit mapping rules are only required for licenses not handled by the automatism.
The Velocity template Statistics.vm creates a Statistics.json file that currently looks like this:
{
"Statistics": {
"legal-evaluation": {
"yes": 100,
"no": 2,
"Conditional": 30,
"blank": 10
},
"data-status": {
"ND:NOT_AVAILABLE": 5,
"ND:PROCESSING_FAILED": 7,
"NL:WITH_ISSUES": 10,
"NL:NO_ISSUES": 2,
"NL:CURATED": 1,
"DA:NO_ISSUES": 70,
"DA:CURATED": 20
}
}
}The individual categories can be customized in the statistics.sql template. Using these fields, you can create a Build-Breaker.
For instance, if there are artifacts in your project that have the legal-evaluation value "no", you can break the build.
To achieve this, you can use the JSON processor jq and add a script like the following:
# Check if the count for "no" is greater than 0
NO_COUNT=$(jq '.["Statistics"]["legal-evaluation"]["no"]' Statistics.json)
# If NO_COUNT is greater than 0, break the build
if [ -n "$NO_COUNT" ] && [ "$NO_COUNT" != "null" ] && [ "$NO_COUNT" -gt 0 ]; then
echo "Build failed: 'no' count in legal-evaluation is $NO_COUNT"
exit 1
else
echo "Build successful"
fiThe builtin default base configuration contains settings for the rules and writers section
of the Solicitor configuration file which will be used if the project specific config file omits those sections.
link:files/solicitor_base.cfg[role=include]The following lists the default settings of technical properties as given by the built in application.properties file.
If required these values might be overridden on the command line when starting Solicitor:
java -Dpropertyname1=value1 -Dpropertyname2=value2 -jar solicitor.jar <any other arguments>
link:files/application.properties[role=include]There are different templates that can be used for reporting. For usage, the templates have to be specified in the “writers” section of the solicitor configuration file (see Writers and Reporting). In the default solicitor configuration all templates are specified. (see Appendix A: Default Base Configuration.asciidoc)
With this template a report in Excel format can be created. The spreadsheet contains data from the internal database (see Database structure) which can be fetched by specifying the path to the SQL statements files in the solicitor configuration file.
This template creates a HTML document which has a table containing the relevant data from the internal database. Cells that have been changed, compared to a previous solicitor run, are marked in a different color. For usage, the option -d <filename> needs to be appended with filename being saved_latest_model.json.
This template creates an HTML document which has an overview of OSS components used in the project. The data is displayed in a table with the columns: Name, GroupId, Version, Application, License, LicenseUrl.
Similar to the above but uses guessed license URLs and content, see Guessing of license URLs. As license URL guessing is deprecated this template is no longer included in the standard configuration. For activation see License guessing feature usage.
This template creates an HTML document which contains OSS components that have been mapped to multiple licenses. The data is displayed in a table with the columns: Application, OSS Name/Product, OSS ArtifactId, OSS Version, Effective Normalized Licenses, License Count.
This template creates a bash script for downloading package sources for all packages where the license requires the source code to be included in the distribution.
These templates create script files for downloading package sources and using ScanCode to do a "deep license scan" for finding licenses, copyright information (statements, holders, authors) and NOTICE files for each artifact within a project. See Experimental Scancode Integration.
|
Note
|
Generating these scripts is an experimental feature and might be changed or removed in future versions without any notice. |
This template creates an attributions document which lists all used OSS components with their licenses, license texts and found copyrights information as well as found information from NOTICE files. The template is part of the Experimental Scancode Integration and requires ScanCode to be used to collect all necessary information.
Solicitor comes with a sample rule data set and sample reporting templates. In general it will
be required to correct, supplement and extend this data sets and templates. This can be done straightforward
by creating copies of the appropriate resources (rule data XLS/CSV and template files), adopting them and further on referencing those copies instead of the original resources from the project configuration file.
Even though this approach is possible it will result in hard to maintain configurations,
especially in the case of multiple projects using Solicitor in parallel.
To support such scenarios Solicitor provides an easy extension mechanism which allows
to package all those customized configurations into a single archive and reference it from the
command line when starting Solicitor.
This facilitates configuration management, distribution and deployment of such extensions.
The extensions might be provided as JAR file or even as a simple ZIP file. There is only one mandatory file which contains (at least metadata) about the extension and which needs to be included in this archive in the root folder.
link:files/application-extension.properties[role=include]This file is included via the standard Spring Boot profile mechanism. Besides containing
naming and version info on the extension this file might override any
property values defined within Solicitor.
Any other resources (like rule data or templates) which need to be part of the Extension can be included in the archive as well - either in the root directory or any subdirectories. If the extension is active those resources will be available on the classpath like any resources included in the Solicitor jar.
Overriding / redefining the default base configuration within the Extension enables to update all rule data and templates without the need to touch the projects configuration file.
The Extension will be activated by referencing it as follows when starting Solicitor:
java -Dloader.path=path/to/the/extension.zip -jar solicitor.jar <any other arguments>
It is also possible to extend the functionality of Solicitor within an extension by implementing Spring Beans which implement certain interfaces. As the resources contained in the extension are included into Solicitors classpath those beans might be discovered through the Spring component scan mechanism and thus be activated.
|
Note
|
The Spring components scanning mechanisms by default searches only in package com.devonfw.tools.solicitor (and subpackages). You either need to define the extension classes in these packages or create a specific configuration class in this package which has an
appropriate @ComponentScan annotation which points to your packages.
|
|
Warning
|
Extending Solicitor via Java is an advanced topic. Only the Interfaces given below should be used. Even those should be regarded as unstable and might change without notice. For any details on the interfaces see the Solicitor source code and corresponding Javadoc. |
A spring bean implementing this interface might provide ComponentInfo/LicenseInfo data for ApplicationComponents identified
by their packageUrl. (The buildin implementation of this interface is reading such component info from scancode result files
from the local file system, see Experimental Scancode Integration.) Alternative implementations might e.g. get this information
from a corporate server or even a public service available on the internet.
Spring beans implementing this interface will be called at certain points in the Solicitor processing lifecycle. See the Javadoc for details. Implementations should preferably use com.devonfw.tools.solicitor.lifecycle.AbstractSolicitorLifecycleListener as base class which contains NOOP functionality for all methods which might be overridden as required.
- Changes in 1.32.0
- Changes in 1.31.0
-
-
https://github.com/devonfw/solicitor/issues/295: Add PackageUrlHandler for cran packages.
-
https://github.com/devonfw/solicitor/issues/195: PackageURLs are now consequently represented within the Solicitor code via the PackageURL java class. This should not result in functional changes but any possible Java code used in (optional) Solicitor Extensions (see Java Extensions) might need to be adopted to the the new data structures.
-
https://github.com/devonfw/solicitor/issues/299: Restructuring of PackageURLHandler class structure and processing to better handle PackageURL types for which no specific SingleKindPackageURLHandler is defined. This might result in PackageURLs to be processed which were ignored until now.
-
- Changes in 1.30.0
-
-
https://github.com/devonfw/solicitor/pull/292: Improved the extraction of spdxids from spdx expressions when parsing ScanCode V32 result files. Previously the result might have contained empty strings to be returned as spdxids.
-
https://github.com/devonfw/solicitor/issues/293: Improved structure of documentation on the different Readers for processing data of Gradle projects.
-
- Changes in 1.29.0
-
-
https://github.com/devonfw/solicitor/pull/291: Fixed a bug in the processing of ScanCode V32 files.
-
https://github.com/devonfw/solicitor/pull/290: Fixed an incorrect documentation of a rule in the user guide.
-
- Changes in 1.28.0
-
-
https://github.com/devonfw/solicitor/issues/288: New feature "reporting groups" for creating reports for subsets of Applications. See Reporting Groups.
-
https://github.com/devonfw/solicitor/issues/12: New
statisticsVelocity and SQL template which can be used in a build-breaker.
-
- Changes in 1.27.0
-
-
https://github.com/devonfw/solicitor/issues/283: New Reader for data generated by the Gradle License Report Plugin. See Gradle License Report. Reader
gradle2deprecated (stage 2). Readergradleremoved. -
https://github.com/devonfw/solicitor/issues/285: VelocityWriter now enforces UTF-8 encoding when writing results.
-
- Changes in 1.26.0
-
-
https://github.com/devonfw/solicitor/issues/281: Solicitor now assumes ScanCode v32 to be used within the ScanCode integration. ScanCode JSON result files of v30 and v31 can still be processed but the scripting for doing the scans assumes v32 to be installed.
-
- Changes in 1.25.0
-
-
https://github.com/devonfw/solicitor/issues/277: When reading content (license texts or notice files) within the scancode adapter files which are greater than 1 million bytes will be skipped. This avoids large memory consumption and resulting instability.
-
https://github.com/devonfw/solicitor/issues/274: Fixed issue where no packageURL was created when using the CSV reader. Added attribute 'packageType'.
-
https://github.com/devonfw/solicitor/issues/279: Fixed issue where the CycloneDX reader could not read licenses declared as 'expression'.
-
- Changes in 1.24.2
-
-
https://github.com/devonfw/solicitor/pull/271: Fixed an incompatibility with JDK 8.
-
- Changes in 1.24.1
-
-
https://github.com/devonfw/solicitor/pull/270: Fixed an incompatibility with JDK 8.
-
- Changes in 1.24.0
-
-
https://github.com/devonfw/solicitor/issues/263: Some features were pushed from deprecation stage 1 to stage 2, which means they do not longer work with default configuration: repoType attribute, npm and npm-license-crawler readers, REGEX prefix notation, LicenseAssignmentProject.xls. See List of Deprecated Features for details.
-
https://github.com/devonfw/solicitor/pull/265: Added some license name mappings.
-
https://github.com/devonfw/solicitor/pull/266: Improve correlation of records (diff processing, see Determining difference to previously stored model) for aggregated inventory report
OSS-Inventory_aggregated_*.xlsx. -
https://github.com/devonfw/solicitor/issues/267: Introduce more fine grained and hierarchical curations of licenses and copyrights. See Curating data via a curations file.
-
- Changes in 1.23.0
-
-
https://github.com/devonfw/solicitor/issues/255: Deprecate LicenseUrl guessing.
-
https://github.com/devonfw/solicitor/issues/258: Add GenericExcelWriter for debugging of SQL scripts.
-
https://github.com/devonfw/solicitor/issues/260: Extended the user guide towards semantics of Usage Patterns.
-
- Changes in 1.22.0
-
-
https://github.com/devonfw/solicitor/pull/243: Make sure the MavenReader is protected against XXE threats.
-
https://github.com/devonfw/solicitor/pull/244, https://github.com/devonfw/solicitor/pull/253: Updated Drools rule engine to 8.27.0.Beta.
-
https://github.com/devonfw/solicitor/issues/247: Running Solicitor on Java 8 is deprecated (Stage 1) and will be no longer possible soon. Move to Java 11 ASAP!
-
https://github.com/devonfw/solicitor/pull/254: Refactoring: Introduction of CurationDataHandle to enable additional ways to represent/reference curation data.
-
- Changes in 1.21.0
-
-
https://github.com/devonfw/solicitor/pull/239: Improving some internal components to reduce risk of path traversal attacks in case that these components are (re)used in some webservice implementation.
-
https://github.com/devonfw/solicitor/issues/240: Improve Attributions.html to use packageUrl. Fixed bug where license texts for components with license type 'SCANCODE' were not printed.
-
- Changes in 1.20.0
-
-
https://github.com/devonfw/solicitor/issues/232: Set a standard for ordering LicenseNameMapping rules. Rules with an 'or-later' suffix are put before '-only' rules.
-
https://github.com/devonfw/solicitor/issues/234: Correct handling of new data model fields in ModelImporterExporter
dataStatus,traceabilityNotesetc. -
https://github.com/devonfw/solicitor/pull/235: Improvements in Curation Data Handling. When the curationDataSelector parameter is set to "none," no curations will be applied.
-
https://github.com/devonfw/solicitor/issues/237: New Reader for license info of systems built with Yarn Modern. See Yarn Modern (Yarn 2 and above).
-
- Changes in 1.19.0
-
-
https://github.com/devonfw/solicitor/issues/227: Fixed a bug where the
dataStatusfield in the aggregated OSS-Inventory was not filled. -
https://github.com/devonfw/solicitor/issues/228: Extended
ApplicationComponent.dataStatusvalues to reflect situation when no licenses were obtained from the Scancode information. See dataStatus values of the Scancode integration. -
https://github.com/devonfw/solicitor/issues/230: Enable automatic mapping of
RawLicensedata obtained from Scancode toNormalizedLicenses. See Automatic mapping ofRawLicensedata obtained from Scancode toNormalizedLicense. -
Generalize pattern of scancode licenses classified as WITH_ISSUES (from
LicenseRef-scancode-free-unknownto.*unknown.*)
-
- Changes in 1.18.0
-
-
https://github.com/devonfw/solicitor/pull/225: Added some additional name mapping rules to handle SPDX-IDs and license references from Scancode.
-
- Changes in 1.17.1
-
-
https://github.com/devonfw/solicitor/issues/223: Fixed a regression bug in Solicitor command line parsing which (within Version 1.16.0 and 1.17.0) prevents correct parsing of "l" and "d" options.
-
- Changes in 1.17.0
-
-
https://github.com/devonfw/solicitor/issues/221: Provide status information on data obtained from Scancode in field
ApplicationComponent.dataStatus. See dataStatus values of the Scancode integration.
-
- Changes in 1.16.0
-
-
https://github.com/devonfw/solicitor/pull/212: Improvement in determining License-URL within NpmLicenseCheckerReader.
-
https://github.com/devonfw/solicitor/issues/213: Avoid (too) long filenames when caching license texts or licenseurls. See Encoding of URLs.
-
https://github.com/devonfw/solicitor/issues/218: Update dependencies to latest version.
-
- Changes in 1.15.0
-
-
https://github.com/devonfw/solicitor/issues/208: Add two new lifecycle methods to
SolicitorLifecycleListener. -
https://github.com/devonfw/solicitor/issues/207: Add a new feature allowing the exclusion of paths and files of scanned artifacts from the Scancode information.
-
https://github.com/devonfw/solicitor/issues/211: Allow setting alternative locations for curation data (
curationDataSelector). Note that the standard implementation included within Solicitor does not yet honor this value.
-
- Changes in 1.14.0
-
-
https://github.com/devonfw/solicitor/issues/202: Include parameter in CurationProvider.findCurations() to allow getting curation from alternative locations.
-
https://github.com/devonfw/solicitor/issues/190: Deprecate
repoTypeattribute in configuration of readers.
-
- Changes in 1.13.0
-
-
https://github.com/devonfw/solicitor/issues/198: Add PackageUrlHandler for nuget packages.
-
https://github.com/devonfw/solicitor/issues/191: Refactoring of the (experimental) Scancode integration (formerly class ScancodeFileAdapter).
-
https://github.com/devonfw/solicitor/issues/192: References to files within the sources of a component (e.g. license or notice files) are now returned from the Scancode adapter by a uri with schme/prefixed
pkgcontent:. This replaces the usage offile:urls in this case. The same syntax needs to be used within curation data if the url pointing to license texts within the component needs to be curated. -
https://github.com/devonfw/solicitor/issues/199: Refactoring of Source_Download_Script.vm to use packageUrl instead of repoType.
-
- Changes in 1.12.0
-
-
https://github.com/devonfw/solicitor/issues/182: Add new data quality and traceability attributes to the ComponentInfo data structure.
-
https://github.com/devonfw/solicitor/issues/185: Fixed random ordering of rows in OSS-Inventory-Simple, which causes false differences to be marked.
-
https://github.com/devonfw/solicitor/issues/189: Added a CycloneDX Reader, to enable reading SBOMs in CycloneDX 1.4 or 1.5 format.
-
- Changes in 1.11.0
-
-
https://github.com/devonfw/solicitor/pull/179: Added further name mapping rules.
-
https://github.com/devonfw/solicitor/issues/168: Fixed NullPointerException for blank license in License URL Guessing.
-
- Changes in 1.10.0
-
-
https://github.com/devonfw/solicitor/issues/175: Introduce new properties
packageDownloadUrlandsourceDownloadUrlinApplicationComponent. Process fileorigin.yamlwithin Experimental Scancode Integration to be able to set these properties to non default values. -
https://github.com/devonfw/solicitor/issues/177: Contents of local resources (
file:) are no longer cached in FilesystemCachingContentProvider.
-
- Changes in 1.9.0
-
-
https://github.com/devonfw/solicitor/issues/171: Multiple improvements in processing of ScanCode results.
-
https://github.com/devonfw/solicitor/issues/167: Fixed a bug which prevented license URLs given in scancode curations (see Structure of curations file) to be resolved properly when they point to the local file system (starting with
file:).
-
- Changes in 1.8.1
-
-
https://github.com/devonfw/solicitor/issues/164: Fixed a bug which might result in license texts not being retrieved.
-
- Changes in 1.8.0
-
-
https://github.com/devonfw/solicitor/issues/154: Corrected dependency declaration for solicitor-core.jar.
-
https://github.com/devonfw/solicitor/issues/156: Included engagement name as member in class SolicitorSetup.
-
https://github.com/devonfw/solicitor/issues/158: Include library com.auth0/java-jwt to make it available for extensions.
-
https://github.com/devonfw/solicitor/issues/160: License texts are now included in the data model json.
-
https://github.com/devonfw/solicitor/issues/162: Include added notice file content and license texts to the ComponentInfo interface.
-
- Changes in 1.7.0
-
-
https://github.com/devonfw/solicitor/issues/152: Enhancements for using java code in extensions.
-
- Changes in 1.6.0
-
-
https://github.com/devonfw/solicitor/issues/146: Fixed the bug which prevented already defined velocity macro with same name to be redefined in different template.
-
https://github.com/devonfw/solicitor/issues/135: Introduce
sourceRepoUrlas new property inApplicationComponent. Depending on the kind of Reader eitherossHomepageand/orsourceRepoUrlwill be filled with data. -
https://github.com/devonfw/solicitor/issues/149: Added name mappings so that for all SPDX-IDs used in the name mapping the SPDX-ID itself is also recognized and formally mapped.
-
- Changes in 1.5.0
-
-
https://github.com/devonfw/solicitor/issues/6: Fixed the bug by allowing multiple
NormalizedLicenseentries with same id perApplicationComponentif the declared license differs. This allows to assign multiple licenses of same type (e.g. MIT) to a component and also will allow multiple "UNKNOWN" licenses to be reported for the same component. Note that as a side effect additional and unexpectedNormalizedLicenseentries might now be created. This might be caused from multipleLicenseAssignment*.xlsrules firing for differentRawLicenseentries in the sameApplicationComponentand resulting in identicalNormalizedLicenseid. In this case it is necessary to restrict those different rules to only fire for specificRawLicenseentries.
-
- Changes in 1.4.0
-
-
https://github.com/devonfw/solicitor/issues/141: Improved robustness of report generation in cases where PackageURL can not be determined (e.g. if data originates from CSV reader).
-
https://github.com/devonfw/solicitor/issues/139: Provide extension interface to allow reading information about components/licenses from alternative sources. See Extension Interfaces.
-
https://github.com/devonfw/solicitor/issues/137: Internal restructuring of Solicitor modules which allows Solicitor code to be used as dependency in other projects.
-
https://github.com/devonfw/solicitor/issues/129: Added spellcheck support within documentation for run-together words like camel cased ones.
-
https://github.com/devonfw/solicitor/issues/130: Fixed a bug where the guessedLicenseUrl and guessedLicenseUrlAuditInfo fields were not filled correctly in the aggregated inventory.
-
Added reader for data generated by OSS Review Toolkit (ORT). See OSS Review Toolkit (ORT).
-
Added support for API changes of new scancode release (v31) https://github.com/nexB/scancode-toolkit/releases/tag/v31.0.1.
-
https://github.com/devonfw/solicitor/issues/124: Added documentation of '--production' option for npm-license-checker plugin.
-
https://github.com/devonfw/solicitor/issues/125: Deprecated usage of npm-license-crawler.
-
Stability and data corruption safety for bash scripts of scancode integration.
-
Initial version of experimental scancode integration. See Experimental Scancode Integration.
-
New decision table structure
LicenseAssignmentV2with additional conditionorigin. Old structure deprecated but still supported. Migrate existing project decision tables by renamingLicenseAssignmentProject.xlstoLicenseAssignmentV2Project.xlsand introducing a new (empty) columnOriginbetween existing columnsOSS VersionandDeclared License. -
Added Solicitor Logo and code for creating variants / animation.
-
https://github.com/devonfw/solicitor/issues/117: New attribute
packageUrlinApplicationComponent. -
Experimental scancode-toolkit integration changed to using Bash scripting.
-
Ruleset change: For GPL/LGPL-Licenses use
…-onlyor…-or-laterIDs instead of the deprecated ones likeGPL-3.0. -
https://github.com/devonfw/solicitor/issues/113: Allow project specific writers (
additionalWriters) to be defined without overriding default writers. -
https://github.com/devonfw/solicitor/issues/15: Enable Decision Tables to be alternatively defined as CSV. Allow dynamic determination of applicable format by specifying resource names without file extension.
-
https://github.com/devonfw/solicitor/issues/108: Updated spring boot framework, drools rule engine and other used components to latest versions.
-
https://github.com/devonfw/solicitor/issues/110: Allow an additional user guide to be extracted when using an extension.
-
- Changes in 1.3.0
-
-
New report ScancodeDownloadScript.vm to compile copyright information using ScanCode.
-
https://github.com/devonfw/solicitor/issues/75: Added license URL guessing, see Guessing of license URLs.
-
https://github.com/devonfw/solicitor/issues/86: In case that downloading content for a given URL fails no WARN message with stacktrace will be shown any more. Instead there will be an info message (SOLI-047 or SOLI-048) indicating that the content could not be downloaded. This change is due to the fact that failed downloads are expected - especially with the new feature license URL guessing.
-
Readers for PIP and YARN added.
-
https://github.com/devonfw/solicitor/issues/101: If downloaded license texts contain large amounts of html formatted content they will be replaced by a placeholder indicating the need for cleanup. A warning message will be written in this case (SOLI-050).
-
https://github.com/devonfw/solicitor/issues/103: Changed structure of Solicitor source code repository to maven multi module structure.
-
https://github.com/devonfw/solicitor/issues/7: Allow more flexible CSV file format within the CsvReader.
-
https://github.com/devonfw/solicitor/issues/78: Introduce new suffix (REGEX) in decision tables to mark regular expressions. Using this suffix avoids breaking any sorting when using mixed verbatim strings and regex patterns. The old prefix syntax REGEX: has been deprecated.
-
- Changes in 1.2.3
-
-
https://github.com/devonfw/solicitor/issues/97: Fixed the bug which made the GradleReader and GradleReader2 skip the first entry in the file.
-
https://github.com/devonfw/solicitor/issues/87: GradleReader and GradleReader2 no longer fail when reading files that contain no entry. Actually this was due to bug https://github.com/devonfw/solicitor/issues/97.
-
- Changes in 1.2.2
-
-
Fixed bug which resulted in corrupt XLS report due to cell comment exceeding maximum allowed size.
-
- Changes in 1.2.1
-
-
https://github.com/devonfw/solicitor/issues/94: Fixed by making sure that formulas get evaluated when opening the workbook with excel.
-
Fixed bug when reading saved data model for delta calculation. (
repoTypewas not read correctly and resulted in always reporting a difference.)
-
- Changes in 1.2.0
-
-
Added some license name mapping rules in LicenseNameMappingSample.xls.
-
https://github.com/devonfw/solicitor/issues/71: New "Quality Report" which might be helpful in validating the outcome of the Solicitor run. Currently this report contains a list of all application components which have more than one effective license attached. This might be helpful for spotting cases where appropriate rules for selecting the applicable license in case of dual-/multilicensing is missing.
-
- Changes in 1.1.1
-
-
Corrected order of license name mapping which prevented Unlicense, The W3C License, WTFPL, Zlib and Zope Public License 2.1 to be mapped.
-
- Changes in 1.1.0
-
-
https://github.com/devonfw/solicitor/issues/67: Inclusion of detailed license information for the dependencies included in the executable JAR. Use the '-eug' command line option to store this file (together with a copy of the user guide) in the current work directory.
-
Additional rules for license name mappings in decision table LicenseNameMappingSample.xls.
-
https://github.com/devonfw/solicitor/pull/61: Solicitor can now run with Java 8 or Java 11.
-
- Changes in 1.0.8
-
-
https://github.com/devonfw/solicitor/issues/62: New Reader of type
npm-license-checkerfor reading component/license data collected by NPM License Checker (https://www.npmjs.com/package/license-checker). The type of the existing Reader for reading CSV data from the NPM License Crawler has been changed fromnpmtonpm-license-crawler-csv. (npmis still available but deprecated.) Projects should adopt their Reader configuration and replace typenpmbynpm-license-crawler-csv.
-
- Changes in 1.0.7
-
-
https://github.com/devonfw/solicitor/issues/56: Enable continuing analysis in multiapplication projects even is some license files are unavailable.
-
Described simplified usage of license-maven-plugin without need to change pom.xml. (Documentation only)
-
Ensure consistent sorting even in case that multiple "Ignored" licenses exist for a component
-