




English | 中文
Make Flink|Spark easier
A magical framework that makes Flink development easier
The original intention of StreamX is to make the development of Flink easier. StreamX focuses on the management of development phases
and tasks. Our ultimate goal is to build a one-stop big data solution integrating stream processing, batch processing, data warehouse and
data laker.


- Scaffolding
- Out-of-the-box connectors
- Support maven compilation
- Configuration
- Multi version flick support(1.12.x,1.13.x,1.14.x)
- on Kubernetes deployment (
K8s-Native-Application/K8s-Native-Session) - on YARN deployment (
YARN-Application/YARN-Per-Job) - Support
ApplicaionandYarn-Per-Jobmode start,stop,savepoint, resume fromsavepoint- Flame graph
- Notebook
- Project configuration and dependency version management
- Task backup and rollback
- Manage dependencies
- UDF
- Flink SQL WebIDE
- Catalog、Hive
- Full support from task
developmenttodeployment - ...
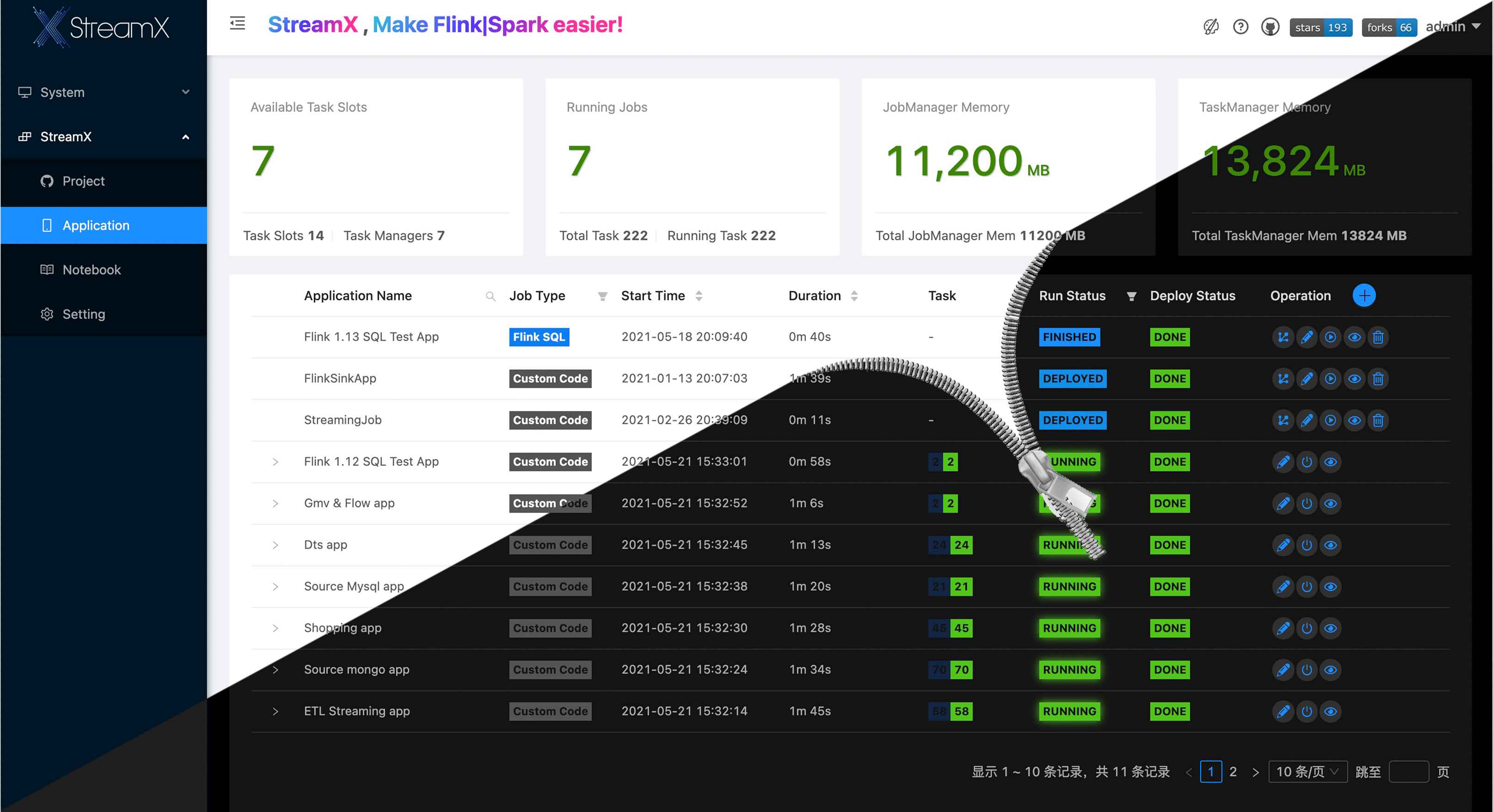

Streamx consists of three parts,streamx-core,streamx-pump and streamx-console
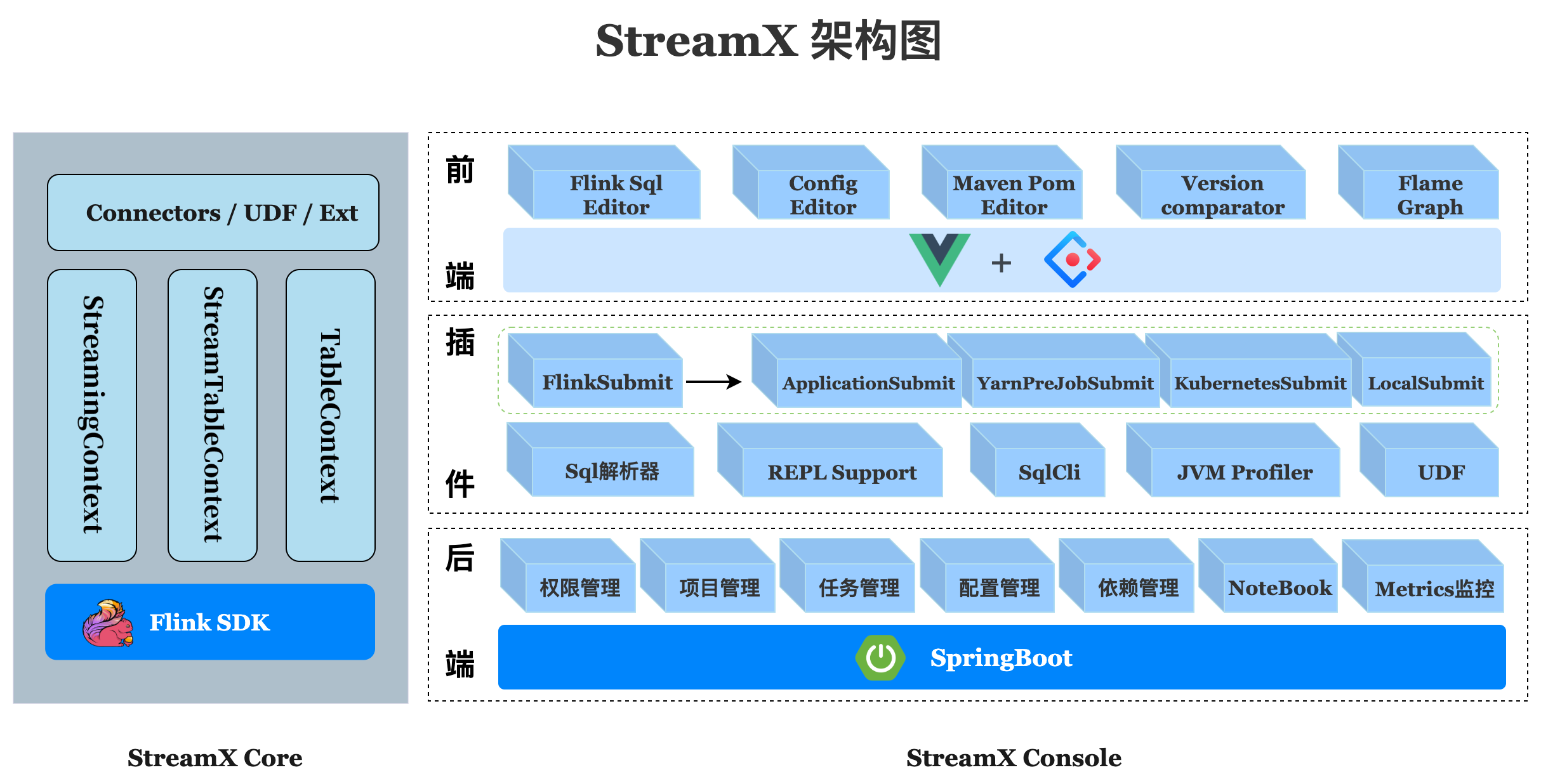
streamx-core is a framework that focuses on coding, standardizes configuration, and develops in a way that is better than configuration by
convention. Also it provides a development-time RunTime Content and a series of Connector out of the box. At the same time, it
extends DataStream some methods, and integrates DataStream and Flink sql api to simplify tedious operations, focus on the business
itself, and improve development efficiency and development experience.
streamx-pump is a planned data extraction component, similar to flinkx. Based on the various connector provided in streamx-core, the
purpose is to create a convenient, fast, out-of-the-box real-time data extraction and migration component for big data, and it will be
integrated into the streamx-console.
streamx-console is a stream processing and Low Code platform, capable of managing Flink tasks, integrating project compilation,
deploy, configuration, startup, savepoint, flame graph, Flink SQL, monitoring and many other features. Simplify the daily operation
and maintenance of the Flink task.
Our ultimate goal is to build a one-stop big data solution integrating stream processing, batch processing, data warehouse and data laker.
- Apache Flink
- Apache YARN
- Spring Boot
- Mybatis
- Mybatis-Plus
- Flame Graph
- JVM-Profiler
- Vue
- VuePress
- Ant Design of Vue
- ANTD PRO VUE
- xterm.js
- Monaco Editor
- ...
Thanks to the above excellent open source projects and many outstanding open source projects that are not mentioned, for giving the greatest respect, special thanks to Apache Zeppelin , IntelliJ IDEA, Thanks to the fire-spark project for the early inspiration and help.
git clone https://github.com/streamxhub/streamx.git
cd streamx
./mvnw clean install -DskipTests -Denv=prod
click Document for more information
Apache Zeppelin is a Web-based notebook that enables data-driven, interactive data analytics and collaborative documents with SQL, Java, Scala and more.
At the same time we also need a one-stop tool that can cover development, test, package, deploy, and start.
streamx-console solves these pain points very well, positioning is a one-stop stream processing platform, and has developed more exciting
features (such as Flink SQL WebIDE, dependency isolation, task rollback , flame diagram
etc.)
FlinkX is a distributed offline and real-time data synchronization framework based on flink widely used in DTStack, which realizes efficient data migration between multiple heterogeneous data sources.
StreamX focuses on the management of development phases and tasks. The streamx-pump module is also under planning, dedicated to solving
data source migration, and will eventually be integrated into the streamx-console.
You can submit any ideas as pull requests or as GitHub issues.
If you're new to posting issues, we ask that you read How To Ask Questions The Smart Way (This guide does not provide actual support services for this project!), How to Report Bugs Effectively prior to posting. Well written bug reports help us help you!
Thanks to JetBrains for supporting us free open source licenses.

Are you enjoying this project ? 👋
If you like this framework, and appreciate the work done for it to exist, you can still support the developers by donating ☀️ 👊
| WeChat Pay | Alipay |
|---|---|
 |
 |
Welcome individuals and enterprises to sponsor, your support will help us better develop the project







Thank you to all our backers!
StreamX enters the high-speed development stage, we need your contribution.

