Project นี้เป็นส่วนหนึ่งของรายวิชา CPE 378 การเรียนรู้ของเครื่อง (Machine Learning) สาขาวิชาวิทยาศาสตร์ข้อมูลสุขภาพ มหาวิทยาลัยเทคโนโลยีพระจอมเกล้าธนบุรี ภาคเรียนที่ 2 ปีการศึกษา 2564
โรคหัวใจและหลอดเลือด (cardiovascular disease, CVD) เป็นกลุ่มโรคที่เกิดจากความผิดปกติ ของหัวใจหรือหลอดเลือด ได้แก่ โรคหลอดเลือดหัวใจ (coronary heart disease) โรคหลอดเลือดสมอง (cerebrovascular disease) โรคเส้นเลือดแดงส่วนปลายอุดตัน (peripheral artery disease) ภาวะ หลอดเลือดดำ อุดตัน (deep vein thrombosis) และภาวะลิ่มเลือดอุดตันในปอด (pulmonary embolism) เป็นต้น ปัจจัยเสี่ยงหลักที่สำ คัญของโรคหัวใจและหลอดเลือด เกิดจากพฤติกรรมการใช้ชีวิตประจำวันที่ไม่ถูกต้อง ได้แก่ การรับประทานอาหารที่มีรสเค็มจัด หรืออาหารไขมันสูง การไม่ออกกำ ลังกาย การสูบบุหรี่ และการดื่มแอลกอฮอล์ ปัจจัยเสี่ยงดังกล่าวจะนำ ไปสู่ภาวะความดันโลหิตสูง ระดับน้ำ ตาลในเลือดสูง ระดับไขมัน ในเลือดสูง ภาวะน้ำ หนักเกินหรือโรคอ้วน และเกิดโรคหัวใจและหลอดเลือดในที่สุด โรคหัวใจและหลอดเลือด เป็นโรคที่พบมากในผู้สูงอายุ (1)
จากการรายงานสถิติขององค์การอนามัยโลก (WHO) ในปี 2563 พบว่า โรคหัวใจและหลอดเลือด (cardiovascular diseases) คือกลุ่มโรคที่เป็นสาเหตุการตายอันดับ 1 ของคนทั่วโลก โดยมีผู้เสียชีวิตจาก กลุ่มโรคนี้ประมาณ 17.9 ล้านคน และสำหรับสถิติข้อมูลการเสียชีวิตของคนไทย ในกลุ่มโรคหัวใจและหลอดเลือด พบว่า ร้อยละ 80 เสียชีวิตด้วยกล้ามเนื้อหัวใจขาดเลือดเฉียบพลัน อีกทั้งข้อมูลจากกรมการแพทย์ ปี 2557 พบว่า ประเทศไทยมีค่าใช้จ่ายในการรักษาพยาบาลเฉลี่ยของผู้ป่วยโรคหัวใจถึง 6,906 ล้านบาทต่อปี และมีแนวโน้มการป่วยเพิ่มขึ้นอย่างต่อเนื่อง ซึ่งส่งผลกระทบต่อคุณภาพชีวิตของประชาชน เกิดความสูญเสียทางเศรษฐกิจจากการเสียชีวิตก่อนวัยอันควร ทั้งในระดับบุคคล ครอบครัว สังคม และประเทศชาติ (2)
จากสถิติที่กล่าวว่าโรคโรคหัวใจและหลอดเลือดเป็นสาเหตุสำคัญในการเสียชิวิตของประชากรส่วนใหญ่ซึ่งวิธีในการช่วยเพิ่มโอกาสในการรักษา และเพิ่มอัตราการรอดชีวิตสามารถทำได้หากวิฉัยโรคโรคได้เร็ว การทำเทคโนโลยีทางคอมพิวเตอร์อย่างการเรียนรู้ของเครื่องเข้ามาช่วยในการวินิจฉัยจึงเป็นหนึ่งในทางเลือกที่เหมาะสม
ดังนั้นในการทำ Project ในครั้งนี้ คณะผู้จัดทำจึงเลือกอัลกอริทึม 3 แบบ คือ Logistic Regression Classifier, Random Forest Classifier, และ eXtreme Gradient Boosting (XGBoost) นำมาใช้ในการสร้างแบบจำลองทำนายความเสี่ยงโรคหลอดเลือดหัวใจจากชุดข้อมูล Cardiovascular Disease
- เพื่อเปรียบเทียบความถูกต้องของอัลกอริทึมทั้ง 3 แบบ ได้แก่ Logistic Regression Classifier, Random Forest Classifier, และ eXtreme Gradient Boosting (XGBoost)
- เพื่อหาอัลกอริทึมที่สามารถสร้างแบบจำลองในการทำนายความเสี่ยงโรคได้ถูกต้องที่สุด
-
Ensemble Method
- เป็นวิธีการปรับปรุงแบบจำ ลองเดิมให้สามารถรับมือกับปัญหาที่มีความซับซ้อนมากขึ้นได้ ซึ่งเป็นการรวบรวมหลายแบบจำ ลองด้วยวิธีต่าง ๆ เพื่อให้ได้แบบจำลองสุดท้ายที่มีประสิทธิภาพ และแม่นยำมากขึ้น Ensemble ใน Machine Learning ที่มักใช้กันบ่อยมี 2 วิธี ได้แก่
- Bagging (ย่อมาจาก Bootstrap Aggregation) ซึ่งเป็นพื้นฐานของ Random Forest Classifier ใน scikit-learn library
- Boosting ซึ่งเป็นพื้นฐานของ AdaBoost หรือ Gradient Boosting ในไลบรารี่เช่น XGBoost และ LightGBM
- เป็นวิธีการปรับปรุงแบบจำ ลองเดิมให้สามารถรับมือกับปัญหาที่มีความซับซ้อนมากขึ้นได้ ซึ่งเป็นการรวบรวมหลายแบบจำ ลองด้วยวิธีต่าง ๆ เพื่อให้ได้แบบจำลองสุดท้ายที่มีประสิทธิภาพ และแม่นยำมากขึ้น Ensemble ใน Machine Learning ที่มักใช้กันบ่อยมี 2 วิธี ได้แก่
-
GridSearchCV (3)
- เป็นไลบรารี่ sklearn สำหรับการปรับพารามิเตอร์ในโมเดล GridSearchCV เป็นอัลกอริทึมประเภท Exhaustive search
- ใช้ค้นหาพารามิเตอร์ที่เหมาะสมสำหรับโมเดลตามค่าของพารามิเตอร์ที่กำหนดใน parameter grid
- Parameter grid เป็นตัวแปรที่ประเภท dictionary เก็บค่า parameter เป็น key เก็บ list ค่าพารามิเตอร์ เป็น value ผู้ใช้จำ เป็นจะต้องมีการกำหนดค่าของพารามิเตอร์ที่สนใจเป็น list โดยพารามิเตอร์จะถูกเพิ่มประสิทธิภาพด้วยการทำ cross-validated grid-search เพื่อลดความจำเพาะต่อชุดข้อมูลที่ใช้ฝึกโมเดล

ดังนั้นจึงเลือกอัลกอริทึม 3 แบบ คือ
- Logistic Regression เป็น classifier algorithm เป็นเทคนิคการวิเคราะห์สถิติเชิงคุณภาพ นิยมใช้มากในการวิจัยทางด้านการแพทย์และสาธารณสุข (4) เป็นเทคนิคการวิเคราะห์ความสัมพันธ์ของตัวแปรที่มี เป้าหมายการวิเคราะห์คือ ทำนายหรือคาดการณ์โอกาสของการเกิดขึ้น และไม่เกิดขึ้นที่เป็นไปได้ของข้อมูลที่สนใจ (5)
- Random Forest เป็น Ensemble model ประเภทหนึ่งที่มีพื้นฐานมาจากต้นไม้ตัดสินใจ (Decision tree) ซึ่งเป็นแบบจำลองที่อ้างอิงตามกฎ (Rule-based) ที่จะสร้างกฎ If-else condition โดยจำลองว่าถ้าเกิดเหตุการณ์ A แล้วผลลัพธ์จะเป็นอย่างไร และหากไม่เกิดเหตุการณ์ A จะได้ผลลัพธ์อย่างไร
- eXtreme Gradient Boosting (XGBoost) แบบจำลองที่ถูกพัฒนาขึ้นมาต่อจาก Gradient boosting เพื่อเพิ่มความแม่นยำและความยืดหยุ่นให้กับแบบจำลอง โดยใช้หลักการของ Ensemble Learning Method โดยพัฒนาขึ้นเพื่อให้ทำงานได้เร็วยิ่งขึ้นกว่าเดิมในการค้นหาตัวแปรที่จะส่งผลต่อแบบจำลองมากที่สุดแทนการใช้ทุก ๆ ตัวแปรแบบ gradient boosting ดั้งเดิม ในการ Boosting เพื่อสร้างตัวเรียนรู้หลายๆตัว (Multiple Learner) (6) หรือเรียกได้ว่าเป็นการรวม Weak Leamners หลาย ๆ ตัวมาทำงานเป็นช่ต่อเข้าด้วยกัน ซึ่ง Learner ที่สร้างขึ้นใหม่แต่ละรุ่นนั้นจะทำการแก้ไขข้อบกพร่องในการทำงานของ Learner รุ่นก่อนหน้าเพื่อลด Error พอฝึกแบบจำลองเสร็จแล้ว Learner ทุกตัวจะพยากรณ์ร่วมกัน (7)
ข้อมูลที่ใช้ในการวิเคราะห์ ประกอบด้วย ดังนี้ Cardiovascular Disease Dataset และ Synthetic Dataset
1. Cardiovascular Disease Dataset
เป็นข้อมูลเกี่ยวกับโรดหัวใจและหลอดเลือดของคนไข้ทั้ง 70,000 คน โดยมีผู้ป่วยเป็นโรคหัวใจและหลอดเลือด 34,979 คน และผู้ป่วยที่ไม่เป็นโรคหัวใจและหลอดเลือด 35,021 คน สามารถเข้าถึงได้โดย https://www.kaggle.com/datasets/sulianova/cardiovascular-disease-dataset

Cardiovascular Disease Dataset มีทั้งหมด 70,000 datapoints โดยประกอบด้วย 12 Columns ดังนี้
- age (อายุ) มีหน่วยเป็น วัน (days)
- weight (น้ำหนัก) มีหน่วยเป็นกิโลกรัม (kg)
- height (ส่วนสูง) มีหน่วยเป็นเซนติเมตร (cm)
- ap_hi (ความดันช่วงหัวใจบีบตัว หรือความดันตัวบน) มีหน่วยเป็นมิลลิเมตรปรอท (mmHg) ค่าปกติคือ 90-140 mmHg
- ap_Io (ความดันช่วงหัวใจคลายตัว หรือความดันตัวล่าง) มีหน่วยเป็นมิลลิเมตรปรอn (mmHg) ค่าปกติคือ 60-90 mmHg
- gender (เพศ) 1 หมายถึง เพศหญิง 2 หมายถึง เพศชาย
- smoke (การสูบบุหรี่) 0 หมายถึง ไม่สูบ 1 หมายถึง สูบ
- active (การออกกำลังกาย) 0 หมายถึง ไม่ออกกำลังกาย 1 หมายถึง ออกกำลังกาย
- alco (การดื่มแอลกอฮอล์) 0 หมายถึง ไม่ดื่ม 1 หมายถึง ดื่ม
- cardio (การป่วยเป็นโรคหลอดเลือดหัวใจ) 0 หมายถึง ไม่ป่วยเป็นโรคหลอดเลือดหัวใจ 1 หมายถึง ป่วยเป็นโรคหลอดเลือดหัวใจ
- cholesterol (โคเลสเตอรอล) 1 หมายถึง ปกติ 2 หมายถึง ผิดปกติ 3 หมายถึง ผิดปกติมาก
- gluc (ระดับน้ำตาลในเลือด) 1 หมายถึง ปกติ 2 หมายถึง ผิดปกติ 3 หมายถึง ผิดปกติมาก
1. ตรวจสอบข้อมูล

จากการตรวจสอบข้อมูล พบว่า มี 70,000 datapoints และประกอบด้วย 12 Columns โดย เป็น numerical data ทั้งหมด ซึ่ง มี 12 integers และ 1 float
2. ตรวจสอบ null ของข้อมูล

จากการตรวจสอบ null ในข้อมูล พบว่า ในข้อมูลไม่มี Null
3. Descriptive statistics

จากการตรวจสอบ Descriptive statistics พบว่า มีความผิดปกติตรงค่า Min และ ค่า Max ใน Column ดังนี้
-
height: ส่วนสูงที่น้อยที่สุดคือ 55 cm และมากที่สุดคือ 250 cm
-
weight: น้ำหนักที่น้อยที่สุดคือ 10 kg และมากที่สุดคือ 200 kg
-
ap_hi: ความดันช่วงหัวใจบีบตัวที่น้อยที่สุดคือ -150 mmHg และมากที่สุดคือ 16,020 mmHg ซึ่ง ค่าความดันช่วงหัวใจบีบตัวจะติดลบไม่ได้ และไม่ควรน้อยกว่า 80 mmHg และมากกว่า 180 mmHg เพราะจะกลายเป็น emergency case (8)
-
ap_lo: ความดันช่วงหัวใจคลายตัวที่น้อยที่สุดคือ -70 mmHg และมากที่สุดคือ 11,000 ซึ่ง ค่าความดันช่วงหัวใจคลายตัวจะติดลบไม่ได้ และไม่ควรน้อยกว่า 60 mmHg และมากกว่า 110 mmHg เพราะจะกลายเป็น emergency case (8)
ดังนั้นเพื่อจัดการกับข้อมูลทีมีีความผิดปกติดังกล่าว จึงต้องทำ Preparing Data ในขั้นตอนต่อไป
4. สรุปการกระจายตัวของข้อมูล และสัดส่วนของข้อมูลแต่ละ Columns ในข้อมูล
- age
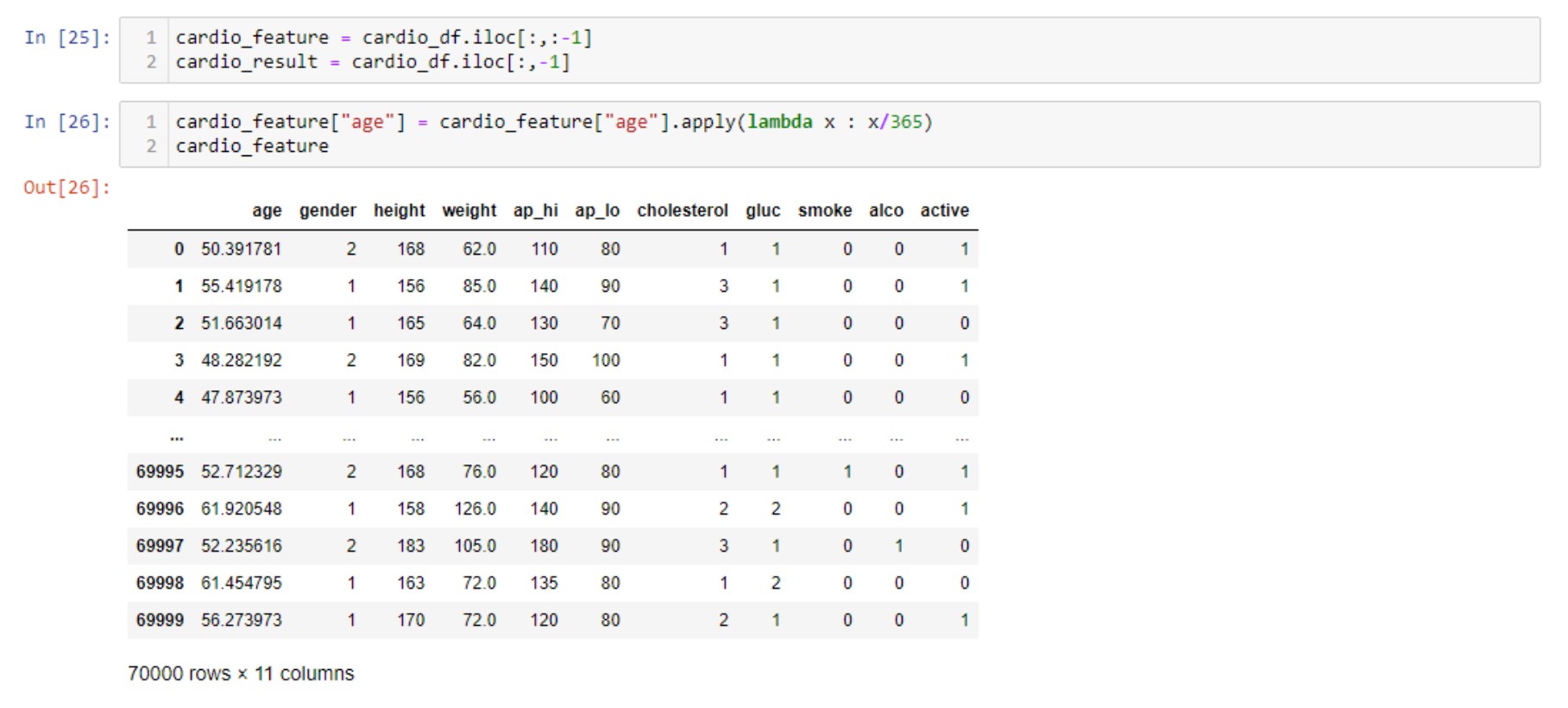
แปลง age Column ให้มีหน่วยเป็น ปี

การกระจายตัวของ age Column
- gender

การแสดงสัดส่วนของข้อมูล gender Column โดย 1 หมายถึง เพศหญิง ส่วน 2 หมายถึง เพศชาย
จากการแสดงสัดส่วนของข้อมูล gender Column พบว่า มีจำนวนผู้ป่วยเพศหญิง(1) มากกว่าจำนวนผู้ป่วยเพศชาย(2)
- height

จาก box plot ของ height Column พบ Outliers จำนวนมาก จึงต้องทำ Data Preparation ในขั้นตอนต่อไป
- weight

จาก box plot ของ weight Column พบ Outliers จำนวนมาก จึงต้องทำ Data Preparation ในขั้นตอนต่อไป
- ap_hi

จาก box plot ของ ap_hi Column พบ Outliers จำนวนมาก จึงต้องทำ Data Preparation ในขั้นตอนต่อไป
- ap_lo

จาก box plot ของ ap_hi Column พบ Outliers จำนวนมาก จึงต้องทำ Data Preparation ในขั้นตอนต่อไป
- cholesterol

การแสดงสัดส่วนของข้อมูล cholesterol Column โดย 1 หมายถึง ปกติ 2 หมายถึง ผิดปกติ 3 หมายถึง ผิดปกติมาก
- gluc

การแสดงสัดส่วนของข้อมูล cholesterol Column โดย 1 หมายถึง ปกติ 2 หมายถึง ผิดปกติ 3 หมายถึง ผิดปกติมาก
- smoke

การแสดงสัดส่วนของข้อมูล smoke Column โดย 0 หมายถึง ไม่สูบ 1 หมายถึง สูบ
- alco

การแสดงสัดส่วนของข้อมูล alco Column โดย 0 หมายถึง ไม่ดื่ม 1 หมายถึง ดื่ม
- active

การแสดงสัดส่วนของข้อมูล active Column โดย 0 หมายถึง ไม่ออกกำลังกาย 1 หมายถึง ออกกำลังกาย
- cardio

การแสดงสัดส่วนของข้อมูล cardio Column โดย 0 หมายถึง ไม่ป่วยเป็นโรคหลอดเลือดหัวใจ 1 หมายถึง ป่วยเป็นโรคหลอดเลือดหัวใจ
1. การจัดการข้อมูลที่มีความผิดปกติใน ap_hi Column หรือ ความดันช่วงหัวใจบีบตัว
เนื่องจากการทำ Exploratory Data Analysis (EDA) ใน Cardiovascular Disease Dataset พบว่า ap_hi Column มีความผิดปกติ คือ ความดันช่วงหัวใจบีบตัวที่น้อยที่สุดคือ -150 mmHg และมากที่สุดคือ 16,020 mmHg ซึ่งค่าความดันช่วงหัวใจบีบตัวจะติดลบไม่ได้ และไม่ควรน้อยกว่า 80 mmHg และมากกว่า 180 mmHg เพราะจะกลายเป็น emergency case (8)
จึงทำการลบข้อมูลที่มีค่า ความดันช่วงหัวใจบีบตัวต่ำกว่า 80 mmHg และมากกว่า 180 mmHg ออก โดยวิธีดังนี้

2. การจัดการข้อมูลที่มีความผิดปกติใน ap_lo Column หรือ ความดันช่วงหัวใจคลายตัว
เนื่องจากการทำ Exploratory Data Analysis (EDA) ใน Cardiovascular Disease Dataset พบว่า ap_lo Column มีความผิดปกติ คือ ความดันช่วงหัวใจคลายตัวที่น้อยที่สุดคือ -70 mmHg และมาก ที่สุดคือ 11,000 ซึ่งค่าความดันช่วงหัวใจคลายตัวจะติดลบไม่ได้ และไม่ควรน้อยกว่า 60 mmHg และมาก กว่า 110 mmHg เพราะจะกลายเป็น emergency case (8)
จึงทำการลบข้อมูลที่มีค่า ความดันช่วงหัวใจคลายตัวต่ำกว่า 60 mmHg และมากกว่า 110 mmHg ออก โดยวิธีดังนี้

3. เพิ่ม BMI Column และจัดการข้อมูล BMI ที่มีความผิดปกติ
จากการตรวจสอบข้อมูล Weight และ Height พบว่า ส่วนสูงที่น้อยที่สุดคือ 55 cm และมากที่สุด คือ 250 cm น้ำหนักที่น้อยที่สุดคือ 10 kg และมากที่สุดคือ 200 kg จะเห็นว่าช่วงข้อมูลมีค่าผิดปกติจาก น้ำหนักและส่วนสูงของมนุษย์ธรรมดาอย่างเห็นได้ชัด (9) ซึ่งเทียบจากค่าดัชนีมวลกาย โดยเอาข้อมูลน้ำหนัก และส่วนสูงไปคำนวน
โดยสูตรของ Body Mass Index (BMI) มีดังนี้
การเพิ่ม BMI Column มีวิธีดังนี้

แสดงขั้นตอนการเพิ่ม BMI Column

Descriptive statistics ของ Cardiovascular Disease Dataset หลังจากเพิ่ม BMI Column ซึ่งยังมีความผิดปกติตรงค่า Min และ ค่า Max อยู่
จาก Descriptive statistics หลังจากเพิ่ม BMI Column จะเห็นว่า มีความผิดปกติตรงค่า Min และ ค่า Max โดยค่าที่น้อยที่สุด คือ 3.47 และมากที่สุด คือ 298.67 ซึ่งค่า BMI ดังกล่าวผิดปกติไปจากเกณฑ์ของมนุษย์ที่ไม่ควรจะต่ำกว่า 16 และไม่ควรจะสูงกว่า 40 (9) จึงทำการลบข้อมูลที่มีค่า BMI ที่ ต่ำกว่า 16 และมากกว่า 40 ออก โดยวิธีดังรูป จากนั้นลบ Weight และ Height Column ออก เพื่อลดความซ้ำซ้อนของข้อมูล

แสดงขั้นตอนการลบข้อมูลที่มีความผิดปกติ ใน BMI และ Descriptive statistics หลังจากลบข้อมูลที่มีความผิดปกติแล้ว
4. การเปลี่ยนแปลงข้อมูลใน gender, cholesterol, gluc Column

ทำการเปลี่ยนแปลงข้อมูลในทั้ง 3 Column ดังนี้ gender, cholesterol และ gluc เพื่อให้เข้าใจง่ายขึ้น และสะดวกต่อการนำไปวิเคราะห์ต่อ
5. การเปลี่ยนแปลงหน่วยของข้อมูลใน age Column

ทำการเปลี่ยนแปลงหน่วยของข้อมูลใน age Column จากหน่วยวัน ให้เป็น ปี เพื่อให้เข้าใจง่ายขึ้น และสะดวกต่อการนำไปวิเคราะห์ต่อ


จะเห็นว่าข้อมูลที่ได้ไม่มีความผิดปกติแล้ว จากการกระจายของ cardio Column หลังจากการทำ Data Preparation แล้ว พบว่า สัดส่วนของข้อมูลใน cardio Column มีค่าใกล้เคียงกัน ดังนั้นจึงสามารถใช้ ค่าความถูกต้อง (Accuracy) ในการประเมินแบบจำลองในขั้นตอนต่อ ๆ ไปได้
2. Synthetic Dataset


1.1 Logistic Regression Classifier โดยการใช้ GridSearchCV()

การฝึกโมเดล Logistic Regression โดยนำอัลกอริทึม GridSearchCV() มาใช้ในการหาพารามิเตอร์ที่เหมาะสม ที่ทำให้โมเดลได้ค่าความถูกต้องสูงสุด ซึ่งพารามิเตอร์ที่ทำการปรับค่า มีดังนี้
- C : Inverse of regularization strength Regularization คือ เทคนิคในการปรับโมเดลเพื่อลดค่า loss function และป้องกันไม่ให้โมเดลจำเพาะต่อข้อมูลน้อยหรือมากเกินไป (underfitting or overfitting) ดังนั้นเมื่อเรากำหนด ค่า C ให้มีค่าสูง เป็นการให้ความสำคัญ (weight) กับชุดข้อมูลที่ใช้ฝึกโมเดล
- solver : อัลกอริทึมที่ใช้ในขั้นตอนการลดค่า loss function หรือกระบวนการ optimization
- max_iter : จำนวนรอบสูงสุดในการดำเนินการตาม solver เพื่อหาจุดที่ค่า loss function ไม่เปลี่ยนแปลงค่า (converge)

การฝึกโมเดล Logistic Regression โดยนำอัลกอริทึม GridSearchCV() ใช้ทั้งหมด 140 combinations โดยฝึกโมเดลด้วยชุดข้อมูลที่แบ่งด้วยเทคนิค Cross Validation ออกเป็น 5 ส่วน ผลลัพธ์ combination ที่ดีที่สุดคือ {'C': 0.1, 'max iter': 2500, 'solver': 'liblinear'}

Logistic regression combination ที่ดีที่สุดได้ค่าความถูกต้องของชุดข้อมูลฝึกและชุดข้อมูลทดสอบเท่ากับ 72.17% และ 72.66% ตามลำดับ
1.2 Random Forest Classifier โดยการใช้ GridSearchCV()

การฝึกโมเดล Random Forest โดยนำอัลกอริทึม GridSearchCV() มาใช้ในการหาพารามิเตอร์ที่เหมาะสม ที่ทำให้โมเดลได้ค่าความถูกต้องสูงสุด ซึ่งพารามิเตอร์ที่ทำการปรับค่า มีดังนี้
- n_estimators : จำนวนของต้นไม้ที่ใช้ในการทำนาย
- max_depth : ความลึกสูงสุดของต้นไม้ การเพิ่มค่านี้จะทำให้โมเดลซับซ้อนขึ้น
- max_features : จำนวน feature ที่ใช้พิจารณาในการแบ่ง node
- min_samples_leaf : จำนวนข้อมูลที่น้อยที่สุดใน 1 leaf node
- min_samples_split : จำนวนข้อมูลที่น้อยที่สุดในการแบ่ง node
- criterion : ฟังก์ชั่นที่ใช้ในการวัดความสามารถในการแบ่ง
- class_weight : ค่า weight สำหรับแต่ละ class
- bootstrap : เทคนิคในการใช้ bootstrap samples ในการสร้างต้นไม้

การฝึกโมเดล Random Forest โดยนำอัลกอริทึม GridSearchCV() ใช้ทั้งหมด 1080 combinations โดยฝึกโมเดลด้วยชุดข้อมูลที่แบ่งด้วยเทคนิค Cross Validation ออกเป็น 5 ส่วน ผลลัพธ์ combination ที่ดีที่สุดคือ {'bootstrap': True, 'class_weight': 'balanced', 'criterion': 'gini', 'max_depth': 8, 'max_features': 'sqrt', 'min_samples_leaf': 3, 'min_samples_split': 2, 'n_estimators': 200}

1.3 eXtreme Gradient Boosting (xGB) โดยการใช้ GridSearchCV()


การฝึกโมเดล eXtreme Gradient Boosting (xGB) โดยนำอัลกอริทึม gridsearchcv มาใช้ในการหาพารามิเตอร์ที่เหมาะสม ที่ทำให้โมเดลได้ค่าความถูกต้องสูงสุด ซึ่งพารามิเตอร์ที่ทำการปรับค่า มีดังนี้
- colsample_bytree : คืออัตราส่วน subsample ของคอลัมน์เมื่อสร้างต้นไม้แต่ละต้น การสุ่มตัวอย่างจะเกิดขึ้นครั้งเดียวสำหรับต้นไม้ทุกต้นที่สร้าง
- gamma : คือการลด Minimum loss ในการแบ่งเพิ่มเติมบน leaf node ของต้นไม้ ยิ่งแกมมามากเท่าไร อัลกอริธึมก็จะยิ่งอนุรักษ์ค่า gamma มากขึ้นเท่านั้น
- learning_rate : เป็น parameter ที่ควบคุมว่าจะเปลี่ยนแปลงค่า weight มากหรือน้อยเท่าไหร่ของ Model ใน 1 Step ของ Training ถ้าปรับไว้มากเกินไปจะทำให้คำตอบของ Model ไม่ลู่เข้าสู่คำตอบจริงหรือจุดที่เป็น Global Minimum แต่ถ้าปรับไว้น้อยเกินไปจะทำให้ใช้เวลาในการ Train นานขึ้น
- Max_depth : ความลึกสูงสุดของต้นไม้ การเพิ่มค่านี้จะทำให้โมเดลซับซ้อนขึ้น ถ้ากำหนดค่า Max_depth = 0 หมายถึงไม่จำกัดความลึก ซึ่งสิ่งที่ควรต้องระวังคือ XGBoost จะใช้หน่วยความจำเยอะดังนั้นจึงไม่ควรกำหนดให้ Max_depth = 0
- min_child_weight : ผลรวมขั้นต่ำของน้ำหนักอินสแตนซ์ที่จำเป็นสำหรับโหนดลูก หากการแบ่งต้นไม้ให้ค่าน้ำหนักรวมของอินสแตนซ์โหนดปลายสุดน้อยกว่า min_child_weight จะยกเลิกการแบ่งเพิ่มเติม
- n_estimators : จำนวนของต้นไม้ที่ใช้ในการทำนาย
- scale_pos_weight : ควบคุมความสมดุลของน้ำหนักบวกและลบ ซึ่งมีประโยชน์สำหรับ class ที่ไม่สมดุล

จากการทำ eXtreme Gradient Boosting โดยการใช้ GridSearchCV() เพื่อหา parameter ที่ดีที่สุดจากการ Tuning Parameters วนซ้ำไปเรื่อย ๆ จนได้ Best parameter คือ { 'colsample_bytree': 0.5, 'gamma': 1.5, 'learning_rate': 0.01, 'max_depth': 10, 'min_child_weight': 10, 'n_estimators': 100, 'scale_pos_weight': 1 } ได้ค่าความถูกต้องในการทำนายชุดข้อมูลฝึกและชุดข้อมูลทดสอบเท่ากับ 74.4292% และ 72.8% ตามลำดับ
จากการใช้อัลกอริทึมทั้ง 3 ได้แก่ Logistic Regression, Random Forest และ eXtreme Gradient Boosting สร้างแบบจำลองจากข้อมูล Synthetic Dataset โดยการกำหนดค่า hyperparameters แบบเดียวกับผลลัพธ์จากการทำ GridSearchCV() สรุปผลลัพธ์มีค่าดังต่อไปนี้
2.1 Logistic Regression

Logistic regression combination ที่ดีที่สุดได้ค่าความถูกต้องในการทำนายชุดข้อมูลฝึกและชุดข้อมูลทดสอบเท่ากับ 88.93% และ 89.2% ตามลำดับ
2.2 Random Forest

Random Forest combination ที่ดีที่สุดได้ค่าความถูกต้องในการทำนายชุดข้อมูลฝึกและชุดข้อมูลทดสอบเท่ากับ 88.93% และ 89.2% ตามลำดับ
2.3 eXtreme Gradient Boosting
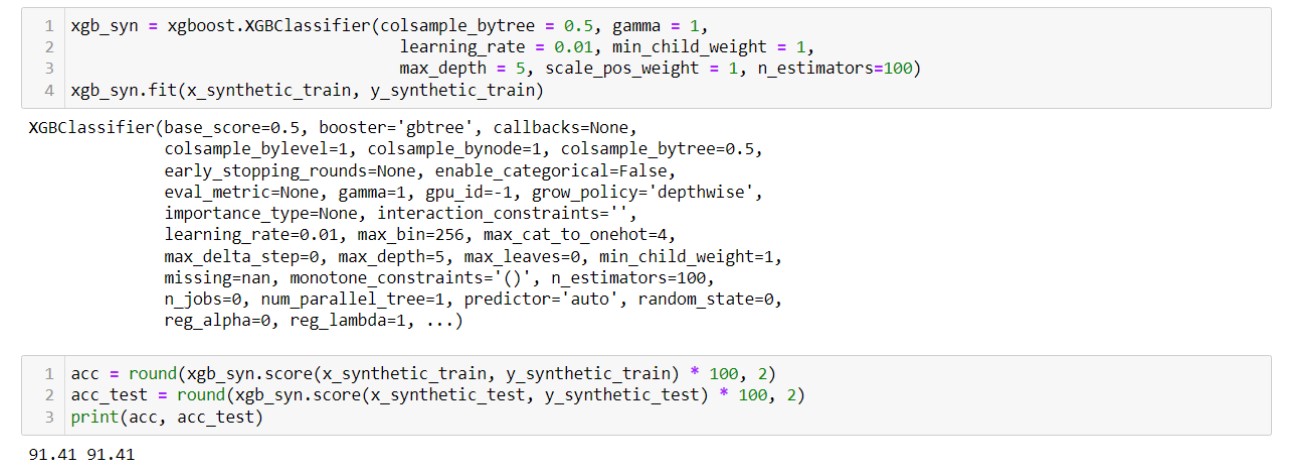
eXtreme Gradient Boosting combination ที่ดีที่สุดได้ค่าความถูกต้องในการทำนายชุดข้อมูลฝึกและชุดข้อมูลทดสอบเท่ากับ 91.41% และ 91.41% ตามลำดับ

การวิเคราะห์ผลจาก Cardiovascular Disease Dataset จะได้ว่า ค่าความถูกต้องที่ได้จากแบบจำลองแต่ละอัลกอริทึมพบว่าค่าค่อนข้างใกล้เคียงกัน จากการสำรวจข้อมูลหรือทำ Exploratory Data Analysis (EDA) จึงพบว่า มีเพียงบางปัจจัยในชุดข้อมูลที่ส่งผลต่อการแยก class ได้อย่างชัดเจน สาเหตุต่อมาอาจมาจาก ค่าจากปัจจัยในชุดข้อมูลที่เก็บมาผิดประเภท เช่น ค่าโคเลสเตอรอลและระดับน้ำตาลในเลือด ที่ควรจะเก็บมาเป็นค่า numerical แต่ข้อมูลชุดนี้กลับเก็บค่าเป็น categorical แบบมีลำดับ สาเหตุสุดท้ายคือข้อมูลชุดนี้ไม่มีแหล่งที่มาอ้างอิง ซึ่งส่งผลต่อความน่าเชื่อถือ ของชุดข้อมูล จากทั้ง 3 สาเหตุดังกล่าวอาจเป็นที่มาที่ส่งผลต่อประสิทธิภาพในการแยกประเภทของแบบ จำลองหรือค่าความถูกต้อง
-
โรคหัวใจและหลอดเลือด [อินเตอร์เน็ต]. [เข้าถึงเมื่อ 14 พ.ค. 2565]. เข้าถึงได้จาก: https://ccpe.pharmacycouncil.org/index.php?option=seminar_detail&subpage=seminar_detail&id=1623
-
รอบรู้เรื่องโรคและภัยสุขภาพ : สคร.6 ชลบุรี ชวนปกป้องหัวใจ ในวันหัวใจโลก [อินเตอร์เน็ต]. 2563 [เข้าถึงเมื่อ 14 พ.ค. 2565]. เข้าถึงได้จาก: https://ddc.moph.go.th/odpc6/news.php?news=14902&deptcode=odpc6&news_views=265
-
Scikit-learn [อินเตอร์เน็ต]. [เข้าถึงเมื่อ 14 พ.ค. 2565]. เข้าถึงได้จาก: https://scikit-learn.org/stable/modules/generated/sklearn.model_selection.GridSearchCV.html
-
การวิเคราะห์ข้อมูลการวิจัยทางวิทยาศาสตร์สุขภาพโดยใช้ การถดถอยลอจีสติก [อินเตอร์เน็ต]. [เข้าถึงเมื่อ 14 พ.ค. 2565]. เข้าถึงได้จาก: http://classroom.takasila.org/classroom/dataupload/takasila/project/29file/Logistic/LogisticSLT.pdf
-
หลักการและการใช้การวิเคราะห์การถดถอยโลจิสติคสำ หรับการวิจัย [อินเตอร์เน็ต]. [เข้าถึงเมื่อ 14 พ.ค. 2565]. เข้าถึงได้จาก: http://rdi.rmutsv.ac.th/rmutsvrj/download/year4-issue1-2555/p1.pdf
-
การใช้เทคโนโลยีการเรียนรู้ของเครื่อง เพื่อทำนายผลการเรียนของนักเรียน [อินเตอร์เน็ต]. [เข้าถึง เมื่อ 14 พ.ค. 2565]. เข้าถึงได้จาก: http://ir-ithesis.swu.ac.th/dspace/bitstream/123456789/610/1/gs611130429.pdf
-
Boosting [อินเตอร์เน็ต]. [เข้าถึงเมื่อ 14 พ.ค. 2565]. เข้าถึงได้จาก: https://guopai.github.io/ml-blog11.html
-
Blood pressure chart: What is a healthy range? 8 signs your blood pressure is too high [อินเตอร์เน็ต]. [เข้าถึงเมื่อ 14 พ.ค. 2565]. เข้าถึงได้จาก: https://www.express.co.uk/life-style/health/1454979/blood-pressure-chart-healthy-range-signs-too-high-symptoms-EVG
-
Am I a candidate for bariatric surgery? Learn your body mass index [อินเตอร์เน็ต]. [เข้าถึงเมื่อ 14 พ.ค. 2565]. เข้าถึงได้จาก: https://www.honorhealth.com/medical-services/bariatric-weight-loss-surgery/bariatric-surgery-candidate