[Add] Logits Processor Zoo with HF Transformers #2524
There are no files selected for viewing
{kind=link}
| Original file line number | Diff line number | Diff line change |
|---|---|---|
| @@ -0,0 +1,383 @@ | ||
| --- | ||
| title: "Controlling Language Model Generation with NVIDIA's LogitsProcessorZoo" | ||
| thumbnail: /blog/assets/logits-processor-zoo/thumbnail.png | ||
| authors: | ||
| - user: ariG23498 | ||
| - user: aerdem | ||
| guest: true | ||
| org: nvidia | ||
|
There was a problem hiding this comment. This author profile does not seem to belong to the nvidia org. |
||
| --- | ||
|
|
||
| # Controlling Language Model Generation with NVIDIA's LogitsProcessorZoo | ||
|
There was a problem hiding this comment. I love how the intro provides great context now, thank you! 🙌 |
||
|
|
||
| > **Struggling to get language models to follow your instructions?** | ||
|
|
||
| NVIDIA's [LogitsProcessorZoo](https://github.com/NVIDIA/logits-processor-zoo/tree/main) provides powerful tools for controlling the behavior of language models during text generation. Whether you want to control sequence lengths, enforce specific phrases, or guide multiple-choice answers, this library offers precise control over model outputs. In this post, we'll dive into its features and show how you can use it to refine your AI workflows. | ||
|
|
||
| ## What Are Logits in Language Models? | ||
ariG23498 marked this conversation as resolved.
Show resolved
Hide resolved
|
||
|
|
||
| 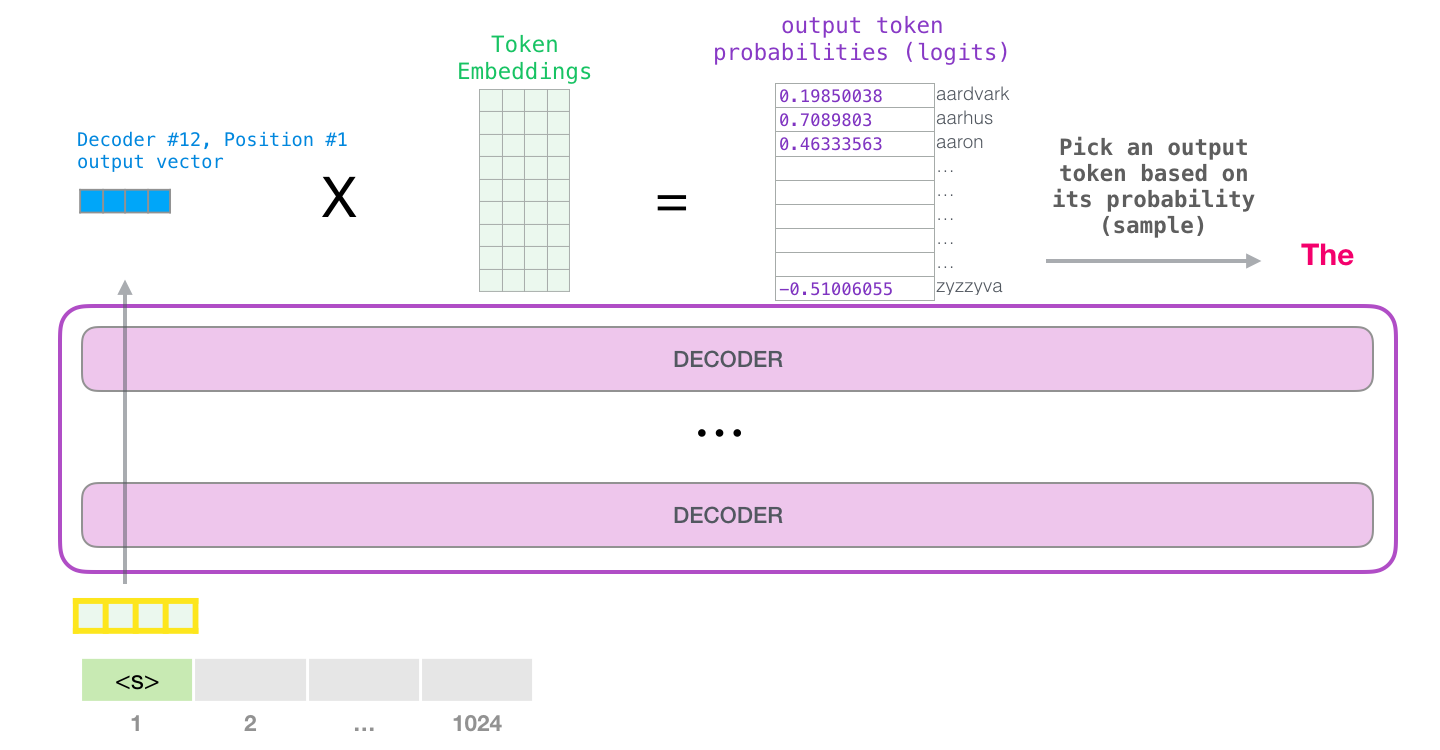 | ||
| Taken from: https://jalammar.github.io/illustrated-gpt2/ | ||
|
|
||
| Logits are the raw, unnormalized scores generated by language models for each token in their vocabulary. These scores are transformed into probabilities via the **softmax** function, guiding the model in selecting the next token. | ||
|
|
||
| Here's an example of how logits fit into the generation process: | ||
|
|
||
| ```python | ||
| from transformers import AutoTokenizer, AutoModelForCausalLM | ||
| import torch | ||
|
|
||
| # Load a model and tokenizer | ||
| model_name = "meta-llama/Llama-3.2-1B" | ||
| tokenizer = AutoTokenizer.from_pretrained(model_name) | ||
| model = AutoModelForCausalLM.from_pretrained(model_name, torch_dtype=torch.bfloat16, device_map="auto") | ||
|
|
||
| # Input text | ||
| prompt = "The capital of France is" | ||
| inputs = tokenizer(prompt, return_tensors="pt").to(model.device) | ||
|
|
||
| # Get logits | ||
| with torch.inference_mode(): | ||
| outputs = model(**inputs) | ||
| logits = outputs.logits | ||
|
|
||
| # Logits for the last token | ||
| last_token_logits = logits[:, -1, :] | ||
| ``` | ||
|
|
||
| These logits represent the model's confidence for each potential next word. Using softmax, we can turn them into probabilities and decode them into the generated text: | ||
|
|
||
| ```python | ||
| # Prediction for the next token | ||
| next_token_probs = torch.nn.functional.softmax(last_token_logits, dim=-1) | ||
|
|
||
| # Decode logits to generate text | ||
| predicted_token_ids = torch.argmax(next_token_probs, dim=-1) | ||
| generated_text = tokenizer.batch_decode(predicted_token_ids, skip_special_tokens=True) | ||
| print("Generated Text:", generated_text[0]) | ||
|
|
||
| >>> Generated Text: Paris | ||
| ``` | ||
|
|
||
| While this pipeline works for general text generation, **raw logits are not optimized for task-specific constraints or custom behaviors**. This is where logit processing becomes indispensable. | ||
ariG23498 marked this conversation as resolved.
Show resolved
Hide resolved
|
||
|
|
||
| ## Why Process Logits? | ||
|
|
||
| Raw logits often fall short when controlling output behavior. For example: | ||
|
|
||
| - **Lack of constraints:** They might not adhere to required formats, grammar rules, or predefined structures. | ||
| - **Overgeneralization:** The model could prioritize generic responses instead of specific, high-quality outputs. | ||
| - **Task misalignment:** Sequences may end too early, be overly verbose, or miss critical details. | ||
|
|
||
| Logit processing enables us to tweak the model's behavior by modifying these raw scores before generation. | ||
|
|
||
| ## NVIDIA's LogitsProcessorZoo | ||
ariG23498 marked this conversation as resolved.
Show resolved
Hide resolved
|
||
|
|
||
| NVIDIA's [LogitsProcessorZoo](https://github.com/NVIDIA/logits-processor-zoo) simplifies post-processing of logits with modular components tailored for specific tasks. | ||
| Let's explore its features and see how to use them. To follow along, head over to | ||
| [the notebook](https://huggingface.co/datasets/ariG23498/quick-notebooks/blob/main/nvidia-logits-processor-zoo.ipynb) and experiment with the logits processors. | ||
|
|
||
| Install the library using: | ||
|
|
||
| ```bash | ||
| pip install logits-processor-zoo | ||
| ``` | ||
|
|
||
| To demonstrate the processors, we'll create a simple `LLMRunner` class that initializes a model and tokenizer, exposing a `generate_response` method. | ||
|
There was a problem hiding this comment. I'd maybe mention that we need to supply a list of processors to control generation. |
||
|
|
||
| ```python | ||
| # Adapted from: https://github.com/ariG23498/logits-processor-zoo/blob/main/example_notebooks/transformers/utils.py | ||
|
There was a problem hiding this comment. Is there a reason to use your fork instead of nvidia's? There was a problem hiding this comment. We are currently working on a PR with which we will be able to use |
||
| class LLMRunner: | ||
| def __init__(self, model_name="meta-llama/Llama-3.2-1B-Instruct"): | ||
| self.tokenizer = AutoTokenizer.from_pretrained(model_name) | ||
|
|
||
| self.model = AutoModelForCausalLM.from_pretrained( | ||
| model_name, | ||
| torch_dtype=torch.float16, | ||
|
There was a problem hiding this comment. nit: why not bfloat16, as recommended for this particular model and as used in the first code snippet of the post? There was a problem hiding this comment. Thanks for the catch. I missed the |
||
| device_map="auto", | ||
| ) | ||
|
|
||
| def generate_response(self, prompts, logits_processor_list=None, max_tokens=1000): | ||
| if logits_processor_list is None: | ||
| logits_processor_list = [] | ||
|
|
||
| for prompt in prompts: | ||
| conversation = [ | ||
| {"role": "system", "content": "You are a helpful assistant."}, | ||
| {"role": "user", "content": prompt}, | ||
| ] | ||
| inputs = self.tokenizer.apply_chat_template( | ||
| conversation, | ||
| tokenize=True, | ||
| add_generation_prompt=True, | ||
| return_tensors="pt", | ||
| return_dict=True, | ||
| ).to(self.model.device) | ||
|
|
||
| with torch.inference_mode(): | ||
ariG23498 marked this conversation as resolved.
Show resolved
Hide resolved
|
||
| outputs = self.model.generate( | ||
| **inputs, | ||
| max_new_tokens=max_tokens, | ||
| min_new_tokens=1, | ||
| logits_processor=LogitsProcessorList(logits_processor_list), | ||
| ) | ||
|
|
||
| gen_output = self.tokenizer.batch_decode( | ||
| outputs, skip_special_tokens=True, clean_up_tokenization_spaces=False | ||
| ) | ||
| # Extract only the generated output after the original input length | ||
| generated_text = gen_output[0][ | ||
| len( | ||
| self.tokenizer.decode( | ||
| inputs["input_ids"][0], skip_special_tokens=True | ||
| ) | ||
| ) : | ||
| ].strip() | ||
|
|
||
| print(f"Prompt: {prompt}") | ||
| print() | ||
| print(f"LLM response:\n{generated_text}") | ||
|
|
||
| runner = LLMRunner() | ||
| ``` | ||
|
|
||
| ### 1. GenLengthLogitsProcessor | ||
|
|
||
| Control the length of generated sequences by adjusting the likelihood of the end-of-sequence (EOS) token. | ||
|
|
||
| This processor is particularly useful in scenarios where the desired length of generated text plays a | ||
| crucial role, such as generating concise summaries, restricting verbose outputs, or tailoring responses | ||
| to specific use cases. For instance, it can help ensure that a chatbot provides short and meaningful | ||
| responses while maintaining grammatical integrity by completing sentences when required. | ||
|
|
||
| ```py | ||
| example_prompts =[ | ||
| "Tell me a story about a kid lost in forest." | ||
| ] | ||
|
|
||
| # generate short response | ||
| print(runner.generate_response( | ||
| example_prompts, | ||
| [GenLengthLogitsProcessor(runner.tokenizer, boost_factor=0.1, p=2, complete_sentences=True)] | ||
|
There was a problem hiding this comment. A short mention of what |
||
| )) | ||
|
|
||
| >>> Prompt: Tell me a story about a kid lost in forest. | ||
|
|
||
| LLM response: | ||
| Once upon a time, in a dense forest, there lived a young boy named Timmy. Timmy was on a family camping trip with his parents and little sister, Emma. They had been walking for hours, and the dense trees seemed to close in around them. As the sun began to set, Timmy realized he had wandered away from his family. | ||
|
|
||
| At first, Timmy didn't panic. He thought about calling out for his parents and Emma, but his voice was hoarse from singing campfire songs. He looked around, but the trees seemed to stretch on forever, making it impossible to see any familiar landmarks. | ||
|
|
||
| As the darkness grew thicker, Timmy's fear began to creep in. | ||
| ``` | ||
|
|
||
| ```py | ||
| # generate long response | ||
| print(runner.generate_response( | ||
| example_prompts, | ||
| [GenLengthLogitsProcessor(runner.tokenizer, boost_factor=-10.0, p=0, complete_sentences=False)] | ||
| )) | ||
|
|
||
| >>> Prompt: Tell me a story about a kid lost in forest. | ||
|
|
||
| LLM response: | ||
| Once upon a time, in a dense and vibrant forest, there lived a young boy named Max. Max was an adventurous and curious 8-year-old who loved exploring the outdoors. One sunny afternoon, while wandering through the forest, he stumbled upon a narrow path he had never seen before. | ||
|
|
||
| Excited by the discovery, Max decided to follow the path and see where it would lead. The forest was teeming with life, and the sunlight filtering through the trees created a magical atmosphere. Max walked for about 20 minutes, his eyes scanning the surroundings for any signs of civilization. | ||
|
There was a problem hiding this comment. I'm not sure how the text would render inside a |
||
|
|
||
| As the sun began to set, casting a warm orange glow over the forest, Max realized he was lost. He had no phone, no wallet, and no way to communicate with his family. Panic started to set in, and Max began to feel scared and alone. | ||
|
|
||
| Panicked, Max started to run through the forest, his heart racing and his legs trembling. He stumbled upon a clearing and saw a faint light in the distance. As he approached, he saw a small cabin in the center of the clearing. Smoke was rising from the chimney, and Max could hear the sound of someone singing a gentle tune. | ||
|
|
||
| Without hesitation, Max rushed towards the cabin and knocked on the door. A kindly old woman answered, and when she saw Max, she welcomed him with a warm smile. "Hello, young traveler," she said. "What are you doing out here all alone?" | ||
|
|
||
| Max explained his situation, and the old woman listened carefully. She then offered Max a warm cup of tea and a comfortable place to rest. As they talked, Max learned that the old woman was a forest guide, and she had been searching for him all along. | ||
|
|
||
| The old woman took Max on a journey through the forest, teaching him about the different plants, animals, and secrets of the forest. Max learned about the importance of taking care of the environment and respecting the creatures that lived there. | ||
|
|
||
| As the night fell, the old woman invited Max to stay with her for the night. Max was grateful for the kindness and warmth of the old woman, and he drifted off to sleep with a heart full of joy and a mind full of wonder. | ||
|
|
||
| The next morning, the old woman helped Max find his way back to the path he had taken. As they said their goodbyes, the old woman handed Max a small gift – a small wooden acorn with a note that read, "Remember, the forest is full of magic, but it's also full of kindness. Always look for it." | ||
|
|
||
| Max returned home, forever changed by his experience in the forest. He never forgot the kindness of the old woman and the magic of the forest, and he always carried the lessons he learned with him. | ||
|
|
||
| From that day on, Max became known as the forest explorer, and his love for the outdoors was only matched by his love for the people he met along the way. And whenever he looked up at the stars, he remembered the wise words of the old woman: "The forest is full of magic, but it's also full of kindness. Always look for it." | ||
| ``` | ||
|
|
||
ariG23498 marked this conversation as resolved.
Show resolved
Hide resolved
|
||
| In the examples above, we have used the `GenLengthLogitsProcessor` to both shorten and lengthen the | ||
| response generated by the model. | ||
|
|
||
| ### 2. CiteFromPromptLogitsProcessor | ||
|
|
||
| Boost or diminish tokens from the prompt to encourage similar outputs. | ||
|
|
||
| This is particularly valuable in tasks requiring context retention, such as answering questions based | ||
| on a passage, generating summaries with specific details, or producing consistent outputs in dialogue systems. | ||
| For example, in the given code snippet where a user review is analyzed, this processor ensures the | ||
| model generates a response closely tied to the review's content, such as emphasizing opinions about | ||
| the product's price. | ||
|
|
||
| ```py | ||
| example_prompts =[ | ||
| """ | ||
| A user review: very soft, colorful, expensive but deserves its price, stylish. | ||
|
|
||
| What is the user's opinion about the product's price? | ||
| """, | ||
| ] | ||
|
|
||
| # Cite from the Prompt | ||
| print(runner.generate_response( | ||
| example_prompts, | ||
| [CiteFromPromptLogitsProcessor(runner.tokenizer, example_prompts, boost_factor=5.0)], | ||
| max_tokens=50, | ||
| )) | ||
|
|
||
| >>> Prompt: | ||
| A user review: very soft, colorful, expensive but deserves its price, stylish. | ||
|
|
||
| What is the user's opinion about the product's price? | ||
|
|
||
|
There was a problem hiding this comment. I'd remove the prompt repetition here for brevity. |
||
|
|
||
| LLM response: | ||
| Based on the user review, the user's opinion about the product's price is: the user is very satisfied, but the price is expensive, but the product is stylish, soft, and colorful, which is the price the user is willing to pay | ||
| ``` | ||
|
|
||
| Notice how the generation cites the input prompt. | ||
|
|
||
| ### 3. ForceLastPhraseLogitsProcessor | ||
|
|
||
| Force the model to include a specific phrase before ending its output. | ||
|
|
||
| This processor is especially useful in structured content generation scenarios where consistency or | ||
| adherence to a specific format is crucial. It is ideal for tasks like generating citations, | ||
| formal reports, or outputs requiring specific phrasing to maintain a professional or organized presentation. | ||
|
|
||
| ```py | ||
| example_prompts = [ | ||
| """ | ||
| Retrieved information from: https://en.wikipedia.org/wiki/Bulbasaur | ||
| Bulbasaur is a fictional Pokémon species in Nintendo and Game Freak's Pokémon franchise. | ||
| Designed by Atsuko Nishida, Bulbasaur is a Grass and Poison-type, first appearing in Pocket Monsters: Red and Green (Pokémon Red and Blue outside Japan) as a starter Pokémon. | ||
| Since then, it has reappeared in sequels, spin-off games, related merchandise, and animated and printed adaptations of the franchise. | ||
| It is a central character in the Pokémon anime, being one of Ash Ketchum's main Pokémon for the first season, with a different one later being obtained by supporting character May. | ||
| It is featured in various manga and is owned by protagonist Red in Pokémon Adventures. | ||
|
|
||
| What is Bulbasaur? | ||
| """, | ||
| ] | ||
|
|
||
|
|
||
| phrase = "\n\nReferences:" | ||
| batch_size = len(example_prompts) | ||
|
|
||
| print(runner.generate_response( | ||
| example_prompts, | ||
| [ForceLastPhraseLogitsProcessor(phrase, runner.tokenizer, batch_size)] | ||
| )) | ||
|
|
||
|
|
||
| >>> Prompt: | ||
|
|
||
| Retrieved information from: https://en.wikipedia.org/wiki/Bulbasaur | ||
| Bulbasaur is a fictional Pokémon species in Nintendo and Game Freak's Pokémon franchise. | ||
| Designed by Atsuko Nishida, Bulbasaur is a Grass and Poison-type, first appearing in Pocket Monsters: Red and Green (Pokémon Red and Blue outside Japan) as a starter Pokémon. | ||
| Since then, it has reappeared in sequels, spin-off games, related merchandise, and animated and printed adaptations of the franchise. | ||
| It is a central character in the Pokémon anime, being one of Ash Ketchum's main Pokémon for the first season, with a different one later being obtained by supporting character May. | ||
| It is featured in various manga and is owned by protagonist Red in Pokémon Adventures. | ||
|
|
||
| What is Bulbasaur? | ||
|
|
||
|
|
||
| LLM response: | ||
| According to the information retrieved from the Wikipedia article, Bulbasaur is a fictional Pokémon species in the Pokémon franchise. It is a Grass and Poison-type Pokémon, and it has been featured in various forms of media, including: | ||
|
|
||
| - As a starter Pokémon in the first generation of Pokémon games, including Pokémon Red and Blue. | ||
| - As a main character in the Pokémon anime, where it is one of Ash Ketchum's first Pokémon. | ||
| - As a character in the Pokémon manga, where it is owned by protagonist Red. | ||
| - As a character in various other Pokémon media, such as spin-off games and related merchandise. | ||
|
|
||
| Bulbasaur is also a central character in the Pokémon franchise, often appearing alongside other Pokémon and being a key part of the Pokémon world. | ||
|
|
||
| References: | ||
| - https://en.wikipedia.org/wiki/Bulbasaur | ||
|
|
||
| ``` | ||
|
|
||
| ```py | ||
| phrase = "\n\nThanks for trying our RAG application! If you have more questions about" | ||
|
|
||
| print(runner.generate_response(example_prompts, | ||
| [ForceLastPhraseLogitsProcessor(phrase, runner.tokenizer, batch_size)] | ||
| )) | ||
|
|
||
| >>> Prompt: | ||
| Retrieved information from: https://en.wikipedia.org/wiki/Bulbasaur | ||
| Bulbasaur is a fictional Pokémon species in Nintendo and Game Freak's Pokémon franchise. | ||
| Designed by Atsuko Nishida, Bulbasaur is a Grass and Poison-type, first appearing in Pocket Monsters: Red and Green (Pokémon Red and Blue outside Japan) as a starter Pokémon. | ||
| Since then, it has reappeared in sequels, spin-off games, related merchandise, and animated and printed adaptations of the franchise. | ||
| It is a central character in the Pokémon anime, being one of Ash Ketchum's main Pokémon for the first season, with a different one later being obtained by supporting character May. | ||
| It is featured in various manga and is owned by protagonist Red in Pokémon Adventures. | ||
|
|
||
| What is Bulbasaur? | ||
|
|
||
|
|
||
| LLM response: | ||
| Bulbasaur is a fictional Pokémon species in the Pokémon franchise. It is a Grass and Poison-type Pokémon, characterized by its distinctive appearance. | ||
|
|
||
| Thanks for trying our RAG application! If you have more questions about Bulbasaur, feel free to ask. | ||
| ``` | ||
|
|
||
| With each generation we were able to add the `phrase` string right before the end of the generation. | ||
|
|
||
| ### 4. MultipleChoiceLogitsProcessor | ||
|
|
||
| Guide the model to answer multiple-choice questions by selecting one of the given options. | ||
|
|
||
| This processor is particularly useful in tasks requiring strict adherence to a structured answer format, | ||
| such as quizzes, surveys, or decision-making support systems. | ||
|
|
||
| ```py | ||
| example_prompts = [ | ||
| """ | ||
| I am getting a lot of calls during the day. What is more important for me to consider when I buy a new phone? | ||
| 0. Camera | ||
| 1. Battery | ||
| 2. Operating System | ||
| 3. Screen Resolution | ||
|
|
||
| Answer: | ||
| """, | ||
| ] | ||
|
|
||
| mclp = MultipleChoiceLogitsProcessor( | ||
| runner.tokenizer, | ||
| choices=["0", "1", "2", "3"], | ||
| delimiter="." | ||
| ) | ||
|
|
||
| print(runner.generate_response(example_prompts, [mclp], max_tokens=1)) | ||
|
|
||
| >>> Prompt: | ||
| I am getting a lot of calls during the day. What is more important for me to consider when I buy a new phone? | ||
| 0. Camera | ||
| 1. Battery | ||
| 2. Operating System | ||
| 3. Screen Resolution | ||
|
|
||
| Answer: | ||
|
|
||
|
|
||
| LLM response: | ||
| 1 | ||
| ``` | ||
|
|
||
| Here our model does not generate anything other than the choice. This is an immensely helpful attribute while | ||
| working with agents or using models for multiple choice questions. | ||
|
|
||
| ## Hugging Face's LogitsProcessor API | ||
|
|
||
| While NVIDIA's LogitsProcessorZoo is powerful, it's worth mentioning Hugging Face's [LogitsProcessor API](https://huggingface.co/docs/transformers/en/internal/generation_utils#logitsprocessor). Explore the `transformers` documentation for more details and examples. | ||
ariG23498 marked this conversation as resolved.
Show resolved
Hide resolved
|
||
|
|
||
| ## Wrapping Up | ||
|
|
||
| Logit processing is a powerful tool to refine and customize language model outputs. With NVIDIA's **LogitsProcessorZoo** and Hugging Face's `transformers` processors, you can tailor your model's behavior to meet specific requirements. Ready to take your LLMs to the next level? Install these tools and start experimenting today! | ||
ariG23498 marked this conversation as resolved.
Show resolved
Hide resolved
|
||
There was a problem hiding this comment.
Choose a reason for hiding this comment
The reason will be displayed to describe this comment to others. Learn more.
Reminder to update