Release Note Example

 |
 |
 |
 |
|---|---|---|---|
| Vowpal Wabbit on Spark | Quality and Build Refactor | LightGBM Ranking and More | Anomaly Detection and Speech To Text |
| Fast, Sparse, and Scalable Text Analytics | New Azure Pipelines build with Code Coverage, CICD, and an organized package structure. | Barrier Execution mode, performance improvements, increased parameter coverage | New cognitive services on Spark |
- For full documentation check out the VW on Spark Docs
- Added
VowpalWabbitClassifierandVowpalWabbitRegressor - Added Vowpal Wabbit - Quantile Regression for Drug Discovery.ipynb
- Now supports barrier execution mode
- Added the
LightGBMRanker - Added
is_provide_training_metricto LightGBMRanker. - Enabled continued training with init score column
- Added batch training support
- Reduced memory usage
- Fixed issues with frozen jobs
- Fixes for multiclass classification
- Added
AnomalyDetectorandSimpleAnomalyDetectorAPIs - Added
SpeechToTexttransformer - Improved service concurrency
- Added robustness to socket timeouts
- Codegen support for wrapping
Rankerclasses - Notebooks now leverage public blob for faster execution
- Fixed summarize data column handling
- Better compute model statistics error messages
- Upgraded to Spark 2.4.3
- Added Spark on Kubernetes Helm Charts
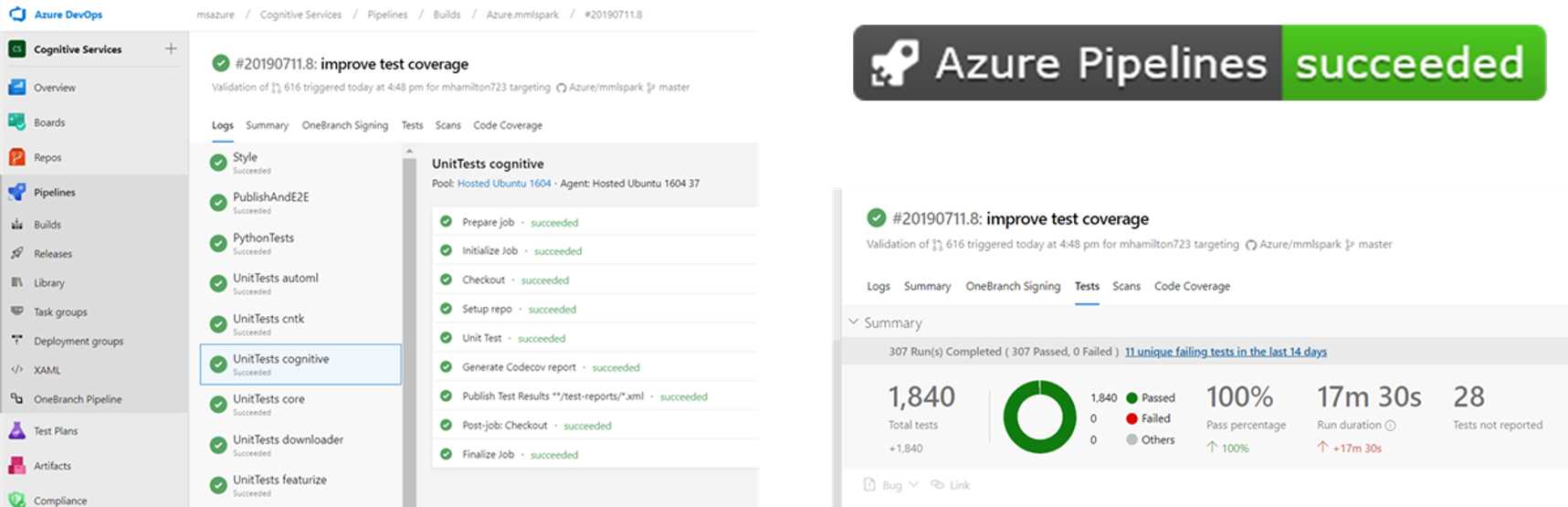
- Tests parallelized on Azure Pipelines. Builds now take ~25min vs ~90min!
- Serverless Builds: Queue as many builds as needed with no machine maintenance costs
- Test results, error messages, and time are viewable from github PR section
- Individual Tests can be re-queued from the GitHub PR Page
- Builds can be queued using the pull request comment:
/azp run.- Full details can be seen by typing
/azp help
- Full details can be seen by typing
- CI pipeline entirely specified in small .yaml file in git repo
- Dramatically simpler developer setup (all through SBT)
- Local developer setup now works on any platform including windows!
- Local setup no longer needs VM, Vagrant, or 30 min to import the library
- All build stages are SBT tasks and can be done locally for rapid testing
- This includes publishing maven packages to local repositories and the MMLSpark maven repo
- All secrets now managed by centralized Azure Key Vault
- IntelliJ will pick up on all scalastyle rules for editor-level style feedback while typing
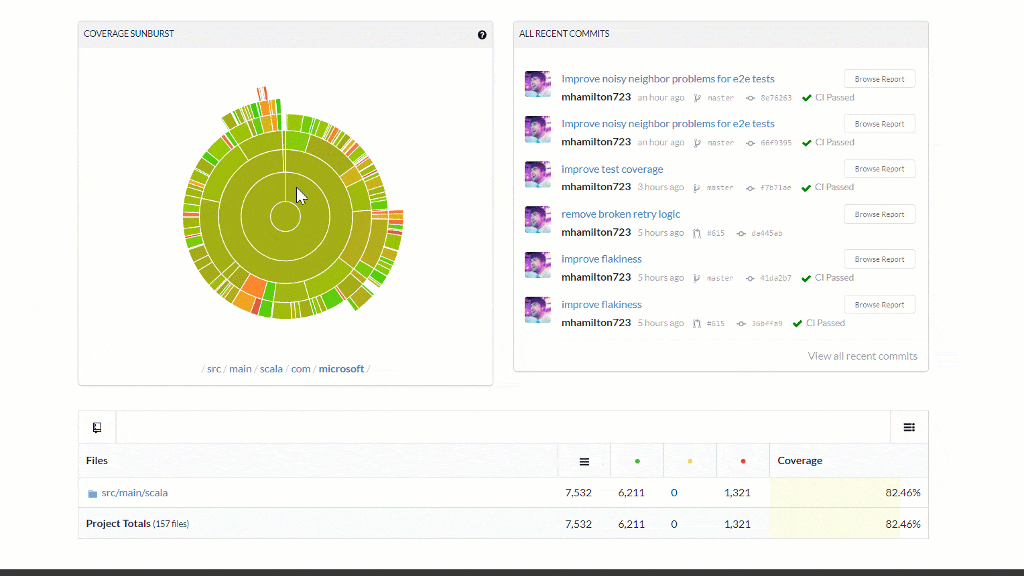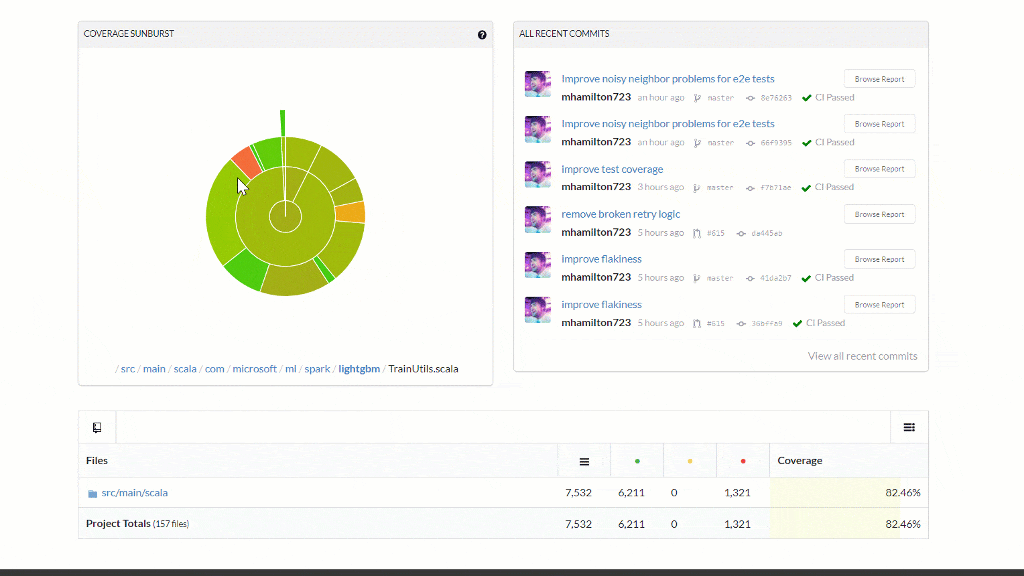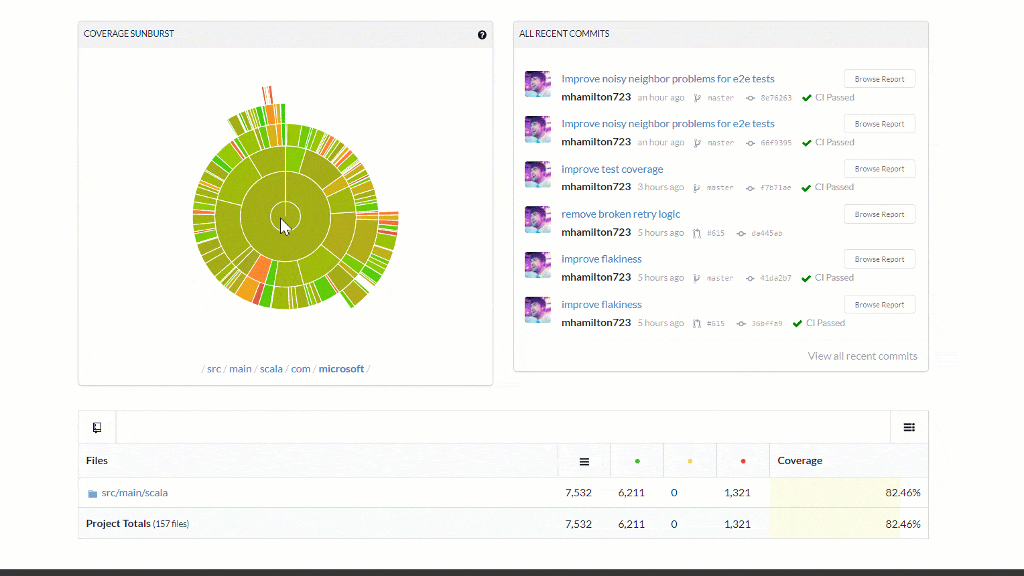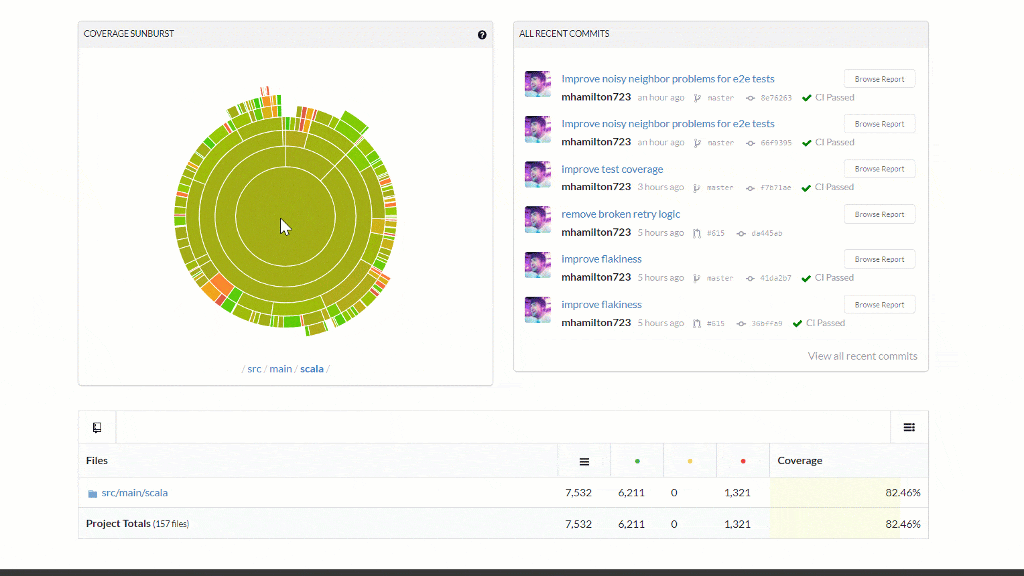
- Code Coverage now supported for every PR and reported in the comments and badge
- Coverage is now a check-in gate to never decrease
- Test coverage increased and dead code removed from the library
- Custom and auto-generated Python tests now supported
- CODEOWNERS file for better code reviews and maintenance
- Codacy integration for automated PR reviews
- MMLSpark now supports a true Scala/Java idiomatic package hierarchy
- Namespace hierarchy also reflected in PySpark code
- Note: This will require changes to existing MMLSpark Programs. For Support in migrating please contact
[email protected]
- Issue and PR templates
- Gitter channel
- Welcome bot to greet new contributors
- Semantic Commits for autogenerating release notes
- Badges to display current and master versions in the README
- For those that already have MMLSpark developer setups please read the new developer guide to reconfigure.
- For those that have standing PRs that need rebasing assistance please reach out to
[email protected] - Please report any bugs or feedback!
We would like to acknowledge the developers and contributors, both internal and external who helped create this version of MMLSpark.
- Ilya Matiach, Markus Cozowicz, Scott Graham, Daniel Ciborowski, Christina Lee, Dalitso Banda, Shaochen Shi, Sudarshan Raghunathan, Anand Raman, Eli Barzilay, Nick Gonsalves, Tao Wu, Jeremy Reynolds, Miguel Fierro, Robert Alexander, AI CAT Team, Azure Search Team
 |
|---|