Read the article...
In the Web Browser, we can get Real-Time Logs from NuttX Devices (Web Serial API) NuttX Emulator (Term.js)...
What if we could Analyse the NuttX Logs in Real-Time? And show the results in the Web Browser?
Like for Stack Dumps, ELF Loader Log, Memory Manager Log (malloc / free)?
Let's do it with PureScript, since Functional Languages are better for Parsing Text.
And we'll support Online Scripting of our PureScript for Log Parsing, similar to try.purescript.org
(Also automate the Stack Dump Analysis)
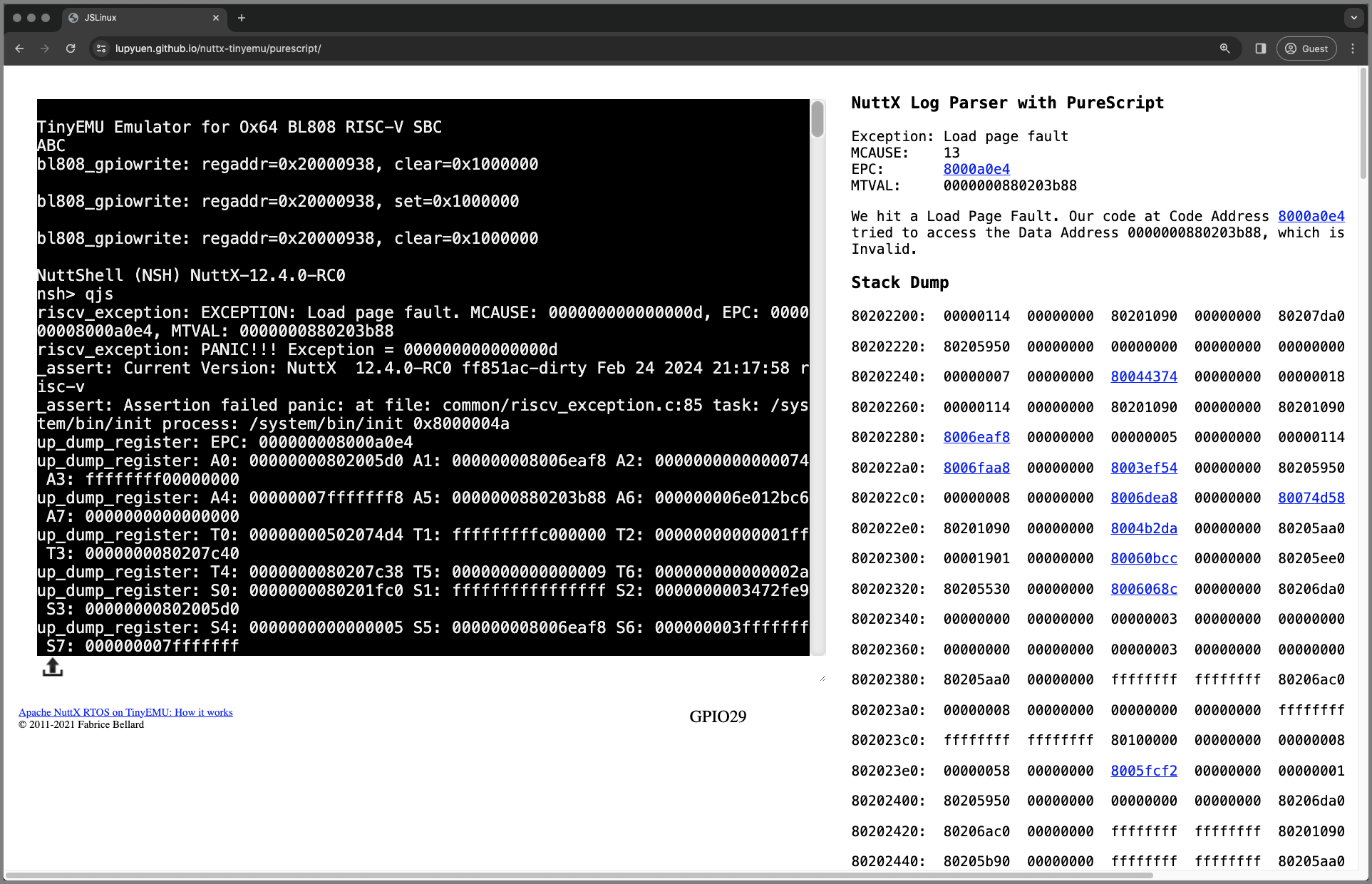
(Here's a NuttX Emulator that crashes. Guess why?)
Why not code all this in JavaScript instead of PureScript?
(1) NuttX Logs might appear differently over time. Good to have a quick way to patch our parser as the NuttX Logs change.
(2) We need to implement high-level Declarative Rules that will interpret the parsed NuttX Logs. We might adjust the Rules over time.
(FYI Parsing CSV in JavaScript looks like this)
Why PureScript instead of Haskell?
Right now our NuttX Logs are accessible in a Web Browser through JavaScript: NuttX Emulator (over WebAssembly) and NuttX Device (over Web Serial API).
PureScript is probably easier to run in a Web Browser for processing the JavaScript Logs.
(Zephyr Stack Dumps are also complicated)
Read the article...
Let's parse the NuttX Stack Dump...
[ 6.242000] riscv_exception: EXCEPTION: Instruction page fault. MCAUSE: 000000000000000c, EPC: 000000008000ad8a, MTVAL: 000000008000ad8a
[ 6.242000] riscv_exception: PANIC!!! Exception = 000000000000000c
[ 6.242000] _assert: Current Version: NuttX 12.4.0 f8b0b06b978 Jan 29 2024 01:16:20 risc-v
[ 6.242000] _assert: Assertion failed panic: at file: common/riscv_exception.c:85 task: /system/bin/init process: /system/bin/init 0xc000001a
[ 6.242000] up_dump_register: EPC: 000000008000ad8a
[ 6.242000] up_dump_register: A0: 0000000000000000 A1: 00000000c0202010 A2: 0000000000000001 A3: 00000000c0202010
[ 6.242000] up_dump_register: A4: 00000000c0000000 A5: 0000000000000000 A6: 0000000000000000 A7: 0000000000000000
[ 6.242000] up_dump_register: T0: 0000000000000000 T1: 0000000000000000 T2: 0000000000000000 T3: 0000000000000000
[ 6.242000] up_dump_register: T4: 0000000000000000 T5: 0000000000000000 T6: 0000000000000000
[ 6.242000] up_dump_register: S0: 0000000000000000 S1: 0000000000000000 S2: 0000000000000000 S3: 0000000000000000
[ 6.242000] up_dump_register: S4: 0000000000000000 S5: 0000000000000000 S6: 0000000000000000 S7: 0000000000000000
[ 6.242000] up_dump_register: S8: 0000000000000000 S9: 0000000000000000 S10: 0000000000000000 S11: 0000000000000000
[ 6.242000] up_dump_register: SP: 00000000c0202800 FP: 0000000000000000 TP: 0000000000000000 RA: 000000008000ad8a
[ 6.242000] dump_stack: User Stack:
[ 6.242000] dump_stack: base: 0xc0202040
[ 6.242000] dump_stack: size: 00003008
[ 6.242000] dump_stack: sp: 0xc0202800
[ 6.242000] stack_dump: 0xc02027e0: c0202010 00000000 00000001 00000000 00000000 00000000 8000ad8a 00000000
[ 6.242000] stack_dump: 0xc0202800: 00000000 00000000 0007e7f0 00000000 c0200208 00000000 c02001e8 00000000
Let's try this single line...
[ 6.242000] stack_dump: 0xc02027e0: c0202010 00000000 00000001 00000000 00000000 00000000 8000ad8a 00000000
Here's our parser in PureScript: src/Main.purs
-- Parse the NuttX Stack Dump.
-- The next line declares the Function Type. We can actually erase it, VSCode PureScript Extension will helpfully suggest it for us.
printResults :: Effect Unit
printResults = do
doRunParser "parseStackDump" parseStackDump
"[ 6.242000] stack_dump: 0xc02027e0: c0202010 00000000 00000001 00000000 00000000 00000000 8000ad8a 00000000"
-- Parse a line of NuttX Stack Dump.
-- Result: { addr: "c02027e0", timestamp: "6.242000", v1: "c0202010", v2: "00000000", v3: "00000001", v4: "00000000", v5: "00000000", v6: "00000000", v7: "8000ad8a", v8: "00000000" }
-- The next line declares the Function Type. We can actually erase it, VSCode PureScript Extension will helpfully suggest it for us.
parseStackDump ∷ Parser { addr ∷ String , timestamp ∷ String , v1 ∷ String , v2 ∷ String , v3 ∷ String , v4 ∷ String , v5 ∷ String , v6 ∷ String , v7 ∷ String , v8 ∷ String }
parseStackDump = do
-- To parse the line: `[ 6.242000] stack_dump: 0xc02027e0: c0202010 00000000 00000001 00000000 00000000 00000000 8000ad8a 00000000`
-- Skip `[ `
-- `void` means ignore the Text Captured
-- `$ something something` is shortcut for `( something something )`
-- `<*` is the Delimiter between Patterns
void $
string "[" -- Match the string `[`
<* skipSpaces -- Skip the following spaces
-- `timestamp` becomes `6.242000`
-- `<*` says when we should stop the Text Capture
timestamp <-
regex "[.0-9]+"
<* string "]"
<* skipSpaces
-- Skip `stack_dump: `
-- `void` means ignore the Text Captured
-- `$ something something` is shortcut for `( something something )`
-- `<*` is the Delimiter between Patterns
void $ string "stack_dump:" <* skipSpaces
-- `addr` becomes `c02027e0`
void $ string "0x"
addr <- regex "[0-9a-f]+" <* string ":" <* skipSpaces
-- `v1` becomes `c0202010`
-- `v2` becomes `00000000` and so on
v1 <- regex "[0-9a-f]+" <* skipSpaces
v2 <- regex "[0-9a-f]+" <* skipSpaces
v3 <- regex "[0-9a-f]+" <* skipSpaces
v4 <- regex "[0-9a-f]+" <* skipSpaces
v5 <- regex "[0-9a-f]+" <* skipSpaces
v6 <- regex "[0-9a-f]+" <* skipSpaces
v7 <- regex "[0-9a-f]+" <* skipSpaces
v8 <- regex "[0-9a-f]+" <* skipSpaces
-- Return the parsed content
-- `pure` because we're in a `do` block that allows Effects
pure
{ timestamp
, addr
, v1
, v2
, v3
, v4
, v5
, v6
, v7
, v8
}Result of parsing...
## We're parsing: [ 6.242000] stack_dump: 0xc02027e0: c0202010 00000000 00000001 00000000 00000000 00000000 8000ad8a 00000000
$ spago run
[info] Build succeeded.
(runParser) Parsing content with 'parseStackDump'
Result: {
addr: "c02027e0", timestamp: "6.242000",
v1: "c0202010", v2: "00000000", v3: "00000001", v4: "00000000",
v5: "00000000", v6: "00000000", v7: "8000ad8a", v8: "00000000" }Not that hard! We could have refactored the code to make it shorter. But we'll keep it long because it's easier to read.
Works OK in JavaScript too: index.html
// Run parseStackDump
const stackDump = `[ 6.242000] stack_dump: 0xc02027e0: c0202010 00000000 00000001 00000000 00000000 00000000 8000ad8a 00000000`;
const result = StringParser_Parser
.runParser
(parseStackDump)
(stackDump)
;
console.log({result});Shows...
{
"result": {
"value0": {
"timestamp": "6.242000",
"addr": "c02027e0",
"v1": "c0202010",
"v2": "00000000",
"v3": "00000001",
"v4": "00000000",
"v5": "00000000",
"v6": "00000000",
"v7": "8000ad8a",
"v8": "00000000"
}
}
}What if the parsing fails?
We'll see result.error...
{
"result": {
"value0": {
"pos": 0,
"error": "Expected '['."
}
}
}So we can run parseStackDump on every line of NuttX Log. And skip the lines with result.error
TODO: Spot interesting addresses like 8000ad8a, c0202010
Read the article...
Let's parse the NuttX Exception...
[ 6.242000] riscv_exception: EXCEPTION: Instruction page fault. MCAUSE: 000000000000000c, EPC: 000000008000ad8a, MTVAL: 000000008000ad8a
Here's how we parse the NuttX Exception in PureScript: src/Main.purs
-- Parse the NuttX Exception.
-- Given this NuttX Exception: `riscv_exception: EXCEPTION: Instruction page fault. MCAUSE: 000000000000000c, EPC: 000000008000ad8a, MTVAL: 000000008000ad8a`
-- Result: { epc: "000000008000ad8a", exception: "Instruction page fault", mcause: 12, mtval: "000000008000ad8a" }
-- The next line declares the Function Type. We can actually erase it, VSCode PureScript Extension will helpfully suggest it for us.
parseException ∷ Parser { exception ∷ String, mcause :: Int, epc :: String, mtval :: String }
parseException = do
-- To parse the line: `riscv_exception: EXCEPTION: Instruction page fault. MCAUSE: 000000000000000c, EPC: 000000008000ad8a, MTVAL: 000000008000ad8a`
-- Skip `riscv_exception: EXCEPTION: `
-- `void` means ignore the Text Captured
-- `$ something something` is shortcut for `( something something )`
-- `<*` is the Delimiter between Patterns
void $
string "riscv_exception:" -- Match the string `riscv_exception:`
<* skipSpaces -- Skip the following spaces
<* string "EXCEPTION:" -- Match the string `EXCEPTION:`
<* skipSpaces -- Skip the following spaces
-- `exception` becomes `Instruction page fault`
-- `<*` says when we should stop the Text Capture
exception <- regex "[^.]+"
<* string "."
<* skipSpaces
-- Skip `MCAUSE: `
-- `void` means ignore the Text Captured
-- `$ something something` is shortcut for `( something something )`
-- `<*` is the Delimiter between Patterns
void $ string "MCAUSE:" <* skipSpaces
-- `mcauseStr` becomes `000000000000000c`
-- We'll convert to integer later
mcauseStr <- regex "[0-9a-f]+" <* string "," <* skipSpaces
-- Skip `EPC: `
-- `epc` becomes `000000008000ad8a`
void $ string "EPC:" <* skipSpaces
epc <- regex "[0-9a-f]+" <* string "," <* skipSpaces
-- Skip `MTVAL: `
-- `mtval` becomes `000000008000ad8a`
void $ string "MTVAL:" <* skipSpaces
mtval <- regex "[0-9a-f]+"
-- Return the parsed content
-- `pure` because we're in a `do` block that allows (Side) Effects
pure
{
exception
, mcause: -1 `fromMaybe` -- If `mcauseStr` is not a valid hex, return -1
fromStringAs hexadecimal mcauseStr -- Else return the hex value of `mcauseStr`
, epc
, mtval
}We can run it in Web Browser JavaScript: index.html
// Run parseException
const exception = `riscv_exception: EXCEPTION: Instruction page fault. MCAUSE: 000000000000000c, EPC: 000000008000ad8a, MTVAL: 000000008000ad8a`
const result1 = StringParser_Parser
.runParser
(parseException)
(exception)
;
console.log({result1});Which shows...
{
"result1": {
"value0": {
"exception": "Instruction page fault",
"mcause": 12,
"epc": "000000008000ad8a",
"mtval": "000000008000ad8a"
}
}
}Read the article...
We explain in friendly words what the NuttX Exception means...
"NuttX crashed because it tried to read or write an Invalid Address. The Invalid Address is 8000ad8a. The code that caused this is at 8000ad8a. Check the NuttX Disassembly for the Source Code of the crashing line."
Here's how we explain the NuttX Exception in PureScript: src/Main.purs
-- Given this NuttX Exception: `riscv_exception: EXCEPTION: Instruction page fault. MCAUSE: 000000000000000c, EPC: 000000008000ad8a, MTVAL: 000000008000ad8a`
-- Explain in friendly words: "NuttX stopped because it tried to read or write an Invalid Address. The Invalid Address is 8000ad8a. The code that caused this is at 8000ad8a. Check the NuttX Disassembly for the Source Code of the crashing line."
-- The next line declares the Function Type. We can actually erase it, VSCode PureScript Extension will helpfully suggest it for us.
explainException ∷ Int → String → String → String
-- Explain the NuttX Exception with mcause 12
explainException 12 epc mtval =
"Instruction Page Fault at " <> epc <> ", " <> mtval
-- Explain the Other NuttX Exceptions, that are not matched with the above
explainException mcause epc mtval =
"Unknown Exception: mcause=" <> show mcause <> ", epc=" <> epc <> ", mtval=" <> mtvalWe can run it in Web Browser JavaScript: index.html
// Run explainException
const result2 = explainException(12)('000000008000ad8a')('000000008000ad8a')
console.log({result2});Which shows...
{
"result2": "Instruction Page Fault at 000000008000ad8a, 000000008000ad8a"
}Read the article...
In the JavaScript generated by PureScript, we point the PureScript Imports to compile.purescript.org, so we don't need to deploy the imports: run.sh
## Change:
## import { main, doBoth, doRunParser, parseCSV, exampleContent2, parseException, parseStackDump, explainException } from './output/Main/index.js';
## To:
## import { main, doBoth, doRunParser, parseCSV, exampleContent2, parseException, parseStackDump, explainException } from './index.js';
## Change:
## import * as StringParser_Parser from "./output/StringParser.Parser/index.js";
## To:
## import * as StringParser_Parser from "https://compile.purescript.org/output/StringParser.Parser/index.js";
cat index.html \
| sed 's/output\/Main\///' \
| sed 's/.\/output\//https:\/\/compile.purescript.org\/output\//' \
>docs/index.html
## Change:
## import * as Control_Alt from "../Control.Alt/index.js";
## To:
## import * as Control_Alt from "https://compile.purescript.org/output/Control.Alt/index.js";
cat output/Main/index.js \
| sed 's/from \"../from \"https:\/\/compile.purescript.org\/output/' \
>docs/index.jsTry it here: https://lupyuen.github.io/nuttx-purescript-parser/
Read the article...
After rewriting the JavaScript Imports, we may now call PureScript from NuttX Emulator: index.html
<script type=module>
// Import Main Module
import { main, doBoth, doRunParser, parseCSV, exampleContent2, parseException, parseStackDump, explainException } from 'https://lupyuen.github.io/nuttx-purescript-parser/index.js';
import * as StringParser_Parser from "https://compile.purescript.org/output/StringParser.Parser/index.js";
// Run parseException
console.log('Running parseException...');
const exception = `riscv_exception: EXCEPTION: Instruction page fault. MCAUSE: 000000000000000c, EPC: 000000008000ad8a, MTVAL: 000000008000ad8a`
const result1 = StringParser_Parser
.runParser
(parseException)
(exception)
;
console.log({result1});
// Run explainException
const result2 = explainException(12)('000000008000ad8a')('000000008000ad8a')
console.log({result2});
// Run parseStackDump
console.log('Running parseStackDump...');
const stackDump = `[ 6.242000] stack_dump: 0xc02027e0: c0202010 00000000 00000001 00000000 00000000 00000000 8000ad8a 00000000`;
const result3 = StringParser_Parser
.runParser
(parseStackDump)
(stackDump)
;
console.log({result3});
</script>Try it here: https://lupyuen.github.io/nuttx-tinyemu/purescript
Read the article...
This is how we parse every line of Terminal Output from NuttX Emulator: term.js
// When TinyEMU prints to the Terminal Output...
Term.prototype.write = function(str) {
// Parse the output with PureScript
parseLog(str);
...
}
// Parse NuttX Logs with PureScript.
// Assume `str` is a single character for Terminal Output. We accumulate the characters and parse the line.
// PureScript Parser is inited in `index.html`
function parseLog(str) {
// Accumulate the characters into a line
if (!window.StringParser_Parser) { return; }
termbuf += str;
if (termbuf.indexOf("\r") < 0) { return; }
// Ignore all Newlines and Carriage Returns
termbuf = termbuf
.split("\r").join("")
.split("\n").join("");
// console.log({termbuf});
// Parse the Exception
const exception = StringParser_Parser
.runParser(parseException)(termbuf)
.value0;
// Explain the Exception
if (exception.error === undefined) {
console.log({exception});
const explain = explainException(exception.mcause)(exception.epc)(exception.mtval);
console.log({explain});
}
// Run parseStackDump
const stackDump = StringParser_Parser
.runParser(parseStackDump)(termbuf)
.value0;
if (stackDump.error === undefined) { console.log({stackDump}); }
// Reset the Line Buffer
termbuf = "";
}
// Buffer the last line of the Terminal Output
let termbuf = "";And it works correctly yay!
"exception": {
"exception": "Load page fault",
"mcause": 13,
"epc": "000000008000a0e4",
"mtval": "0000000880203b88"
}
"explain": "Load Page Fault at 000000008000a0e4, 0000000880203b88"
Try it here: https://lupyuen.github.io/nuttx-tinyemu/purescript
Read the article...
Given an Exception Address like 8000ad8a, can we show the NuttX Disassembly?
We need to chunk nuttx.S (or qjs.S) by address: nuttx-8000ad90.S, nuttx-8000ae00.S, nuttx-8000b000.S, nuttx-80010000.S. And link to the NuttX Repo Source Code.
Let's chunk qjs.S, the NuttX App Disassembly for QuickJS JavaScript Engine...
-
Code Addresses are at 0x8000_0000 to 0x8006_4a28
-
Spanning 277K lines of code!
We created a NuttX Disassembly Chunker that will...
-
Split a huge NuttX Disassembly: qjs.S
-
Into smaller Disassembly Chunk Files: qjs-chunk/qjs-80001000.S
-
So that Disassembly Address 0x8000_0000 will be located in qjs-80001000.S
-
And Disassembly Address 0x8000_1000 will be located in qjs-80002000.S, ...
This is how we chunk a NuttX Disassembly from qjs.S to qjs-chunk...
## Chunk NuttX Disassembly $HOME/qjs.S into
## $HOME/qjs-chunk/qjs-80001000.S
## $HOME/qjs-chunk/qjs-80002000.S
## ...
chunkpath=$HOME
chunkbase=qjs
mkdir -p $chunkpath/$chunkbase-chunk
rm -f $chunkpath/$chunkbase-chunk/*
cargo run -- $chunkpath $chunkbaseAnd this is how we display the Disassembly Chunk by Address: disassemble.js
// Show the NuttX Disassembly for the Requested Address
// http://localhost:8000/nuttx-tinyemu/docs/purescript/disassemble.html?addr=80007028
// Show 20 lines before and after the Requested Address
const before_count = 20;
const after_count = 20;
// Convert `nuttx/arch/risc-v/src/common/crt0.c:166`
// To `<a href="https://github.com/apache/nuttx/blob/master/arch/risc-v/src/common/crt0.c#L166">...`
// Convert `quickjs-nuttx/quickjs-libc.c:1954`
// To `<a href="https://github.com/lupyuen/quickjs-nuttx/blob/master/quickjs-libc.c#L1954">...`
const search1 = "nuttx/";
const replace1 = "https://github.com/apache/nuttx/blob/master/";
const search2 = "quickjs-nuttx/";
const replace2 = "https://github.com/lupyuen/quickjs-nuttx/blob/master/";
// Convert the Source File to Source URL
function processLine(line) {
line = line.split("\t").join(" ");
if (line.indexOf(":") < 0) { return line; }
let url = line.split(":", 2).join("#L");
// Search and replace Source File to Source URL
if (line.indexOf(search1) == 0) {
url = url.split(search1, 2).join(replace1);
} else if (line.indexOf(search2) == 0) {
url = url.split(search2, 2).join(replace2);
} else {
return line;
}
return `<a href="${url}" target="_blank">${line}</a>`;
}
// Fetch our Disassembly File, line by line
// https://developer.mozilla.org/en-US/docs/Web/API/Fetch_API/Using_Fetch#processing_a_text_file_line_by_line
async function* makeTextFileLineIterator(fileURL) {
const utf8Decoder = new TextDecoder("utf-8");
const response = await fetch(fileURL);
const reader = response.body.getReader();
let { value: chunk, done: readerDone } = await reader.read();
chunk = chunk ? utf8Decoder.decode(chunk) : "";
const newline = /\r?\n/gm;
let startIndex = 0;
let result;
while (true) {
const result = newline.exec(chunk);
if (!result) {
if (readerDone) break;
const remainder = chunk.substr(startIndex);
({ value: chunk, done: readerDone } = await reader.read());
chunk = remainder + (chunk ? utf8Decoder.decode(chunk) : "");
startIndex = newline.lastIndex = 0;
continue;
}
yield chunk.substring(startIndex, result.index);
startIndex = newline.lastIndex;
}
if (startIndex < chunk.length) {
// Last line didn't end in a newline char
yield chunk.substr(startIndex);
}
}
// Fetch and display our Disassembly File, line by line
async function run() {
// Set the Title. `addr` is `80007028`
const addr = new URL(document.URL).searchParams.get("addr");
const title = document.getElementById("title");
title.innerHTML +=
addr.substring(0, 4).toUpperCase()
+ "_"
+ addr.substring(4).toUpperCase();
// URL of our Disassembly File, chunked for easier display.
// TODO: Given an Exception Address like 8000ad8a. we should try multiple files by address:
// qjs-8000ad90.S, qjs-8000ae00.S, qjs-8000b000.S, qjs-80010000.S
const url = "qjs-chunk/qjs-80008000.S";
// Remember the lines before and after the Requested Address
const before_lines = [];
const after_lines = [];
let linenum = 0;
// Process our Disassembly File, line by line
const iter = makeTextFileLineIterator(url);
for await (const line1 of iter) {
if (after_lines.length == 0) { linenum++; }
// Look for the Requested Address
if (line1.indexOf(` ${addr}:`) == 0) {
const line2 = processLine(line1);
after_lines.push(line2);
continue;
}
// Save the lines before the Requested Address
const line2 = processLine(line1);
if (after_lines.length == 0) {
before_lines.push(line2);
if (before_lines.length > before_count) { before_lines.shift(); }
} else {
// Save the lines after the Requested Address
after_lines.push(line2);
if (after_lines.length > after_count) { break; }
}
}
// Requested Line is `after_lines[0]`.
// Show the Before and After Lines.
const line = after_lines[0];
after_lines.shift();
console.log({before_lines});
console.log({line});
console.log({after_lines});
const disassembly = document.getElementById("disassembly");
const file = `https://github.com/lupyuen/nuttx-tinyemu/tree/main/docs/purescript/${url}#L${linenum}`;
disassembly.innerHTML = [
`<p><a href=${file}>(See the Disassembly File)</a></p>`,
before_lines.join("<br>"),
`<span id="highlight"><br>${line}<br></span>`,
after_lines.join("<br>"),
`<p><a href=${file}>(See the Disassembly File)</a></p>`,
].join("<br>");
}
run();Try it here: https://lupyuen.github.io/nuttx-tinyemu/purescript/disassemble.html?addr=8000702a
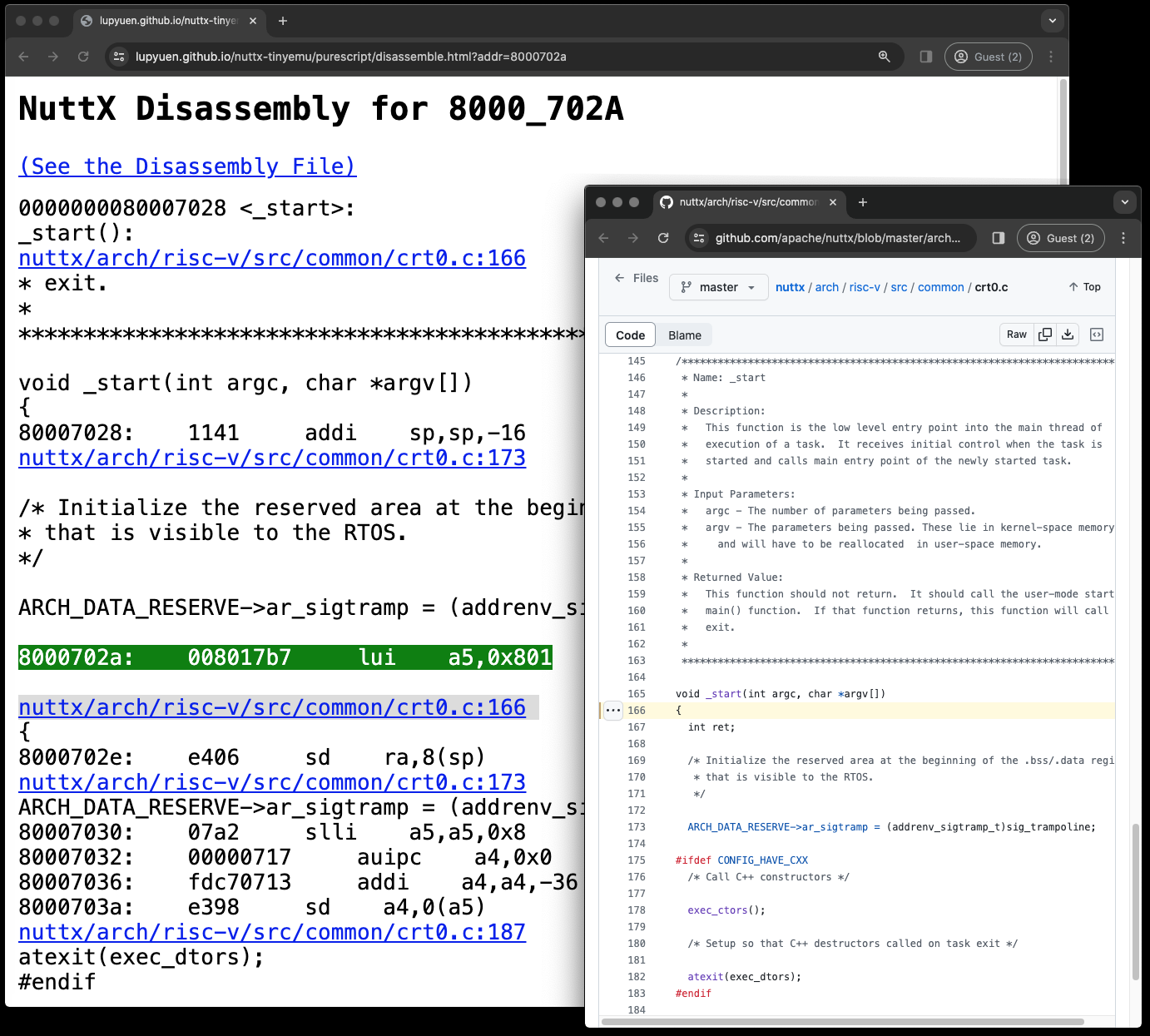
Read the article...
Given a NuttX Address like 80007028: How will we know whether it's in NuttX Kernel or NuttX Apps? And whether it's Code, Data, BSS or Heap?
This is how we identify a NuttX Address in PureScript: src/Main.purs
-- Given an Address, identify the Origin (NuttX Kernel or App) and Type (Code / Data / BSS / Heap)
identifyAddress ∷ String → Maybe { origin ∷ String , type ∷ AddressType }
-- Address 502xxxxx comes from NuttX Kernel Code
-- Address 800xxxxx comes from NuttX App Code (QuickJS)
-- `|` works like `if ... else if`
-- "a `matches` b" is same as "(matches a b)"
-- `Just` returns an OK Value. `Nothing` returns No Value.
identifyAddress addr
| "502....." `matches` addr = Just { origin: "nuttx", type: Code }
| "800....." `matches` addr = Just { origin: "qjs", type: Code }
| otherwise = Nothing
-- Address can point to Code, Data, BSS or Heap
data AddressType = Code | Data | BSS | Heap
-- How to display an Address Type
instance Show AddressType where
show Code = "Code"
show Data = "Data"
show BSS = "BSS"
show Heap = "Heap"
-- Return True if the Address matches the Regex Pattern.
-- Pattern is assumed to match the Entire Address.
matches ∷ String → String → Boolean
-- Match the Begin `^` and End `$` of the Address
-- `<>` will concat 2 strings
-- "a `unsafeRegex` b" is same as "(unsafeRegex a b)"
matches pattern addr =
let
patternWrap = "^" <> pattern <> "$"
in
isJust $ -- Is there a Match...
patternWrap `unsafeRegex` noFlags -- For our Regex Pattern (no special flags)
`match` addr -- Against the Address?
-- Test our code. Parse the NuttX Exception and NuttX Stack Dump. Explain the NuttX Exception.
-- `Effect` says that it will do Side Effects (printing to console)
-- `Unit` means that no value will be returned
-- The next line declares the Function Type. We can actually erase it, VSCode PureScript Extension will helpfully suggest it for us.
printResults :: Effect Unit
printResults = do
-- NuttX Kernel: 0x5020_0000 to 0x5021_98ac
-- NuttX App (qjs): 0x8000_0000 to 0x8006_4a28
logShow $ identifyAddress "502198ac" -- (Just { origin: "nuttx", type: Code })
logShow $ identifyAddress "8000a0e4" -- (Just { origin: "qjs", type: Code })
logShow $ identifyAddress "0000000800203b88" -- NothingTsk tsk so much Hard Coding...
Our Rules are still evolving, we're not sure how the NuttX Log Parser will be used in future.
That's why we need a PureScript Editor that will allow the Rules to be tweaked easily for other platforms...
Read the article...
How to build a PureScript Editor that will allow the Rules to be tweaked easily for other platforms?
To run our PureScript Editor for NuttX...
git clone https://github.com/lupyuen/nuttx-trypurescript
cd nuttx-trypurescript
cd client
## Build and Test Locally:
npm install
## Produces `output` folder
## And `public/js/index.js`
npm run serve:production
## Test at http://127.0.0.1:8080
## Deploy to GitHub Pages:
rm -r ../docs
cp -r public ../docs
simple-http-server .. &
## Test at http://0.0.0.0:8000/docs/index.html
## If we need `client.js` bundle:
## npm run build:productionTry it here: https://lupyuen.github.io/nuttx-trypurescript
Copy src/Main.purs to the PureScript Editor.
main :: Effect Unit
main = printResultsTo this...
import TryPureScript (render, withConsole)
main :: Effect Unit
main = render =<< withConsole do
printResultsOur NuttX Parser Output appears...
Instruction Page Fault at epc, mtval
Unknown Exception: mcause=0, epc=epc, mtval=mtval
(runParser) Parsing content with 'parseException'
Result: { epc: "000000008000ad8a", exception: "Instruction page fault", mcause: 12, mtval: "000000008000ad8a" }
-----
(runParser) Parsing content with 'parseStackDump'
Result: { addr: "c02027e0", timestamp: "6.242000", v1: "c0202010", v2: "00000000", v3: "00000001", v4: "00000000", v5: "00000000", v6: "00000000", v7: "8000ad8a", v8: "00000000" }
-----
The Generated Web Browser JavaScript looks like this...
<script type="module">
import * as Control_Alt from "https://compile.purescript.org/output/Control.Alt/index.js";
import * as Control_Applicative from "https://compile.purescript.org/output/Control.Applicative/index.js";
import * as Control_Apply from "https://compile.purescript.org/output/Control.Apply/index.js";
...
var bind = /* #__PURE__ */ Control_Bind.bind(StringParser_Parser.bindParser);
var alt = /* #__PURE__ */ Control_Alt.alt(StringParser_Parser.altParser);
var voidRight = /* #__PURE__ */ Data_Functor.voidRight(StringParser_Parser.functorParser);
...TODO: Where is Main Function?
TODO: Copy Generated JavaScript to NuttX Emulator
Read the article...
Why are we passing addresses in Text instead of Numbers? Like 8000ad8a
That's because 0x8000ad8a is too big for PureScript Int, a signed 32-bit integer. PureScript Int is meant to interoperate with JavaScript Integer, which is also 32-bit.
What about PureScript BigInt?
spago install bigints
npm install big-integerIf we use PureScript BigInt, then we need NPM big-integer.
But NPM big-integer won't run inside a Web Browser with Plain Old JavaScript. That's why we're passing addresses as Strings instead of Numbers.
Let's run parseCSV in Node.js. Normally we run PureScript like this...
spago runThis is how we run it in Node.js...
$ spago build
$ node .spago/run.js
### Example Content 1 ###
(runParser) Parsing content with 'fail'
{ error: "example failure message", pos: 0 }
-----
(unParser) Parsing content with 'fail'
Position: 0
Error: "example failure message"
-----
(runParser) Parsing content with 'numberOfAs'
Result was: 6
-----
(unParser) Parsing content with 'numberOfAs'
Result was: 6
Suffix was: { position: 59, substring: "" }
-----
(runParser) Parsing content with 'removePunctuation'
Result was: "How many as are in this sentence you ask Not that many"
-----
(unParser) Parsing content with 'removePunctuation'
Result was: "How many as are in this sentence you ask Not that many"
Suffix was: { position: 59, substring: "" }
-----
(runParser) Parsing content with 'replaceVowelsWithUnderscore'
Result was: "H_w m_ny '_'s _r_ _n th_s s_nt_nc_, y__ _sk? N_t th_t m_ny."
-----
(unParser) Parsing content with 'replaceVowelsWithUnderscore'
Result was: "H_w m_ny '_'s _r_ _n th_s s_nt_nc_, y__ _sk? N_t th_t m_ny."
Suffix was: { position: 59, substring: "" }
-----
(runParser) Parsing content with 'tokenizeContentBySpaceChars'
Result was: (NonEmptyList (NonEmpty "How" ("many" : "'a's" : "are" : "in" : "this" : "sentence," : "you" : "ask?" : "Not" : "that" : "many." : Nil)))
-----
(unParser) Parsing content with 'tokenizeContentBySpaceChars'
Result was: (NonEmptyList (NonEmpty "How" ("many" : "'a's" : "are" : "in" : "this" : "sentence," : "you" : "ask?" : "Not" : "that" : "many." : Nil)))
Suffix was: { position: 59, substring: "" }
-----
(runParser) Parsing content with 'extractWords'
Result was: (NonEmptyList (NonEmpty "How" ("many" : "a" : "s" : "are" : "in" : "this" : "sentence" : "you" : "ask" : "Not" : "that" : "many" : Nil)))
-----
(unParser) Parsing content with 'extractWords'
Result was: (NonEmptyList (NonEmpty "How" ("many" : "a" : "s" : "are" : "in" : "this" : "sentence" : "you" : "ask" : "Not" : "that" : "many" : Nil)))
Suffix was: { position: 59, substring: "" }
-----
(runParser) Parsing content with 'badExtractWords'
{ error: "Could not find a character that separated the content...", pos: 43 }
-----
(unParser) Parsing content with 'badExtractWords'
Position: 43
Error: "Could not find a character that separated the content..."
-----
(runParser) Parsing content with 'quotedLetterExists'
Result was: true
-----
(unParser) Parsing content with 'quotedLetterExists'
Result was: true
Suffix was: { position: 59, substring: "" }
-----
### Example Content 2 ###
(runParser) Parsing content with 'parseCSV'
Result was: { age: "24", firstName: "Mark", idNumber: "523", lastName: "Kenderson", modifiedEmail: "[email protected]", originalEmail: "[email protected]" }
-----
(unParser) Parsing content with 'parseCSV'
Result was: { age: "24", firstName: "Mark", idNumber: "523", lastName: "Kenderson", modifiedEmail: "[email protected]", originalEmail: "[email protected]" }
Suffix was: { position: 110, substring: "" }
-----Here's how we run parseCSV in the Web Browser: index.html
// Import Main Module
import { main, doBoth, doRunParser, parseCSV, exampleContent2 } from './output/Main/index.js';
import * as StringParser_Parser from "./output/StringParser.Parser/index.js";
// Run parseCSV
const result = StringParser_Parser
.runParser
(parseCSV)
(exampleContent2)
;
console.log({result});Output:
{
"result": {
"value0": {
"idNumber": "523",
"firstName": "Mark",
"lastName": "Kenderson",
"age": "24",
"originalEmail": "[email protected]",
"modifiedEmail": "[email protected]"
}
}
}We expose the PureScript Functions in the Web Browser: index.html
// Import Main Module
import { main, doBoth, doRunParser, parseCSV, exampleContent2 } from './output/Main/index.js';
import * as StringParser_Parser from "./output/StringParser.Parser/index.js";
// For Testing: Export the PureScript Functions
window.main = main;
window.doBoth = doBoth;
window.doRunParser = doRunParser;
window.parseCSV = parseCSV;
window.exampleContent2 = exampleContent2;
window.StringParser_Parser = StringParser_Parser;So we can run experiments in the JavaScript Console...
// Run parseCSV in JavaScript Console
window.StringParser_Parser
.runParser
(window.parseCSV)
(window.exampleContent2)To run parseCSV at try.purescript.org, change...
main :: Effect Unit
main = printResultsTo this...
import TryPureScript (render, withConsole)
main :: Effect Unit
main = render =<< withConsole do
printResultsHere's how we compile PureScript to JavaScript inside our Web Browser...
// Compile PureScript to JavaScript
// Maybe we'll run a PureScript to analyse the Real-Time Logs from a NuttX Device?
// https://lupyuen.github.io/nuttx-tinyemu/blockly/
async function compile_purescript() {
// Public Server API that compiles PureScript to JavaScript
// https://github.com/purescript/trypurescript#server-api
const url = "https://compile.purescript.org/compile";
const contentType = "text/plain;charset=UTF-8";
// PureScript to be compiled to JavaScript
const body =
`
module Main where
import Prelude
import Effect (Effect)
import Effect.Console (log)
import Data.Array ((..))
import Data.Foldable (for_)
import TryPureScript (render, withConsole)
main :: Effect Unit
main = render =<< withConsole do
for_ (10 .. 1) \\n -> log (show n <> "...")
log "Lift off!"
`;
// Call Public Server API to compile our PureScript to JavaScript
// Default options are marked with *
// https://developer.mozilla.org/en-US/docs/Web/API/Fetch_API/Using_Fetch
const response = await fetch(url, {
method: "POST", // *GET, POST, PUT, DELETE, etc.
mode: "cors", // no-cors, *cors, same-origin
cache: "no-cache", // *default, no-cache, reload, force-cache, only-if-cached
credentials: "same-origin", // include, *same-origin, omit
headers: { "Content-Type": contentType },
redirect: "follow", // manual, *follow, error
referrerPolicy: "no-referrer", // no-referrer, *no-referrer-when-downgrade, origin, origin-when-cross-origin, same-origin, strict-origin, strict-origin-when-cross-origin, unsafe-url
body: body,
});
// Print the response
// { "js": "import * as Control_Bind from \"../Control.Bind/index.js\";\nimport * as Data_Array from \"../Data.Array/index.js\";\nimport * as Data_Foldable from \"../Data.Foldable/index.js\";\nimport * as Data_Show from \"../Data.Show/index.js\";\nimport * as Effect from \"../Effect/index.js\";\nimport * as Effect_Console from \"../Effect.Console/index.js\";\nimport * as TryPureScript from \"../TryPureScript/index.js\";\nvar show = /* #__PURE__ */ Data_Show.show(Data_Show.showInt);\nvar main = /* #__PURE__ */ Control_Bind.bindFlipped(Effect.bindEffect)(TryPureScript.render)(/* #__PURE__ */ TryPureScript.withConsole(function __do() {\n Data_Foldable.for_(Effect.applicativeEffect)(Data_Foldable.foldableArray)(Data_Array.range(10)(1))(function (n) {\n return Effect_Console.log(show(n) + \"...\");\n })();\n return Effect_Console.log(\"Lift off!\")();\n}));\nexport {\n main\n};",
// "warnings": [] }
console.log(await response.json());
}The JSON Response looks like this...
{
"js": "
import * as Control_Bind from "../Control.Bind/index.js";
import * as Data_Array from "../Data.Array/index.js";
import * as Data_Foldable from "../Data.Foldable/index.js";
import * as Data_Show from "../Data.Show/index.js";
import * as Effect from "../Effect/index.js";
import * as Effect_Console from "../Effect.Console/index.js";
import * as TryPureScript from "../TryPureScript/index.js";
var show = /* #__PURE__ */ Data_Show.show(Data_Show.showInt);
var main = /* #__PURE__ */ Control_Bind.bindFlipped(Effect.bindEffect)(TryPureScript.render)(/* #__PURE__ */ TryPureScript.withConsole(function __do() {
Data_Foldable.for_(Effect.applicativeEffect)(Data_Foldable.foldableArray)(Data_Array.range(10)(1))(function (n) {
return Effect_Console.log(show(n) + "...");
})();
return Effect_Console.log("Lift off!")();
}));
export {
main
};
",
"warnings": []
}