- PDF: Git-Github
- Usar un sistema de control de versiones como Git
- Instalando Git y GitBash en Windows
- Instalando Git en OSX
- Instalando Git en Linux
- Tipos de archivos y sus diferencias
- Introducción a la terminal y línea de comandos
- Diferencias entre la estructura de archivos de Windows, Mac o Linux.
- Comandos básicos en la terminal:
- Qué es staging, repositorios y cuál es el ciclo básico de trabajo en GitHub
- Ciclo de vida o estados de los archivos en Git:
- Comandos para mover archivos entre los estados de Git:
- Qué es un Branch (rama) y cómo funciona un Merge en Git
- Crea un repositorio de Git y haz tu primer commit
- Analizar cambios en los archivos de tu proyecto con Git
- Volver en el tiempo en nuestro repositorio utilizando branches y checkout
- git reset vs git rm
- git rm
- Flujo de trabajo básico con un repositorio remoto
- Introducción a las ramas o branches de Git
- Fusión de ramas con Git merge
- Solución de conflictos al hacer un merge
- Uso de Github
- Cómo funcionan las llaves públicas y privadas
- Configura tus llaves SSH en local
- En Windows y Linux:
- En Mac
- Conexión a GitHub con SSH
- Tags y versiones en Git y GitHub
- Manejo de ramas en GitHub
- Ver gráficamente nuestro entorno y flujo de trabajo local en Git
- Configurar múltiples colaboradores en un repositorio de GitHub
- Flujo de trabajo profesional con Pull requests
- Caso ejemplo: Error tipográfico en la rama master
- Ignorar archivos en el respositorio con .gitignore
- Readme.md es una excelente práctica
- Tu sitio web público con GitHub Pages
- Git Rebase: Reorganizando el trabajo realizado
- Git Stash: Guardar cambios en memoria y recuperarlos después
- Git Clean: Limpiar tu proyecto de archivos no deseados
- Git cherry-pick: Traer commits viejos al head de un branch
- Reconstruír commits en Git con amend
- Git Reset y Reflog: Úsese en caso de emergencia
- Buscar en archivos y commits de Git con Grep y log
- Comandos y recursos colaborativos en Git y Github
Un sistema de control de versiones como Git nos ayuda a guardar el historial de cambios y crecimiento de los archivos de nuestro proyecto.
En realidad, los cambios y diferencias entre las versiones de nuestros proyectos pueden tener similitudes, algunas veces los cambios pueden ser solo una palabra o una parte específica de un archivo específico. Git está optimizado para guardar todos estos cambios de forma atómica e incremental, o sea, aplicando cambios sobre los últimos cambios, estos sobre los cambios anteriores y así hasta el inicio de nuestro proyecto.
El comando para iniciar nuestro repositorio, o sea, indicarle a Git que queremos usar su sistema de control de versiones en nuestro proyecto, es git init.
El comando para que nuestro repositorio sepa de la existencia de un archivo o sus últimos cambios es git add. Este comando no almacena las actualizaciones de forma definitiva, solo las guarda en algo que conocemos como “Staging Area”
El comando para almacenar definitivamente todos los cambios que por ahora viven en el staging area es git commit. También podemos guardar un mensaje para recordar muy bien qué cambios hicimos en este commit con el argumento -m "Mensaje del commit".
TIP:
Se puede usar git commit -am "Mensaje del commit" para hacer git add . y git commit -m "Mensaje" al mismo tiempo!
Por último, si queremos mandar nuestros commits a un servidor remoto, un lugar donde todos podamos conectar nuestros proyectos, usamos el comando git push.
Windows y Linux comandos diferentes, graban el enter de formas diferentes y tienen muchas otras diferencias. Cuando instales Git Bash en Windows debes elegir si prefieres trabajar con la forma de Windows o la forma de UNIX (Linux y Mac) .
Ten en cuenta que, normalmente, los entornos de desarrollo profesionales tienen personas que usan sistemas operativos diferentes. Esto significa que, si todos podemos usar los mismos comandos, el trabajo resultará más fácil para todos en el equipo.
Los comandos de UNIX son los más comunes entre los equipos de desarrollo. Así que, a menos que trabajes con tecnologías nativas de Microsoft (por ejemplo, .NET), la recomendación es que elijas la opción de la terminal tipo UNIX para obtener una mejor compatibilidad con todo tu equipo.
- Ir a la página de Github: https://git-scm.com/downloads
- Iniciar el instalador
- Asegurarse te marcar la opción Git Bash
- Activar TrueType (Mejora las fuentes cuando usas la línea de comandos)
- Marcar Git from the command line and also from 3rd party software (Recomendado)
- Marcar use the OpenSSL library
- Marcar checkout Windows-style, commit unix-style line endings (Compatibilidad con UNIX y Linux)
- Marcar MinTTY
- Ejecutar Git Bash
La instalación de GIT en Mac es un poco más sencilla. No debemos instalar GitBash porque Mac ya trae por defecto una consola de comandos (la puedes encontrar como “Terminal”). Tampoco debemos configurar OpenSSL porque viene listo por defecto.
OSX está basado en un Kernel de UNIX llamado BSD. Estos significa que hay algunas diferencias entre las consolas de Mac y Linux. Pero no vas a notar la diferencia a menos que trabajes con acceso profundo a las interfaces de red o los archivos del sistema operativo. Ambas consolas funcionan muy parecido y comparten los comandos que vamos a ver durante el curso.
- Puedes descargar Git aquí: https://git-scm.com
Puedes verificar que Git fue instalado correctamente con el comando git --version.
Cada distribución de Linux tiene un comando especial para instalar herramientas y actualizar el sistema.
Cada distribución tiene su comando especial y debes averiguar cómo funciona para poder instalar Git.
- En las distribuciones derivadas de Debian (como Ubuntu) el comando especial es
apt-get - En Red Hat es
yumy enArchLinuxespacman.
Antes de hacer la instalación, debemos hacer una actualización del sistema. En nuestro caso, los comandos para hacerlo son sudo apt-get update y sudo apt-get upgrade.
Con el sistema actualizado, ahora sí podemos instalar Git y, en este caso, el comando para hacerlo es sudo apt-get install git. También puedes verificar que Git fue instalado correctamente con el comando git --version.
Editores de código, archivos binarios y de texto plano Un editor de código es una herramienta que nos brinda muchas ayudas para escribir código, algo así como un bloc de notas muy avanzado. Los editores más populares son VSCode, Sublime Text y Atom, pero no necesariamente debes usar alguno de estos para continuar con el curso.
Archivos de Texto (.txt): Texto plano normal y sin nada especial. Lo vemos igual sin importar dónde lo abramos, ya sea con el bloc de notas o con editores de texto avanzados.
Archivos RTF (.rtf): Podemos guardar texto con diferentes tamaños, estilos y colores. Pero si lo abrimos desde un editor de código, vamos a ver que es mucho más complejo que solo el texto plano. Esto es porque debe guardar todos los estilos del texto y, para esto, usa un código especial un poco difícil de entender y muy diferente a los textos con estilos especiales al que estamos acostumbrados.
Archivos de Word (.docx): Podemos guardar imágenes y texto con diferentes tamaños, estilos o colores. Al abrirlo desde un editor de código podemos ver que es código binario, muy difícil de entender y muy diferente al texto al que estamos acostumbrados. Esto es porque Word está optimizado para entender este código especial y representarlo gráficamente.
Recuerda que debes habilitar la opción de ver la extensión de los archivos, de lo contrario, solo podrás ver su nombre.
La forma de hacerlo en Windows es Vista > Mostrar u ocultar > Extensiones de nombre de archivo.
La ruta principal en Windows es C:/ en UNIX es solo /
Windows no hace diferencia entre mayúsculas y minúsculas pero UNIX sí.
Recuerda que GitBash usa la ruta /c para dirigirse a C:\ (o /d para dirigirse a D:/ ) en Windows. Por lo tanto, la ruta del usuario con el que estás trabajando es /C/Users/Nombre de tu usuario
- pwd: Nos muestra la ruta de carpetas en la que te encuentras ahora mismo.
- mkdir: Nos permite crear carpetas (por ejemplo, mkdir Carpeta-Importante).
- touch: Nos permite crear archivos (por ejemplo, touch archivo.txt).
- rm: Nos permite borrar un archivo o carpeta (por ejemplo, rm archivo.txt). Mucho cuidado con este comando, puedes borrar todo tu disco duro.
- cat: Ver el contenido de un archivo (por ejemplo, cat nombre-archivo.txt).
- ls: Nos permite cambiar ver los archivos de la carpeta donde estamos ahora mismo. Podemos usar uno o más argumentos para ver más información sobre estos archivos (los argumentos pueden ser -- + el nombre del argumento o - + una sola letra o shortcut por cada argumento).
- ls -a: Mostrar todos los archivos, incluso los ocultos.
- ls -l: Ver todos los archivos como una lista.
- cd: Nos permite navegar entre carpetas.
- cd /: Ir a la ruta principal:
- cd o cd ~: Ir a la ruta de tu usuario
- cd carpeta/subcarpeta: Navegar a una ruta dentro de la carpeta donde estamos ahora mismo.
- cd .. (cd + dos puntos): Regresar una carpeta hacia atrás.
- Si quieres referirte al directorio en el que te encuentras ahora mismo puedes usar cd . (cd + un punto).
- history: Ver los últimos comandos que ejecutamos y un número especial con el que podemos repetir su ejecución.
- ! + número: Ejecutar algún comando con el número que nos muestra el comando history (por ejemplo, !72).
- clear: Para limpiar la terminal. También podemos usar los atajos de teclado Ctrl + L o Command + L.
Todos estos comandos tiene una función de autocompletado, o sea, puedes escribir la primera parte y presionar la tecla Tab para que la terminal nos muestre todas las posibles carpetas o comandos que podemos ejecutar. Si presionas la tecla Arriba puedes ver el último comando que ejecutamos.
Recuerda que podemos descubrir todos los argumentos de un comando con el argumento --help (por ejemplo, cat --help).
Para iniciar un repositorio, o sea, activar el sistema de control de versiones de Git en tu proyecto, solo debes ejecutar el comando git init.
Este comando se encargará de dos cosas:
- Primero, crear una carpeta .git donde se guardará toda la base de datos con cambios atómicos de nuestro proyecto.
- Segundo, crear un área en la memoria RAM, que conocemos como Staging, que guardará temporalmente nuestros archivos (cuando ejecutemos un comando especial para eso) y nos permitirá, más adelante, guardar estos cambios en el repositorio (también con un comando especial).

Cuando trabajamos con Git, nuestros archivos pueden vivir y moverse entre 4 diferentes estados (cuando trabajamos con repositorios remotos pueden ser más estados pero lo estudiaremos más adelante):
Archivos Untracked: Son archivos que NO viven dentro de Git, solo en el disco duro. Nunca han sido afectados por git add, así que Git no tiene registros de su existencia.
Archivos Unstaged: Entiendelos como archivos “Tracked pero Unstaged”. Son archivos que viven dentro de Git pero no han sido afectados por el comando git add ni mucho menos por git commit. Git tiene un registro de estos archivos pero está desactualizado, sus últimas versiones solo están guardadas en el disco duro.
Archivos Staged: Son archivos en Staging. Viven dentro de Git y hay registro de ellos porque han sido afectados por el comando git add, aunque no sus últimos cambios. Git ya sabe de la existencia de estos últimos cambios pero todavía no han sido guardados definitivamente en el repositorio porque falta ejecutar el comando git commit.
Archivos Tracked: Son los archivos que viven dentro de Git, no tienen cambios pendientes y sus últimas actualizaciones han sido guardadas en el repositorio gracias a los comandos git add y git commit.
Recuerda que hay un caso muy raro donde los archivos tienen dos estados al mismo tiempo: Staged y Untracked. Esto pasa cuando guardas los cambios de un archivo en el área de Staging (con el comando git add) pero, antes de hacer commit para guardar los cambios en el repositorio, haces nuevos cambios que todavía no han sido guardados en el área de Staging (en realidad, todo sigue funcionando igual pero es un poco divertido).
-
git status: Nos permite ver el estado de todos nuestros archivos y carpetas.
-
git add: Nos ayuda a mover archivos del Untracked o Unstaged al estado Staged. Podemos usar
git add nombre-del-archivo-o-carpetapara añadir archivos y carpetas individuales ogit add -Apara mover todos los archivos de nuestro proyecto (tanto untrackeds como unstageds). -
git reset HEAD: Nos ayuda a sacar archivos del estado Staged para devolverlos a su estado anterior. Si los archivos venían de Unstaged, vuelven allí. Y lo mismo se venían de Untracked.
-
git commit: Nos ayuda a mover archivos de Staged a Tracked. Esta es una ocasión especial, los archivos han sido guardado o actualizados en el repositorio. Git nos pedirá que dejemos un mensaje para recordar los cambios que hicimos y podemos usar el argumento -m para escribirlo (git commit -m "mensaje").
-
git rm: Este comando necesita alguno de los siguientes argumentos para poder ejecutarse correctamente:
-
git rm --cached: Mueve los archivos que le indiquemos al estado Untracked.
-
git rm --force: Elimina los archivos de Git y del disco duro. Git guarda el registro de la existencia de los archivos, por lo que podremos recuperarlos si es necesario (pero debemos usar comandos más avanzados).
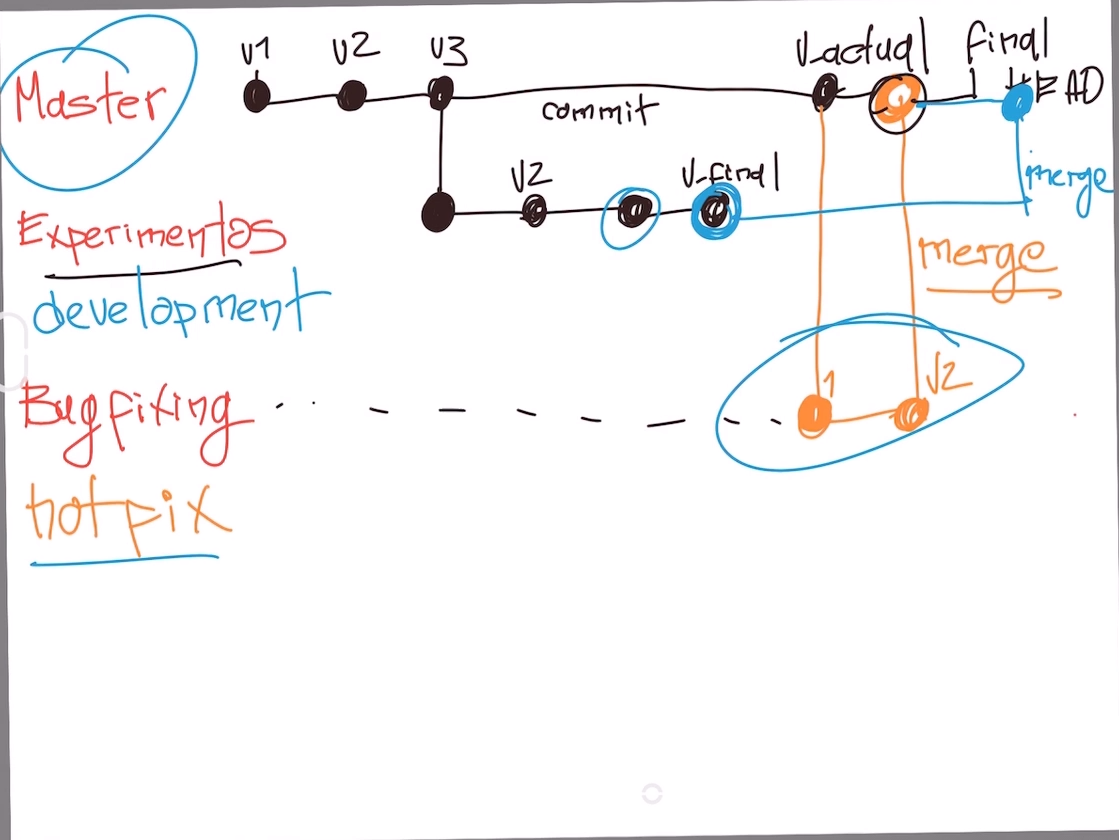
Git es una base de datos muy precisa con todos los cambios y crecimiento que ha tenido nuestro proyecto. Los commits son la única forma de tener un registro de los cambios. Pero las ramas amplifican mucho más el potencial de Git.
Todos los commits se aplican sobre una rama. Por defecto, siempre empezamos en la rama master (pero puedes cambiarle el nombre si no te gusta) y creamos nuevas ramas, a partir de esta, para crear flujos de trabajo independientes.
Crear una nueva rama se trata de copiar un commit (de cualquier rama), pasarlo a otro lado (a otra rama) y continuar el trabajo de una parte específica de nuestro proyecto sin afectar el flujo de trabajo principal (que continúa en la rama master o la rama principal).
Los equipos de desarrollo tienen un estándar:
- Todo lo que esté en la rama master va a producción.
- Las nuevas features, características y experimentos van en una rama “development” (para unirse a master cuando estén definitivamente listas).
- Y los issues o errores se solucionan en una rama “hotfix” para unirse a master tan pronto como sea posible.
Crear una nueva rama lo conocemos como Checkout. Unir dos ramas lo conocemos como Merge.
Podemos crear todas las ramas y commits que queramos. De hecho, podemos aprovechar el registro de cambios de Git para crear ramas, traer versiones viejas del código, arreglarlas y combinarlas de nuevo para mejorar el proyecto.
Solo ten en cuenta que combinar estas ramas (sí, hacer “merge”) puede generar conflictos. Algunos archivos pueden ser diferentes en ambas ramas. Git es muy inteligente y puede intentar unir estos cambios automáticamente, pero no siempre funciona. En algunos casos, somos nosotros los que debemos resolver estos conflictos “a mano”.
Si quieres ver los archivos ocultos de una carpeta puedes habilitar la opción de Vista > Mostrar u ocultar > Elementos ocultos (en Windows) o ejecutar el comando ls -a.
Le indicaremos a Git que queremos crear un nuevo repositorio para utilizar su sistema de control de versiones. Solo debemos posicionarnos en la carpeta raíz de nuestro proyecto y ejecutar el comando git init.
Recuerda que al ejecutar este comando (y de aquí en adelante) vamos a tener una nueva carpeta oculta llamada .git con toda la base de datos con cambios atómicos en nuestro proyecto.
Recuerda que Git está optimizado para trabajar en equipo, por lo tanto, debemos darle un poco de información sobre nosotros. No debemos hacerlo todas las veces que ejecutamos un comando, basta con ejecutar solo una sola vez los siguientes comandos con tu información:
git config --global user.email "[email protected]"
git config --global user.name "Tu Nombre"
git config --global color.ui true
Existen muchas otras configuraciones de Git que puedes encontrar ejecutando el comando git config --list (o solo git config para ver una explicación más detallada).
El comando git show nos muestra los cambios que han existido sobre un archivo y es muy útil para detectar cuándo se produjeron ciertos cambios, qué se rompió y cómo lo podemos solucionar. Pero podemos ser más detallados.
Si queremos ver la diferencia entre una versión y otra, no necesariamente todos los cambios desde la creación del archivo, podemos usar el comando git diff commitA commitB.
Recuerda que puedes obtener el ID de tus commits con el comando git log.
El comando git checkout + ID del commit nos permite viajar en el tiempo. Podemos volver a cualquier versión anterior de un archivo específico o incluso del proyecto entero. Esta también es la forma de crear ramas y movernos entre ellas.
También hay una forma de hacerlo un poco más “ruda”: usando el comando git reset. En este caso, no solo “volvemos en el tiempo”, sino que borramos los cambios que hicimos después de este commit.
Hay dos formas de usar git reset:
- Con el argumento
--hard, borrando toda la información que tengamos en el área de staging (y perdiendo todo para siempre). - O, un poco más seguro, con el argumento--soft, que mantiene allí los archivos del área de staging para que podamos aplicar nuestros últimos cambios pero desde un commit anterior.
Git reset y git rm son comandos con utilidades muy diferentes, pero aún así se confunden muy fácilmente.
Este comando nos ayuda a eliminar archivos de Git sin eliminar su historial del sistema de versiones. Esto quiere decir que si necesitamos recuperar el archivo solo debemos “viajar en el tiempo” y recuperar el último commit antes de borrar el archivo en cuestión.
Recuerda que git rm no puede usarse así nomás. Debemos usar uno de los flags para indicarle a Git cómo eliminar los archivos que ya no necesitamos en la última versión del proyecto:
- git rm --cached: Elimina los archivos del área de Staging y del próximo commit pero los mantiene en nuestro disco duro.
- git rm --force: Elimina los archivos de Git y del disco duro. Git siempre guarda todo, por lo que podemos acceder al registro de la existencia de los archivos, de modo que podremos recuperarlos si es necesario (pero debemos usar comandos más avanzados). -git reset: Este comando nos ayuda a volver en el tiempo. Pero no como git checkout que nos deja ir, mirar, pasear y volver. Con git reset volvemos al pasado sin la posibilidad de volver al futuro. Borramos la historia y la debemos sobreescribir. No hay vuelta atrás.
Este comando es muy peligroso y debemos usarlo solo en caso de emergencia. Recuerda que debemos usar alguna de estas dos opciones:
Hay dos formas de usar git reset:
-
con el argumento
--hard, borrando toda la información que tengamos en el área de staging (y perdiendo todo para siempre). -
O, un poco más seguro, con el argumento
--soft, que mantiene allí los archivos del área de staging para que podamos aplicar nuestros últimos cambios pero desde un commit anterior. -
git reset --soft: Borramos todo el historial y los registros de Git pero guardamos los cambios que tengamos en Staging, así podemos aplicar las últimas actualizaciones a un nuevo commit.
-
git reset --hard: Borra todo. Todo todito, absolutamente todo. Toda la información de los commits y del área de staging se borra del historial.
¡Pero todavía falta algo!
git reset HEAD: Este es el comando para sacar archivos del área de Staging. No para borrarlos ni nada de eso, solo para que los últimos cambios de estos archivos no se envíen al último commit, a menos que cambiemos de opinión y los incluyamos de nuevo en staging con git add, por supuesto.
¿Por que esto es importante? Imagina el siguiente caso:
Hacemos cambios en los archivos de un proyecto para una nueva actualización. Todos los archivos con cambios se mueven al área de staging con el comando git add. Pero te das cuenta de que uno de esos archivos no está listo todavía. Actualizaste el archivo pero ese cambio no debe ir en el próximo commit por ahora.
¿Qué podemos hacer?
Bueno, todos los cambios están en el área de Staging, incluido el archivo con los cambios que no están listos. Esto significa que debemos sacar ese archivo de Staging para poder hacer commit de todos los demás.
¡Al usar git rm lo que haremos será eliminar este archivo completamente de git! Todavía tendremos el historial de cambios de este archivo, con la eliminación del archivo como su última actualización. Recuerda que en este caso no buscábamos eliminar un archivo, solo dejarlo como estaba y actualizarlo después, no en este commit.
En cambio, si usamos git reset HEAD, lo único que haremos será mover estos cambios de Staging a Unstaged. Seguiremos teniendo los últimos cambios del archivo, el repositorio mantendrá el archivo (no con sus últimos cambios pero sí con los últimos en los que hicimos commit) y no habremos perdido nada.
Conclusión: Lo mejor que puedes hacer para salvar tu puesto y evitar un incendio en tu trabajo es conocer muy bien la diferencia y los riesgos de todos los comandos de Git.












Por ahora, nuestro proyecto vive únicamente en nuestra computadora. Esto significa que no hay forma de que otros miembros del equipo trabajen en él.
Para solucionar esto están los servidores remotos: un nuevo estado que deben seguir nuestros archivos para conectarse y trabajar con equipos de cualquier parte del mundo.
Estos servidores remotos pueden estar alojados en GitHub, GitLab, BitBucket, entre otros. Lo que van a hacer es guardar el mismo repositorio que tienes en tu computadora y darnos una URL con la que todos podremos acceder a los archivos del proyecto para descargarlos, hacer cambios y volverlos a enviar al servidor remoto para que otras personas vean los cambios, comparen sus versiones y creen nuevas propuestas para el proyecto.
Esto significa que debes aprender algunos nuevos comandos:
git clone url_del_servidor_remoto: Nos permite descargar los archivos de la última versión de la rama principal y todo el historial de cambios en la carpeta .git.git push: Luego de hacer git add y git commit debemos ejecutar este comando para mandar los cambios al servidor remoto.git fetch: Lo usamos para traer actualizaciones del servidor remoto y guardarlas en nuestro repositorio local (en caso de que hayan, por supuesto).git merge: También usamos el comando git fetch con servidores remotos. Lo necesitamos para combinar los últimos cambios del servidor remoto y nuestro directorio de trabajo.git pull: Básicamente, git fetch y git merge al mismo tiempo.
Las ramas son la forma de hacer cambios en nuestro proyecto sin afectar el flujo de trabajo de la rama principal. Esto porque queremos trabajar una parte muy específica de la aplicación o simplemente experimentar.
La cabecera o HEAD representan la rama y el commit de esa rama donde estamos trabajando. Por defecto, esta cabecera aparecerá en el último commit de nuestra rama principal. Pero podemos cambiarlo al crear una rama:
git branch rama
git checkout -b rama
O movernos en el tiempo a cualquier otro commit de cualquier otra rama con los comandos:
git reset id-commit
git checkout rama-o-id-commit
O eliminar una rama desde Git:
git branch -D nombre-de-la-rama
El comando git merge nos permite crear un nuevo commit con la combinación de dos ramas (la rama donde nos encontramos cuando ejecutamos el comando y la rama que indiquemos después del comando).
Crear un nuevo commit en la rama master combinando los cambios de la rama cabecera:
git checkout master
git merge cabecera
Crear un nuevo commit en la rama cabecera combinando los cambios de cualquier otra rama:
git checkout cabecera
git merge cualquier-otra-rama
Asombroso, ¿verdad? Es como si Git tuviera super poderes para saber qué cambios queremos conservar de una rama y qué otros de la otra. El problema es que no siempre puede adivinar, sobretodo en algunos casos donde dos ramas tienen actualizaciones diferentes en ciertas líneas en los archivos. Esto lo conocemos como un conflicto y aprenderemos a solucionarlos en la siguiente clase.
Recuerda que al ejecutar el comando git checkout para cambiar de rama o commit puedes perder el trabajo que no hayas guardado. Guarda tus cambios antes de hacer git checkout.
Git nunca borra nada a menos que nosotros se lo indiquemos. Cuando usamos los comandos git merge o git checkout estamos cambiando de rama o creando un nuevo commit, no borrando ramas ni commits (recuerda que puedes borrar commits con git reset y ramas con git branch -d).
Git es muy inteligente y puede resolver algunos conflictos automáticamente: cambios, nuevas líneas, entre otros. Pero algunas veces no sabe cómo resolver estas diferencias, por ejemplo, cuando dos ramas diferentes hacen cambios distintos a una misma línea.
Esto lo conocemos como conflicto y lo podemos resolver manualmente, solo debemos hacer el merge, ir a nuestro editor de código y elegir si queremos quedarnos con alguna de estas dos versiones o algo diferente. Algunos editores de código como VSCode nos ayudan a resolver estos conflictos sin necesidad de borrar o escribir líneas de texto, basta con hundir un botón y guardar el archivo.
Recuerda que siempre debemos crear un nuevo commit para aplicar los cambios del merge. Si Git puede resolver el conflicto hará commit automáticamente. Pero, en caso de no pueda resolverlo, debemos solucionarlo y hacer el commit.
Los archivos con conflictos por el comando git merge entran en un nuevo estado que conocemos como Unmerged. Funcionan muy parecido a los archivos en estado Unstaged, algo así como un estado intermedio entre Untracked y Unstaged, solo debemos ejecutar git add para pasarlos al área de staging y git commit para aplicar los cambios en el repositorio.
GitHub es una plataforma que nos permite guardar repositorios de Git que podemos usar como servidores remotos y ejecutar algunos comandos de forma visual e interactiva (sin necesidad de la consola de comandos).
Luego de crear nuestra cuenta, podemos crear o importar repositorios, crear organizaciones y proyectos de trabajo, descubrir repositorios de otras personas, contribuir a esos proyectos, dar estrellas y muchas otras cosas.
El README.md es el archivo que veremos por defecto al entrar a un repositorio. Es una muy buena práctica configurarlo para describir el proyecto, los requerimientos y las instrucciones que debemos seguir para contribuir correctamente.
Para clonar un repositorio desde GitHub (o cualquier otro servidor remoto) debemos copiar la URL (por ahora, usando HTTPS) y ejecutar el comando git clone + la URL que acabamos de copiar. Esto descargara la versión de nuestro proyecto que se encuentra en GitHub.
Sin embargo, esto solo funciona para las personas que quieren empezar a contribuir en el proyecto. Si queremos conectar el repositorio de GitHub con nuestro repositorio local, el que creamos con git init, debemos ejecutar las siguientes instrucciones:
Primero: Guardar la URL del repositorio de GitHub con el nombre de origin:
git remote add origin URL
Segundo: Verificar que la URL se haya guardado correctamente:
git remote
git remote -v
Tercero: Traer la versión del repositorio remoto y hacer merge para crear un commit con los archivos de ambas partes:
Podemos usar:
git fetch y git merge
O solo:
git pull origin master --allow-unrelated-histories
Por último, ahora sí podemos hacer git push para guardar los cambios de nuestro repositorio local en GitHub:
git push origin master
Las llaves públicas y privadas nos ayudan a cifrar y descifrar nuestros archivos de forma que los podamos compartir archivos sin correr el riesgo de que sean interceptados por personas con malas intenciones.
La forma de hacerlo es la siguiente:
- Ambas personas deben crear su llave pública y privada.
- Ambas personas pueden compartir su llave pública a las otras partes (recuerda que esta llave es pública, no hay problema si la “interceptan”).
- La persona que quiere compartir un mensaje puede usar la llave pública de la otra persona para cifrar los archivos y asegurarse que solo puedan ser descifrados con la llave privada de la persona con la que queremos compartir el mensaje.
- El mensaje está cifrado y puede ser enviado a la otra persona sin problemas en caso de que los archivos sean interceptados.
- La persona a la que enviamos el mensaje cifrado puede usar su llave privada para descifrar el mensaje y ver los archivos.
Puedes compartir tu llave pública pero nunca tu llave privada.
Primer paso: Generar tus llaves SSH. Recuerda que es muy buena idea proteger tu llave privada con una contraseña.
ssh-keygen -t rsa -b 4096 -C "[email protected]"
Segundo paso: Terminar de configurar nuestro sistema.
- Encender el "servidor" de llaves SSH de tu computadora:
eval $(ssh-agent -s)
- Añadir tu llave SSH a este "servidor":
ssh-add ruta-donde-guardaste-tu-llave-privada
- Encender el "servidor" de llaves SSH de tu computadora:
eval "$(ssh-agent -s)"
Si usas una versión de OSX superior a Mac Sierra (v10.12) debes crear o modificar un archivo "config" en la carpeta de tu usuario con el siguiente contenido (ten cuidado con las mayúsculas):
Host *
AddKeysToAgent yes
UseKeychain yes
IdentityFile ruta-donde-guardaste-tu-llave-privada
- Añadir tu llave SSH al "servidor" de llaves SSH de tu computadora (en caso de error puedes ejecutar este mismo comando pero sin el argumento -K):
ssh-add -K ruta-donde-guardaste-tu-llave-privada
Luego de crear nuestras llaves SSH podemos entregarle la llave pública a GitHub para comunicarnos de forma segura y sin necesidad de escribir nuestro usuario y contraseña todo el tiempo.
Para esto debes entrar a la Configuración de Llaves SSH en GitHub, crear una nueva llave con el nombre que le quieras dar y el contenido de la llave pública de tu computadora.
Ahora podemos actualizar la URL que guardamos en nuestro repositorio remoto, solo que, en vez de guardar la URL con HTTPS, vamos a usar la URL con SSH:
git remote add origin URL
O para configurar nuevamente una nueva URL
git remote set-url origin url-ssh-del-repositorio-en-github
Los tags o etiquetas nos permiten asignar versiones a los commits con cambios más importantes o significativos de nuestro proyecto.
Comandos para trabajar con etiquetas:
- Crear un nuevo tag y asignarlo a un commit:
git tag -a nombre-del-tag id-del-commit - Borrar un tag en el repositorio local:
git tag -d nombre-del-tag - Listar los tags de nuestro repositorio local:
git tag o git show-refs --tags - Publicar un tag en el repositorio remoto:
git push origin --tags - Borrar un tag del repositorio remoto:
git tag -d nombre-del-taggit push origin :refs/tags/nombre-del-tag
Puedes trabajar con ramas que nunca envias a GitHub, así como pueden haber ramas importantes en GitHub que nunca usas en el repositorio local. Lo importantes que aprendas a manejarlas para trabajar profesionalmente.
Crear una rama en el repositorio local:
git branch nombre-de-la-rama
git checkout -b nombre-de-la-rama
Publicar una rama local al repositorio remoto:
git push origin nombre-de-la-rama
Eliminar ramas remotas desde Git:
Puedes borrar la rama remota desde git utilizando este comando:
git push nombre-remoto :nombre-de-la-rama
Por ejemplo, si quieres borrar la rama bugfix del servidor, puedes utilizar:
git push origin :bugfix
Recuerda que podemos ver gráficamente nuestro entorno y flujo de trabajo local con Git usando el comando gitk
Por defecto, cualquier persona puede clonar o descargar tu proyecto desde GitHub, pero no pueden crear commits, ni ramas, ni nada.
Existen varias formas de solucionar esto para poder aceptar contribuciones. Una de ellas es añadir a cada persona de nuestro equipo como colaborador de nuestro repositorio.
Solo debemos entrar a la configuración de colaboradores de nuestro proyecto (Repositorio > Settings > Collaborators) y añadir el email o username de los nuevos colaboradores.
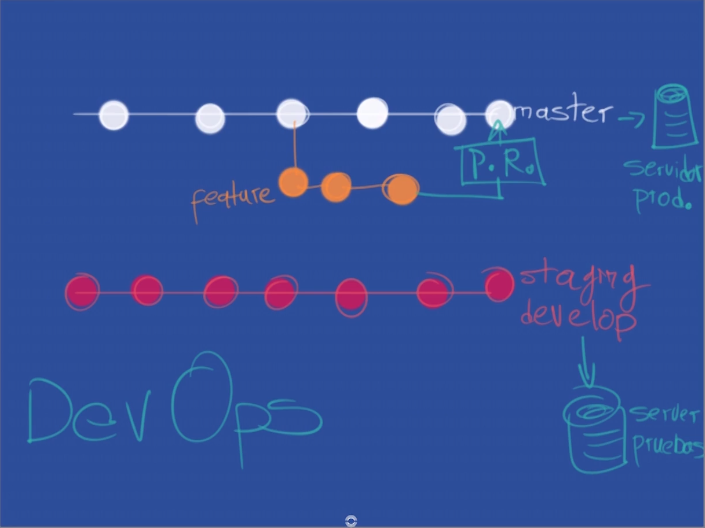
En un entorno profesional normalmente se bloquea la rama master, y para enviar código a dicha rama pasa por un code review y luego de su aprobación se unen códigos con los llamados merge request.
Para realizar pruebas enviamos el código a servidores que normalmente los llamamos staging develop (servidores de pruebas) luego de que se realizan las pruebas pertinentes tanto de código como de la aplicación estos pasan a el servidor de producción con el ya antes mencionado merge request.
$ git branch fix-typo
$ git checkout fix-typo
Luego de solucionar el problema:
$ git commit…
$ git push origin fix-typo
Luego se crea un nuevo Pull Request de master con fix-typo (En GitHub)
Se puede asignar el Pull Request a un miembro, o agregar miembros para que le hagan review, luego hay que "Crear el pull request" y el request pasa al proceso de: Code Review
Los reviewers pueden pedir cambios o aprobar el Pull Request, al terminar esto, quien sea que este a cargo de realizar los merge, debe realizarlo. (Se debe respetar quien es el que hace los merges para tener consistencia en los Code Reviews). Ya después se puede borrar el branch fix-typo de GitHub dependiendo de las prácticas de cada equipo.
No todos los archivos que agregas a un proyecto deberían ir a un repositorio, por ejemplo cuando tienes un archivo donde están tus contraseñas que comúnmente tienen la extensión .env o cuando te estás conectando a una base de datos; son archivos que nadie debe ver.
README.md es una excelente práctica en tus proyectos, md significa Markdown es un especie de código que te permite cambiar la manera en que se ve un archivo de texto.
Lo interesante de Markdown es que funciona en muchas páginas, por ejemplo la edición en Wikipedia; es un lenguaje intermedio que no es HTML, no es texto plano, es una manera de crear excelentes texto formateados.
GitHub tiene un servicio de hosting gratis llamado GitHub Pages, tu puedes tener un repositorio donde el contenido del repositorio se vaya a GitHub y se vea online.
El comando rebase es una mala práctica, nunca se debe usar, pero para efectos de curso te lo vamos a enseñar para que hagas tus propios experimentos. Con rebase puedes recoger todos los cambios confirmados en una rama y ponerlos sobre otra.
Cambiamos a la rama que queremos traer los cambios:
git checkout experiment
Aplicamos rebase para traer los cambios de la rama que queremos:
git rebase master
Cuando necesitamos regresar en el tiempo porque borramos alguna línea de código pero no queremos pasarnos a otra rama porque nos daría un error ya que debemos pasar ese “mal cambio” que hicimos a stage, podemos usar git stash para regresar el cambio anterior que hicimos.
git stash es típico cuando estamos cambios que no merecen una rama o no merecen un rebase si no simplemente estamos probando algo y luego quieres volver rápidamente a tu versión anterior la cual es la correcta.

A veces creamos archivos cuando estamos realizando nuestro proyecto que realmente no forman parte de nuestro directorio de trabajo, que no se debería agregar y lo sabemos.
Para saber qué archivos vamos a borrar tecleamos:
git clean --dry-run
Para borrar todos los archivos listados (que no son carpetas) tecleamos:
git clean -f
Existe un mundo alternativo en el cual vamos avanzando en una rama pero necesitamos en master uno de esos avances de la rama, para eso utilizamos el comando git cherry-pick IDCommit
A veces hacemos un commit, pero resulta que no queríamos mandarlo porque faltaba algo más. Utilizamos git commit --amend, amend en inglés es remendar y lo que hará es que los cambios que hicimos nos lo agregará al commit anterior.
Si el caso es que únicamente olvidamos incluir archivos al commit y el mensaje que habíamos ingresado estaba bien, también podríamos ejecutar el siguiente comando:
gitcommit--amend--no-edit
Con el --no-edit además de todo lo que significa el --amend estamos diciéndole a git que utilice el mensaje que ya habíamos ingresado.
¿Qué pasa cuando todo se rompe y no sabemos qué está pasando? Con git reset HashDelHEAD nos devolveremos al estado en que el proyecto funcionaba.
git reset --soft HashDelHEAD te mantiene lo que tengas en staging ahí. git reset --hard HashDelHEAD resetea absolutamente todo incluyendo lo que tengas en staging.
git reset es una mala práctica, no deberías usarlo en ningún momento; debe ser nuestro último recurso.
A medida que nuestro proyecto se hace grande vamos a querer buscar ciertas cosas.
Por ejemplo: ¿cuántas veces en nuestro proyecto utilizamos la palabra color?
Para buscar utilizamos el comando git grep color y nos buscará en todo el proyecto los archivos en donde está la palabra color.
Con git grep -n color nos saldrá un output el cual nos dirá en qué línea está lo que estamos buscando.
Con git grep -c color nos saldrá un output el cual nos dirá cuántas veces se repite esa palabra y en qué archivo.
Si queremos buscar cuántas veces utilizamos un atributo de HTML lo hacemos con git grep -c "<p>"
- Comando para ver cuántos commits ha hecho cada miembro del equipo:
git shortlog -sn
git shortlog -sn -all
git shortlog -sn -all --no-merges
Crear un shortcode en Git para el shortlog:
git config --global alias.stats "shortlog -sn -all --no-merges"
Ejecutarlo:
git stats
- Saber quién hizo qué:
git blame -c nombre-del-archivo / git blame -c index.html
- Saber cómo funciona un comando
git blame --help / Mostrará una guía de su funcionamiento
- Ver las ramas de Git y Github
Ver las ramas locales:
git branch
Ver las ramas remotas:
git branch -r
Ver todas las ramas:
git branch -a