Stupor is a duplicate file detector written in Python 3.4 that is able to detect duplicate files on any mounted file system under Linux or Unix variants such as OS X and BSD. To use stupor please see below for examples.
Stupor is a combination of single threaded and multithreaded algorithms used to detect duplicate files.
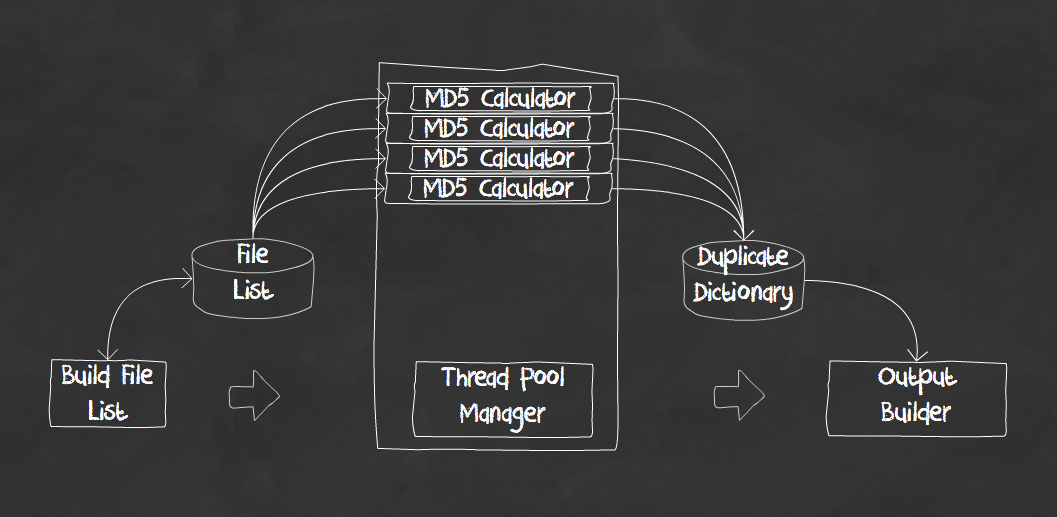
The first algorithm is contained in the crawler class and is located in the crawler library under stupor_lib/crawler.py. This class wraps the 'find' command which is one of the more efficient methods in building a list of files under a specific location. Once the class is instantiated we call the 'crawl_path' method which crawls the filesystem and returns a list of files.
Once we have a list of files we can then start processing each file separately and in parallel. To do this we create a thread pool to calculate the MD5 value of each file. To calculate the MD5 we first read in a "chunk" (or block) of the file into a character list and then use the MD5 library to calculate the file's checksum.
After the checksum is calculated the thread returns the path to the file and the calculated checksum. If the file and checksum are not located in the duplicate files dictionary we add it to the dictionary with the key as the checksum and file path as the value. If the key exists already then we have detected a duplicate. In this case we append the path of the file to the other value. Each value stored in the dictionary is stored inside the value list for that key. If there is only one path for a key then we assume there are no duplicates to this file. Therefore any key's value that has a length greater than one is assumed to be a duplicate file.
Python >= 3.4
Set chunk size of 1GB:
./stupor -p /tmp -o ~/duplicates.txt -c 1024
Set thread count to 16 (default is 4):
./stupor -p /tmp -o ~/duplicates.txt -t 16
Defaults:
./stupor -p /tmp -o ~/duplicates.txt
These calculations were done on my home PC. Right now it takes about 48 minutes to complete on 3.1TB of data that is ~17% replicated. See below for example runtime numbers:
Configuration:
| PART | Descrition |
|---|---|
| CPU | Intel Core i7 (3770K) CPU |
| RAM | 16GB DDR3-800 (non-ecc) |
| DISK | 3x2TB 6Gb/s 7200RPM drives 8MB Cache |
| FILE SYSTEM | BTRFS's RAID-0 option, LZO compression, proper alignment with 4KB stripe size |
| FS OPTIONS | compress=lzo,autodefrag,fatal_errors=bug,skip_balance,thread_pool=4 |
Runtime:
wonka stupor # time ./stupor -p /data/btrfs/ -t 8 -o output.txt
Start time: 2014-06-23 23:58:53.770263
Crawling filesystem and collecting a file list . . .
Crawler time: 70.069773 seconds
Identifying duplicates . . .
Duplicate detect time: 2835.133265 seconds
Number of files: 473924
Stop time: 2014-06-24 00:47:19.481615
Duplicate file count: 80879
Duration: 2905.711284
real 48m26.211s
user 8m59.681s
sys 4m13.506s