Label Reader API
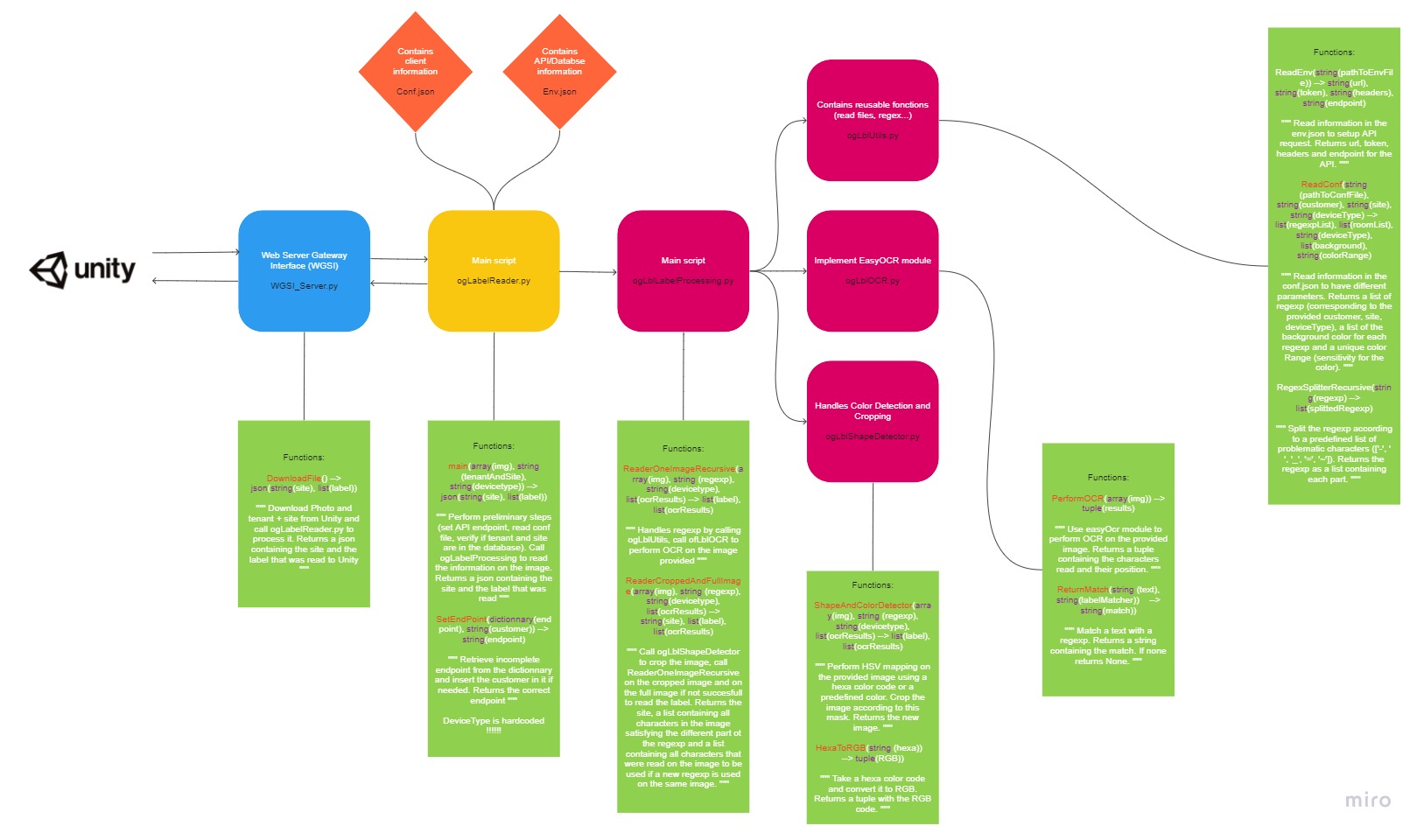
- Architecture of the label reader API
- Easy OCR and its drawbacks
- Reading the logs
- Label_regular vs label_specific
- Output of the Python Server in label_regular
To make Optical Character Recognition (OCR), we used the easy OCR module available at the following link: https://github.com/JaidedAI/EasyOCR
EasyOCR is nice to use because the installation is quite simple and it works whether you have GPUs or not. It is very effective to read texts but can still be used to read characters that do not have a meaning (e.g: a label of a rack) even though it is a little bit less precise.
Some of the flaws of easy OCR are that it can only read from left to right/top to bottom and that it sometimes cuts labels into several parts. This was quite an issue for us as we are using regular expressions, so if the label is cut, it cannot be matched.
To solve this issue, we decided to split the regular expression into multiple parts to ensure the matching. e.g: Ro[1-3]-Rack[A-B][0-9] --> Ro[1-3],Rack[A-B][0-9]
When trying to read: Ro3-RackB2, if easy OCR reads:
Line 1: Ro3
Line 2: -
Line 3: RackB2
We will match the different parts and return [Ro3, RackB2].
We may mismatch some parts of the regex if they are only made from 1 or 2 characters but in the end, we catch a lot of the labels that would not have been read otherwise.
Below is an example of a log produced while reading a label


You can see numbers on these logs. I added them to highlight the process of the script.
- Reading informations from the images sent from the Hololens2.
- Comparing tenant and deviceType received with .conf.json to find associated full regular expressions.
- Checking if the pair tenant/site is correct with an API call.
- Crop the image using the color in .conf.json associated to the full regular expression.
- Read text line by line on cropped image and compare with 1st part of the regex. Repeat with next regular expression parts.
- If there was no match with the 1st full regular expressions on the cropped image, read text line by line on full image and compare with 1st part of the regex.
- If there was no match with the 1st full regular expressions on the full image, repeat Process from Step 6 with next full regular expressions (not represented).
I decided to use this process to optimize the processing time of the script. The most costly part (in time) is reading the characters on an image using easyOCR. We try to read on a cropped image to reduce the time needed to read the character. If it did not work we use the whole image (which a lot longer). If there were no match with the 1st full regular expression, we can directly reuse the characters that were read on the full image (we do not need to do it again) so we skip the steps with the cropped image.
label_regular is set to work for any use case by not doing any correction to the text read with esayOCR. Hence, they are less precise but can be adapted to another regular expression. label_specific is including a number of corrections to the text specific to our use case. It is more precise in our case but cannot be adapted to another regular expression in an easy way. Please note that label_specific was the previous version of label_regular and thus has less detailed logs while having messier code.
The current output of the python server is a JSON with the following information:
{
"site": site,
"room": label[0],
"rack": label[1],
}
with site referring to the site provided in the Unity application and label the list containing the text corresponding to each part of the regular expression provided.
In our case, label[0] refers to the room, and label[1] refers to the rack.
To adapt this code, one needs to adapt the dictionary built in the ogLabelReader.py file.