Visit the Website
Don't know that much about programming? Or you don't have enough time? Then visit the Web Version
You can just input your keywords, and dont have to worry about the programming part.
Besides the information which can be retrieved via the free twitterscraper tool, the website also retrieves user information.
A simple script to scrape for Tweets using the Python package requests to retrieve the content and Beautifullsoup4 to parse the retrieved content.
Twitter has provided REST API's which can be used by developers to access and read Twitter data. They have also provided a Streaming API which can be used to access Twitter Data in real-time.
Most of the software written to access Twitter data provide a library which functions as a wrapper around Twitters Search and Streaming API's and therefore are limited by the limitations of the API's.
With Twitter's Search API you can only sent 180 Requests every 15 minutes. With a maximum number of 100 tweets per Request this means you can mine for 4 x 180 x 100 = 72.000 tweets per hour. By using TwitterScraper you are not limited by this number but by your internet speed/bandwith and the number of instances of TwitterScraper you are willing to start.
One of the bigger disadvantages of the Search API is that you can only access Tweets written in the past 7 days. This is a major bottleneck for anyone looking for older past data to make a model from. With TwitterScraper there is no such limitation.
Per Tweet it scrapes the following information: + Username and Full Name + Tweet-id + Tweet-url + Tweet text + Tweet html + Tweet timestamp + No. of likes + No. of replies + No. of retweets
To install twitterscraper:
(sudo) pip install twitterscraperor you can clone the repository and in the folder containing setup.py
python setup.py installYou can use the command line application to get your tweets stored to JSON right away. Twitterscraper takes several arguments:
-hor--helpPrint out the help message and exits.-lor--limitTwitterScraper stops scraping when at least the number of tweets indicated with--limitis scraped. Since tweets are retrieved in batches of 20, this will always be a multiple of 20. Omit the limit to retrieve all tweets. You can at any time abort the scraping by pressing Ctrl+C, the scraped tweets will be stored safely in your JSON file.--langRetrieves tweets written in a specific language. Currently 30+ languages are supported. For a full list of the languages print out the help message.-bdor--begindateSet the date from which TwitterScraper should start scraping for your query. Format is YYYY-MM-DD. The default value is set to 2006-03-21. This does not work in combination with--user.-edor--enddateSet the enddate which TwitterScraper should use to stop scraping for your query. Format is YYYY-MM-DD. The default value is set to today. This does not work in combination with--user.-uor--userScrapes the tweets from that users profile page. This also includes all retweets by that user. See examples below.-por--poolsizeSet the number of parallel processes TwitterScraper should initiate while scraping for your query. Default value is set to 20. Depending on the computational power you have, you can increase this number. It is advised to keep this number below the number of days you are scraping. For example, if you are scraping from 2017-01-10 to 2017-01-20, you can set this number to a maximum of 10. If you are scraping from 2016-01-01 to 2016-12-31, you can increase this number to a maximum of 150, if you have the computational resources. Does not work in combination with--user.-oor--outputGives the name of the output file. If no output filename is given, the default filename 'tweets.json' or 'tweets.csv' will be used.-cor--csvWrite the result to a CSV file instead of a JSON file.-dor--dump: With this argument, the scraped tweets will be printed to the screen instead of an outputfile. If you are using this argument, the--outputargument doe not need to be used.
Below is an example of how twitterscraper can be used:
twitterscraper Trump --limit 100 --output=tweets.json
twitterscraper Trump -l 100 -o tweets.json
twitterscraper Trump -l 100 -bd 2017-01-01 -ed 2017-06-01 -o tweets.json
twitterscraper realDonaldTrump -u -o tweets_username.json
You can use any advanced query Twitter supports. An advanced query should be placed within quotes, so that twitterscraper can recognize it as one single query.
Here are some examples:
- search for the occurence of 'Bitcoin' or 'BTC':
twitterscraper "Bitcoin OR BTC " -o bitcoin_tweets.json -l 1000 - search for the occurence of 'Bitcoin' and 'BTC':
twitterscraper "Bitcoin AND BTC " -o bitcoin_tweets.json -l 1000 - search for tweets from a specific user:
twitterscraper "Blockchain from:VitalikButerin" -o blockchain_tweets.json -l 1000 - search for tweets to a specific user:
twitterscraper "Blockchain to:VitalikButerin" -o blockchain_tweets.json -l 1000 - search for tweets written from a location:
twitterscraper "Blockchain near:Seattle within:15mi" -o blockchain_tweets.json -l 1000
You can construct an advanced query on Twitter Advanced Search or use one of the operators shown on this page. Also see Twitter's Standard operators
You can also scraped all tweets written by retweetet by a specific user. This can be done by adding the boolean argument -u / --user argument to the query.
If this argument is used, the query should be equal to the username.
Here is an example of scraping a specific user:
twitterscraper realDonaldTrump -u -o tweets_username.json
This does not work in combination with -p, -bd, or -ed but it is the only way to scrape for retweets.
You can easily use TwitterScraper from within python:
from twitterscraper import query_tweets
if __name__ == '__main__':
list_of_tweets = query_tweets("Trump OR Clinton", 10)
#print the retrieved tweets to the screen:
for tweet in query_tweets("Trump OR Clinton", 10):
print(tweet)
#Or save the retrieved tweets to file:
file = open(“output.txt”,”w”)
for tweet in query_tweets("Trump OR Clinton", 10):
file.write(tweet.encode('utf-8'))
file.close()
A regular search within Twitter will not show you any retweets. Twitterscraper therefore does not contain any retweets in the output. To give an example: If user1 has written a tweet containing #trump2020 and user2 has retweetet this tweet, a search for #trump2020 will only show the original tweet. The only way you can scrape for retweets is if you scrape for all tweets of a specific user with the -u / --user argument.
All of the retrieved Tweets are stored in the indicated output file. The contents of the output file will look like:
[{"fullname": "Rupert Meehl", "id": "892397793071050752", "likes": "1", "replies": "0", "retweets": "0", "text": "Latest: Trump now at lowest Approval and highest Disapproval ratings yet. Oh, we're winning bigly here ...\n\nhttps://projects.fivethirtyeight.com/trump-approval-ratings/?ex_cid=rrpromo\u00a0\u2026", "timestamp": "2017-08-01T14:53:08", "user": "Rupert_Meehl"}, {"fullname": "Barry Shapiro", "id": "892397794375327744", "likes": "0", "replies": "0", "retweets": "0", "text": "A former GOP Rep quoted this line, which pretty much sums up Donald Trump. https://twitter.com/davidfrum/status/863017301595107329\u00a0\u2026", "timestamp": "2017-08-01T14:53:08", "user": "barryshap"}, (...)
]
In order to correctly handle all possible characters in the tweets (think of Japanese or Arabic characters), the output is saved as utf-8 encoded bytes. That is why you could see text like "u30b1 u30f3 u3055 u307e u30fe ..." in the output file.
What you should do is open the file with the proper encoding:
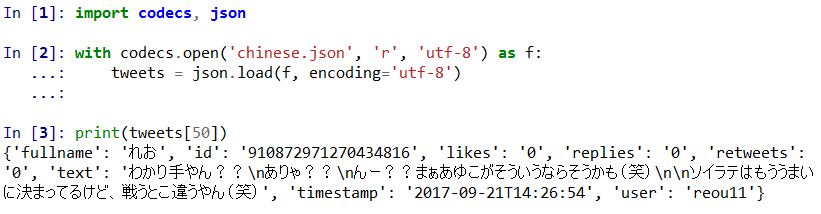
Example of output with Japanese characters
After the file has been opened, it can easily be converted into a pandas DataFrame
import codecs, json
import pandas as pd
with codecs.open('tweets.json', 'r', 'utf-8') as f:
tweets = json.load(f, encoding='utf-8')
list_tweets = [list(elem.values()) for elem in tweets]
list_columns = list(tweets[0].keys())
df = pd.DataFrame(list_tweets, columns=list_columns