
An experimental distributed streaming platform

Currently, working in the foundation of the storage layer.
Found an issue? Feel like contributing? Make sure to check out our contributing guide first.
To know more about component internals, performance and references, please check the architecture internals documentation.
- Learn
- Implement a Kinesis-like streaming-service
- Single binary
- Easy to Host, Run & Operate
Available make commands
make build- Builds the application with cargomake build_release- Builds the application with cargo, with release optimizationsmake docker_test_watcher- Runs funzzy on linux over docker-composemake docs- Generates the GitHub Markdown docs (At the moment only mermaid)make format- Formats the code according to cargomake help- Lists the available commandsmake install- Builds a release version and installs to your cago bin pathmake run- Runs the newly builtmake test- Tests all features
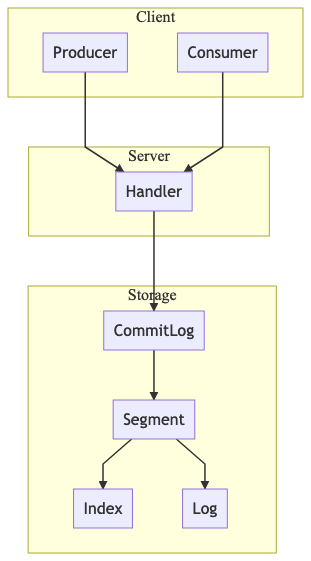
At this point, we have only the foundation of the Storage layer implemented. The other parts of the above picture are for demonstration purposes of future componentes.
The storage layer is where the data is persisted for long-term reading.
The main component of the whole system is the commit-log, an abstraction manages reads and writes to the log by implementing an immutable, append-only, file-backed sequence of "records", or chunks of data/events that are transmited from producers to consumers.
Records can be written to the log, always appending the last record over and over.
e.g.:
current cursor
segment 0 ^
|-------------------------------|
| record 0 | record 1 | ... | --> time
|-------------------------------|
In order to manage and scale read and writes, the commit-log split groups of records into Segments, managing to write to a single segment until it reaches a certain, specified size.
Each time a record is written, the segment is trusted to have enough space for the given buffer, then the record is written to the current segment, and the pointer is updated.
More info in the commit_log/src/lib.rs file.
A Segment is a tuple abstraction to manage the Index and Log files.
Every Segment is composed of a log-file and an index, e.g.:
00000000000011812312.log
00000000000011812312.idx
The role of the segment is to manage writes to the logfile and ensure the entries can be read later on by doing lookups in the index.
On every write, the segment writes an entry to the index with the record's position and size, in the log-file, for later use.
The segment also manages the size of the log file, preventing it from being written once it reaches the specified.
When a segment is full, the commit log makes sure to rotate to a new one, closing the old one.
See how it looks like on disk (on a high-level):
current cursor
segment 0 ^
|-------------------------------| |
| record 0 | record 1 | ... | segment 1 (current) |
|-------------------------------|-----------------------------| --> time
| record 2 | record 3 | ... |
|-----------------------------|
Under the hood is a bit more complex, the management of writing to the file to disk is of the Segments', as well as managing the Index file.
More info in the commit_log/src/segment.rs and commit_log/src/segment/index.rs and log.rs files.
The log file is a varied-size sequence of bytes that is storing the content of the records produced by the producers. However, the log itself doesn't have any mechanism for recovery of such records. That's responsibility of the index.
Once initialized, the log-file is truncated to reach the desired value and reserve both memory and disk space, the same for the index.
current cursor
^
|-------------------------------|
| record 0 | record 1 | ... |----> time
|-------------------------------|
Neither reads nor writes to the index are directly triggering disk-level actions.
Both operations are being intermediated by a memory-mapping buffers, managed by the OS.
More info in the commit_log/src/segment/log.rs file.
The role of the index is to provide pointers to records in the log file. Each entry of the index is 20 bytes long, 10 bytes are used for the offset address of the record in the log file, the other 10 bytes for the size of the record.
e.g.:
current cursor
^
|-------------------------------|
| offset-size | offset-size |...|----> time
|-------------------------------|
There is no separator, it's position-based.
e.g.:
00000001000000000020
---------------------
offset | size
* 000000010 -> offset
* 000000020 -> size
Neither reads nor writes to the index are directly triggering disk-level actions.
Both operations are being intermediated by a memory-mapping buffers, managed by the OS.
More info in the commit_log/src/segment/index.rs file.
These are preliminar and poorly collected results, yet it looks interesting:
Storage (Tests are completely offline, no network¹ ...)
- Setup 1:
OS: macOS Mojave 10.14.4 (18E226)
CPU: 2,5 GHz Intel Core i7
RAM: 16 GB 2133 MHz LPDDR3
HD: 256 GB SSD Storage
---------------
Segment size: 20 MB
Index size: 10 MB
5 GB worth records written in 37.667706s
5 GB worth cold records read in 1.384433s
5 GB worth warm records read in 1.266053s
Per-segment²:
-
~130 MB/s on write
-
~3.7 GB/s on cold read (while loading into memory pages)
-
~4.2 GB/s on warm read (already loaded into memory pages)
-
Setup 2:
OS: macOS Mojave 10.14.5 (18F203)
CPU: 2,9 GHz Intel Core i9
RAM: 32 GB 2400 MHz DDR4
HD: 500 GB SSD Storage
---------------
Segment size: 20 MB
Index size: 10 MB
5 GB worth records written in 26.851791s
5 GB worth cold records read in 141.969ms
5 GB worth warm records read in 124.623ms
Per-segment²:
-
~187 MB/s on write
-
~35 GB/s on cold read (while loading into memory pages)
-
~41 GB/s on warm read (already loaded into memory pages)
-
Setup 3:
OS: macOS Mojave 10.14.5 (18F203)
CPU: 2,9 GHz Intel Core i9
RAM: 32 GB 2400 MHz DDR4
HD: 500 GB SSD Storage
---------------
Segment size: 50 MB
Index size: 20 MB
10 GB worth records written in 54.96796s
10 GB worth cold records read in 437.933ms
10 GB worth warm records read in 310.853ms
Per-segment²:
- ~181 MB/s on write
- ~22 GB/s on cold read (while loading into memory pages)
- ~21 GB/s on warm read (already loaded into memory pages)
Notes:
- ¹ - Offline - no network overhead taken into account, network will be a big player on the overhead. However, the focus now is storage.
- ² - Per-segment performance, in a comparinson with kinesis/kafka that would be the per-shard value. If you were to have 10 shards, you could achieve 10x that, limited by external factors, HD/CPU/...
- Talks
- Blogposts
- Building a Distributed Log from Scratch, Part 1: Storage Mechanics
- Building a Distributed Log from Scratch, Part 2: Data Replication
- Building a Distributed Log from Scratch, Part 3: Scaling Message Delivery
- Building a Distributed Log from Scratch, Part 4: Trade-Offs and Lessons Learned
- Building a Distributed Log from Scratch, Part 5: Sketching a New System
- The Log: What every software engineer should know about real-time data's unifying abstraction
- How Kafka's Storage Internals Work
- Code
- travisjeffery/Jocko - Distributed commit log service in Go
- zowens/commitlog - Append-only commit log library for Rust
- liftbridge-io/liftbridge - Lightweight, fault-tolerant message streams