-
Notifications
You must be signed in to change notification settings - Fork 42
Commit
This commit does not belong to any branch on this repository, and may belong to a fork outside of the repository.
Merge pull request #11 from maxpert/nats
Moving to NATS instead of dragonboat due to it's inefficiencies.
- Loading branch information
Showing
13 changed files
with
299 additions
and
2,258 deletions.
There are no files selected for viewing
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| Original file line number | Diff line number | Diff line change |
|---|---|---|
|
|
@@ -5,36 +5,33 @@ A distributed SQLite replicator. | |
|
|
||
| ## What is it useful for right now? | ||
| If you are using SQLite as ephemeral storage, or a scenario where eventual consistency is fine for you. | ||
| Marmot can give you a solid replication between your nodes as Marmot builds on top of fault-tolerant | ||
| consensus protocol ([Multi-Raft](https://tikv.org/deep-dive/scalability/multi-raft/)), thus allowing | ||
| robust recovery and replication. This means if you are running a medium traffic website based on | ||
| SQLite you should be easily able to handle load without any problems. Read heavy workloads won't | ||
| be bottle-necked at all as Marmot serves as a side car letting you build replication cluster | ||
| without making any changes to your application code, and allows you to keep using to your | ||
| SQLite database file. In a typical setting your setup would look like this: | ||
| Marmot can give you a solid replication between your nodes as Marmot builds on top of fault-tolerant | ||
| [NATS](https://nats.io/), thus allowing robust recovery and replication. This means if you are | ||
| running a medium traffic website based on SQLite you should be easily able to handle load | ||
| without any problems. Read heavy workloads won't be bottle-necked at all as Marmot serves | ||
| as a side car letting you build replication cluster without making any changes to your | ||
| application code, and allows you to keep using to your SQLite database file. | ||
|
|
||
| 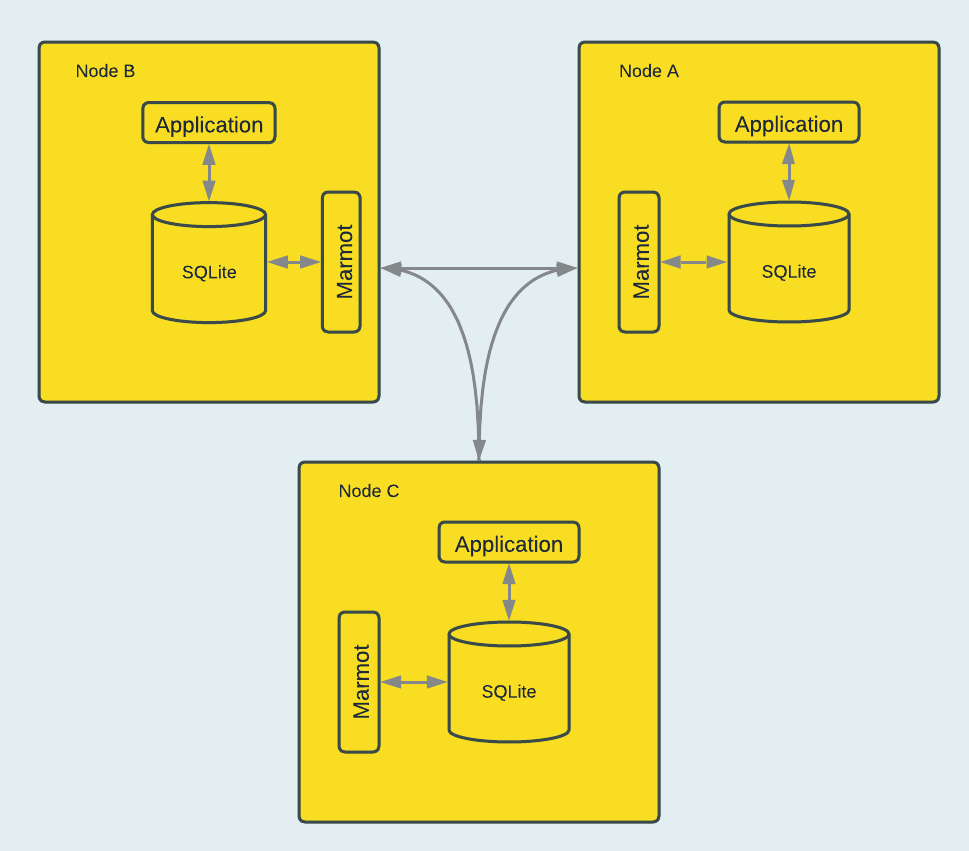 | ||
| ## Dependencies | ||
| Starting 0.4+ Marmot depends on [nats-server](https://nats.io/download/). | ||
|
|
||
| ## Production status | ||
|
|
||
| **MARMOT IS IN RELEASE CANDIDATE STAGES, WHICH MEANS MOST OF ISSUES HAVE BEEN IRONED OUT, HOWEVER THERE MIGHT BE EDGE CASE RACE CONDITIONS THAT MIGHT CAUSE PROBLEMS. FOR NOW WE RECOMMEND USAGE FOR EPHEMERAL STORAGE USE CASE ONLY WHERE LOOSING DATA, OR CORRUPTION OF DB FILE IS NOT AN ISSUE.** | ||
| **MARMOT IS NOT READY FOR PRODUCTION USAGE** | ||
|
|
||
| Right now it's being used for ephemeral cache storage in production services, on a very read heavy site. This easily replicates cache values across | ||
| the cluster, keeping a fast local copy of cache database. | ||
| Right now it's being used for ephemeral cache storage in production services, on a very read heavy site. | ||
| This easily replicates cache values across the cluster, keeping a fast local copy of cache database. | ||
|
|
||
| ## Features | ||
|
|
||
| - MultiRaft based consensus with ability to manually move a cluster around | ||
| - Built on top of NATS, abstracting stream distribution and replication | ||
| - Bidirectional replication with almost masterless architecture | ||
| - Ability to snapshot and fully recover from those snapshots | ||
| - SQLite based log storage | ||
|
|
||
| To be implemented for next GA: | ||
| - Command batching + compression for speeding up bulk load / commit commands to propagate quickly | ||
| - On the fly join and cluster rebalancing | ||
| - Per node database level command ordering | ||
| - Gossip and SRV based node discovery | ||
| - CDC output to NATS and log file | ||
|
|
||
| ## Running | ||
|
|
||
|
|
@@ -46,45 +43,35 @@ go build -o build/marmot ./marmot.go | |
| Make sure you have 2 SQLite DBs with exact same schemas (ideally exact same state): | ||
|
|
||
| ```shell | ||
| rm -rf /tmp/raft # Clear out previous raft state, only do for cold start | ||
| build/marmot -bootstrap [email protected]:8162 -bind 127.0.0.1:8161 -bind-pane localhost:6001 -node-id 1 -db-path /tmp/cache-1.db | ||
| build/marmot -bootstrap [email protected]:8161 -bind 127.0.0.1:8162 -bind-pane localhost:6002 -node-id 2 -db-path /tmp/cache-2.db | ||
| nats-server --jetstream | ||
| build/marmot -nats-url nats://127.0.0.1:4222 -node-id 1 -db-path /tmp/cache-1.db | ||
| build/marmot -nats-url nats://127.0.0.1:4222 -node-id 2 -db-path /tmp/cache-2.db | ||
| ``` | ||
|
|
||
| ## Demos | ||
| Demos for `v0.4.x`: | ||
| - Scaling Pocketbase with Marmot [Coming soon] | ||
|
|
||
| Demos for `v0.3.x` (Legacy) with PocketBase `v0.7.5`: | ||
| - [Scaling Pocketbase with Marmot](https://youtube.com/video/VSa-VJso050) | ||
| - [Scaling Pocketbase with Marmot - Follow up](https://www.youtube.com/watch?v=Zapupe_FREc) | ||
|
|
||
| ## Documentation | ||
|
|
||
| Marmot is picks simplicity, and lesser knobs to configure by choice. Here are command line options you can use to | ||
| Marmot picks simplicity, and lesser knobs to configure by choice. Here are command line options you can use to | ||
| configure marmot: | ||
|
|
||
| - `cleanup` - Just cleanup and exit marmot. Useful for scenarios where you are performing a cleanup of hooks and | ||
| change logs. (default: `false`) | ||
| - `db-path` - Path to DB from which given tables will be replicated. These tables can be specified in `replicate` | ||
| option. (default: `/tmp/marmot.db`) | ||
| - `replicate` - A comma seperated list of tables to replicate with no spaces in between (e.g. news,history) | ||
| (default: [empty]) **DEPRECATED after 0.3.11 now all tables are parsed and listed, this is required for | ||
| snapshots to recover quickly** | ||
| - `db-path` - Path to DB from which all tables will be replicated (default: `/tmp/marmot.db`) | ||
| - `node-id` - An ID number (positive integer) to represent an ID for this node, this is required to be a unique | ||
| number per node, and used for consensus protocol. (default: 0) | ||
| - `bind` - A `host:port` combination of listen for other nodes on (default: `0.0.0.0:8610`) | ||
| - `raft-path` - Path of directory to save consensus related logs, states, and snapshots (default: `/tmp/raft`) | ||
| - `log-replicas` - Number of copies to be committed for single change log. By default it set to `floor(shards/2) + 1`. | ||
| - `shards` - Number of shards over which the database tables replication will be distributed on. It serves as mechanism for | ||
| consistently hashing leader from Hash(<table_name> + <primary/composite_key>) for all the nodes. These partitions can | ||
| be assigned to various nodes in cluster which allows you to distribute leadership load over multiple nodes rather | ||
| than single master. By default, there are 16 shards which means you should be easily able to have upto 16 leader | ||
| nodes. Beyond that you should use this flag to create a bigger cluster. Higher shards also mean more disk space, | ||
| and memory usage per node. Marmot has basic a very rough version of adding shards, via control pane, but it | ||
| needs more polishing to make it idiot-proof. | ||
| - `bootstrap` - A comma seperated list of initial bootstrap nodes `<node_id>@<ip>:<port>` (e.g. | ||
| `[email protected]:8162,[email protected]:8163` will specify 2 bootstrap nodes for cluster). | ||
| - `bind-pane` - A `host:port` combination for control panel address (default: `localhost:6010`). All the endpoints | ||
| are basic auth protected which should be set via `AUTH_KEY` env variable (e.g. `AUTH_KEY='Basic ...'`). This | ||
| address should not be a public accessible, and should be only used for cluster management. This in future | ||
| will serve as full control panel hosting and cluster management API. **EXPERIMENTAL** | ||
| consistently hashing JetStream from `Hash(<table_name> + <primary/composite_key>)`. This will allow NATS servers to | ||
| distribute load and scale for wider clusters. Look at internal docs on how these JetStreams and subjects are named. | ||
| - `nats-url` - URL string for NATS servers, it can also point to multipule servers as long as its comma separated (e.g. | ||
| `nats://user:[email protected]:4222` or `nats://user:pass@host-a:4222, nats://user:pass@host-b:4222`) | ||
| - `verbose` - Specify if system should dump debug logs on console as well. Only use this for debugging. | ||
|
|
||
| For more details and internal workings of marmot [go to these docs](https://github.com/maxpert/marmot/blob/master/docs/overview.md). | ||
|
|
@@ -94,8 +81,8 @@ Right now there are a few limitations on current solution: | |
| - You can't watch tables selectively on a DB. This is due to various limitations around snapshot and restore mechanism. | ||
| - WAL mode required - since your DB is going to be processed by multiple process the only way to have multi-process | ||
| changes reliably is via WAL. | ||
| - Downloading snapshots of database is still WIP. However, if you can have start off node with same copies of DB it will | ||
| work flawlessly. | ||
| - Downloading snapshots of database is still WIP. However, it doesn't affect replication functionality as everything | ||
| is upsert or delete. Right snapshots are not restore, or initialized. | ||
| - Marmot is eventually consistent. This simply means rows can get synced out of order, and `SERIALIZABLE` assumptions | ||
| on transactions might not hold true anymore. | ||
|
|
||
|
|
||
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
Oops, something went wrong.