This project is meant for extracting movies and TV Shows information from IMDb and to store the obtained data into our own database for further queries. These information are extracted through web scraping, driven by a batch process.
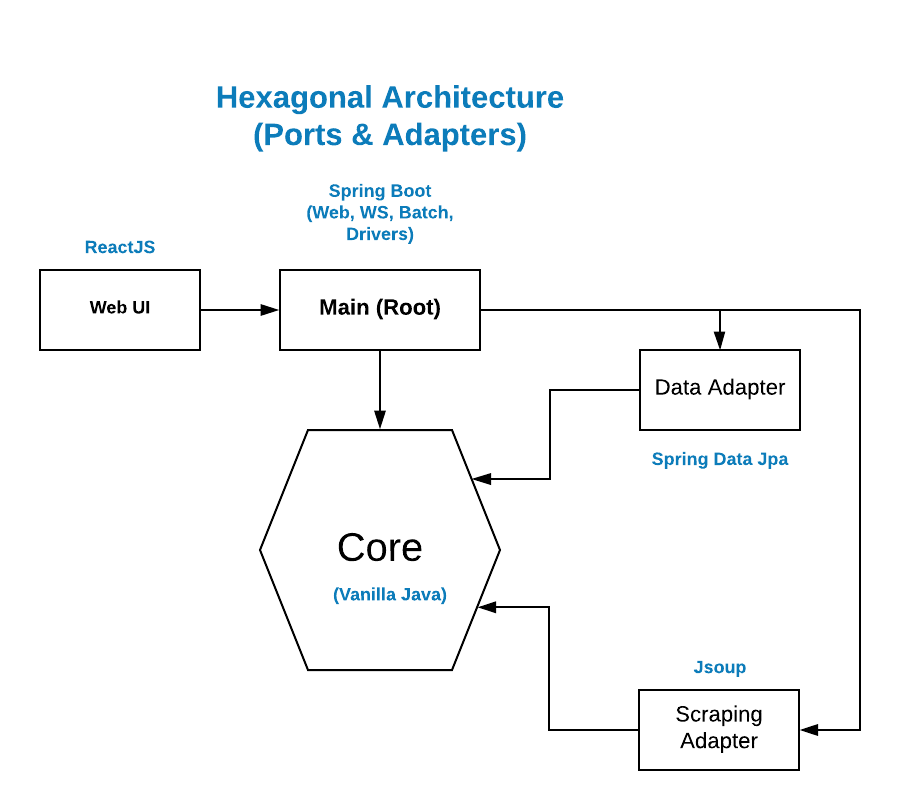
The project follows the principles of an Hexagonal Architecture (aka Ports & Adapters) exposed by Alistair Cockburn. It's compound of the following modules:
- core: Domain + Ports + Usecases.
- data-adapter: Adapters intended for persistence purposes.
- scraping-adapter: Adapters meant for scraping purposes.
- main: The infrastructure; the root where all the above modules gets glued and the application gets bootstrapped.
- web-ui: The web interface from which the batch process gets triggered and can be monitored.

{kind=link}
{kind=link}
The following are the technologies I used for building this project:
- Java: the language used in the whole project at the backend.
- Spring Boot: the framework used for providing infrastructure and autoconfiguration. Also, several dependencies of it are used for exposing http and websocket endpoints, for batch processing, security, validation, etc...It is used at the main module.
- Spring Batch: It is used in the main module for batch processing.
- PostgreSQL: Database used for storing the data extracted from the IMDb website. The driver for this database is included as dependency in the infrastructure module (main).
- Jsoup: A Java-based library for scraping and parsing HTML from a URL, file, or string.
- ReactJS: Javascript library for building UIs.
The project was built with Maven following a multimodule-based approach, having a parent POM for dependencies management and a child POM for each module.
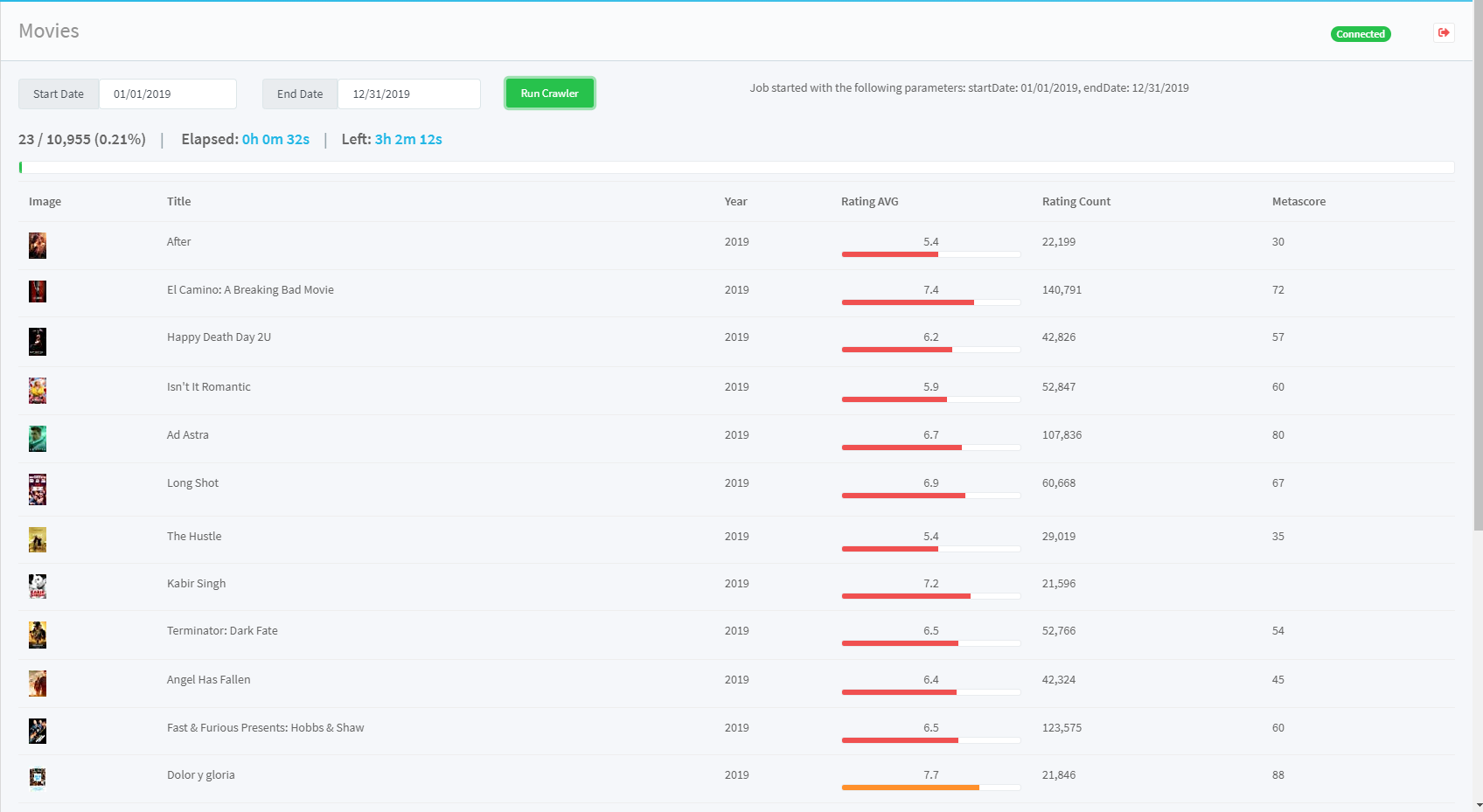
The below image is a screenshot of the UI in which you can see the progress of the scraping activity: