

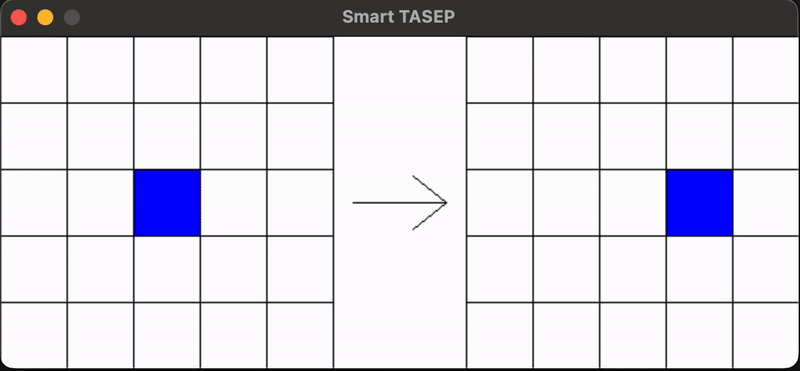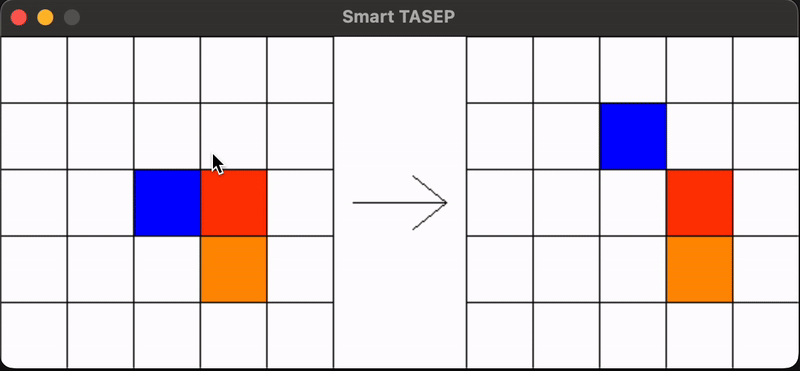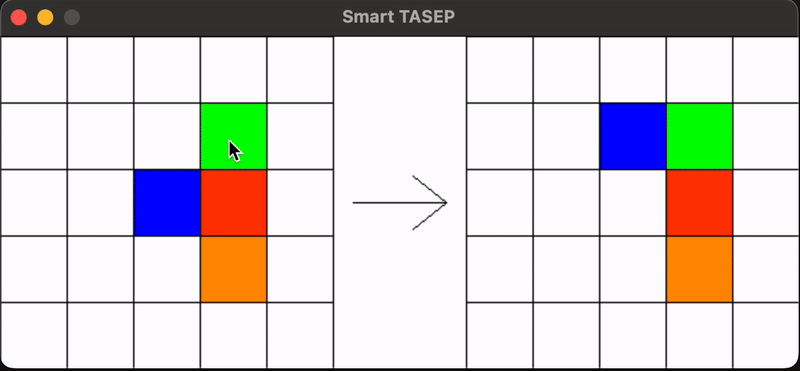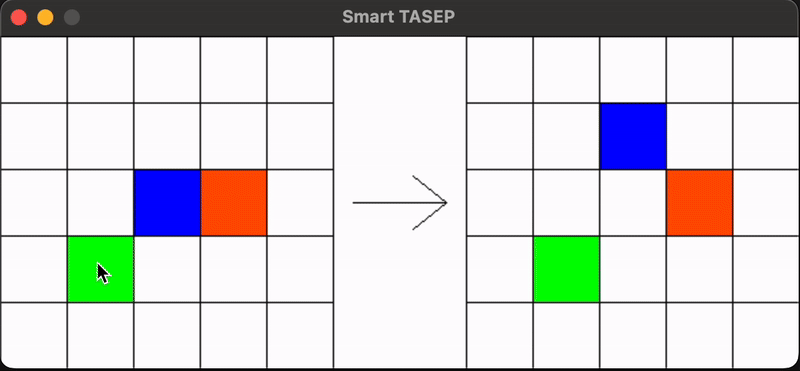
The SmartTasep package implements a Totally Asymmetric Simple Exclusion Process (TASEP) using reinforcement learning (RL) agents. In this simulation, particles perceive their environment at each time step, and a neural network decides their next action (move forward, up, or down) to maximize the total current. The repository employs Double Deep Q Learning (DDQN) with a policy network and a target network that is updated using a soft update mechanism. Experience replay is used to sample from a buffer of past experiences, facilitating learning.
- TASEP simulation with RL agents
- Double Deep Q Learning (dDQN)
- Policy network and target network with soft updates
- (Prioritized) Experience replay for improved learning
- Real-time training visualization with pygame and matplotlib
- Saving trained networks
- Loading and running pretrained simulations
- Testing learned policies interactively
- Customizable reward functions
Classes in TASEP-Smarticles:
DQN.py: Neural network RL agent classGridEnvironment.py: Environment class that computes states, transitions, and rewardsTrainer.py: Wrapper class for training the network, saving, loading and running simulationsPlayground.py: Class for testing learned policies interactively
-
Install the package using pip:
pip install smarttasep
-
Import the package:
from smarttasep import Trainer, EnvParams, Hyperparams, Playground
-
Run a training session:
envParams = EnvParams(render_mode="human", length=128, width=24, moves_per_timestep=200, window_height=200, observation_distance=3, distinguishable_particles=True, initial_state_template="checkerboard", social_reward=True, use_speeds=True, sigma=10, allow_wait=True, invert_speed_observation=True) hyperparams = Hyperparams(BATCH_SIZE=32, GAMMA=0.85, EPS_START=0.9, EPS_END=0.05, EPS_DECAY=100_000, TAU=0.005, LR=0.001, MEMORY_SIZE=500_000) trainer = Trainer(envParams, hyperparams, reset_interval=100_000, fl total_steps=500_000, plot_interval=4000, new_model=True) trainer.train_and_save()
-
Load a pretrained model and run a simulation:
trainer = trainer.load() # shows a list of available models and prompts the user to choose one trainer.run()
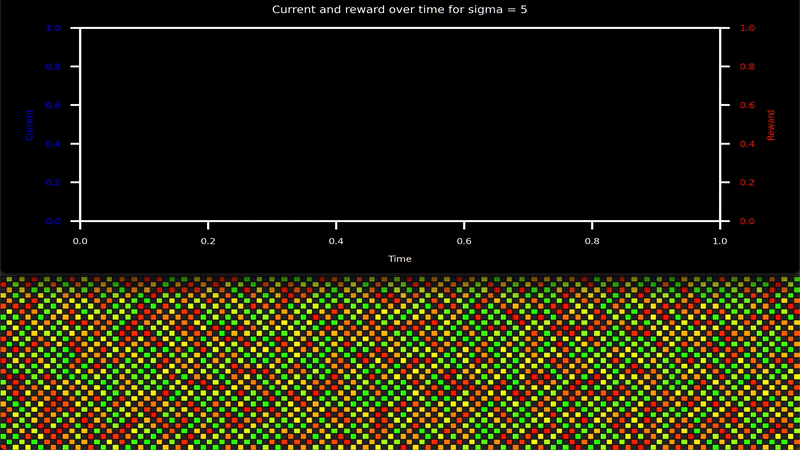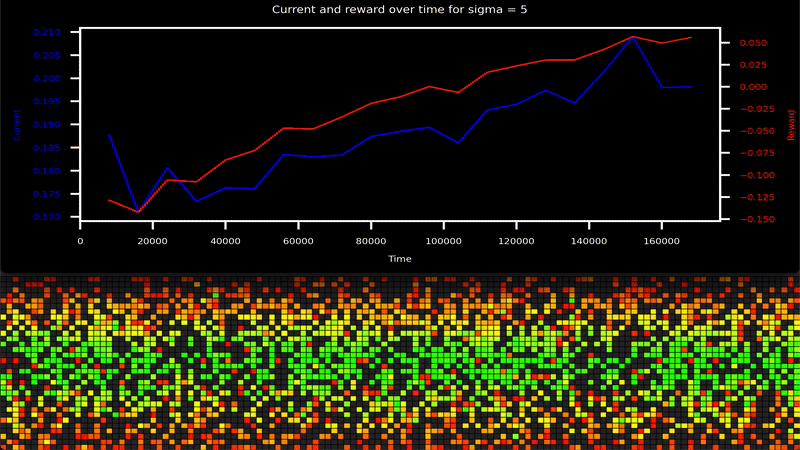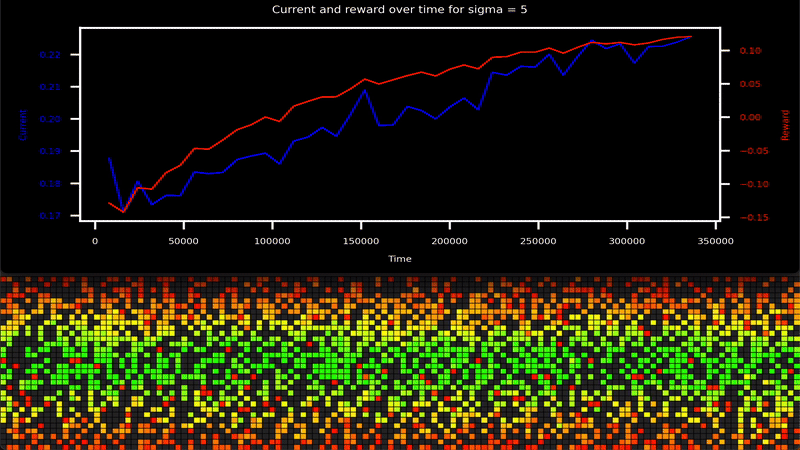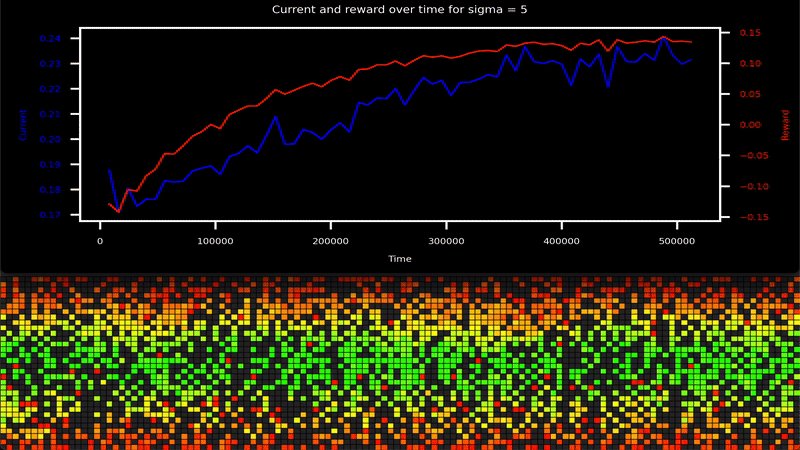
-
Test a learned policy interactively:
Playground() # shows a list of available models and prompts the user to choose one
Jonas Märtens
GitHub: https://github.com/jonasmaertens
Current Version: 0.1.0
This project is licensed under the MIT License - see the LICENSE.md file for details