
![]()
![]()
![]()
Unlock the full potential of CommonCrawl data with CmonCrawl, the most versatile extractor that offers unparalleled modularity and ease of use.
CmonCrawl stands out from the crowd with its unique features:
- High Modularity: Easily create custom extractors tailored to your specific needs.
- Comprehensive Access: Supports all CommonCrawl access methods, including AWS Athena and the CommonCrawl Index API for querying, and S3 and the CommonCrawl API for downloading.
- Flexible Utility: Accessible via a Command Line Interface (CLI) or as a Software Development Kit (SDK), catering to your preferred workflow.
- Type Safety: Built with type safety in mind, ensuring that your code is robust and reliable.
$ pip install cmoncrawl$ git clone https://github.com/hynky1999/CmonCrawl
$ cd CmonCrawl
$ pip install -r requirements.txt
$ pip install .Begin by preparing your custom extractor. Obtain sample HTML files from the CommonCrawl dataset using the command:
$ cmon download --match_type=domain --limit=100 html_output example.com htmlThis will download a first 100 html files from example.com and save them in html_output.
Create a new Python file for your extractor, such as my_extractor.py, and place it in the extractors directory. Implement your extraction logic as shown below:
from bs4 import BeautifulSoup
from cmoncrawl.common.types import PipeMetadata
from cmoncrawl.processor.pipeline.extractor import BaseExtractor
class MyExtractor(BaseExtractor):
def __init__(self):
# you can force a specific encoding if you know it
super().__init__(encoding=None)
def extract_soup(self, soup: BeautifulSoup, metadata: PipeMetadata):
# here you can extract the data you want from the soup
# and return a dict with the data you want to save
body = soup.select_one("body")
if body is None:
return None
return {
"body": body.get_text()
}
# You can also override the following methods to drop the files you don't want to extracti
# Return True to keep the file, False to drop it
def filter_raw(self, response: str, metadata: PipeMetadata) -> bool:
return True
def filter_soup(self, soup: BeautifulSoup, metadata: PipeMetadata) -> bool:
return True
# Make sure to instantiate your extractor into extractor variable
# The name must match so that the framework can find it
extractor = MyExtractor()Set up a configuration file, config.json, to specify the behavior of your extractor(s):
{
"extractors_path": "./extractors",
"routes": [
{
# Define which url match the extractor, use regex
"regexes": [".*"],
"extractors": [{
"name": "my_extractor",
# You can use since and to choose the extractor based
on the date of the crawl
# You can ommit either of them
"since": "2009-01-01",
"to": "2025-01-01"
}]
},
# More routes here
]
}Please note that the configuration file config.json must be a valid JSON. Therefore, comments as shown in the example above cannot be included directly in the JSON file.
Test your extractor with the following command:
$ cmon extract config.json extracted_output html_output/*.html htmlAfter testing, start the full crawl and extraction process:
cmon download --match_type=domain --limit=100 dr_output example.com recordThis will download the first 100 records from example.com and save them in dr_output. By default it saves 100_000 records per file, you can change this with the --max_crawls_per_file option.
$ cmon extract --n_proc=4 config.json extracted_output dr_output/*.jsonl recordNote that you can use the --n_proc option to specify the number of processes to use for the extraction. Multiprocessing is done on file level, so if you have just one file it will not be used.
Before implementing any of the strategies to mitigate high error responses, it is crucial to first check the status of the CommonCrawl gateway and S3 buckets. This can provide valuable insights into any ongoing performance issues that might be affecting your access rates. Consult the CommonCrawl status page for the latest updates on performance issues: Oct-Nov 2023 Performance Issues.
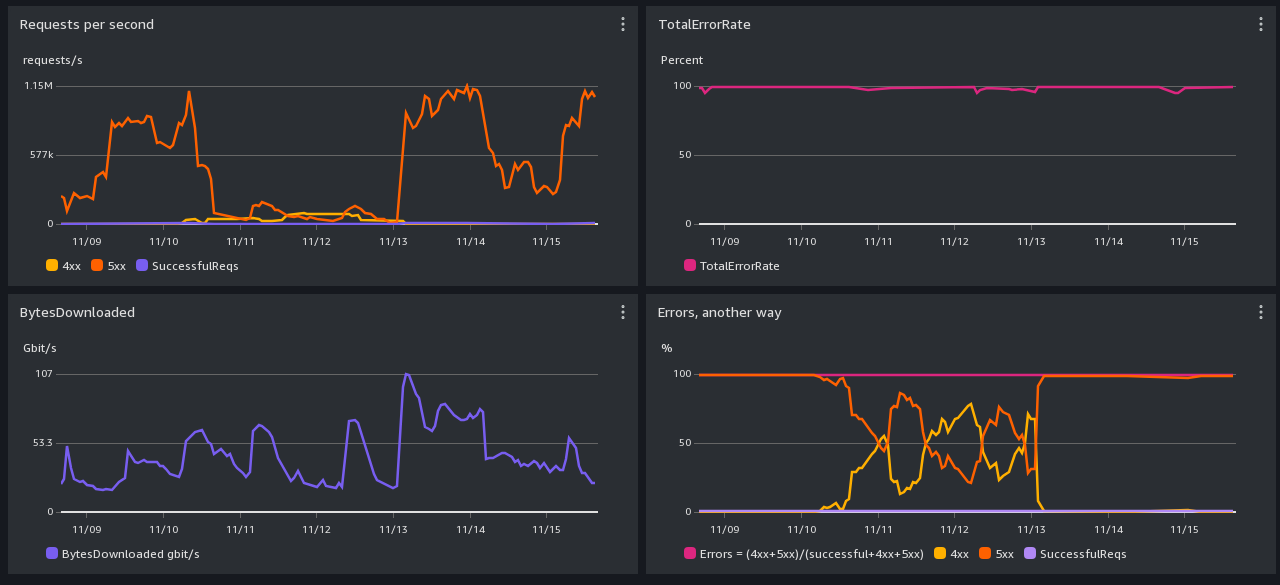
Encountering a high number of error responses usually indicates excessive request rates. To mitigate this, consider the following strategies in order:
-
Switch to S3 Access: Instead of using the API Gateway, opt for S3 access which allows for higher request rates.
-
Regulate Request Rate: The total requests per second are determined by the formula
n_proc * max_requests_per_process. To reduce the request rate:- Decrease the number of processes (
n_proc). - Reduce the maximum requests per process (
max_requests_per_process).
Aim to maintain the total request rate below 40 per second.
- Decrease the number of processes (
-
Adjust Retry Settings: If errors persist:
- Increase
max_retryto ensure eventual data retrieval. - Set a higher
sleep_baseto prevent API overuse and to respect rate limits.
- Increase
CmonCrawl was designed with flexibility in mind, allowing you to tailor the framework to your needs. For distributed extraction and more advanced scenarios, refer to our documentation and the CZE-NEC project.
For practical examples and further assistance, visit our examples directory.
Join our community of contributors on GitHub. Your contributions are welcome!
CmonCrawl is open-source software licensed under the MIT license.