-
Notifications
You must be signed in to change notification settings - Fork 0
Fair Share Scheduling
With the large investment in HPC resources, the batch system has traditionally been responsible for making sure users receive fair access to the computing resources they are entitled to. One of the earlier solutions for guaranteeing equitable access was to use quotas. Once a user had reached their quota for the month, the batch system prevented them from running any more jobs. However, if every user did not run enough jobs to reach their quota, compute cycles would go unused and be wasted.
A better method was devised and was called fair-share scheduling. This method guaranteed each user the resources (namely cycles) they were entitled to, but allowed other users to exceed their allotted portions when cycles would otherwise go idle. The basic fair-share algorithm set a job's priority to a value that was proportional to the difference between the shares of the cluster that were allotted and the aggregate usage of all prior jobs run by the user. The more jobs a user ran, the lower the priority would be assigned to subsequent job submitted by that user. As stated in the Job Priority Plugin Implementation Notes...
"[The fair share factor is] a factor between 0.0 and 1.0 that represents how much computing resources have been used by past user jobs that have charged the account associated with the job. This "fair-share" factor takes into consideration the number of shares of computing resources the user has purchased or been promised. A value of 0.5 represents an account that has accrued usage commensurate with the assigned shares. The 1.0 value represents an account that has yet to be charged any usage (no jobs have run charging that account), while values between 0.0 and 0.5 represent over-serviced accounts."
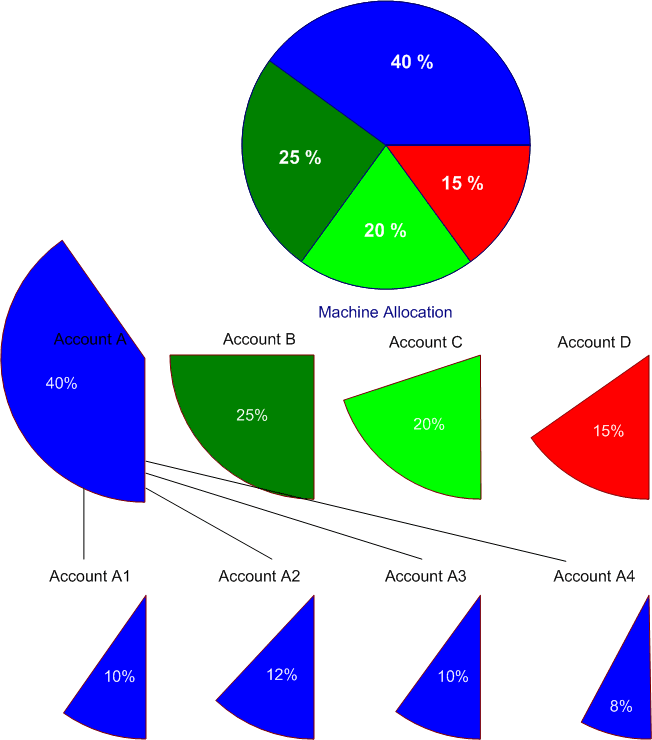
Slightly later, an enhancement was added that established a hierarchy of charge accounts. Shares of cluster's resources could be assigned to higher order charge accounts. Each of these accounts could have child charge accounts, and grandchildren accounts, and shares of the parent could be assigned independently to each child. I depicted this in a diagram which appears here
{kind=link}
While this re-ordering of a flat set of users into a hierarchy of charge accounts simplified the assignment and management of shares of a cluster to divisions, projects, and ultimately users, it complicated the creation of the fair-share factor that represented the level of service.
For example, how should fair-share factors be calculated for two users charging the same account when one user has never run a job and the other has run many jobs charged to the account? On the one hand, it seems unfair to assign a lower priority to jobs from the user who has yet to submit a job. On the other hand, it also seems unfair to sibling accounts to assign a fair-share factor of 1.0 to the first job the user submits. From the perspective of users' sibling accounts, all jobs charging an over-serviced account should have a lower fair-share priority than under-serviced accounts. And so it would appear that the user who has yet to run a job should suffer, do some degree, for the usage charged by their fellow users who have charged many runs to that account.
To address this, algorithms were devised to "thread the needle" and come up with fair-share factors that took into account all of the cpu cycles charged to an account and make adjustments for the different users drawing from the same account, whether they were under or over-serviced. The notion of "effective usage" was introduced. Users who had run many jobs charging an account were assigned a higher "effective usage", while those who had yet to submit a job were assigned a lower "effective usage" value that was greater than zero.
While this solution worked for most cases, there were corner cases where "unfairness" crept in. Over-serviced users in an account with 1 share had the same fair-share factor (zero) as over-serviced users in an account with many more shares. This prompted developers at BYU to develop the Fair Tree Fairshare Algorithm. They established a simple rule: the fair-share factor for all descendants of Account A had to be greater than all descendants of a sibling Account B, when the fair-share factor of Account A itself was greater than Account B’s fair-share factor.
The Flux solution adopts the same rule, but implements it in a more transparent way.