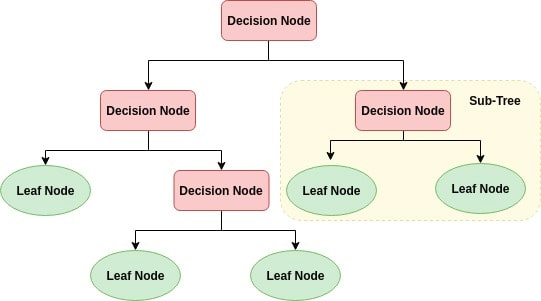
A decision tree is a flowchart-like tree structure where an internal node represents feature(or attribute), the branch represents a decision rule, and each leaf node represents the outcome. This flowchart-like structure helps us in decision making.
{kind=link}
{kind=link}
- min_samples_split (default value = 2) nodes cannot be further seperated below this value.
- criterion : optional (default=”gini”) It controls how a Decision Tree decides where to split the data. It is the measure of impurity in a bunch of examples. This parameter allows us to use the different-different attribute selection measure. Supported criteria are “gini” for the Gini index and “entropy” for the information gain.
- splitter This parameter allows us to choose the split strategy. Supported strategies are “best” to choose the best split and “random” to choose the best random split.
https://scikit-learn.org/stable/modules/generated/sklearn.tree.DecisionTreeClassifier.html
Import the following libraries:
from sklearn.tree import export_graphviz
from sklearn.externals.six import StringIO
from IPython.display import Image
import pydotplus
If the error Graphviz executables not found occurs, then run the following command:
import os
os.environ['PATH'] = os.environ['PATH']+';'+os.environ['CONDA_PREFIX']+r"\Library\bin\graphviz"

