Speech-to-Text-WaveNet2 : End-to-end sentence level English speech recognition using DeepMind's WaveNet
A tensorflow implementation of speech recognition based on DeepMind's WaveNet: A Generative Model for Raw Audio. (Hereafter the Paper)
The architecture is shown in the following figure.
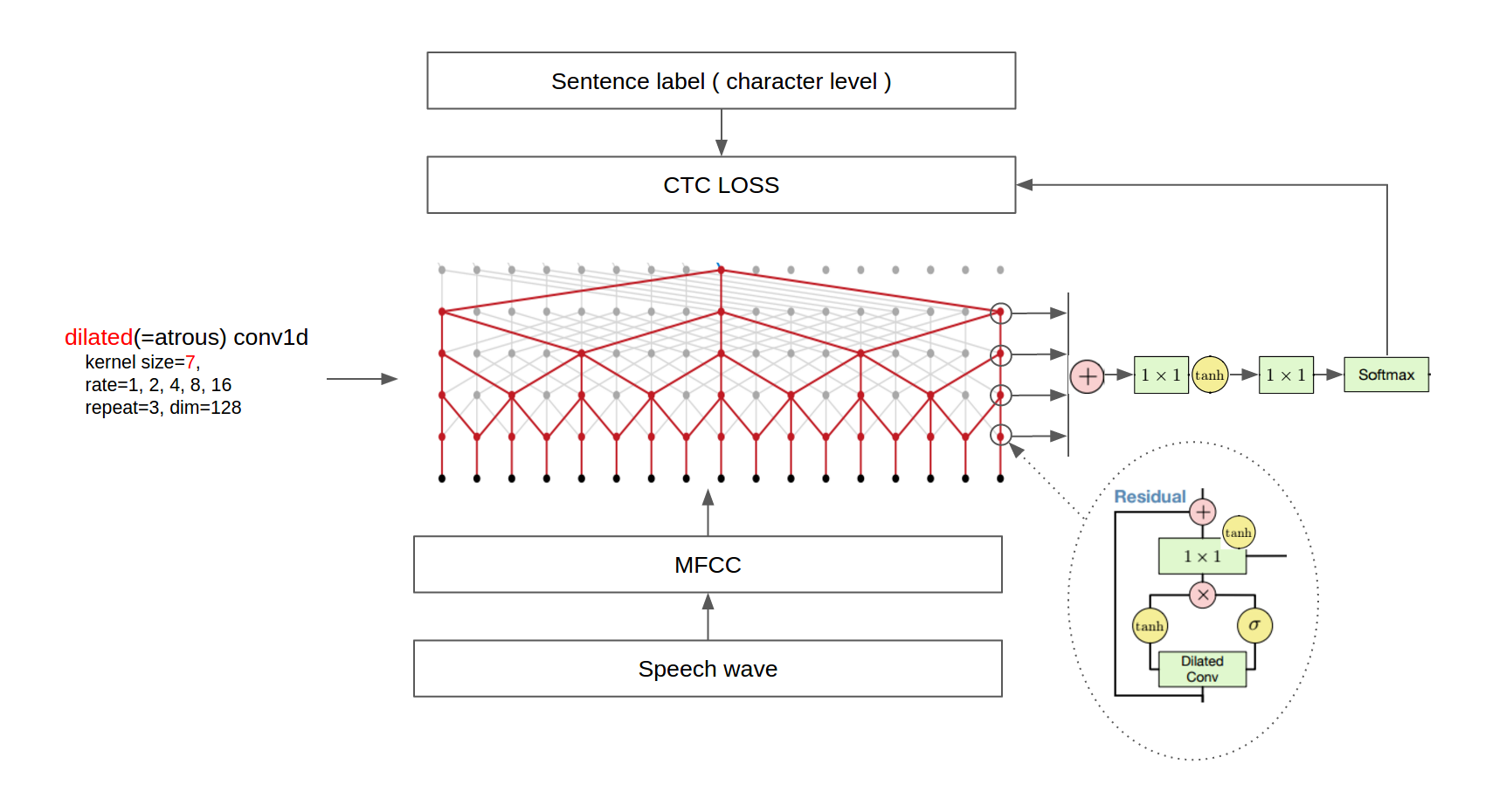
Current Version : 2.1.0.0
- demo
- test
- train
- train model
- tensorflow >= 1.12.0
- librosa
- glog
- nltk
If you have problems with the librosa library, try to install ffmpeg by the following command. ( Ubuntu 14.04 )
sudo add-apt-repository ppa:mc3man/trusty-media
sudo apt-get update
sudo apt-get dist-upgrade -y
sudo apt-get -y install ffmpeg
Audio was augmented by the scheme in the Tom Ko et al's paper. (Thanks @migvel for your kind information)
Exculte
python ***.py --help
to get help when you use ***.py
- Download and extract dataset(only VCTK support now, other will coming soon)
- Assume the directory of VCTK dataset is f:/speech, Execute
python tools/create_tf_record.py -input_dir='/zhzhao/VCTK'
to create record for train or test
- Rename config/config.json.example to config/english-28.json
- Execute
python train.py
to train model.
Execute
python test.py
to evalute model.
1.Download pretrain model(buriburisuri model) and extract to 'release' directory
2.Execute
python demo.py -input_path
to transform a speech wave file to the English sentence. The result will be printed on the console.
For example, try the following command.
python demo.py -input_path=data/demo.wav -ckpt_dir=release/buriburisuri
The result will be as follows:
please scool stella
The ground truth is as follows:
PLEASE SCOOL STELLA
As mentioned earlier, there is no language model, so there are some cases where capital letters, punctuations, and words are misspelled.
- buriburisuri model : convert model from https://github.com/buriburisuri/speech-to-text-wavenet.
- try to tokenlize the english label with nltk
- train with all punctuation
- add attention layer
- buriburisuri's speech-to-text-wavenet
- ibab's WaveNet(speech synthesis) tensorflow implementation
- tomlepaine's Fast WaveNet(speech synthesis) tensorflow implementation
- SugarTensor
- EBGAN tensorflow implementation
- Timeseries gan tensorflow implementation
- Supervised InfoGAN tensorflow implementation
- AC-GAN tensorflow implementation
- SRGAN tensorflow implementation
- ByteNet-Fast Neural Machine Translation
If you find this code useful please cite us in your work:
Kim and Park. Speech-to-Text-WaveNet. 2016. GitHub repository. https://github.com/buriburisuri/.
Namju Kim ([email protected]) at KakaoBrain Corp.
Kyubyong Park ([email protected]) at KakaoBrain Corp.