{kind=link}
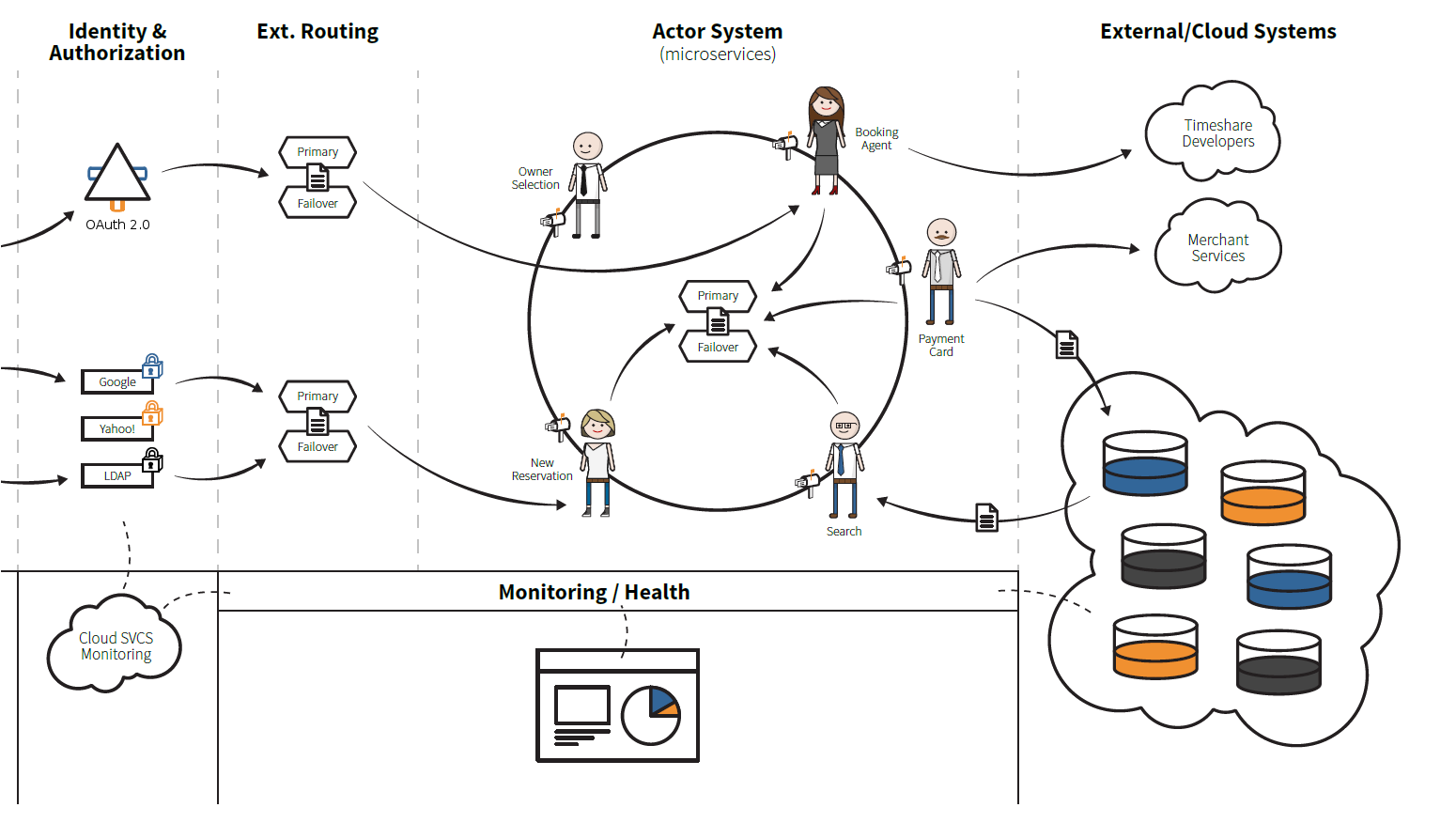
If you have interest in Scala / Akka and how to create a non-stop (“always available”) microservices platform using Akka's clustering capability then please read on. Some knowledge of Akka's actor system is assumed. Throughout this post the terms microservices and actors are used interchangeably.
First, a little background. When we first started architecting ResortShare's new reservation platform in March 2015, I was sure of two things: the traditional Java monolithic application wasn't going to give us the flexibility we needed, and that a document-based database would provide a much better solution than a traditional relational SQL database. This post is about the former and doing away with the Java monolith by adopting a microservices based architecture.
The microservices capabilities that we most wanted to leverage are the potential for non-stop operation, and an enhanced continuous delivery model.
There are many businesses that can either benefit or require non-stop computer systems and applications. The short list includes financial, banking, and retail. In our case at ResortShare it was highly desirable to be constantly available for processing reservations both internally and externally. On the external side, we needed to accept new reservations and modifications made through on-line travel agencies in real-time.
Continuous delivery is where software is developed in short cycles. It aims to build, test, and release features faster and more frequently. The concept of microservices lends themselves toward this model of development due to their focus on business function and their small footprint.
Additionally, we wanted the capability to run any number of microservice versions in the production environment at one time. We also wanted to build new microservices and immediately push them to production. These new microservices would be enabled for user acceptance testing / quality assurance through configuration but not available to current production users. Once user acceptance testing is completed these new versions could simply be turned on. This approach would ultimately remove the need for a majority of the development environment as well as the complete obsolescence of a staging environment, thus saving valuable resources and money.
Akka is one fantastic message driven platform and has variety message routers that are used primarily for load balancing. However, there are no routers out of the box that can be configured for content based message routing. The good news is that Akka provides APIs that allow for the construction of custom routing logic.
To be honest, I've never been a big fan of content-based routing due to the additional overhead of inspecting the content and trying to make a decision on where to send it. My adage has always been stupid pipes are much faster than smart pipes. That said, I've changed my mind and now think that content-based message routing is the perfect use case to enable non-stop microservice operation and an enhanced continuous deliver model for the Akka platform.
Our approach is to use a JSON message wrapper containing the following data: target actor, user name, user's security groups and, finally, the message payload itself. The “target actor” is simply a path used to identify the desired destination or class of actors. The “user name” is provided, if needed, for auditing, etc. Users are either people logged into a UI or a system process. The combination of target actor / user's security groups are used to build a key by the routing logic to determine the actual actor that is to receive the message. The concept here is that actors within the given target are selected by the user's credentials. For example, a user that is part of the “QA” group would have their requests routed to an upcoming version of the target actor, whereas normal users would have their requests routed to the current production version. In other words, old and new versions of any actor can be used in parallel. If an undetected defect is encountered after turning on an actor for production, you can simply modify the router's configuration and put the old version back in play.
Resiliency was also given consideration so all content-based routers are deployed in pairs where one is a primary router and the second is a fail-over router. During testing, they can be created in the same JVM but in production, they're deployed in separate JVMs on different virtual Linux servers with separate configurations. If a primary router encounters an exception that is not an extension of IllegalStateException, then the message is automatically routed through the fail-over router. It's our standard to throw an extended IllegalStateException when programming or when configuration errors are encountered. Thus, if exception is encountered that's outside this category, the assumption is something has gone awry with the primary router and then the fail-over router can be used.
I've created a relatively simple proof of concept project to accompany this post that is open source and available at Github (You are reading it here.) This project provides unit tests for parsing JSON configuration files that use the Play library as well as integration tests with Akka's cluster, and a custom content based router. Finally, a sample cluster application is provided to illustrate how to use the router, associated client traits, and how to introduce new actors to a running cluster.
This content-based router logic (com.mread.routers.ConfigurableRouterLogic) performs two distinct functions. The first being the configuration rules parser / loader. The second provides the physical message routing logic based upon the configuration rules and the target actor / user security groups of each message.
The configuration rules parser / loader is run when the router is first created and also when a change is detected in the configuration file. If there are no errors detected in the configuration, and all the referenced actors can be found in the cluster, only then are the new rules activated in the routing logic. An Akka timer is created to check, once a minute, for changes in the configuration file's signature. If a change is detected, and errors exist, the existing rules are kept in place and router operations continue as before.
Akka's resolveOne method which is used to resolve an actor via the actor's path (nodePath), returns a Future[ActorRef]. Akka's select method which is used to route messages, requires a concrete actor reference (non-Future). Since these two APIs are in conflict, the actor references need to be resolved while loading the configuration instead of using a traditionally lazy pattern. Additionally, we don't want to use a potential configuration that has errors.
I always tell new Scala developers that they need to learn how to break up long linear solutions into blocks of small solutions that can be run in parallel whenever possible. This is a perfect example of using Scala's Future to do things in parallel by resolving the required actors all at once. I don't know if you can say that the following method “contains syntactic sugar” but it does contain sugar nonetheless.
/**
* INTERNAL API.
*
* Find all ActorRefs associated with a specific "target" destination (actor identifier)
*/
private def findRoutees(routes: Map[String, List[ActorRouteRef]]) : Future[Boolean] = {
implicit val timeout = Timeout(5 seconds)
val futures : MutableList[Future[Object]] = MutableList.empty
val keys = routes.keys
keys foreach { key =>
val actorRoutes = routes get key
actorRoutes match {
case Some(actors) =>
actors foreach { actorRouteRef =>
actorRouteRef.actorRoute.nodePath match {
case Some(nodePath) =>
val f = context.actorSelection(nodePath).resolveOne()
f onSuccess {
case ref =>
actorRouteRef.synchronized {
actorRouteRef.routee = Some(ActorRefRoutee(ref))
}
log.info("findRoutees found specified actor for:" + nodePath)
}
f onFailure {
case ex: Exception =>
log.error(ex, "findRoutees couldn't find specified actor for:" + nodePath)
}
futures += f
case None => // this shouldn't happen as error should have been detected during parsing
log.error("nodePath not specified for key:" + key + "actor name:" + actorRouteRef.actorRoute.actorName)
}
}
case None => // do nothing
}
}
// wrap futures with Try
val listOfFutureTrys = futures.map(futureToFutureTry(_))
// use Future.sequence, to give you a Future[List[Try[T]]]
val futureListOfTrys = Future.sequence(listOfFutureTrys)
//Then filter:
//val futureListOfSuccesses = futureListOfTrys.map(_.filter(_.isSuccess))
//identify the specific failures:
val futureListOfFailures = futureListOfTrys.map(_.filter(_.isFailure))
futureListOfFailures.map[Boolean] { failures =>
failures.size == 0
}
}The findRoutees method takes a map of routes and returns a successful Future[Boolean] if all actor nodePaths were found. This is done by looping though all the configured routes using the resolveOne method to find the ActorRef for each route then holds all the Futures in a mutable list of Future[Object]. It then wraps these Futures into a List of Future[Try] and finally filters out any failures to return the Future[Boolean].
If you run the sample application (below) on a multi-core computer, note the tight time gaps between the resolutions in the console.
The content-based message router is actually an actor that routes messages received through its inbox through a ConfigurableRouterLogic object, which uses an in-memory cache to speed the transition of future messages that match the key generated from the target actor / user security group combination.
Primary and fail-over routers are configured in a node's configuration file. The following is extracted from application.conf:
mread {
clusterRouter {
configFile = "src/main/resources/Routes.json"
cacheSize = 100
}
actorRouter {
primary = "akka.tcp://[email protected]:2551/user/clusterRouter"
failover = "akka.tcp://[email protected]:2552/user/clusterRouter"
}
}
The Routes.json file provides the rules for the routing logic and looks like this:
{
"version": "1",
"notes": "nodePath can be relative or absolute",
"paths": [
{
"path": "/saveOrder",
"routes": [
{
"actorName": "saveOrder",
"version": "1",
"groups": ["orders"],
"nodePath": "/user/saveOrder"
},
{
"actorName": "saveOrder1",
"version": "1.1",
"groups": ["orders","qa"],
"nodePath": "/user/saveOrder1"
}
]
},
{
"path": "/modifyOrder",
"routes": [
{
"actorName": "modifyOrder",
"version": "1",
"groups": ["orders"],
"nodePath": "/user/modifyOrder"
},
{
"actorName": "modifyOrder1",
"version": "1.1",
"groups": ["orders","qa"],
"nodePath": "/user/modifyOrder1"
}
]
},
{
"path": "/deleteOrder",
"routes": [
{
"actorName": "deleteOrder",
"version": "1",
"groups": ["orders"],
"nodePath": "/user/deleteOrder"
},
{
"actorName": "deleteOrder1",
"version": "1.1",
"groups": ["orders","qa"],
"nodePath": "/user/deleteOrder1"
}
]
}
]
}The JSON configuration file is structured as follows. The root node contains version, notes, and paths. For each unique (target actor) path any number of routes can exist, where each route represents a destination actor, that must be unique by name, and unique by security groups. If only one route exists within a given path it's determined to be the default route for the given path. The nodePath identifies the desired actor within the cluster. If the nodePath doesn't contain a fully qualified path, then the path is relative to the router's node.
Before continuing you'll need to have Scala (2.11.7) and SBT installed. The following tests are run from within SBT, usually within a development environment such as Eclipse, or from a terminal window.
To test the configuration parser:
> testOnly com.mread.test.json.TestRoutes
To test the RoutingLogic:
> testOnly com.mread.test.router.RoutingLogic
To test both at once:
> test
The sample application is a small cluster with two seed nodes. The first node contains a message generator actor that randomly picks a target and security group, then logs, and finally sends a message through the primary router using the “Ask” pattern. When the receiving actor responds to the original message, the response is also logged. The first and second nodes contain copies of the actors that can respond to the message generator. Note that it's the nodes responsibility to create the routers and the supporting actors.
To run the sample application from SBT:
> run
Once the cluster starts up, the message generator starts sending messages every 10 seconds. If you want, you can make modifications to the Routes.json file while the application is running. As long as there are no parsing errors and all referenced actors can be found, the new rules take effect within a minute.
Say you want to move production from “saveOrder” to “saveOrder1,” and also introduce a new actor called “saveOrder2” for “QA” testing all at the same time. This can be accomplished by adding a new node to the cluster, and then modifying the Routes.json file.
To add the new node to the cluster from SBT:
- First open a new terminal window, and move to the directory containing the project.
- Start a new version of SBT, and then issue the command:
- > run 2053
- Next modify Routes.json by replacing the “routes” for the target /saveOrder with the following:
"routes": [
{
"actorName": "saveOrder",
"version": "1",
"groups": ["orders","deprecated"],
"nodePath": "/user/saveOrder"
},
{
"actorName": "saveOrder1",
"version": "1.1",
"groups": ["orders"],
"nodePath": "/user/saveOrder1"
},
{
"actorName": "saveOrder2",
"version": "1.2",
"groups": ["orders","qa"],
"nodePath": "akka.tcp://[email protected]:2553/user/saveOrder2"
}
]The changes are as follows. First, “deprecated” was added to the “groups” of the first actor route “saveOrder”. Next, the “qa” group was removed from the “saveOrder1” actor route, and finally a new route was created for “saveOrder2”, that contains the groups [“orders”, “qa”]. Once the configuration file is saved and loaded by the routers, you should start to see messages going to the “saveOrder2” actor in the new node.
In our sample application we've created a trait to implement the “Ask” and “Tell” patterns that automatically routes messages through the primary router, with a fail-over router when an exception is encountered that's not an extension of an IllegalStateException.
By taking a look at the MsgGenerator actor we can see the usage of our RouteTrait.routeAskMessage example:
import com.mread.actor.traits.RouteTrait
...
class MsgGenerator extends Actor with ActorLogging with RouteTrait {
// abstract fields inherited from RouteTrait
override lazy val primaryRouter = getConfigOpt("mread.actorRouter.primary")
override lazy val failOverRouter = getConfigOpt("mread.actorRouter.failover")
...
routeAskMessage(msg).map { rMsg =>
log.info("MsgGenerator received a response:" + rMsg)
}
}Usage for the “Tell” is simply:
routeTellMessage(msg)Because the primary and fail-over routers are defined as abstract fields in RouteTrait, you'll need to provide an override for each of these fields in your actor class. The helper function getConfigOpt is used to return the configured options as Option[String] from application.conf.
As we've seen from our sample application, we can facilitate a non-stop environment by using a content-based router in an Akka cluster. In our examples thus far, we've been using SBT in a development environment. Moving to production, you'll be building and deploying the individual Akka nodes using something like Jenkins, and starting them using either Akka's Command Line Management or potentially ConductR.
I know a lot of people like Docker production deployments but for me, I'm not totally sold on using it for production as it's just another container as is the JVM. Personally, I think Docker's best use case in combination with a JVM is for developing and emulating potential complex production environments.
There are certainly no limits on how many router pairs (primary / fail-over) you can create for production. I like the idea of using one pair to provide a production endpoint for web services, another for “QA” endpoints, and one or more pairs for the internal middle tier. This allows you to simplify router configuration files and focus on business functionality. Other considerations may be to use load balancing routers before the content base router, and / or on the back end as the actors configured for the router. Another option is to do away with the fail-over pairs and “just let it fail.” There really is no limit to the way you can set up an Akka cluster with content based routing.
My preference is to place all content-based routers, logging, monitoring, and any other infrastructure related actors (ones that are not likely to change) into seed nodes, and then place application specific actors into their own nodes. Later in the future, when all actors of a particular node have been deprecated and are no longer used for a time, then those nodes can be shut down and removed from the cluster.
In this post I've show how an organization can create a non-stop (“always available”) microservices platform using the very powerful Akka actor system's clustering capabilities along with content-based routing. We've also taken a brief look at how an enhanced constant delivery model might work within this environment. The idea of doing away with the “staging” environment was also introduced thus saving valuable resources and money.
The sample content based routing logic is somewhat rudimentary but it's still very capable in its flexibility to run multiple versions of any given microservice / actor at one time. Future enhancements might include automatic resolution of actors through cluster listeners, and automatic actor life cycle management.
It's my sincere hope that these concepts prove useful to you. I also hope that you find the joy and appreciation that I've found with Scala. I just can't bring myself to go back to programming in Java.
I appreciate and welcome any feedback you might have.
Thank you for taking the time out of your busy day to read my post.
Michael Read [email protected] is a highly accomplished and effective leader, cutting-edge technologist, senior software architect, and developer. Michael joined the Lightbend, Inc. team as Senior Consultant in Nov, 2017. Throughout Michael's career he has successfully recruited, managed, and led numerous software development teams. Today, Michael is most passionate about building highly scalable, cutting-edge, reactive applications using a distributed microservice based architecture. His preferred tools are Scala, Akka, Akka Streams, Play, Elasticsearch, Spark, and Kafka.
His LinkedIn profile can be viewed here → https://www.linkedin.com/in/michael-read-45a0262