
IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) 2025
Chanyoung Kim, Dayun Ju, Woojung Han, Ming-Hsuan Yang, Seong Jae Hwang
Yonsei University & University of California, Merced
Open-Vocabulary Semantic Segmentation (OVSS) has advanced with recent vision-language models (VLMs), enabling segmentation beyond predefined categories through various learning schemes. Notably, training-free methods offer scalable, easily deployable solutions for handling unseen data, a key goal of OVSS. Yet, a critical issue persists: lack of object-level context consideration when segmenting complex objects in the challenging environment of OVSS based on arbitrary query prompts. This oversight limits models' ability to group semantically consistent elements within object and map them precisely to userdefined arbitrary classes. In this work, we introduce a novel approach that overcomes this limitation by incorporating object-level contextual knowledge within images. Specifically, our model enhances intra-object consistency by distilling spectral-driven features from vision foundation models into the attention mechanism of the visual encoder, enabling semantically coherent components to form a single object mask. Additionally, we refine the text embeddings with zero-shot object presence likelihood to ensure accurate alignment with the specific objects represented in the images. By leveraging object-level contextual knowledge, our proposed approach achieves state-of-the-art performance with strong generalizability across diverse datasets.
pip install torch==1.10.1+cu111 torchvision==0.11.2+cu111 -f https://download.pytorch.org/whl/cu111/torch_stable.html
pip install openmim scikit-learn scikit-image
mim install mmcv==2.0.1 mmengine==0.8.4 mmsegmentation==1.1.1
pip install ftfy regex numpy==1.23.5 yapf==0.40.1We include the listed dataset configurations in this repo, following SCLIP: PASCAL VOC (with and without the background category), PASCAL Context (with and without the background category), Cityscapes, ADE20k, COCO-Stuff164k, and COCO-Object.
Please follow the MMSeg data preparation document to download and pre-process the datasets. The COCO-Object dataset can be converted from COCO-Stuff164k by executing the following command:
python ./datasets/cvt_coco_object.py PATH_TO_COCO_STUFF164K -o PATH_TO_COCO_OBJECTTo evaluate CASS on a single benchmark, run the following command:
python eval.py --config ./configs/cfg_{benchmark_name}.py --pamr offTo evaluate CASS on a all 8 benchmarks, run the following command:
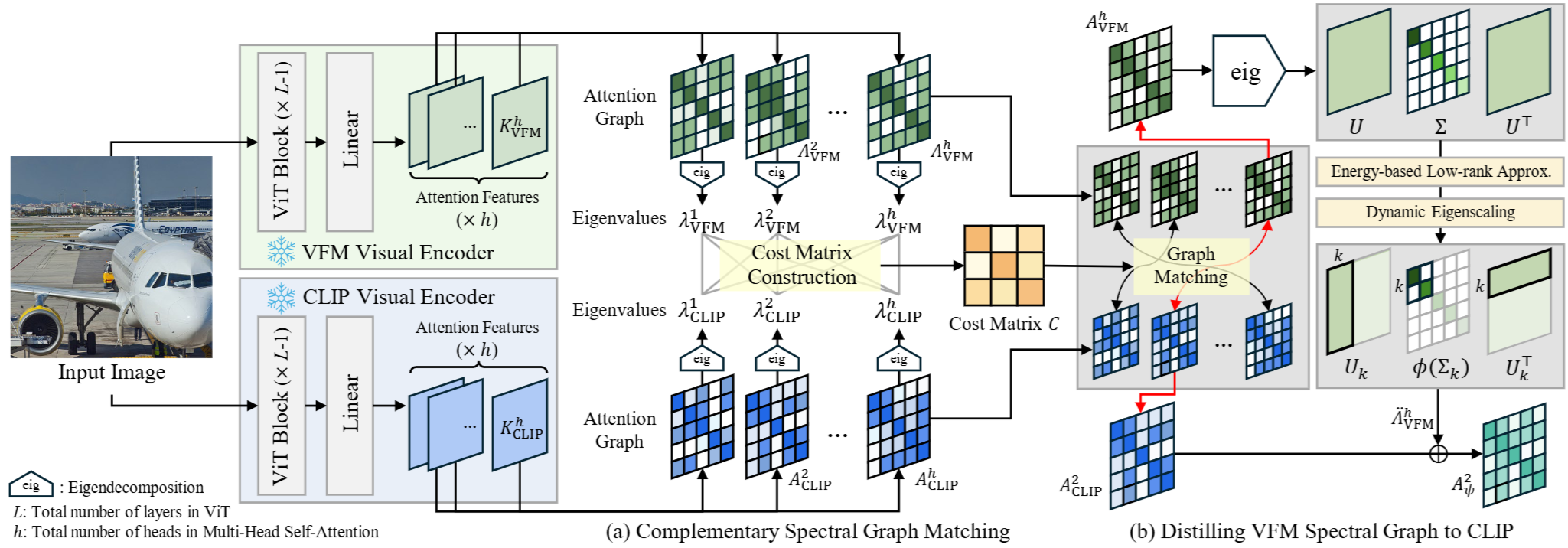
bash eval_all.shDetailed illustration of our proposed training-free spectral object-level context distillation mechanism. By matching the attention graphs of VFM and CLIP head-by-head to establish complementary relationships, and distilling the fundamental object-level context of the VFM graph to CLIP, we enhance CLIP's ability to capture intra-object contextual coherence.
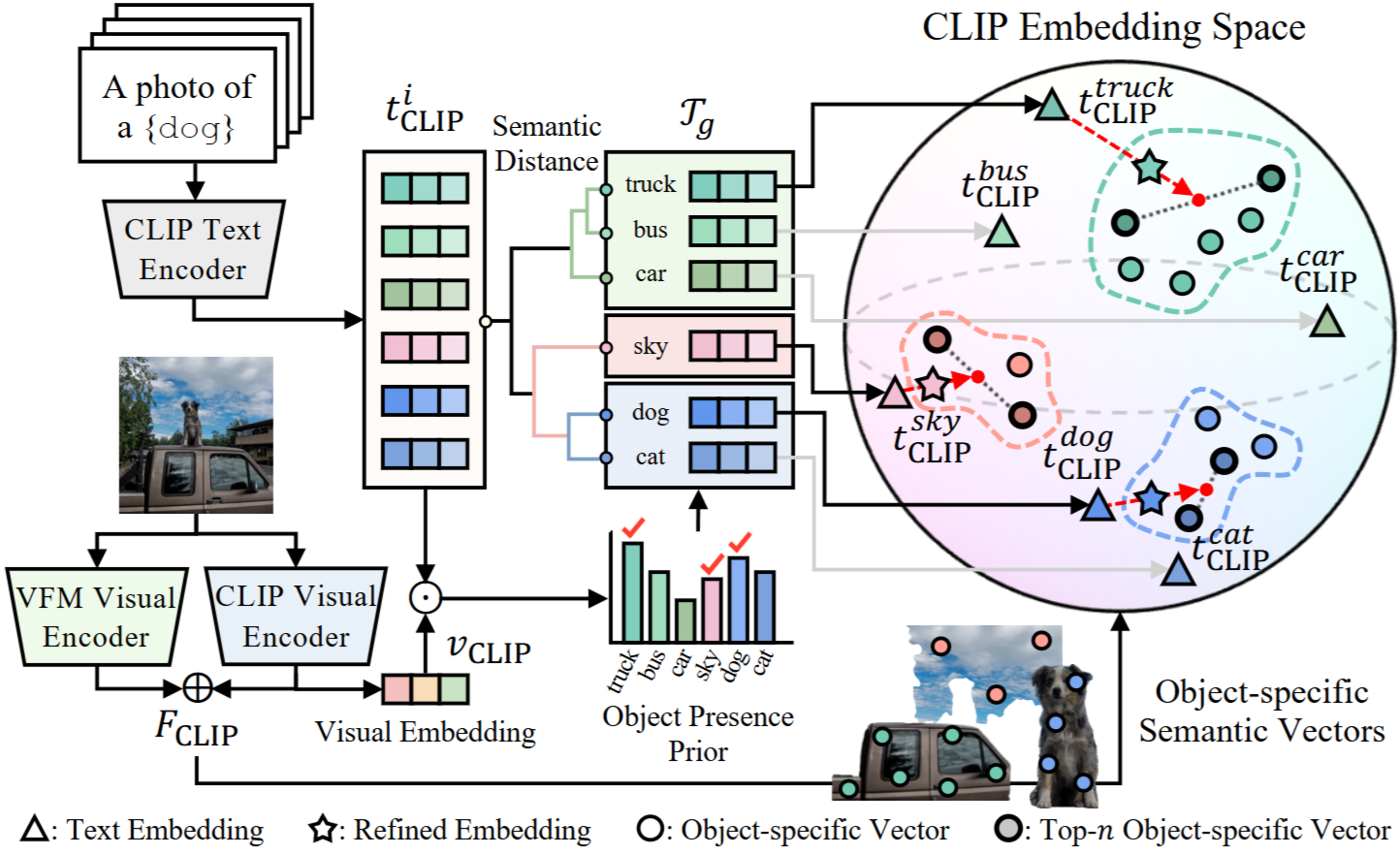
Detailed illustration of our object presence prior-guided text embedding adjustment module. The CLIP text encoder generates text embeddings for each object class, and the object presence prior is derived from both visual and text embeddings. Within hierarchically defined class groups, text embeddings are selected based on object presence prior, then refined in an object-specific direction to align with components likely present in the image.
Qualitative comparison across the Pascal VOC, Pascal Context, COCO, and ADE20K datasets using CLIP ViT-B/16.

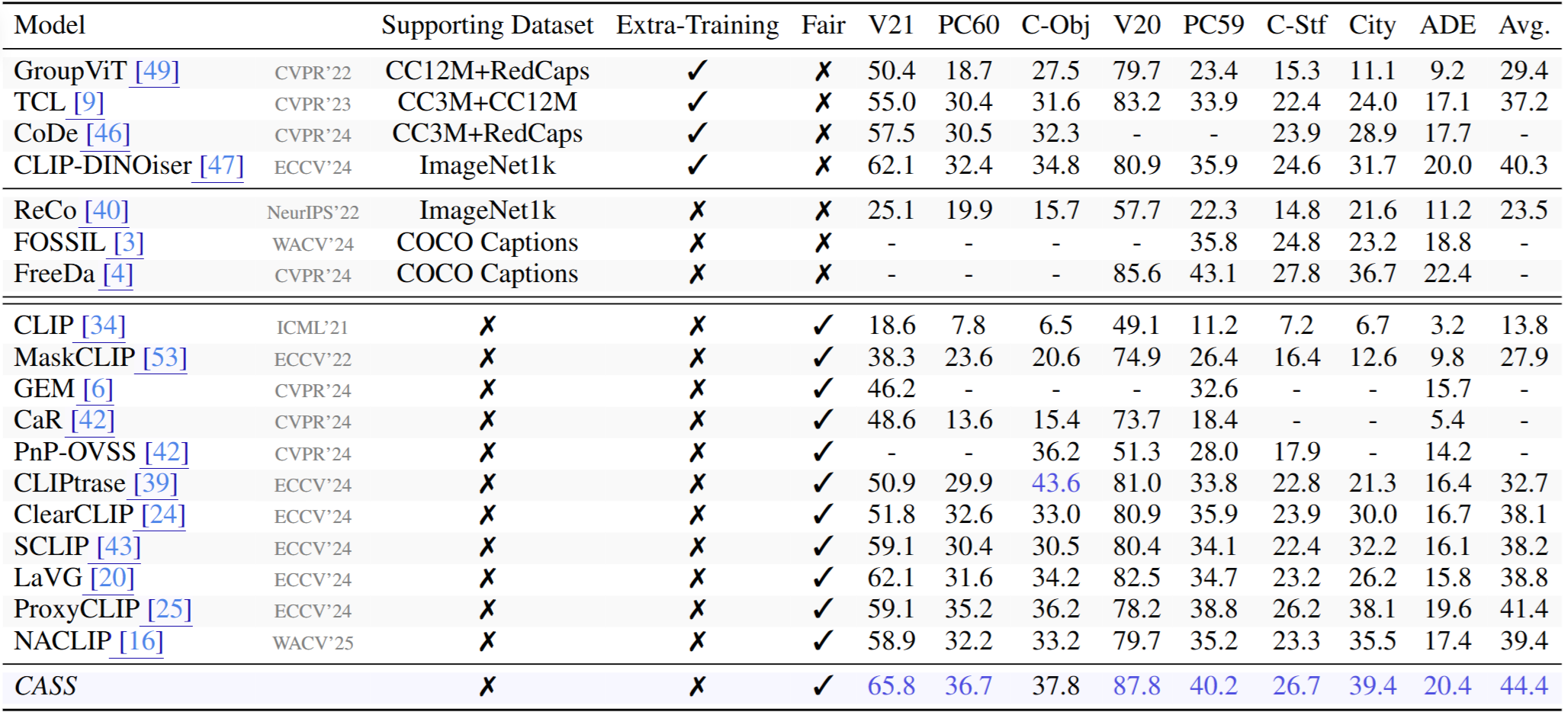
Quantitative results with state-of-the-art unsupervised open-vocabulary semantic segmentation models on eight datasets.
If you found this code useful, please cite the following paper:
@InProceedings{kim2024distilling,
author = {Kim, Chanyoung and Ju, Dayun and Han, Woojung and Yang, Ming-Hsuan and Hwang, Seong Jae},
title = {Distilling Spectral Graph for Object-Context Aware Open-Vocabulary Semantic Segmentation},
booktitle = {Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)},
month = {June},
year = {2025}
}
This repository has been developed based on the NACLIP and SCLIP repository. Thanks for the great work!