2011
Agenda
- Hudson package system progress
- IOS
- TOD, Going forward
- Higher level tools
- Russian holidays to Jan 10
Minutes
Package build
- Working on getting tests running w/in Google test system
- Lots of conversion work on existing tests, so looking to just change the output xml to compatible format for their statistics understood by Hudson
- Trying to create macro wrappers to automate this
- All new functions will use Google tests
- Then expand Hudson based system for more configurations
- Right now it only does Linux and Mac
- Android: test on Android simulator from command line in batch mode
- Timeline:
- test system will be converted by mid-Jan
- expand system to all OS: Completed by end of month — that’s the system, not necessarily that all tests work
OpenCV on IOS / iPhone
- CMake tool chain might make this easy
- Need support or a long term volunteer to support this, possibilities
- http://eosgarden.net/en/opensource/opencv-ios/overview/
- http://niw.at/articles/2009/03/14/using-opencv-on-iphone/en
Version control
- Switch to mercurial? A bit simpler than GIT
- Git is good, but more complex
- Google code supports mercurial
- Git hub
- In any case, this would make it easier for external users to support things like ios.
TOD
- Refactored
- Working reasonably well on data by prime sense
- Need to test on the datasets on the head cart (backward compatibility, accuracy test)
- Have kinect working independent of ROS
- Recognition and training
- Ethan has scripts that turn old bag data into the refactored version
- No one has tried the full pipeline
- kinect has a setting for ~1000×1000 resolution in the openni, accessible through dynamic reconfigure
- Better in grayscale
Next steps
- Higher level tools focus
- Build into android
- Get iOS working
Action Items
Gary
- See if Bart has connections back to Apple about supporting OpenCV on iOS
Alexander
Vadim
Victor
Kurt
Ethan
- Will look at state of tod
From last time
Gary
Alexander
Vadim
Victor
Kurt
Ethan
Agenda
- Hudson progress
- TOD
- vslam
- Foundation
- Future plans
- Higher level functionality
Minutes
-
TOD (textured object detection)
- By mid-day will have end to end training
- Haven’t made scripts to make data from old bag files
- Alexander is continuing work on the detection part
- Everyone should be working in unstable branch of ROS for this
- Training might be broken right now
- Alexander thinks TOD doesn’t work well yet with kinect
- Ethan tested using super xVGA using high res mode and got some solid matches
- Old bag files are /wg/wgdata1/vol1/textured_object/bags
- Contest will use bags and tools for reading them
- The tool will dump data to images and point clouds
- Training tool uses a calibration pattern to give the object pose
- Might use 3D point clouds + PCL to remove table to get segmented objects
- tod_detecting was moved to unstable. Ehtan did a diff and the 2 projects were almost the same
- tod_detection has now been extensively changed in unstable
- Specifically, Ethan added pre-clustering differently from Alexander
- cluster_sample in apps. Before it matches, clusters keypoints in 2D and treats each as a set of test points
- Working on end-to-end, train→test not working on algorithmic stuff yet
- Victor tod status: “We are trying to recover from refactoring”. Need to convert old bags to new. Alexander is working with objects that he already has.
- Ethan is working on capture, train+test, bag converstion
- Ethan should be done with bag conversion today.
- Victor wants to test on high res to compare after refactoring
- Debayer mode seems like a no-op, but check near edges for color bleed or in gray scale for zippering effects
- Ethan has been using tod_detecting in unstable
-
Solutions in Perception:
- V: More than 20 objects, rec and pose should be 2 different algorithms. Alexander has been working on this
- Match, cluster then pose validation
- Look at nlopt for giving a default method of finding pose
- use for image alignment or pose alignment. reproject error or image differencing. But a bit slow
- compared with solvePNP. nlopt was substantially more stable
- You can do this without gradients, it uses the errors to calculate Jacobians etc
- Training set can be in zip files and bags
- Can run anywhere, but algorithm will also run with node
- Iterative Closest Point (ICP)
- V: More than 20 objects, rec and pose should be 2 different algorithms. Alexander has been working on this
- Foundation
- Talk to Willow about whether they help launch and/or Itseez
- Future
- Higher level functionality that supports assisted teleop
- Wiki opencv submission process
- Need to look over and approve so that it can be linked to the main site
- OpenCV is lacking in cheat sheet. Need newbie boot up
- Tutorials in opencv/user guide?
- Victor putting down what should be in user guide
- Concentrate on cxcore
Vadim
It was not a productive week, because of the holidays.
- 2 bugs have been fixed:
- video capturing on Windows (ticket #788 and related #752,
- compile errors (#783)
- continued working on the googletest-based tests; some helper macros and functions for comparing images, loading test data etc. have been added.
Plans:
- Finish cxcoretest port to google test, add test reports to our hudson config.
- Split cvtest into module-specific tests; convert to google test (try to do it quickly using cxts(opencv test system)-to-gtest wrappers).
Action Items
Gary
- Look into foundation
- Feedback on OpenCV submission
Alexander
Vadim
Victor
- Put down user feedback for “user guide”
Kurt
Ethan
- Get old bag reader to Alexander
- Maybe segment using PCL plain removal
From last time
Gary
Alexander
Vadim
Victor
Kurt
Ethan
Agenda
- Code submission
- Allow lighter user contrib?
- documentation status
- LSH … state of this code?
- vslam if Kurt shows up
- higher level functionality brainstorm
-
TOD
- TOD has been put in a “real time” end to end system using kinect. It is now trivial to collect datasets in. We need to focus on this data.
- There were old Prosilica bags that are now broken. Ethan thinks it will take many hours to reserect partly because there was no natural match between the point clouds and the image and that has to be resynthesized. I’d like to avoid putting in time to old data sets since we won’t be going back to prosilica but will go with Kinect.
- Speeding up TOD matching
- Refactoring status?
- Putting TOD in REIN
- Putting in 3D to 3D matching (ICP in PCL library)
Minutes
-
vslam
- 3 developers are rewriting Haki’s code which will form the basis
- also monocular vslam
- Uses local databases of points from all images rather than image to image which ~works better (maybe)
-
Code submission
- 2 processes? user contrib and formal
- Most CV is experimental, need a larger filter for acceptance
- Maybe go with the more formal contribution process, then look at using git to make a less formal method
- Most of our contributors are researchers, not software engineers
- Most of the time, we get prototypes that need work
- To make it easier to work for us, we can establish this process
- Git can help with this because if code is developed and put into their own branch of OpenCV, it will work more seamlessly
- Then at least it builds as an opencv function
- Decision: propagate this new approach
-
new test system:
- cxcore now completely uses google test framework (took 2 weeks for Vadim)
- next, cv needs to be split into modules (still using our old test system)
- This will take this week.
- First, will try to convert output of old tests to google xml.
- Decision: see how it goes converting output
-
Documentation Status
- James was going to modify the python scripts that change latex to rst
- The intent is that someone in the future will edit rst directly (they may still use James’s script to convert latex to rst)
- rst looks much like wiki text, but allows direct latex math formulas
-
LSH
- Contributed Xavier Delecor, said had good speedup
- But sometimes you get zero candidates for some points
- Multiple random 1D projections, splitting the axis into into some bins/quantized
- Each bin acts like an element of a hash table. If collisions, you get a linked list, traverse to get points
- With multiple random projects and search for closest points, you’ll probably get the closest point
- Might need a modification to look for neighbor bins if local bin is empty.
- How does standard LSH handle that problem?
- Claims this only happens with artificial data, claims real data does not have this problem
- ’’Dubious’’
- Waiting on Marius comment for FLANN
- Will experiment with other code for LSH for now
- Claims this only happens with artificial data, claims real data does not have this problem
-
TOD:
- Code is refactored, similar results to older code but a little worse
- Training on new data: inconsistent frames
- Might be a result of bad fiducials
- Could scale old data and see what accuracy hit
- Where is the refactored code? tod_deecting in unstable ROS
- Very few false positives but there were missed detection, 3 out of 6 items found
- Can work from recognition, but wrong pose.
- Need to draw point cloud into reference frame and then draw in rviz
- End to end system
- Potential problem with
- Alexander is using tod_core, but tod_training?
- Ethan record a set of test bag systems
- Need 3D to 3D use poseEst
- Not in OpenCV
- Decisions:
- Ethan/Gary capture larger new “gold” data set
- Alexander check in code and start using tod_core and tod_training
- Speed up binary match with LSH, and/or use SURF for now with FLANN
- Add in 3D to 3D matching
- Check that pose is OK in the new data (does the bad poses problem go away)
- Put it into REIN
Vadim
- New test system:
- The whole last week was spent in converting the remaining core tests to the google test framework.
- Now all 78 core tests use the new framework.
- The next thing is to break up cv tests into the smaller modules and convert them to (the actual conversion can be done step by step, as soon as the new project structure is used).
Victor
-
TOD:
- Refactoring of the detection code is finished.
- A converter from the old training base format to the new one has been implemented.
- The new code has been tested on the old base and showed slightly worse results (below). [Alexander]
TEXTURED_OBJECT_DETECTION:
/shared/binpick/test_base/test1 FP = 1
cards 0.961905 0
coffee_filter 0.829268 0
TOD_DETECTING:
/shared/binpick/test_base/test1 FP = 2
cards 0.916763 0
coffee_filter 0.7739839 0
-
Pose refinement with edges:
- LM-ICP has been opitmized using distance transform and its gradient.
- Experiments with avocado slicer show that the effect from the refinement is not dramatic.
- We will experiment with less textured objects.[Ilya]
-
Kinect with OpenCV:
- integrated openni into opencv and tested in ubuntu.
- A strawman implementation CvCapture_OpenNI that allows to get depth images has been created.
- A sample for working with Kinect has been created. The next stage is testing all of this for Windows. Maria
-
User manual:
- A prototype of a user manual for OpenCV has been created for download.
- It is supposed to be a layer between reference manual and samples, explaining how to solve specific problems with OpenCV. [Victor]
Anatoly Baksheev (GPU)
Accomplishments: 1) Main focus on documentation. Covered about 80% of functions. Reviewed docs written. Left introduction, data structures (GpuMat, Stream, CudaMem), initialization, FAQ, Getting started, interoperability with CUDA, multi-threading, multi-GPU. Think will finish docs this week. 2) GPU module. · Resolved ticket #798 (can't find template in a black image containing single template occurrence). Closed tickets #809, #813, #58# Created sample for morphology on GPU. (FYI, OpenCV's bug tracker: https://code.ros.org/trac/opencv/ticket/798) · Committed FD for windows. (Wait NPP_staging for other platforms) Updated FD & sample according to Anton's comments and wishes. Fixed bug he found. · Investigating FD issue in Debug configuration is in process. This is reproduced only on Anton's computer. 3) BFM + Quadro status. We almost sure that the issue (NPP_staging transpose test fails after BFM test) is on our side in BFM. But we did not work on this, will return later. Plans: 1) Finish with documentation. 2) Benchmarks, samples, testing, other small tasks. 3) Commit Anton's FD tests. May be add possibility to Anton's FD interface.
Action Items
Gary
- Write an example user contrib
Alexander
- Communicate with Ethan to sync up the code:
- Commit TOD changes, make sure you are using or switch to tod_core, tod_training, tod_detect (and/or switch to tod_rein when ready)
- use new kinect data
- Check pose (I think it’s probably OK with new data)
- Check miss detection — this is he main gap with TOD right now
Vadim
- split cv into modules, have them put out google test compliant xml files
Victor
Kurt
Ethan
- Make sure Alexander is using the correct bags
- Put tod into rein
- code stub for challenge
- new pattern
- LSH
James
- Change python scripts that convert latex to rst adding pretty print capabilities/formatting
- Will allow editing rst manually
From last time
Gary
- (./) Look into foundation
- (./) Feedback on OpenCV submission
- Do we want a lighter process for user submissions?
Alexander
Vadim
Victor
- Put down user feedback for “user guide”
Kurt
Ethan
- Get old bag reader to Alexander
- Maybe segment using PCL plain removal
Agenda
- Keyed calibration pattern (leave out a dot?)
- Facilities for rotation/projection of data
-
LSH (Vincent worked on). Looks promising for binary patterns
- If this was new code, contrib to FLANN … or OpenCV?
-
TOD
- Status updates
- Have 50+ items in data bags from kinect
-
MOPED is finally open sourced … sigh, if this had happened a few months ago
- We’ll run comparisons. MOPED looks good on their data, we’ll try it on ours
- Some advantages for our code is that we run on any feature detector/descriptor
- FAST+BRIEF is very fast even on CPU
- Underway to fit within REIN
- We’ll have 3D to 3D (not sure if MOPED has) This is in ICP in PCL
- Some advantages for our code is that we run on any feature detector/descriptor
- Whatever form eventually gets contributed, we’ll cite both, theirs prior
- We’ll run comparisons. MOPED looks good on their data, we’ll try it on ours
- Code stubs for challenge (Guess these are due by noon today)
- Status updates
- Khronos meeting results (haven’t heard back so far)
- Change python scripts that convert latex to rst adding pretty print capabilities/formatting
- Will allow editing rst manually
- Going forward
- Recognition and pose
- oFAST
- Use simulated annealing to find just one tree
- Can we use what we have or the above to get oriented corners?
- LSH — very useful for binary patterns. Orders of magnitude speed up
- FAST detector, can we get orientation
- Kinect status
Minutes
- New dots calibration pattern
- Can we key it so it is not symmetric?
- Student at NNU is working on. Ilya can come up with a good way. He’s attending computer vision school in France. This week
- For partial patterns, need a good graph matching pattern. Using one from Boost, but this isn’t so good
- The code is now factored into blob detection and grid detection, so it’s easier to warp
- Right now the detector is good for calibration but not registration
- DECISION: Put Ilya on it next week
- Right now the detector is good for calibration but not registration
- Vadim is moving towards complete independence of each module to make OpenCV more flexible and … more modular.
- This way, a single or several modules of functionality can be loaded by users or not.
- Tests to be distributed into modules
-
MOPED now open source
- Paper, code
- Most of the time for MOPED is spent in clustering and matching points
- That’s where we’ll have to look for speedup
-
MOPED uses Bundler to create it’s 3D models
- Bundler is great code for structure from motion. It uses the “MIT license” which is ~= BSD except have to cite authors(?)
- Question for OpenCV is, since features and alignment are fundamental, we may make such a module. Do we just include code like this?
- Or, once we make our modules more independent, do we do a ROS like thing and configure CMAKE to pull such code in if the user builds modules that need the external code?
-
LSH
- Question to move into FLANN modulue (FLANN exisits outside of opencv but inside it is a module) or into Features2D support?
- DECISION: Talk to Marius about whether it’s best inside or outside FLANN
-
FAST-ER (http://mi.eng.cam.ac.uk/~er258/work/fast.html)
- We don’t have FASTER in OpenCV, we have FAST (chain of pixels around circle)
- GPU team used brute force but it’s really fast on GPU
- In OpenCV, we have decision trees and forms of boosting (gradient trees) that may allow learning corners AND their orientation
- It would be great to get out a single tree that could do corners and orientation. In FASTER, they use simulated annealing
- Victor is in touch with work to create a minimal depth single tree from a boosted forest.
- DECISION: Pursue this. Vincent will look at the ability to learn this, Victor research how to turn into single trees
- We don’t have FASTER in OpenCV, we have FAST (chain of pixels around circle)
- Kinect:
- OpenCV supports Kinect now!
- It works for Linux and Windows,
- there is a sample kinect_maps.cpp.
- We can obtain RGB image, disparity image, and a point cloud. Maria
Vadim
Hello,
The key results of the past week:
- Test system overhaul
- Merged gtest-based test engine and cxts (the original OpenCV test engine). It’s now a single test engine, formed as yet another opencv module (opencv_ts, located at opencv/modules/ts).
- Wrote special gtest wrapper for cxts-based tests. The wrapper runs the cxts test, based on the output it reports success or failure to gtest engine and copies all the output from cxts log to gtest as well.
- As a result, all the existing tests should build and run without any modifications (or with minor modifications) as normal gtest tests, and thus they all generate XML report usable within Hudson.
- The only major thing that changes is registration of such wrapped tests, but it’s just 1-2 lines of code per test.
- As proof-of-concent, extracted several tests for image processing OpenCV functions from tests/cv, put them to opencv/modules/imgproc/test. The tests have been successfully compiled and run as gtest tests.
Plans:
- this week: do some ts code cleanup; finish reorganization of all the OpenCV tests. Add test execution & displaying test XML reports to our Hudson task list.
- next week: start conversion of our documentation from Latex to RST; split it by modules as well.
Victor
-
TOD:
- the difference between the old and the refactored (in unstable) versions is eliminated, both versions show same accuracy (see below).
- Smaller changes: added threshold parameter to FeatureExtractor class, changed and refactored RatioTestMatcher class, changed and refactored the converter from the old base format (tod_converter). [Alexander]
object detection rate FP rate /shared/binpick/TEST/test1/cards 0.95283 0.0188679 /shared/binpick/TEST/test1/4medals 0.886792 0.132075 /shared/binpick/TEST/test1/coffee_filter 0.729167 0 /shared/binpick/TEST/test1/clogx 0.811321 0
-
Pose estimation:
- first results with the edges fitting show that edges can improve the final pose with an initial guess from tod.
- Attached are 4 images of coffee_filter, before and after the fitting algorithm, both test image projection and rviz pose.
- Fitting is done by the ICP algorithm with chamfer distance.
- We expect the method give more improvement for objects that are partly textured so that initial pose is sufficiently close to the correct one. [Ilya]
Kinect: OpenCV is supporting Kinect now! It works for Linux and Windows, there is a sample kinect_maps.cpp. We can obtain RGB image, disparity image, and a point cloud. Maria
Action Items
Gary
Alexander
Vadim
Victor
Kurt
Ethan
- Finish code stubs
James
From last time
Gary
- Write an example user contrib
Alexander
- (./) Communicate with Ethan to sync up the code:
- (./) Commit TOD changes, make sure you are using or switch to tod_core, tod_training, tod_detect (and/or switch to tod_rein when ready)
- use new kinect data
- Check pose (I think it’s probably OK with new data)
- Check miss detection — this is he main gap with TOD right now
Vadim
- (./) split cv into modules, have them put out google test compliant xml files
Victor
Kurt
Ethan
- (./) Make sure Alexander is using the correct bags
- Put tod into rein
- (./) code stub for challenge
- new pattern
- (./) LSH (Vincent)
James
- Change python scripts that convert latex to rst adding pretty print capabilities/formatting
- Will allow editing rst manually
Agenda
-
MOPED uses Bundler to create it’s 3D models
- Bundler is great code for structure from motion. It uses the “MIT license” which is ~= BSD except have to cite authors(?)
- Question for OpenCV is, since features and alignment are fundamental, we may make such a module. Do we just include code like this?
- Or, once we make our modules more independent, do we do a ROS like thing and configure CMAKE to pull such code in if the user builds modules that need the external code?
Minutes
- OpenCV is not a non-profit yet ‘’a “todo item”’‘, but this shouldn’t affect it’s khronos
- OpenCV Khronos meeting summary
- Took a high level view of joining the standard
- Everyone acknowledged that OpenCV is well known
- Some already have contracts underway to use other Khronos libraries, so liked this
- Since there is no spec, more open source, so tends to be used for prototyping more
- At NVidia discussed that refinement by committee works well, but design by committee works badly
- What level of detail do we need?
- Can’t have too much detail
- OpenCL from Apple turned up with a complete spec
- Now under refinement
- Want spec that makes it easy to put together end programs
- features2D does this
- Want more in machine learning, object recognition, classification
- Making OpenCV work better with other hardware is big
- It should work with all cameras on all systems. That would be huge.
- Want to enable hardware vendors invest in accelerated versions of the API
- The GPU module has been a parallel API, but has to be called separately
- We want the hardware to be hidden to the user, it just takes advantage of what’s there
- Do we have to address heterogeneous environments?
- Looking at homogeneous architectures first
- features2D does this
- For vision, there are still many changes going on, only agreed on functions get in
- What we can do is something like stereo — the api can be the same, but the implementation can be under the hood
- Provide hints to define what methods used
- Define the API and let people compete on implementations
- Add things like cloud computing afterwards
- Optical flow
- What we can do is something like stereo — the api can be the same, but the implementation can be under the hood
- How to create algorithms that allow a certain level of precision
- Most of the current Khronos APIs tend to be low level using accuracy and precision
- Implementation up to implementations on different hardware
- Most of the current Khronos APIs tend to be low level using accuracy and precision
- 2 levels of functions here:
- Low level can be precisely defined
- High level such as “face detection” can define the input-output
- This is what most programmers/users want to consume
- This would then drive vendors to compete to improve/make these higher levels really working
- Gesture
- Face
- Body
- Object poses
- …
- How to deal with 3D
- Standardize OpenNI(?)
- ‘’Note, OpenCV already supports OpenNI input.’’
- Standardize OpenNI(?)
-
Decisions:
- Work on document spec
- Feedback to get ready for May meeting
- Set up meeting when Victor is going to be here March. Watch out for GDC
Anatoly [GPU]
Accomplishments: 1) GPU Module · Set of device query functions are replaced with DeviceInfo class. This class wraps corresponding Cuda functions. · Minor fix in build system, now user can specify (in CMake) from what virtual architecture binary code of real architecture is built. Example, sources -> ptx_13 -> cubin_20 or sources -> ptx_11 -> cubin_20. · Added simple multi-GPU sample (it uses Cuda Driver API context management functions). Going to finish StereoBM Multi GPU sample. · Added own implementation of cv::norm function with single parameter. Now norm(A-B) is calculated via NPP, norm(A) by our implementation. Before there was NPP call with B matrix filled with zeros. But in this case there is an extra memory allocation inside the function and performance bottle neck. 2) Performance · Added 18 cases (functions for which performance is measured) to performance sample. · cv::Integral works slow. Added version of the function with external buffer (this eliminate extra memory allocation inside). Prepared independent from GPU module performance test for NPP image integrals. Speed-up is about 3x and that is suspicious. Asked Frank about this. 3) Issue with BFM + GPUComlumTest only on Quadro FX5800. · Debugged our code. Found a bug. Guess the bug is in NPP_staging. May be because of its build way. Created repro-case and send to Anton. 4) Documentation, Faq, etc. · Finished with docs. · Read all topics on OpenCV Yahoo groups. Created summary (most was a technical questions). · Prepared draft of year report (2 pages). Plans: · Finish with the BFM issue. · Victors suggestions: prepare more demo videos visual odometery, textured object detection, face detection). · Finish wiki page, faq. Search Internet about users feedback. · Finish multi-GPU StereoBM sample.
Action Items
Gary
Alexander
Vadim
Victor
Kurt
Ethan
- Finish code stubs
James
From last time
Gary
- Write an example user contrib
Alexander
- (./) Communicate with Ethan to sync up the code:
- (./) Commit TOD changes, make sure you are using or switch to tod_core, tod_training, tod_detect (and/or switch to tod_rein when ready)
- use new kinect data
- Check pose (I think it’s probably OK with new data)
- Check miss detection — this is he main gap with TOD right now
Vadim
- (./) split cv into modules, have them put out google test compliant xml files
Victor
Kurt
Ethan
- (./) Make sure Alexander is using the correct bags
- Put tod into rein
- (./) code stub for challenge
- new pattern
- (./) LSH (Vincent)
James
- Change python scripts that convert latex to rst adding pretty print capabilities/formatting
- Will allow editing rst manually
Agenda
- Some discussion on the merits/uses of foundation vs something else for OpenCV
- Khronos spec
- GSoC (end of Feb)
- Victor incoming?
-
GPU docs
- list of functions at least.
- linear time epnp using either
- http://cvlab.epfl.ch/software/EPnP/ Fua, lepetit
- They have a cvpr and ijcv paper:
- http://cvlab.epfl.ch/~lepetit/papers/lepetit_ijcv08.pdf
- oFast, rBrief report
-
TOD improvements
- Where to go next. Vincent has improved by working on LSH and making sure the bins don’t get too big (non-discriminative).
- Question is whether to have Alexander move on. We’ll need lots of other things coming up (not in any order):
- Human detection using 2D+3D — model based, parts whole. Have an intern coming in spring on this.
- Non-textured object detection. Revamping BiGG+VFH
- Transparent items
- Lighting detection
- SFS solutions(?)
- 2D pictorial bar codes.
- Can you figure out a way to watermark this??
- Articulated object detection, model based.
- Surface detection (cloth, wet, transparent …)
- Pose detection “tool box” — points based, line based, surfaces …
- Probabilistically fusing information from many sources
- In general, some higher level tools:
- Very robust face detection;
- 3D face tracking;
- hand recognition and pose
- Data training toolbox (rotating data …)
- Question is whether to have Alexander move on. We’ll need lots of other things coming up (not in any order):
- Where to go next. Vincent has improved by working on LSH and making sure the bins don’t get too big (non-discriminative).
- Test coverage
- Documentation progress
- Keyed calibration dots?
- Kinect status?
- Want a facility to calibrate a better RGB camera with kinect.
Minutes
- Khronos
- Haven’t done work on this because of test work (below) and (IROS 2011 outlet detection paper — March )
- Vadim on this on the current week
- Foundation
- Should we sync plans with PCL or just call it as another library?
- PCL has compilation issues on Windows. It uses boost, VTK
- Should we sync plans with PCL or just call it as another library?
- GSoC deadline is Feb 28-March 11
- GSoC uses
- Write more samples
- User guide and set of tutorials
- Documentation
- Write more samples
//////////wiki lost tons of notes here/////////
- oFast rBrief
- We’ve made a very fast oriented FAST detector. We’ve also discovered problems with the corner formulation of FAST (it will always get edges and almost never “ideal corners” since it cannot access interior pixel other than the center.
- We have a fix for this that should not make FAST any slower.
- We’ll be publishing this soon.
- We’ve made a very fast oriented FAST detector. We’ve also discovered problems with the corner formulation of FAST (it will always get edges and almost never “ideal corners” since it cannot access interior pixel other than the center.
- Victor will be here
Anatoly Baksheev (GPU)
Accomplishments:
1) Face Detection code. Now NPP_stagging is available as sources.
- Switched from NPP_stagging binaries to sources. Fixed lot of compilation issues under Ubuntu: Replaced VS2008-only code with cross platform, issues those are connected with advanced template techniques. Added exports (dllexport) where need.
- Integrated Anton’s tests for NPP_staging and FD to opencv test system.
- Integrated Anton’s FD API sample.
- Not tested under Ubuntu yet (so temporary disabled under Ubuntu).
2) Documentation.
- Added functionality list to the wiki page. Added FAQ page.
- Added itseez channel with videos for GPU. (http://www.youtube.com/user/Itseez). Now there are HOG, FD, Visual Odometry (mixed CPU+GPU) and SteremBM videos. Textured Object Detection (TOD) video from ROS is delayed due to an issue found in SURF (supports only 4 levels).
- Fixed latex2sphinx GPU docs building bug
3) The issue with BFM + NPP Staging transpose on Quadro.
- Reproduced with NPP_Stagging sources build by us. NSight reports access violations. Send repro-case to Anton.
4) Spend some time for Textured Object Detection (TOD) to create demo video for it.
- Replaced SURF implementation in the ROS pipeline. Met a problem SURF does not find features. We guess that is because of limitation: SURF GPU supports only 4 levels, but there are 5Mpix dataset. Need to write one special kernel for that case.
- solvePNP is on CPU because it is not implemented on GPU (but good speed-up expected).
- Found bug in SURF on GPUs with CC < 1.# Investigating.
5) Tests & samples
- Added stereo_multi_gpu sample.
- Updated performance sample (added norm, erode, cvtColor), small fix in BFM performance test.
- Fixed minMax, resize, warpAffine, and warpPerspective tests. Before the tests did not pass due to different interpolation precision on GPU and CPU. Now byte-wise check is replaced with less strong check.
Plans:
- Test FD under Ubuntu. Investigate issue #865 reported by a user (GPU FD example slower than before)
- Work with TOD. Investigate bug #866 (SURF for old cards).
* - You can see Youtube videos of OpenCV+GPU.
- You can read here OpenCV GPU doc page.
Action Items
Gary
Alexander
Vadim
Victor
Kurt
Ethan
- Finish code stubs
James
From last time
Gary
Alexander
Vadim
Victor
Kurt
Ethan
- Finish code stubs
James
Agenda
- TOD
- Android slimed down set for OpenCV
- Khronos spec
- POSE estimation
Minutes
- Android
- We’ll meld the spec of Khronos with Android. Slimmed down functionality that supports mobile
- Need different scenarios
- Smallest set … what it enables
- Next larger set … what it enables
- …
- Then we’ll go back with the Android team and iterate with them about what makes sense as the best trade off of size and functionality
- This is high priority
- Need different scenarios
- I will have to figure out the OpenCV foundation or separate entity stuff
- We’ll meld the spec of Khronos with Android. Slimmed down functionality that supports mobile
-
GPU
- We’d like to move to OpenCL as it gets mature. At the time the project started, it was not capable enough
- The OpenCL compiler is still under development
- Very hard to say how to write efficiently in OpenCL when we can’t really do the experiments NVidia & ATI yet
- The OpenCL compiler is still under development
- We’d like to move to OpenCL as it gets mature. At the time the project started, it was not capable enough
-
TOD
- Victor and Alexander Could compile the packages on the wiki
- rBrief works better on kinect than SIFT/SURF etc. Why? We don’t know.
- Need to do scaling studies, low vs high resolution
- Issues of scaling to many objects … previously, feature bins get too general.
- Now that the pipeline is working, we can start trying these experiments
- One problem we’ve found is that feature points that are actually on an edge are not descriminative
- This is a problem from FAST — it picks up edges (for us)
- We adaptively find “enough” features by lowering the fast threshold. This picks up edge points which are not discriminative as a feature point.
- This is a problem from FAST — it picks up edges (for us)
- So, we’ll probably need to add in a heuristic in FAST that gets rid of edges … this shouldn’t slow down FAST much since it is only at the points it actually selects that are finally filtered.
- Pose estimation package
- Kurt sent an alternative to RANSAC for pose. It’s written for stereo but may generalize
- How much time is spent in RANSAC? With small number of inliers … it can fail
- Currently pose estimation is in “calib 3D”
- Probably need a summary of what is in each package
- specs for pose estimation
- If you have 2 point clouds that have > 1 object, it’s ambiguous
- Different cases
- If you have 2 point clouds that have > 1 object, it’s ambiguous
- Need frameworks
- Higher level functionality
Vadim
- The work on the tests conversion to google test framework has been finished (except for opencv_gpu tests, which will be converted by the GPU team). All the tests, except for couple of tests in features2d, pass successfully. Several bugs have been fixed in order to build and run the tests on Ubuntu and Windows OSes.
- Started the work on the API specs for the OpenCV standard. It includes the headers, containing a subset of OpenCV functionality, plus Sphinx-generated PDF with the API description. The current version of the headers and the PDF has been sent out.
Plans for this week:
- spend a few days on the critical and major bug reports, submitted in a few last weeks.
- continue the work on the standard.
- start the work on splitting OpenCV documentation by modules.
Victor
Pose estimation: used NLopt library for optimization in pose estimation. The DIRECT algorithm has shown good results. The attachments show the initial pose obtained by tod on coffee_filter when we allow pose estimation from a small textured area, and the final result by DIRECT followed by LM-ICP optimization. The improvement is substantial even when the initial guess is far from the ground truth (LM alone was not able to solve cases like this correctly). [Ilya] Circle pattern detector: tests for detection and pose estimation of circles and chessboard patterns were done. The pattern was fixed with regard to the camera, and we were varying the lighting (an example pattern is attached). The detection rate for circle detector was ~98%, for chessboard (same size) -- around 55% (low resolution chessboard detector from pr2_plugs stack was used to detect the checkerboard pattern). The poses should have not depended on lighting so a variation in pose gives an estimation of errors. We calculated covariance matrices of rotation and translation and compared the largest eigenvalues (that correspond to the largest variance along the corresponding direction). The results are in the table below. One can see that circle pattern gives much lower variance in translation, probably due to higher accuracy for detecting circle centers. [Ilya] tvec largest eigenvalue normalized rvec largest eigenvalue angle variance Circles 0.05 # 4e-11 1.1e-05 Chessboard 0.29 # 9e-10 # 3e-05 moped: compared tod with moped by implementing a converter from tod training base to moped format and another converter to parse moped log files for compatibility with tod training system. [*Maria*] tod: unifying tow methods in tod_detecting (removed all macros, single base format, now one can choose between TODRecognizer and KinectRecognizer -- the support for rBrief in the former is on the way). [Alexander]
Action Items
Gary
- Get name of Android vision lead to Victor. We might be able to do a first discussion next week
- Create first draft of mobile functionality list.
Alexander
Vadim
Victor
Kurt
Ethan
- Finish code stubs
James
From last time
Gary
Alexander
Vadim
Victor
Kurt
Ethan
- Finish code stubs
James
Agenda
- Homography request, not sure if valid
- OpenCV on Android
- Google interest
- Can we just make a slimmed down set of core functionality?
- Want to support (right now I’m ignoring what should be front side phone/pad and what should be backside server …)
- AR, which means tracking, homography
- VSLAM (for eventual 3D reconstruction, but for right now, model capture)
- Object recognition
- TOD, BiGG …)
- Text rec. Google does a good job, iPhone app is better. Probably on the phone we want feature extraction support.
- Camera enhancement (stabilization, rectification, multi-view, dynamic range via burst mode …)
- Computational photography support
- Want to support (right now I’m ignoring what should be front side phone/pad and what should be backside server …)
Minutes
- Can you find homography from 3 points if you have focal length
- This is a pnp solution problem, think it always needs 4 points
- 6 unknowns, but not unique for just 3 points
- This is a pnp solution problem, think it always needs 4 points
- OpenCV on Android
- How to make vision on android easier
- Linking against private library is only good for internal demos
- Soon, there should be a public API for native access to the camera so that you don’t have to go through Java
- Android experimental branch
- Victor in CA right now
Vadim [now working on infrastructure/software engineering]
- The initial work on the conversion of OpenCV documentation to RST has been done.
- Added “refman” target to the OpenCV CMake build scripts. It builds opencv.pdf out of rst sources.
- Sphinx and Latex are being detected at the configure stage.
- All the RST files (C++ part only for now), automatically generated by James’ scripts from .tex sources, have been moved to the corresponding modules, e.g. opencv/doc/latex2sphinx/cpp/core_*.rst moved to opencv/modules/core/doc/*.rst.
- Closed 14 tickets at code.ros.org/trac/opencv: ## 833, 838, 852, 855, 880, 884, 885, 889, 891, 893, 896, 900, 911, 912
Plans for this week:
- continue to clean the bug tracker. try to merge the # 2-related fixes to our OpenCV # 2 branch.
- clean up, reformat the integrated RST files. think of adding C & Python parts.
- continue the work on the standard.
Victor [now working on TOD, Pose, …]
TOD: measurements of descriptors precision-recall curves show that SURF gives more correct matches compared to RBRIEF on images from prosilica, but on kinect images RBRIEF is better. The difference is not in resolution only: attached is an PR curve on a prosilica image resized down to 2MP, showing SURF being better than RBRIEF. Maybe the problem is in using a wrong Bayer filter that gives a poor quality image causing high variation in SURF descriptors. Experiments with collecting data on kinect are on the way. [Alexander, Maria] Pose estimation toolkit: Alexander is looking at the paper after finishing work on tod. He will start implementing the Howard's algorithm this week. MOPED: MOPED on MOPED data works well (12 obects, SIFT detector and descriptor (SiftGPU library), test resolution 1280x720) with hard coded parameters - see moped_origin_data.png. On TOD data (where TOD has good detection rate) MOPED does not work (43 objects, SURF detector and descriptor (OpenCV), train and test resolution 2448x2050) - see moped_tod_data.png. I can run MOPED on TOD data using SURF only, but I tried to vary all other algorithm parameters (of detector and descriptor, clustering, matching). The main reason for bad results on TOD base is a small number of "good" matches. Seems that detection rate of MOPED (and possibly of other such approaches) is sensitive to the data (image resolution, quality...). [*Maria*] DOT: Started to play with fast_template_detector package that implements DOT. A simple experiment was done: templates of yellow cup were learned and the detection on the same object was run. Preliminary results show that: 1) If the background is the same as the one used for training the yellow cup is detected. But if the background is different the yellow cup is not detected; 2) A blue cup of the same shape is not detected on the background used in training; 3) Seems that fast_template_detector is not multi scale. [*Maria*] Pose estimation: an infrastructure for evaluating pose estimation algorithms has been implemented. The current algorithm that refines pose from tod using chamfer matching gives good results on a subset of objects. Below is a tables of average errors of tod pose (first line) and refined pose (second line). However the algorithm is still sensitive to initial pose from tod. [Ilya] Other: Victor gave a talk in Saint-Petersburg computer science club on vision for robotics (2 hours), opencv (1.5 hours) and led a practice session (3 hours). More than 50 participants from different SpB universities, a lot of interest in vision and opencv. SpB computer science club http://logic.pdmi.ras.ru/csclub/en/ is a non-profit financed by several individuals that invites speakers to give talks on modern problems of computer science. Pose estimation errors of tod pose (first line) and refined pose (second line), the first column is a Hausdorff distance between a test point cloud and a train point cloud rotated to test reference frame: Hausdorff (cm*) rot. angle (deg) rot. axis (deg) translation (cm*) 4medals 10.79 1# 57 -- 1# 63 0.73 1.63 0.41 0.86 avocado_slicer 10.79 1# 57 -- 1# 63 0.73 1.63 0.41 0.86 can_opener 9.91 2# 52 -- 11.65 0.72 1.08 0.22 0.83 coffee_filter 10.78 2# 84 -- 1# 34 0.63 1.98 0.25 0.99 corkscrew_b 10.50 2# 12 -- 11.98 0.69 1.46 0.22 1.01 drain_stopper 10.16 2# 32 -- 1# 00 0.51 0.80 0.16 0.67
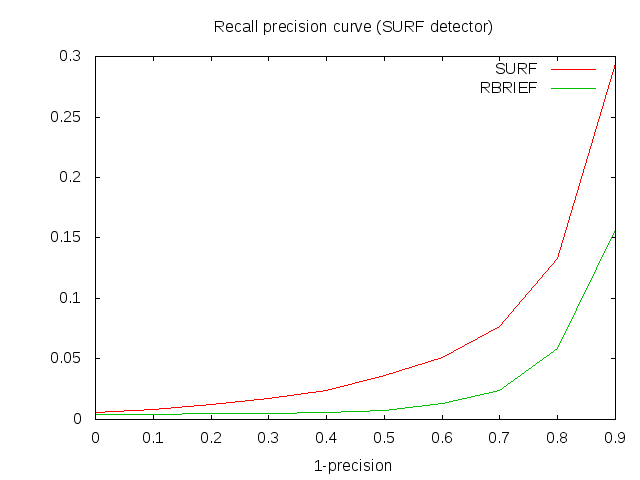
- SURF vs BRIEF for Prosilica camera (results are quite reversed on kinect, not completely sure why yet)
- !moped_origin_data.png| Example of Textured Object Detection!
- Matching results with bag of words => geometric constraint
Anatoly [GPU]
Accomplishments & Activities: 1) OpenCV GPU module ** Ported all GPU tests to GTest as it has already done for all other modules. ** Applied patch to NPP_stagging transpose from Anton. (I suggested him requesting commit rights to update his code without my mediation). ** Added dataset to OpenCV test data repository for some Anton's tests and updated test code so it can find the data. Now all these tests are executed entirely. 2) SURF & Textured Object Detection (TOD). ** We replaced SURF to GPU implementation and did experiments. - TOD pipeline did not find objects until we regenerated objects database by SURF_GPU (before it was saved from SURF on CPU). But now there is still less detected objects than with SURF on CPU. Less objects number speed-ups farther processing. So it will be incorrect to compare CPU/GPU performance (total speed-up is # 5x for Quadro) until behavior is the same. Our guess is because of SURF results difference on GPU & CPU. - We did not pay attention for the small variation on our test images, but it seems important for this pipeline. Now we are investigating why the differences are. Will try to reach behavior similarity because it makes easier to switch implementations. ** Started work on solvePnP (RANSAC version) function used in the pipeline (30% of total time). This function computes object position from its 2D-3D point correspondences. - Implemented projectPoint and transformPoints functions that are called inside. All other parts are computed on CPU. - Thinking of super-optimized version of solvePnP_Ransac that does whole work on GPU, but unsure if possible need to solve equations efficiently within thread block. Plans: · Continue work with TOD & SURF.
Action Items
Gary
- Create first draft of mobile functionality list.
Alexander
Vadim
Victor
Kurt
Ethan
- Finish code stubs
James
From last time
Gary
- (./) Get name of Android vision lead to Victor. We might be able to do a first discussion next week
Alexander
Vadim
Victor
Kurt
Ethan
- (./) Finish code stubs
James
Agenda
- This meeting will be very short. Victor is still traveling and Gary and Ethan are on a 30 hour sleepless push to get a new paper out to ICCV.
- The main on going work is
- Vadim’s continual improvement of OpenCV infrastructure, now getting the documentation system in good shape.
- Our efforts to put together a core function set for OpenCV Khronos proposal
- This is pretty much the exact same list for Android
- Work on developing a mature pose estimation and refinement toolbox
Minutes
Gary
- Oriented FAST with Rotational BREIF. Ethan, Vincent, Kurt and myself have been working on this for some time and are writing it up. We’ve found ways to de-correlate the feature’s elements and also how to improve FAST’s corner detection using techniques from Harris.
- We believe at this point that this feature has the potential to simply replace almost all other interest point detector descriptors. It is 100x faster than SIFT (10x) and works better than both on fairly extensive tests in tracking, stitching and recognition.
Vadim
- Started work on cleaning up the documentation.
- Using a simple script the RST files have been reformatted to get a better look and have been further polished a bit.
- >300 errors and warnings from Sphinx have been fixed.
- Many cross-references have been fixed too.
- Closed 3 trac tickets: ## 852, 882, 921 + fixed the bug with duplicated SIFT keypoints, reported by e-mail.
Plans for this week:
- continue to clean the bug tracker. try to merge the # 2-related fixes to our OpenCV # 2 branch.
- further documentation improvements.
- continue the work on the standard.
- resume the work on the migration to Hudson.
Victor
-
TOD:
- recognition statistics on TOD collected depending on resolution. We see there is a strong dependence of tod parameters on resolution.
- Two graphs attached showing the dependence of detection rate on resolution in megapixels with a single set of parameters (detrate.png) and parameters adjusted for resolution (detrateImproved.png).
- The parameters we decrease with resolution are cluster threshold for hierarchical algorithm, minimum cluster size, minimum inliers count, re-projection error (for inlier definition). [Alexander]
-
Registration:
- Implement the first version of Howard’s method. See matches.png, filteredMatches.png. On these images there are about 1500 features on every image (after filtering, ie each keypoint have corresponding 3d point).
- The size of the maximum clique is 14 from 502 matches.
- Now we try to adjust the parameters of the algorithm for newcollege data (detector, image filtering, distance threshold, descriptor size). Also we want to try Hirschmuller version with two constraint and adaptive distance threshold. [Alexander]
-
DOT:(is not TOD!, This is a gradient grid detector similar to Gary’s BiGG)
- Made experiments with different objects of Willow base (640×480) using fast_template_detector.
- A detector for one object on rotating table was trained.
- It detects the object on almost all frames of train bag-file. The detection on test data depends a lot on algorithm parameters, more time is needed to analyze the results we get. Maria
-
Pose estimation:
- The algorithm has been improved by using frame registration to get a 3d model of edges from different train images and filtering points in the 3d model by density to remove instable edges. This has improved the averaged ratio of successful refinements of pose [Ilya]:
Old ratio New ratio
4medals 0.11 0.28
avocado_slicer 0.02 0.06
can_opener 0.09 0.14
coffee_filter 0.08 0.19
corkscrew_b 0.17 0.49
drain_stopper 0.23 0.44
- The algorithm has been improved by using frame registration to get a 3d model of edges from different train images and filtering points in the 3d model by density to remove instable edges. This has improved the averaged ratio of successful refinements of pose [Ilya]:
Action Items
Gary
- Get name of Android vision lead to Victor. We might be able to do a first discussion next week
- Create first draft of mobile functionality list.
Alexander
Vadim
Victor
Kurt
Ethan
- Finish code stubs
James
From last time
Gary
Alexander
Vadim
Victor
Kurt
Ethan
- Finish code stubs
James
Agenda
NOTE: This meeting will be held on Thursday instead of Tuesday
Sigh. We can’t find a time to all meet this week, skip to next Tuesday
Meeting occurred Tue., March 15, 2011
- CvMLData not documented at all
- LatentSVM not documented
- HighGUI using QT tutorial …
-
GSoC OpenCV application
- GSoC application site is at http://www.google-melange.com/gsoc/org_app/take/gsoc_program/google/gsoc2011/orgapp. Due March 1# Notification March 18th.
- Need to spec projects.
- Can we summarize action to take from the long email thread ’’opencv proposal for khronos meeting notes_?
- What’s next on the Khronos spec. In many ways, I also think that high level APIs can be more useful than low … and programers want to consume vision apps at a high level as contrasted to vision PhD’s who want low level.
- We need to get an answer for Android apps back to Google.
- I have some fairly clear ideas on this: Some android apps such as VR that would also serve as stub code for other developers to use as advanced starting points for vision apps on the phone. Do this in several key areas.
- Machine learning of sparse feature banks. Andrew Ng’s work. Should we consider implementing (great on GPU … or cluster)
- Sparse Autoencoders http://www.stanford.edu/class/cs294a/handouts.html ?
- When can we get a tech writer going?
Minutes
-
GSOC: Gary submitted our application on March 8
- We’ve improved the project page http://opencv.willowgarage.com/wiki/GSOC_OpenCV2011
- We’ve already been getting many email inquires already, though we won’t know if Opencv is in until next week.
- Gary giving a Kinect + opencv tutorial. Material for this is in opencv_user.pdf
- Machine Learning
- Alexi is writing documentation on
- LatentSVM not documented
- CvMLData not documented at all, Victor might take
- Alexi is writing documentation on
- QT interface
- Fairly easy to use, will use it in a machine learning
- slots, callbacks, signals such as mouse — assign slots to signals
- HighGUI docs fairly simple
- There is sample code for this *…/opencv/sample/cpp/Qt_sample *
- Ethan and Troy are working on a graph based object recognition infrastructure
- Build in python, can do it programatically or graphically.
- Attach visualization on the fly, set parameters on the fly
- In the end, it outputs in C++ so the whole thing can be compiled and run in C++
- Q on loops and conditionals
- Build in python, can do it programatically or graphically.
- Interns working on object recognition. Need at end:
- sample of usage
- test code with known results that we can reproduce
- differences from papers
- documentation of how to use
- documentation of where it works and where it doesn’t
-
DOT (for texture-less objects)
- Unstable results because code implemented here is different. Contacting Stephan about this
- Have to decide what we want in.
- BiGG could scale for matching since we did that hierarchically
- DOT is probably faster per template
- These things should be put in LSH framework which, by the way
- LHS
-
TOD is finding objects well
- factor ID from pose
- Then use a pose estimation toolbox
- Pose toolbox
- Khronos application
- Have to decide on scope of this standard
- Maybe we should create part of opencv that can be easily accelerated in parallel
- Still a large subset of OpenCV
- Many expensive functions can be put there given GPU and multi-core.
- Array types should be native to the fast side (GPU mat)
- Hook up with PCL sooner not later on data types
- Image processing?
- Reference implementation of all of opencv will be there for standard stuff and for experimental
- The parallelizable stuff is in the khronos standard
- Start with the GPU implementation as standard
- OpenCL is an influence for us on this
- Vadim to work on this this week.
- Have to get back to Google on Android apps. How much does the khronos spec intersect with what should be on Android?
- All the things in the spec will end up getting super fast on mobile next gen.
- Tech writer
- We have a tech writer who has (preliminarily) agreed to start working on the documentation
- Grammer and style will be gone over first
- We have a tech writer who has (preliminarily) agreed to start working on the documentation
Vadim
- Converted to RST OpenCV 1.x C & Python reference manual.
- Now there are 2 PDFs: opencv1x.pdf that describes C & Python API (as 2 different parts), and opencv.pdf that describes OpenCV # x C++ API.
- Python bindings for OpenCV # x API are not documented yet.
- Fixed the remaining errors and warnings during opencv.pdf generation. Still, there are quite a few broken hyperlinks and places with bad formatting.
- Have preliminary agreement with the experienced technical writer who will improve OpenCV reference manual.
- Did some cleanups and optimizations of the core module.
- Added support of the mixed array data types to the basic functions, like cv:add() (e.g. cv::add(src1_8u, src2_8s, dst_16s)).
- Prepared two proposals for the GSoC 2011: OpenCV+OpenCL and Python samples.
Plans for this week:
- Work on the Khronos draft
- continue to clean the bug tracker.
- resume the work on the standard draft.
Victor
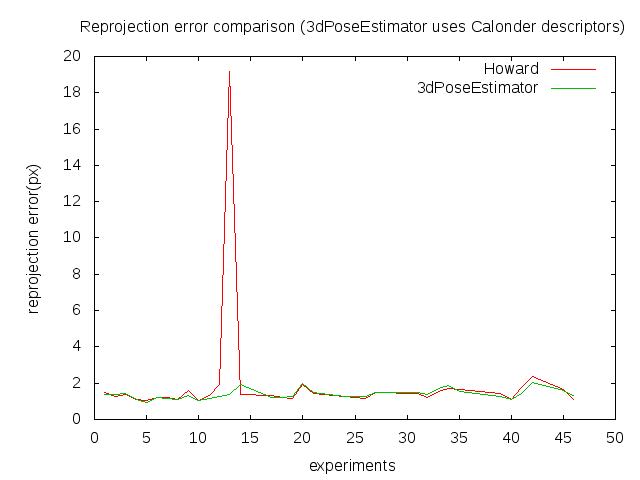
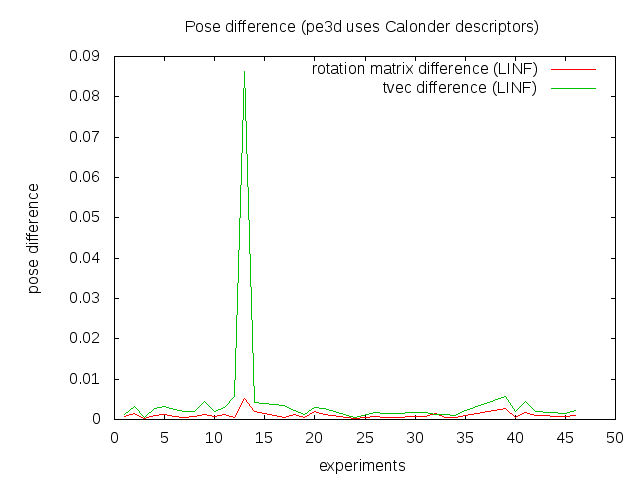
Hudson: Andrey Morozov has started to work on this from March 1# He has learned how to create a build job of an svn revision but met many problems with cmake and multi-configuration builds. Pose estimation: fixed several bugs in Howard's algorithm. The results have been compared to pe3d. Methods generally give the same results, but Howard's method sometimes gives larger reprojection error (see the charts attached). Investigation is on the way. [Alexander] TOD: experiments with running solvePnP initialization on each ransac step instead of full LM optimization showed worse accuracy because initialized pose is very far from the LM optimized result. A large set of experiments on varying detector threshold showed that accuracy on 1MP resolution (prosilica data) does not depend on detector threshold. This is different from the first implementation of tod that we tested on VGA resolution. Accuracies on 5MP and 1MP are shown in the table below. [Alexander] Object 5MP Det. rate FP rate /shared/binpick/TEST/test1/cards 0.971698 0.00943396 /shared/binpick/TEST/test1/4medals 0.886792 0.0943396 /shared/binpick/TEST/test1/coffee_filter 0.666667 0 /shared/binpick/TEST/test1/clogx 0.792453 0.00943396 Object 1MP /shared/binpick/TEST2mp/test1/cards 0.603774 0.00943396 /shared/binpick/TEST2mp/test1/4medals 0.745283 0.0566038 /shared/binpick/TEST2mp/test1/coffee_filter 0.135417 0 /shared/binpick/TEST2mp/test1/clogx 0.283019 0 DOT: Implemented a sample to test fast_template_detector on TOD datasets. Fixed fast_template_detector training to use masked train data. But most objects are not detected on test bags. I think there are at least 2 reasons of this: fast_template_detector implementation is not invariant to small translations (to the contrary with DOT described in the paper), fast_template_detector is not multi-scale. I asked about this on ros-users http://code.ros.org/lurker/message/20110311.171629.40285f18.en.html, but there is not answer yet. Found original DOT implementation of Hinterstoisser (LGPL licensed). This code is based on IPP, SSE and has been tested by Hinterstoisser under win32 only. Solved memory problem (segmentation fault) of Hinterstoisser's DOT under my ubuntu6# Started experimented with this DOT (see screenshort1.png and screenshot# png attached). A sample to test Hinterstoisser's DOT on TOD dataset is in progress. [*Maria*] Pose refinement with edges: implemented an algorithm for computing a single edge from multiple edges that come from different registered frames. initialClouds.png shows a set of 3D points corresponding to edges that come from different frames, projected into one of the frames, edgeModel.png shows the final result. The initial model consists of 86K points, the final model -- about 5K. This significantly speeds up the pose refinement using edges as the cost function is computed by projecting these 3D points into an image. The algorithm uses an approximate solution to K-partite matching problem. [Ilya]
-
- DOT Experiments:




Anatoly (GPU)
Accomplishments: 1) Cuda # 0 · Leaned all changes. · Investigating link errors for VS2008 with multiple definitions of stuff from C++ Runtime Library. Still don't know why all is ok with Cuda# 2, but not with Cuda# 0. 2) SURF & TOD · Made SURF_GPU more consistent with CPU one and integrated it to OpenCV. Some optimization of SURF_GPU. · Results are not 100% similar with CPU version, but TOD work as with pure CPU implementation, i.e. sets of detected objects are the same. We decided to stop. There is a compromise between performance and similarity. · Performance for Core 2 Duo 3Ghz / Quadro FX5800: o SURF_GPU performance is 2x slower than before o TOD performance is 2x faster than pure CPU implementation. (# 5x for old SURF_GPU, but less number of detected objects). Pure CPU version solvePnP was used, because of bad speed-up at current stage. · Going to test it on Core i7 + C2050 and create TOD demo video. Guess, we will need to recreate the video, if we have GPU-optimized version solvePnP with good speed-up. 3) Image stitching currently only CPU implementation and research. · Implemented two images blending algorithm via feathering. · Implemented simple two image stitching (SURF based). · Many image stitching is in progress. Farther research is also in progress. There are a lot of things to study (many image stitching, better blending algorithms, intensity correction etc.). · Late will think what and how to port on GPU. Some parts in image stitching are close to solvePnP problem. We will consult with James when we will be ready. Plasn: · Create video for TOD · Continue studing stitching · Continue work with CUDA# 0. May be switch to it if stable (and stop Cuda# 2 support).
Action Items
Gary
- Send Victor BiGG code
- Sync up on data structures pcl+opencv
- Talk with Ethan on panos and other Android implementations
Radu
- Sync up on data structures pcl+opencv
Alexander
Vadim
- Work on Khronos
Victor
Kurt
Ethan
- Finish code stubs
James
From last time
Gary
Alexander
Vadim
Victor
Kurt
Ethan
James
Agenda
- Put in issues for next meeting …
- If we are accepted in GSoC, what adjustments to projects do we want?
- Ethan+Troy’s python=>graphical interface
- Working with PCL, numpy etc
- Example code, many applicants, what do we want?
- Need to prioritize bugs to fix each meeting
- Vincent suggested issues: ideas specific to feature extraction / nearest neighbor :
- identify the use of the currently existing lsh.cpp in OpenCV and see if Vincent needs to integrate his in FLANN asap.
- only use one implementation of distances through OpenCV, an SSE/Neon optimized one that should probably be the templated version of FLANN (for the API at least, otherwise the implemntation needs to be sped up). Right now, we have Euclidean stuff all over, Hamming in brief.cpp, miscellaneous ones in FLANN
- merge the kdtree.cpp and the one in FLANN
- is FLANN using its own kmeans ? If so, that should be merged too. Basically, if we are serious in including FLANN and maintaining it after Marius is done with it, OpenCV should use it as much as possible.
- include James’ LBP (local binary pattern) implementation in OpenCV
- create a feature2d object that would do feature AND descriptor detection at the same time, thus removing duplicate computations (e.g., in ORB we do
feature and descriptor at different scales: we don’t recompute the resizing of the image for each, we use a common one; Other example, in SIFT, prepareGrad is called both in Sift::computeKeypointDescriptor and in Sift::computeKeypointOrientations during the feature extraction phase)
Minutes
- Tutorials
- Make simple boot up
- Kurt had trouble with calibrate, he didn’t find the sample
- Make simple boot up
- Python→graphical interface being worked on
- — really need better documentation for methods:
- how they differ from published paper
- limitations such as not multi-scale
- Should come with a simple train-test sets with expected results
- — really need better documentation for methods:
- SIFT: Was excluded form Android because the code didn’t build
-
FLANN
- Distance compuation: Euclidian, L1 duplicate computations
- Vincent’s LSH vs OpenCV’s version
- Does this go into OpenCV or FLANN
- How do we make sure FLANN stays up to date with LSH
- Distance compuation: Euclidian, L1 duplicate computations
- James developed LBP “Local Binary Pattern”
- It is in OpenCV for faces, why not in general
- Victor will ask Marie about LBP, why wasn’t it generalized
- Easy to add features to cascade classifier — it is easy to add features, but they are coded differently
- Linear time PnP, LePetit’s algorithm — should converge within a month but LePetit has just posted C++ source code
- Bugs
- Might periodically declare bug hackathon week to clear out
Vadim
Hello, # (Documentation) Tech writer started proof-reading of the reference manual. [Elena] # (Hudson/Buildbot) Experiments with Hudson are going on. Because of the certain problems (i.e. CMake + "matrix-type project" cooperation; difficulty with inserting hooks before SVN checkouts; difficulty with interactions with VMWare Fusion client OSes) Alexander and Andrey now consider getting back to Buildbot, at least as a temporary solution to recover nightly testing as fast as possible. [Alexander & Andrey] # (DOT for TOD) Added mask support during the training phase to Hinterstoisser's DOT implementation. Tested it on TOD dataset - the results are similar to original version. Hinterstoisser's DOT (as fast_template_detector) is not multi-scale, so I tested it on train images. It detects the objects quite well on train images (hit.png), but misses objects, mostly if they are more texture-less (miss.png). Also got some information about the implementation details from Stefan Holzer. The group by Stefano Fabri (Univ. of Rome) is also working on DOT. There is possible collaboration on improving the algorithm [*Maria*] # (Pose estimation for TOD) Improved multi-view registration by increasing robustness to outliers. Created and implemented new algorithm for edge model construction by synthesizing ideas of robust statistics and k-partite matching. Images are attached. Experimented on the binpick dataset: Hausdorff (cm*) rot. angle (deg) rot. axis (deg) translation (cm*) avocado_slicer 9.88 1# 86 -- 1# 06 0.72 # 28 0.40 0.63 coffee_filter 8.66 29.22 -- 1# 29 1.00 0.69 0.11 0.31 corkscrew_b 9.13 21.77 -- 11.69 0.69 0.35 0.09 0.53 drain_stopper 10.26 31.05 -- 1# 65 0.44 0.41 0.03 0.28 Evaluated performance of the algorithm: Object Mean refinement time (s) avocado_slicer 30.19 coffee_filter 68.26 corkscrew_b 4# 90 drain_stopper 6# 65 [Ilya] # (TOD on GPU) Created TOD demo (CPU vs GPU) with NVidia team. It's aploaded to our youtube channel (http://www.youtube.com/itseez#p/a/u/0/WnHjuKJvUsk) [Alexander] # (OpenCV standard) No significant documents update; mostly studying OpenCV CUDA module and the OpenCL capabilities, gathering all the pieces together: - Author of the ViennaCL (with permissive for us MIT license), Karl Rupp, contacted me and offered help in porting ViennaCL part that wrapps OpenCL buffers, kernels, context objects etc. into convenient C++ classes. - Image Algebra (http://www.cise.ufl.edu/~jnw/CVAIIA/) approach is probably the way to go for basic interface that we can provide. If so, the OpenCV standard can actually be some high-level component on top of OpenCL. From high-level vectorized notation of the algorithms it will produce OpenCL code. It is quite feasible to do for image processing part. Some complex algorithms, like stereo correspondence, may require custom kernels though. [*Vadim*]
Victor
3d<->3d pose estimation: a posest::PoseEstimator wrapper for Howard's algorithm has been implemented. A test run on new_college sequence shows some issues (see attached trajectory.png). [Alexander] Pose refinement: The edge registration algorithm has become more robust to outliers. The results on binpick dataset are shown in a table below (first line is TOD pose, second is TOD+pose refinement, numbers are errors of different pose parameters). The running time is 30-60 seconds per frame as opposed to several minutes for the algorithm with no edge registration. [Ilya] Hausdorff (cm*) rot. angle (deg) rot. axis (deg) translation (cm*) avocado_slicer 9.88 1# 86 -- 1# 06 0.72 # 28 0.40 0.63 coffee_filter 8.66 29.22 -- 1# 29 1.00 0.69 0.11 0.31 corkscrew_b 9.13 21.77 -- 11.69 0.69 0.35 0.09 0.53 drain_stopper 10.26 31.05 -- 1# 65 0.44 0.41 0.03 0.28 TOD: a demo of running TOD on GPU has been created together with CUDA team http://www.youtube.com/itseez#p/a/u/0/WnHjuKJvUsk. [Alexander] DOT: experimented with Hinterstoisser's implementation of DOT. The support for training masks has been added (it is in the paper, but not in the code). The results are still very sensitive to clutter, the system recognizes an object in a training image (see attached hit.png), but misses it in a similar test image (miss.png). Some time was also spent on understanding what's inside fast_template_detector package in object_recognition stack, exchanging emails with the author, Stefan Holtzer. It is not multi-scale but is invariant to small offsets. [*Maria*] In general, the impression is that the technique is premature to be used standalone for textureless objects, we probably need to combine it with 3D features such as VFH. Other: Alexander was on a sick leave March 16-21.
Anatoly Baksheev (GPU)
Accomplishments: 1) Cuda# 0 · Finished build problems investigation and created repro-case. Submitted bug id 803928: Link error for VS2008 + Cuda# 0 + /MD . Waiting fix or comments from NVidia support. · Finding out how to use Cuda# 0 + VS2010 + OpenCV. 2) TOD & SURF_GPI · Fixed compilation issues for on CC # 0. · Added upright parameter to SURF_GPU (ticket #945); · Tested on Core i7 960 @ # 2GHz + GTX470. Speed-up is from 2x to 6x. Created a demo video (http://www.youtube.com/watch?v=WnHjuKJvUsk&feature=channel_video_title). Possibly in future will update the video if we have faster solvePnPRansac on GPU. 3) Image stitching · Still learning stitching theory and previous work. · Implemented multi-band blending (some examples are attached). It seems to be better than simple feathering, but also suffers from intensity differences. Started implementation of gradient domain based blending methods. Plans: · Docs improvement togeather with technical writer. · Continue work with stitching. · Cuda# 0 + VS2010. In sandbox, not in SVN.
-
TOD: a demo of running TOD on GPU has been created together with CUDA team:
- http://www.youtube.com/itseez#p/a/u/0/WnHjuKJvUsk. [Alexander]

- Multi-band image stitching examples
Action Items
Gary
Radu
Alexander
Vadim
Victor
- Ask Marie about LBP for features 2D
Kurt
Ethan
James
From last time
Gary
- Send Victor BiGG code
- Sync up on data structures pcl+opencv
- Talk with Ethan on panos and other Android implementations
Radu
- Sync up on data structures pcl+opencv
Alexander
Vadim
- Work on Khronos
Victor
Kurt
Ethan
- (./) Finish code stubs for TOD
James
Agenda
- TOD
- Pose finding/refinement
- DOT and extensions of the DOT idea
- GSOC
Minutes
-
TOD
- Pose estimator
- Howard’s algorithm
- If you have stereo on each frame, then instead of Ransac, you can get a 3D pair of points from different frames matched using descriptors
- Calc distance frame 1, Calc distance frame 2 If distance is different, these pairs are inconsistant
- Then construct graph between matches with edges of distances
- A maximal clique on the graph is a set of points that are probably consistent.
- Then use this to find pose
- Method was implemented, but problem putting it inside pose est pe3d, but results are worse because SBA works differently and so get problems with place recognition.
- For 3D model fitting
- Ilya’s method: global optimization done by nlopt, followed by LM optimization. If you start with random pose, then in 10-50% will find significant improvement.
- Takes a few seconds
- Howard’s algorithm
- Kinect 2D image is very noisy
- Detector repeatability is bad in VGA mode
- Lowering thresholds helps
- Detector repeatability is bad in VGA mode
-
DOT
- Started with Holtzer’s DOT in obj recognition stack.
- Added multiscaling
- Simplified the code (but slower)
- Tried Stephan Hinterstoisser’s code. Works better, but doesn’t have masks but hard to read because of SSE but code is LGPL so can’t go into OpenCV
- Maria implemented a reference version of DOT to play with
- Working
- Started with Holtzer’s DOT in obj recognition stack.
- Pose estimator
- Tech writer
- Nearly finished on opencv-gpu grammar check and style
- Hope that she can also catch semantic bugs
- Nearly finished on opencv-gpu grammar check and style
- Dot calibration pattern — send images that don’t work to Ilya
- New neural net training now parallelized with error prop. Sample code (letter_recognition)
- OpenCL implementation as proposed parallelizable core of OpenCV for Khronos
- Need to find subset of operations that can be vectorized on which many other algorithms can be used
- GSoC
- Top priorities are probably iOS port and examples
- Java interface for Android
Vadim
# (Documentation) Merged the revised by tech writer manual on opencv-gpu to trunk. # (User Contributions) Integrated patch for parallel neural net training (error prop using TBB -- Intel threading library) by Konstantin Krivyakin * backprop is difficult to parallelize but error prop can be parallized since all samples are processed at once # (OpenCV standard; OpenCL) Created stub for the experimental module for opencl optimization. That includes CMake scripts and the new empty module. Some experiments with Apple's OpenCL implementation have been done. Misc.: has been sick for 4 days (caught a flu).
Victor
3D pose estimation: refactored the code of Howard's algorithm. I tried to minimize the differences with pe3d estimator by changing algorithm parameters (pe3d usually returns 3-5x more inliers). Now I get better trajectories (see trajWithPlaceRecognizer# png) but after activation of PlaceRecognizer I get an incorrect trajectory in the closure point (see trajWithoutPlaceRecognizer.png). Peh (Howard) and pe3d give very similar reprojection errors on keyframes (see reprojection.png), but there is a 20-30% difference in translation vectors. [Alexander] Pose refinement: implemented an algorithm for the edge model downsampling. The approach is inspired by the Douglas Peucker algorithm. It decreases number of points in the model from several thousands to several hundreds of points (see originalModel.png and downsampledModel.png). Optimized and refactored pose refinement: Object Old mean time (s) Optimized version (s) Downsampled model (s) avocado_slicer 30.19 9.08 1.87 coffee_filter 68.26 10.75 # 99 corkscrew_b 4# 90 11.13 # 41 drain_stopper 6# 65 11.20 # 96 DOT: implemented yet another version of DOT for research purposes. It supports a masked training data, detection threshold depending on object area (unlike Hinterstoisser's implementation). The code is smaller and easer for the experiments (unlike Holzer's implementation) and supports multi-scale detection (unlike both versions). But it does not support templates clustering and does not use SSE and IPP, so it is slower now. Some results of multi-scale detection on TOD base (5 objects) are attached (r1-r# png, the corners of correct rectangles are marked by hand). DOT detects almost all objects on test data, but gives many false positives. [*Maria*] TOD: Supported TUM group (Dejan) that uses tod_* (289, 487, 504, 355, 505, 272, 536, 537 on http://answers.ros.org). [Alexander] Documentation: the tech writer has started to work on the OpenCV manual. A version with improved gpu section of the reference has been checked in. Testing: Andrey is evaluating Hudson vs buildbot. Hudson has better UI but it has a lot of problems for cross-platform builds. This week we will decide on whether we want to stay on buildbot or more to hudson. Other: Victor was on vacations March 18-2#
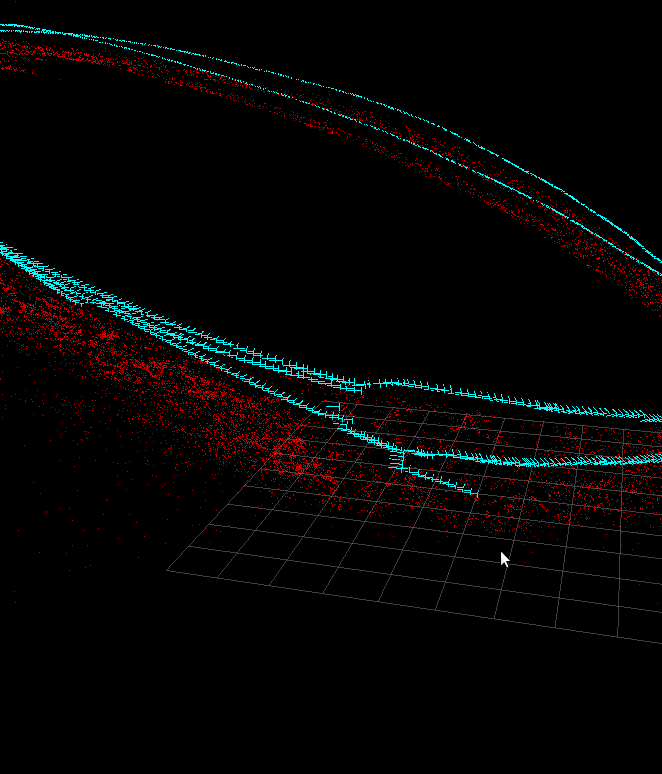
- Trajectory Place Recognizer

- With Trajectory Place Recognizer

- Without place recognzier
- Reprojection

- Original model

- Downsampled model
- DOT results 1

- DOT results 2

- DOT results 3
Anatoly Baksheev (GPU Implementation)
Accomplishments:
1) Cuda# 0· Finished investigation of build issue for VS2010, updated the bug (id 803928) with new repro-case.
· Tested OpenCV + Cuda# 0 with nvcc-update Joe sent to us. It is built without errors with VS2010 and VS2008.
· Submitted bugs for Cuda# 0: 807973, 809007, 809008, 809009, 809017, 809018.
2) Stitching
· Implemented graphcut-based blending seam selection. CPU version of graphcuts was used, because NPP-version is unstable (bug was submitted). Seam selection is necessary for cases when an object present on one image and is hidden on another due to camera movement. Dumb algorithm just mixes images in whole area of intersection and can produce a ghosts. But sometimes generated seam is also wrong. Investigating quality.
· Gradient Domain Blending on CPU blending in gradients space and next image reconstruction.
a. Implemented simple conjugate gradient solver for Poisson equation on CPU (simple, slow, optimizations are possible)
Implemented gradient domain blending itself on CPU. it looks good.· Some improvements of multiband blending on CPU. Now its quality is close to GD blending (on our dataset, without significant intensity differences between images). Some pictures are attached.
3) SURF
· Looked at question about an error on groups. Cant reproduce it.
· Found and fixed bug (seldom case, when features number is more than maximal grid size).
4) Documentation
· Minor GPU docs fixes (broken links, missing description)
· Created Request Feature Form and placed link on OpenCV Wiki.
Plans:
1) Docs together with technical writer (currently this process is separate from us).2) Continue work on stitching:
· Try to improve seam selection results. Compare all blending methods on the same datasets with the same seams generated.
· Try stitching cylindrical panoramas with many images (before was only 2 images stitching). Try many images blending.

- New multiband blend

- Old multiband blend

- Multiblend bad seam

- Multiblend good seam
Action Items
Gary
- Send Victor Dot++ info
Radu
Alexander
Vadim
Victor
- Send around GSoC example frameworks
- Get a usable version of DOT to Gary
Kurt
Ethan
- Get out csv output in tod stub
- Get out way of telling whether there are enough texture points visible
James
From last time
Gary
- Send Victor BiGG code
- Sync up on data structures pcl+opencv
- Talk with Ethan on panos and other Android implementations
Radu
- (./) via GSoC: Sync up on data structures pcl+opencv
Alexander
Vadim
- (./) in discussion … Work on Khronos
Victor
Kurt
Ethan
- (./) Finish code stubs for TOD
James
Agenda
- TOD development => Vincent take over final stage. This code now works fairly well with Kinect and we should move on
-
DOT? Need fairly fast.
- Test code
- Docs
- Example of use/tutorial comments
- Ability to modify parts.
- Move on to LineMode … and how?
- Cheatsheet in manual needs to be an expansion on the stand alone cheatsheet.
- C++ version of LogPolar? POSIT
- planar subdivision/Delaunay, setMouseCallBack, ConDensation not in C++ manual.
- can the proof reader just take the C and C++ and make sure they have the same functions in them??
- Calling a “debug week”(?)
- Ecto (python wrapped development system from Ethan and Troy)
Minutes
-
TOD
- Hard to get it working (Vincent)
- Victor wants to study different resolution qualitys and why it fails
- Features2D use to measure repeatability sse …/samples/cpp/descriptor_extractor_matcher.cpp
-
DOT
- Does it consider “no texture”. 7 bits for region, 8 bit “no gradient” — this can hurt with texturless region
- Walls without texture can match everything
- Slower than Hinterstoissers since it wasn’t optimized yet to allow for multi-scale
- Does it consider “no texture”. 7 bits for region, 8 bit “no gradient” — this can hurt with texturless region
-
LSVM (Felzenschwalb — 1 frame/sec per object) … but no training, use Felz.’s mathlab code with images in PASCAL VOC format. Output model can be run by OpenCV
- Sample in OpenCV.
- 3D head — use Felzenschwalb and then CVFH
*
Vadim
# (User Contributions) Integrated patches for parallel k-nearest search in ml (by Konstantin Krivakin), extended libdc1394 wrapper (by Michael Joachimiak), multi-threading-friendly spilltree (by Kevin Keraudren). # (OpenCV standard; OpenCL) Implemented several simple arithmetical functions (add, subtract, mutliply, divide, absdiff, logical operations). Reading the book "Handbook of Computer Vision Algorithms in Image Algebra" by G. X. Ritter. Trying to develop a reusable basis of simple operations that can be used to express various algorithms (like optical flow algorithms, HOG detector, DOT, stereo correspondence, connected component extraction etc.). That involves a lot of "paper programming", without any code yet.
Victor
Pose estimation: experiments with the Howard's pose estimator. Changed the calculation of inliers count in peh, recalculating on the whole point set after pose estimation. Now the number of inliers from peh is close to the number returned by pe3d. The current problem is a nan in quatenion returned by SBA. [Alexander] Pose refinement: experimented with pose refinement on the whole dataset and investigated reasons why pose refinement works with different quality for different objects. Main reasons of the algorithm poor quality for some objects: # Clutter. For example, a lot of texture (cards), a lot of stable reflections (mommy_messages), a lot of small text (baking_cup). # Presence of view-dependent edges. For example, a handle of the avocado_slicer. # Existence of different good edges projections. For example, corn_holder has a few strong parallel edges and we can translate the pose along these edges without changing the cost function much. Started to use edge orientation in the cost function to reduce the influence of clutter. Preliminary results show that the approach is promising: the number of successful refinements for the corkscrew_b object has been increased from 8 to 14 on the first 18 images. [Ilya] DOT: - Tried to reduce false positives count produced by opencv implementation of DOT. Found several resons of this: # If a part of a training object is highly textured then bit vectors of the corresponding rectangles are almost all from 1s. So these regions vote for almost any test template. Added a filter for such rectangles. # Many regions of train images have "texture-less" bit equal to 1 (for some translation). So texture-less background regions often have correspondences with these regions. Added a filter of matches with texture-less background to the detection function. # Some gradient orientations are popular in some positions, for example bottom border of an object often has vertical gradient. Tried to weigh the correspondences of test and train templates in accordance with frequency of the gradient orientation in given position in training base. But I did not find successful weighting scheme. The added filters reduce false positives count, but they filter correct matches sometimes (see atttachment) and I did not find the thresholds of these filters to remove all false positives and save correct matches. - Started to study the extension of DOT that uses surface normals (3D DOT). Perhaps 3D information will increase the quality of DOT. [*Maria*] features2d tests: - Restored tests on detectors and matchers (they were lost while moving to Google tests). - Fixed gtests on descriptors. - Found the reason of SURF and OpponentSURF tests fails by accuracy (because of the recent changes of FastAtan function implementation). Regenerated the tests data. [*Maria*] Object category recognition: latent svn documentation has been contributed by Alexey Polovinkin. Buildbot: is back to life!!! See http://argus-cv.dnsalias.org:8010. Three builders are implemented (Win32, Linux32, Linux64) where OpenCV is compiled successfully. We have 4 failed tests on all these configurations. In order to do this we: - created 32 bit environment on Ubuntu64 - implemented launch of a builder on Ubuntu64 after every commit in the OpenCV repository - rewrote Windows builder scripts using VS2008 buildstep (appeared in buildbot 0.8.3) - implemented useful functions for generation of CMake parameters for any builder - implemented a wrapper for cmake on Windows64, that catches exceptions
Anatoly Baksheev (GPU)
Accomplishments & activities: 1) Stitching · Refactored image stitching code. Added Voronoi diagram based seam support. · Started studying MRF library from http://vision.middlebury.edu/MRF/code/. it contains implementation of graph cut finding methods for many labels case (alpha-beta swap and alpha-expansion). Going to use it for many image seam search. · Cylindrical panorama stitching for camera rotation (only) model still is in progress. Working on global adjustment algorithm. Started studying camera parameters estimation algorithm for rotation models. 2) OpenCV GPU Module · Updated HOG code according to James Fang's request: o Now HOG can run on sub-matrices, i.e. ROI support. o Eliminated extra memory allocations for multi-scale mode. This was our miss. This increased speed-up for James's conditions. · Investigated ticket #974: FD on GPU does not load some classifiers. This was an internal Haar classifier format limitation for GPU. Send several suggestions to Anton. But he have fixed by his own way. 3) Visual audiometry · Managed to compile vslam package independently from ROS (some dependencies ware also extracted from ROS). · Trying to compile it under win3# (This also includes sparse bundle adjustment (SBA)implementation which will be very useful for many image stitching with arbitrary camera movement.) Plans: 1) Continue work on stitching: · Many images graphcut-based optimal seam search. Many images-blending. · Finish cylindrical panorama stitching. · Start porting some functionality to GPU. 2) Review docs.
Action Items
Gary
- Send Victor, Vadim Ecto
- Update Victor on latest CVFH
Radu
Alexander
Vadim
Victor
Kurt
Ethan
James
From last time
Gary
- (./) Send Victor Dot++ info
Radu
Alexander
Vadim
Victor
- Send around GSoC example frameworks
- Get a usable version of DOT to Gary
Kurt
Ethan
- Get out csv output in tod stub
- Get out way of telling whether there are enough texture points visible
James
Agenda
- DOT code
- HOGDescriptor (see …/samples/cpp/peopledetect.cpp) is not in the manuals.
- GSoC
Minutes
- GSoC
- Tutorials
- We should do some to make a template to follow
- iOS port
- OpenCL — take CUDA group and turn to OpenCL
- Tutorials
- Pose
- Ilya studying paper “Estimation of Curvature and Tangent Direction by Median Filtered Differencing” by Matas Shao, Z. Shao, J. Kittler.
- Same people who did fast chamfer
- Building a pose toolbox will be useful
- Ilya studying paper “Estimation of Curvature and Tangent Direction by Median Filtered Differencing” by Matas Shao, Z. Shao, J. Kittler.
- DOT
- Nest release date:
- June
- Documentation
- Classes are hard in functional method
- Take example from python, more doxygen style
- but don’t limit description by a single line
- Tell what the routine is used for
- Use in sphinx or some other tool
- Meet with technical writer and ask about
Victor
TOD: started using the latest (refactored yet again) version of tod. Fixed bug #5093, a bug with not initialized rvec, tvec in GuessQualifier, a bug in setR method (opencv_candidate), a bug in drawGuess method, implemented returning same camera parameters for train and test in TODRecognizer. Accuracy is still a little lower than with textured_object_detection on prosilica 5mp dataset, need to adapt matcher parameters. [Alexander]
Pose refinement: Finished the implementation of 3d edge orientation in the cost function. The 3d orientations are estimated using the method from “Estimation of Curvature and Tangent Direction by Median Filtered Differencing” by Matas Shao, Z. Shao, J. Kittler. The algorithm was evaluated on different sets of initial random poses on 16 objects. Attached combinedPlot.png shows average rate of successful refinements (i.e. refinements where final pose is close enough to ground truth, judging by distances between translation and rotation vectors) depending on initial poses. Each pose is generated by ground truth by rotating the object by given angle (x-axis) in random direction and translating it by given distance (‘Initial translation’ in the graph) in random direction. Algorithm with edge orientation is plotted with stroked line, without edge orientation — solid line. [Ilya]
DOT: source code was released and sent to Gary. Maria
Untextured objects: scanned a dataset of 15 kitchen objects (IKEA plates, cups and bowls, thanks to globalization, very similar to those in Willow). DOT has been tested on these images (point clouds were not used), example (dot1.png) is attached. Objects of the same shape are often mixed with each other, but DOT will be useful when combined with 3D detector, such as VFH. The current issue is that tod_training does not return good masks including a part of a table, a fix for this is on the way. [Maria, Ilya]
Howard’s 3d<→3d: found parameters that produce crash in SBA more often. The problem was localized in the Cholesky solver that returns nans in the result. So far no idea what causes this. [Alexander]
Buidbot: Now we have 32 builders for different building parameters!
- Ubuntu or Windows
- 32 or 64
- debug or release
- with tbb or not
- with sse or not
We have only 1 failed test on all these configurations. In order to do this we:
- tuned 64 bit environment on Win7 x64
- tuned our scripts for Windows builders
- compiled Python # 6 in debug mode on Win32/Win64
- modified solvePnPRansac test
- Alexey Polovinkin fixed test for LatentSVM [Andrey, Alexander]
- Pose fitting. Y axis is percent of time out of many trials that the fit is correct.

- DOT object recognition results showing multiple recognition of similar shapes (before any filtering is applied)
Anatoly Baksheev (GPU)
Accomplishments & activities: 1) Stitching a) Utility · Added support of CV_32FC4 type for subtract and add functions. · Implemented downsample, upsample functions. · Updated GPU filters so that they support images with size less then GPU block size. (Of cause SMs are idle, but don't think downloading to CPU is better). b) Adjustment · Implemented pair-wise stitching for many images case (combine each new image with previously composited mosaic). This is temporary until global algorithm is not ready. · Working on global (not pair-wise) adjustment algorithm for many images case. Learning sparse bundle adjustment mathematics. (Interesting, will SBA on GPU be reasonable/useful?). c) Blending on GPU · Implemented blendLinear, blendMultiBand on GPU for many images case. Speed-up of blendMultiBand is about 10x (C2050 vs. Core i3 # 93, 2160x4064) and this is not optimal implementation. These results are only for blending, i.e. time of graphcut-based optimal seam search (on CPU) is not included. Waiting stable graphcut from NPP to be able to implement whole pipeline on GPU. 2) Visual odometry · Managed to compile vslam package with dependencies under windows. · Going to eliminate dependencies as much as possible (ex. replace flann library with cv::flann, etc.), merge dependencies in one project, drop unnecessary code. 3) Tested bugs repros for NPP bugs on Cuda# 0 RC2 no change. Plans: 1) Continue work on stitching: many images global adjustment algorithm.
Action Items
Gary
Radu
Alexander
Vadim
Figure out a good time for a “bug hackathon” week and a “doc-athon week”.
- I will be out May 7-17 but can maybe do some work while traveling
- Hopefully we can get most bugs and doc issues done before and June can be more focused on unit and install tests.
Victor
- Suggest next directions for Ilya, Maria and yourself for the May through summer period. Some options (in random order):
- Tutorials/OpenCV Class/Docs
- It is very worthwhile to spend time on this and I don’t think we can trust GSoC students to do the whole thing
- Object Recognition
- Hinterstoisser’s new paper (Line-Mod) on binary codes, combining something like DOT with Depth. Needs to be made
- Modular so new modalities can be added and/or used independently
- These templates are not complete, just indexes into where features occured withing an ROI but they do naturally subdivide into parts. We want to use the learning of parts to approach occlusion.
- Cloth, deformable objects — open area we have nothing on so far
- Transparent — I will be approaching this and it might use a hardware solution of a light that can flash on and off for specularity
- articulated objects
- Hinterstoisser’s new paper (Line-Mod) on binary codes, combining something like DOT with Depth. Needs to be made
- Tutorials/OpenCV Class/Docs
- People
- Torso, upper torso, arm, hand, head — knowing where these are in 3D
- High value classifiers
- This is the same as “People” but maybe for other objects like cups, plates, silverware … chairs tables etc
- Just like we have a popular face detector, do this for other objects
Kurt
Ethan
James
From last time
Gary
- Send Victor, Vadim Ecto
- Update Victor on latest CVFH
Radu
Alexander
Vadim
Victor
Kurt
Ethan
James
Agenda
- GSoC final mentor+project allocation due!
Minutes
-
VSLAM Some configurations get a crash in SBA with forward pose (3D to 3D only). SVD based works
- Removing dependencies … need Kurt’s advice
-
TOD
- Test system doesn’t work with latest changes in TOD detecting
- 2 version,
- Vincent with ORB Good on 1Mpix, some issue at 5Mpix
- Alexander better on 5Mpix, worse on kinect with SURF and SURF
-
DOT Ilya working on fitting pose based on edges, only those that are invariant to viewpoint
- Optimizing Haussdorf distance … can have problems in clutter. But Hausdorf distance is large
- Is pose failure used to filter?
- 6DOF head pose
- Have a student looking at using poser to do this with kinect data
- Better background subtraction added by Zoran Zivkovic and a patch by Konstantin Krivakin
- This works quite well “out of the box” and detects shadow.
- Input and output arrays
- cvADD(inputM1,inputM2,outputM); Previously we used arrays, now can use STL vectors etc
- Possible to allow OpenCV to process eigen matrices
- GSoC
- Tutorials
- 2 for iOS
- Good tutorial on using Sphinx
- Should link theory to a book/Learning OpenCV? Or course outline
12 slots:
2 for Vincent: SfM Mechanical Turk
Motion tracking: Serge [we have a good student for this and interested mentor]
Object tracking: Alexander [we need to coordinate this with Serge]
2 iOS Port: Victor
2 OpenCL Interface: Vadim
OpenCV samples in python: Vadim
2 Tutorials and Examples: Gary [I could see 2 slots for this … I could use help]
Kurt — VSLAM into OpenCV [ Use NVidia team instead
Peter — I don’t remember what your interest this round was. There is an interesting gradient domain (aka blending) proposal
Caroline — Human rec/tracking. I can also see value in “high value classifiers”, that is, just taking something like the rejection cascade (which now can use any feature but has Haar and LBP available) and getting it to work well on different views of the head, eyes, or any body part.
Victor
TOD: Updating test system to work with the latest changes in tod_detecting: - fixed bug in TODRecognizer with clustrering (50898 rev) - modified test system for tod_* (50973 rev) - implemented infrastructure for resizing train and test bases in tod_* format (51021, 51022 rev) - fixed #5097 issue (50974 rev) - answered some questions from Dejan [Alexander] Untextured objects: experimented with pose refinement algorithm on 'plates, cups and bowls' dataset. The algorithm does not give good results the most of the time because it uses object edges that don't change with a viewpoint. As it appears, uniformly colored kitchen items have few such edges and they are weak. We are working on an algorithm that uses test point cloud to do detection and pose estimation, using the same approach (global optimization from nlopt package). This algoritm performs well on a single object (see attachments -- initial.png with initial pose and final.png with pose after optimization) but fails in clutter. [Ilya] Implemented a function for calculating a mask of train objects using point clouds. The main reason is that the existing algorithm in tod_training depends on R,T found using template and often this is not accurate enough, sometimes an object on a table can have has negative z (formally being under the table), resulting in heavy clipping. Our function computes the mask in camera space (independent from R,T quality) and is based on fitting a plane to a table. It gives more accurate masks for all objects from our "plates_cups_bowls" base if object is taller than ~1.5 cm. [*Maria*] Buildbot: - added builders for MacOs - added run tests for Python's module - tested authorization scripts - begin to work on LogObserver class for python tests results - tried to compile OpenCV with CLang on MacOS - we need to compile python from sources in Windows to run python wrappers in Debug mode. This is in progress. [Andrey, Alexander] Tutorials: work in progress on an extensive tutorial of projective geometry with opencv (see the contents below). The foils are 90% done. [Victor] Contents (largely based on 'multiple view geometry' and Golub for theory review): Single-view geometry Pinhole camera model PnP problem, cost functions (reprojection error) Direct Linear Transformation, RANSAC, LM Camera calibration Planar objects, homography Two-view geometry Epipolar geometry, fundamental matrix, Essential matrix Structure from motion 3D reconstruction

- Initial fit

- Final fit
Vadim
# (User Contributions) integrated improved mixture-of-gaussian background subtraction algorithm by Zoran Zivkovic (this is incremental improvement of the previous version, contributed by the same author); integrated another patch by Konstantin Krivakin - for parallel TBB-based SVM prediction. # (Documentation) Fixed most issues reported by tech writer. Some of the issues required fixing Sphinx. The patch has been posted to the Sphinx bug tracker. # (OpenCV interface) Finally, finished transition to InputArray/OutputArray. Fixed all the build problems and most of the problems in tests found by our continuous integration system. plans. # start cleaning bug tracker. # GSoC: define who will be accepted
Anatoly Baksheev
Accomplishments:
1) Finished extracting Visual odometry package with GPU support from ROS. Now we need to decide how it should be integrated into OpenCV. Details were send by Victor yesterday.2) Image stitching
· Spent a lot of time studying Structure from Motion theory (sparse bundle adjustment, starting point computation for LM, papers about SBA on GPU, decomposition homography into rotation and translations, etc.)
· We decided to stop on RotationCameraModel and finish stitching functionality for spherical, cylindrical and planar panoramas. Currently we are working on final (not research) code.
We can consider two models of camera movement: 1) camera only rotates 2) also shifts. In the first case here is quite simple model and we are going to finish it this week. For second case, there is a quite complex algorithms and a lot of things to implement. We decided not to do this. It more close to Structure From Motion (SfM) area rather than panorama composing. And it’s implementation may take very big amount of time.
3) Started work on slides for GTC Israel.
Plans:
1) Finish synthesis of panorama for RotationCameraModel.2) Optimization of GPU stitching stuff.
3) VSLAM into OpenCV
4) New tasks??
Issues:
· Optimal seam selection will use CPU graphcut due to instability of GC from NPP.
Action Items
Gary
Radu
Alexander
Vadim
Victor
- Talk to Kurt about directing someone on the NVidia team for VSLAM
Kurt
Ethan
James
From last time
Gary
Radu
Alexander
Vadim
- Figure out a good time for a “bug hackathon” week and a “doc-athon week”.
- I will be out May 7-17 but can maybe do some work while traveling
- Figure out a target date for the next release. Probably in June.
- Hopefully we can get most bugs and doc issues done before and June can be more focused on unit and install tests.
Victor
- Suggest next directions for Ilya, Maria and yourself for the May through summer period. Some options (in random order):
- Tutorials/OpenCV Class/Docs
- It is very worthwhile to spend time on this and I don’t think we can trust GSoC students to do the whole thing
- Object Recognition
- Hinterstoisser’s new paper (Line-Mod) on binary codes, combining something like DOT with Depth. Needs to be made
- Modular so new modalities can be added and/or used independently
- These templates are not complete, just indexes into where features occured withing an ROI but they do naturally subdivide into parts. We want to use the learning of parts to approach occlusion.
- Cloth, deformable objects — open area we have nothing on so far
- Transparent — I will be approaching this and it might use a hardware solution of a light that can flash on and off for specularity
- articulated objects
- Hinterstoisser’s new paper (Line-Mod) on binary codes, combining something like DOT with Depth. Needs to be made
- Tutorials/OpenCV Class/Docs
- People
- Torso, upper torso, arm, hand, head — knowing where these are in 3D
- High value classifiers
- This is the same as “People” but maybe for other objects like cups, plates, silverware … chairs tables etc
- Just like we have a popular face detector, do this for other objects
Kurt
Ethan
James
Agenda
- GSoC
Minutes
- Tutorials
- Write topics
- Sample of how to solve a meaningful problem
- Line by line explanation of how to solve
- Victor has checked in a tutorial to trunk under
- opencv/doc/opencv_tutorials.pdf
- opencv/doc/tutorials with the latex sources
- Set up payment for the org
Vadim
# (New features) Lapack is not used in OpenCV anymore. The only thing why we needed it was SVD, which now has been replaced with very robust and compact hand-written Jacobi SVD. On large matrices (like 100x100) Jacobi algorithm can be 50-100% slower than Lapack, but on small matrices (3x3 - 10x10) it is several times faster. It's planned to add Eigen3 support by # 3 release time. # (Bug tracker) 32 tickets have been closed. Some analysis of the open bugs has been done: problem domain critical/major/minor/patches build/install 0/12/12/2 documentation 43 in total core 0/10/5/1 highgui 4/30/23/17 imgproc+video 0/18/17/6 python binding 4/10/9/2 all 9/125/63/35 plans. # continue cleaning bug tracker.
Victor
tod: added support for resizing datasets in new (kinect) format. Now we can convert prosilica datasets to the new format and change image resolution. Together with Dejan fixed issue #5097 issue. Updated tod rosinstall file. Got a dependence of detection and false positive rates on test images resolution (with training images resolution fixed at 5mp). The dependence is shown below, one can see that detection rate drops close to zero for two objects and stays on sufficiently high level for another two. High false positive rate for 4medals at 5mp is a bug that is fixed in the latest revision of the code. [Alexander, Victor] Howard 3d<->3d pose estimation: a lot of progress in understanding why vslam does not work with Howard. A crucial difference in between finding a solution by ransac and by clique. All other differences have been eliminated. It looks like the solution found by RANSAC produces inliers that are not consistent in Howard's sense with the thresholds that we selected. If we increase the threshold, we get too many outliers in the maximum clique and a worse solution that also produces bad visual odometry, even after sba. [Alexander] Buildbot: - modified scripts for MacOs (now we have some problems with running Python tests on MacOS in the case of CMAKE_OSX_ARCHITECTURES=i386) - finished LogObserver class for python tests results. Now a user can see number of failed and successful tests - implemented scripts for automatic start of buildbot after reboot BigMac - added sending e-mail after every failed build (temporary messages are set only to Alexander and Andrey) - created issues (#1019, 1021, 1027) - begin to implement scripts for testing Cuda model in OpenCV Pose refinement: the code has been refactored and put to object recognition stack in the package edges_pose_refiner. [Ilya] DOT: first version of DOT is in opencv trunk, still has to be tested and optimized. Tests on "plates_cups_bowls" dataset showed that the method works reliably for matted untextured objects that are different in color from background. [*Maria*]
Anatoly Baksheev
1) OpenCV & GPU· Added 16-bit support to TiffEncoder
· Visual Odometry integration is frozen. Waiting decision how to integrate, and a VSLAM update from Kurt (Willow).
· Review and refactoring of GPU Module. Going to use some Thrust functionality to make our code more standard, and create Thrust extension for pitched memory.
o We reuse from Thrust or implement: functors, binders, micro algorithms, like plus, min, reduceSMEM<T, int>, our analogue of transform_iterator but for pitched memory, our analogue of zip_iterator.
Won’t commit it before support of Cuda# 0.
2) Stitching
· Created spherical, cylindrical, and plane warpers.
· Refactored image stitching code – now it’s easy to switch blender (warper, seam finder) from one to another.
· Rotation model is still in development. We can stich many images (some of results attached). But sometimes results are incorrect, or bad estimated parameters do not allow to stitch. Investigating.
Plans:
· Finish image stitching application.· Meeting with Radu to start PCL Cuda project.
Action Items
Gary
- Look at tutorials and see if what we want to do
- Look at GSoC payment setup
Radu
Alexander
Vadim
Look at GSoC payment setup
- Tutorial suggestions
Victor
- Get me a list of tutorials suggestions
Kurt
Ethan
James
From last time
Gary
Radu
Alexander
Vadim
- Figure out a good time for a “bug hackathon” week and a “doc-athon week”.
- I will be out May 7-17 but can maybe do some work while traveling
- Figure out a target date for the next release. Probably in June.
- Hopefully we can get most bugs and doc issues done before and June can be more focused on unit and install tests.
Victor
- Talk to Kurt about directing someone on the NVidia team for VSLAM
- Suggest next directions for Ilya, Maria and yourself for the May through summer period. Some options (in random order):
- Tutorials/OpenCV Class/Docs
- It is very worthwhile to spend time on this and I don’t think we can trust GSoC students to do the whole thing
- Object Recognition
- Hinterstoisser’s new paper (Line-Mod) on binary codes, combining something like DOT with Depth. Needs to be made
- Modular so new modalities can be added and/or used independently
- These templates are not complete, just indexes into where features occured withing an ROI but they do naturally subdivide into parts. We want to use the learning of parts to approach occlusion.
- Cloth, deformable objects — open area we have nothing on so far
- Transparent — I will be approaching this and it might use a hardware solution of a light that can flash on and off for specularity
- articulated objects
- Hinterstoisser’s new paper (Line-Mod) on binary codes, combining something like DOT with Depth. Needs to be made
- Tutorials/OpenCV Class/Docs
- People
- Torso, upper torso, arm, hand, head — knowing where these are in 3D
- High value classifiers
- This is the same as “People” but maybe for other objects like cups, plates, silverware … chairs tables etc
- Just like we have a popular face detector, do this for other objects
Kurt
Ethan
James
Agenda
- GSoC
- GSoC Payment
- Tutorials
- Other issues
- Release target date
- Further research
- Size filtering
- Distance header
Minutes
- GSoC
- Sergey is looking into gettting us signed up as suppliers
- An admin might have to be involved, but that could be Vadim
- Tutorials
- Do it in Sphinx
- Vadim will set up the first “hello world tutorial”
- iPhone start tomorrow
- Release date/activities
- Cleaning debug tracker
- Integrating patches
- Fixing major bugs
- Maria already fixed most of the ML issues and Features2D bugs
- Many HighGUI issues that are difficult since they are really ffmpeg issues that are environment dependent.
- Marius on FLANN issues
- Documentation: Tech writer reviewed most of the chapters
- But not features2d (should be priority)
- Would like to get ORB in the release since probably the ORB paper is accepted into ICCV and we’d like to announce it there with it already inside of OpenCV and usable for Features 2D.
- Release timeline
- Bug fixing period 3 weeks
- Documentation 3 weeks
- Code writer should look at the user wiki content
- Search on documentation or documentation/cpp or …/c or …/py
- ORB 1 week
- Code coverage completion 2 No new functions without coverage
- Testing 1 week
- Aim for release by June 20th
- Cleaning debug tracker
-
JAVA API for OpenCV
- Tegra team Java binings by CVPR (June 20th)
- Distance header — Vadim thinks it can get in before the release
Vadim
# (Bug Tracker) 13 tickets have been closed. # (Build Issues) OpenCV now builds on Ubuntu 11.04 (after fix in highgui). # (Python) Python bindings for OpenCV 1.x API (by James) and OpenCV # x (auto-generated) have been split into separate modules: cv and cv2, respectively. That should resolve some name conflicts and simplify work on the Java bindings. plans. # continue to clean the bug tracker.
Victor
TOD: - re-factored scripts for training base resizing for support Kinect bases (rev 51305) - fixed bug in guess::draw method, when train and test bases have different camera parameters (rev 51293) - fixed exception in CloudFilter, when bounding box for projected points has vertex with negative coordinates (rev 51293) - correspondence with Dejan and Juilus. Begin to investigate their problems with tod_* (#5083, #5084, #5103, #5104). Learned Maria's code for cropping object for fixing ticket #510# I plan to integrate her code to tod_training. [Alexander] Pose refinement: doxygen documentation for the edges_pose_refiner package was created. All public methods and fields for external use are documented. Implemented code for running the edges_pose_refiner package with train and test data in the new format and run it on TOD poses. Implemented interpolation of point clouds to prosilica resolution (my old implementation used disparity images which are unavailable in the new data format). [Ilya] OpenCV: - fixed a bug in knnMatch (rev. 4969). I think it solves #5104 bug. I plan to check this. - fixed a bug in solvePnPRansac test. Applied a patch of Pieter-Jan Busschaert for the code of solvePnPRansac (rev. 4976). [Alexander] - Added a new sample on MLL that classifies image points and shows a decision boundary (points_classifier.cpp). The base version of the sample was contributed by Alexander Bovyrin, I rewrote it in C++ interface of OpenCV and added 4 new models (CvNormalBayesClassifier, CvBoost, CvERTrees, CvGBTrees). So now it demonstrates all OpenCV supervised learning models as well as unsupervized CvEM. But CvGBTrees gives incorrect decision boundary, a report about this was sent to Pavel (the author of GBT). [*Maria*] # ) Resolved the problems: - tickets on features2d and ml modules: ##832, 977, 982, 978, 932, 899, 877, 887; - fixed crashes in CvBoost (subsamle_mask) and CvGBtrees (C++ wrappers) discovered while adding points_classifier.cpp sample. VisualSlam: - Experimented with Hirschmuller constraints in finding the maximum clique. Similar problems are observed (we get too many outliers in the maximum clique and a worse solution that also produces bad visual odometry, even after sba). [Alexander] Buildbot: - added 2 builders for OpenCV in Ubuntu64 with WITH_CUDA=ON - added builder for Android version of OpenCV on Ubuntu 64 - fixed different bugs in MacOs and Windows builders - added creating OpenCV Linux tarball and HTML documentation every night - added opencv ftp (thanks Andrew S.), we upload tarball and docs every time to ftp://argus-cv.dnsalias.org Now we have two unsolved problems: - incorrect uploading HTML pages with documentation to the FTP - exception after running Python tests on MacOS, when we compile OpenCV for i386 architecture [Andrey, Alexander] Other: May 1st was a public holiday in Russia.
Anatoly Baksheev
1) OpenCV & GPU· Modified CudaMem implementation for ZERO_COPY flag so that rows are aligned to 256 or 512 bytes. Hope after mapping to device memory this will be the same.
· Fixed minor bugs in gpu::cvtColor.
2) Stitching.
· Finished with stitching algorithm for rotation camera model with global adjustment. Now we estimate initial parameters from pair-wise homographies. And next refine it using Lev-Marq. (i.e. solve not sparse Bundle Adjustment problem).
· Improved stability of stitching (added filtering of bad estimated parameters such as negative focal lengths, etc. This caused crashes before). Minor improvements in Voronoi and GraphCut seam finders.
Issues:
- GraphCut seam finding sometimes leads to artifacts.
- Parameters tweaking is required for some datasets.
Plans:
*Add stitching application to SVN tree, move some reusable parts of stitching to different OpenCV modules, add possibility to select CPU or GPU implementation (SURF, BFM, Blending, etc.).
*Test it more, people from Itseez will play with it.
3) Started work on PCL. First task will is to implement OctTree on CUDA/Thrust.
· Compiled PCL.
· Now we study PCL sources and papers about OctTree on GPU.
4) Started thinking about camera calibration without chessboard pattern. This will be our next task.
· GPU here can be used only for SURF and BFM. All other stuff will be on CPU.
Plans:
· Suggest calibration scheme and begin its implementation or at least do some experiments.
· Integrate stitching to OpenCV SVN tree and test it more.
· Work on porting PCL to Cuda.

- Image stitching results
Action Items
Gary
- Contact GSoC interns
- Get foils to Victor
Radu
Alexander
Vadim
Create a tutorial stub
- Contact GSoC interns
- Make sure the tech writer incorporates the opencv.willowgarage.com/wiki/documentation user changes.
Victor
- Get me a list of tutorials suggestions
- Contact GSoC interns
Kurt
Ethan
James
From last time
Gary
- Look at tutorials and see if what we want to do
- Look at GSoC payment setup
Radu
Alexander
Vadim
- Figure out a good time for a “bug hackathon” week and a “doc-athon week”.
- I will be out May 7-17 but can maybe do some work while traveling
- Figure out a target date for the next release. Probably in June.
- Hopefully we can get most bugs and doc issues done before and June can be more focused on unit and install tests.
- Tutorial suggestions
Victor
- Look at GSoC payment setup
- Tutorial suggestions * Talk to Kurt about directing someone on the NVidia team for VSLAM
- Suggest next directions for Ilya, Maria and yourself for the May through summer period. Some options (in random order):
- Tutorials/OpenCV Class/Docs
- It is very worthwhile to spend time on this and I don’t think we can trust GSoC students to do the whole thing
- Object Recognition
- Hinterstoisser’s new paper (Line-Mod) on binary codes, combining something like DOT with Depth. Needs to be made
- Modular so new modalities can be added and/or used independently
- These templates are not complete, just indexes into where features occured withing an ROI but they do naturally subdivide into parts. We want to use the learning of parts to approach occlusion.
- Cloth, deformable objects — open area we have nothing on so far
- Transparent — I will be approaching this and it might use a hardware solution of a light that can flash on and off for specularity
- articulated objects
- Hinterstoisser’s new paper (Line-Mod) on binary codes, combining something like DOT with Depth. Needs to be made
- Tutorials/OpenCV Class/Docs
- People
- Torso, upper torso, arm, hand, head — knowing where these are in 3D
- High value classifiers
- This is the same as “People” but maybe for other objects like cups, plates, silverware … chairs tables etc
- Just like we have a popular face detector, do this for other objects
Kurt
Ethan
James
Agenda
- GSoC
- GSoC Payment
- Tutorials
- Other issues
- Release target date
- Orb — Vincent has cleaned up
- New competition/direction
Minutes
- Image Stitching is now in OpenCV trunk, see 3rd photo below
- DOT from Hinterstoisser is now in trunk. It’s not SSE optimized yet and so runs at ~18ms/template
- Matrices in OpenCV are now indirect, using a proxy types for input. So inputs can be cv::Mat or std::vectors …
- This is a step towards using Eigen out of the box
- Unifying with PCL
- Solutions in perception
- Winners in order were:
Berkeley 68%
Jacobs 66%
Stanford 53%
Baseline (TOD) 50% [But see below …]
-
TOD
- TOD
- Low resolution: Use FAST with low threshold, like 5 and non-max turned off works better
- Winners in order were:
- Release:
- Vadim is working on bugs and docs
- We want the new feature, ORB in. Vincent will commit.
- Docs should go …/modules/features2d/doc/common_interfaces_of_descriptor_extractors.rst
- Tests should go to …/modules/features2d/test/test_features2d.cpp
- Test data will go to opencv_extra: * /opencv_extra/testdata/cv/detectors_descriptors_evaluation/descriptors*
- Release date is still on for June 20th, right before CVPR
Victor
OpenCV: the problem in cv::DynamicAdaptedFeatureDetector (#5104 in ROS trac), modified constructors of cv::AdjusterAdapter's inheritors to pass min and max thresholds. [Maria, Alexander] Fixed tickets ##1038, 1025, 1044, 1046, 1048. [*Maria*] Buildbot: - modified scripts for supporting Vadim's modifications (make docs, make html_docs) - investigated problems with python failed tests on Windows and MacOS, reproduced these problems on two tests (PreliminaryTests.test_lena on MacOs, test_MixChannels on Windows32). Sent this information to Vadim. Found new problem: tests on MacOs are ignored OPENCV_TEST_DATA_PATH variable if WITH_TBB=ON. Plan to continue investigation of these problems. - fixed problem with incorrect Python environment on Win64 - created a web-site with OpenCV documentation built daily by buildbot, it is available at opencv.itseez.com - fixed scripts for the Android builder (this builder doesn't work after rebooting virtual machine) - fixed Documentation builder after Vadim's modifications in docs folder (renaming folders, removing BUILD_REFMAN, ...) - Created an external page http://buildbot.itseez.com so that anybody can track opencv trunk status. [Alexander] TOD: - finished re-factoring scripts for training base resizing, fixed bug when camera parameters file doesn't exist in the main training base folder, fixed incorrect generating of pcds.txt file (rev 51320) - added some useful parameters to frecognizer -s - for saving images with projections into selected folder -o - for sorting images in the image folder in the case of [1-9]*.png format -h - for showing progress (rev 51434) - fixed bug in CloudFilter with incorrect projections (rev 51435) - correspondence with Dejan and Juilus. I am investigating their problems with tod_* (#5104 and #5103) - #5104 I got from Julius their training and test bases, reproduced this problem. Maria and me localized this problem in DynamicAdaptedFeatureDetector, now we are trying to fix them. - #510# I begin to experiment with Maria's version of masker algorithm. I can get better masks on the one bag file with Kinect data (silk.bag) in comparison with default cloud masker in tod_training. I plan to do some more experiments and integrate it to the tod_training on this week. [Alexander] - Fixed #5104 issue (OpenCV 5086 revision, tod_training 51452 revision) - Integrated the new masker algorithm to the tod_training (#5103 issue). [Alexander, Maria] DOT: current opencv implementation is 18.7ms per one frame and one training template, Hintestoisser's version with IPP and SSE -- 4ms. Optimization of opencv version is in progress. [*Maria*] Pose refinement: edges_pose_refiner package has been tested together with tod. It can take a pose generated by tod as an input and refine it using edges cost function. An example is attached, it uses binpick 5MP dataset. Image stitching: thanks to opencv gpu team, we now have image stitching in opencv! It is a separate application opencv_stitching that takes an arbitrary amount of images as an input and automatically generates a single image as an output. It is being tested now. A downsampled stitched image from 6 12MP images is attached (the pano series is quite challenging due to bright sun that changes lighting from image to image). Other: Ilya and Andrey are on vacation this week, Alexander was on vacation May 16th.



Vadim
# (Documentation) Our tech writer finished grammar check of the reference manual. Now she is fixing the hyperlinks and will then check the user's guide and the tutorials. User guide and the tutorials are included into the build process. Online version of the whole documentation (3 parts of the reference manual: OpenCV # x C++ API, OpenCV 1.x C API, OpenCV 1.x Python API, User guide, tutorials) is now automatically generated as well. # (Fixing bugs) 10 tickets have been closed + several build problems and failures in tests, discovered by our buildbot, have been eliminated. plans. # continue to clean the bug tracker.
Action Items
Gary
- Tell Vincent to put ORB in
Radu
Alexander
Vadim
Victor
- Get stitching to have test and doc
Kurt
Ethan
James
From last time
Gary
- Contact GSoC interns
- Get foils to Victor
Radu
Alexander
Vadim
Create a tutorial stub
- Contact GSoC interns
- Make sure the tech writer incorporates the opencv.willowgarage.com/wiki/documentation user changes.
Victor
- Get me a list of tutorials suggestions
- Contact GSoC interns
Kurt
Ethan
James
Agenda
- GSoC … vendor resolved?
- Any intern issues?
- Release status, on schedule?
- Docs.
- PDF doesn’t have detailed sections to jump to like the old one.
- Tutorials
- Future directions: More pose fitting
- New circular calibration pattern.
Minutes
- GSoC vendor status
- Sergey is now also an admin, hopefully will take care of it.
- Documentation
- The table of contents for the pdf is now smaller. In return, there should be an index, but it’s not in yet.
- Vadim will enable tables on every chapter header, imilar to the python documentation here.
- Alexander Mordvitsev (GSoC intern) is now working on further improvements to python bindings and on creating python
- Bindings for Java are being worked on by NVidia team.
- 2 scripts for python:
- 1st script parse OpenCV headers with macro annotation (input, output …)
- 2nd script takes this list and creates C python wrappers from the output of 2nd script
- Java just needs to write a 2nd script for Java.
- Want to do this for Matlab eventually
- Have to do this for swig as well, but here we have complete control
- 2 scripts for python:
- Vincent
- Commited alternative python bindings based on python boost, mat wrappers and some highgui
- Hard to maintain, every function that changes in C++ then needs someone to update
- No documentation on new bindings
- Hopefully new docs will be there before the release
- Commited alternative python bindings based on python boost, mat wrappers and some highgui
- So far, still on Schedule for June 20th release.
- Who to get for OpenCV debug hackathon.
- James for python
- Tutorials in rst/sphinx
- Can we embed youtube into rst such as http://countergram.com/youtube-in-rst
- TOD is used in Technical University of Munich and they found some problems
-
DOT
- Maria is putting in additional false positive
- Victor in US right after CVPR. Week of June 27
Vadim
# (Documentation) - Our tech writer started the second round of the reference manual review. - I'm writing a script that checks completeness and correctness of the reference manual (i.e. it should catch the cases when the number of parameters or their types have been changed). Right now the part that scans the reference manual and the part that extracts the API from headers (based on our parser for Python bindings) are ready and mostly work well. Comparing the two sets of API is in progress. # (Fixing bugs) 18 tickets have been closed. # (GSOC) Alexander Mordvitsev started work on Python bindings. Preliminary version of letter_recog.cpp that demonstrates the use of various classifiers from ml is ready. Apparently, the automatically generated and never debugged Python bindings for random trees works well! Plans: # continue to clean the bug tracker. # finish the script. Start updating the documentation. # start OpenCL+OpenCV GSOC project.
Victor
TOD: - finished working on #5103 task. Added new mode -M 2 to the masker in tod_training package. Added ignoring SEG_FAULT signals using long_jump function. (51281 rev). - fixed problem with zero distortion matrix in opencv_candidate (36818), fiducial (51513). [Alexander] DOT: - Made TBB and some other optimizations for DOT detection. Table of detection times (ms) per template (on Intel Core i5 CPU 760@# 80GHz): | 1 template | 100 templates | ------------------------------------ DOT (with IPP, SSE) | 4 | 0.38 | opencv DOT (last week - without optimizations) | 18.7 | 8.2 | opencv DOT (this week - TBB and some other) | 1# 4 | # 4 | Original DOT has been run without templates clustering, opencv DOT implementation has additional normalizations and checks. [*Maria*] Buildbot: - continue investigation problem with Python on MacOS. Tried to reinstall Python. - removed access for writing on our local repository - fixed problem with incorrect DNS on MacOS -> error on sync of repositories - created backup our virtual machines and scripts - installed Bullseye coverage system on Ubuntu virtual machine, investigated console tools for calculation of coverage [Alexander] opencv: - descriptor_extractor_matcher sample was modified to print a more accurate precision-recall curve. [*Maria*] iOS port: the project has started. opencv # 2 was successfully compiled for iOS by Xiaochao, with the exception of tests, samples, highgui and haar_training app. Artem is working on iOS support in highgui. Other: Ilya is on vacations this week.
Action Items
Gary
Radu
Vincent
- Revert python bindings to use the standard ones.
Alexander
Vadim
- Talk with Vincent about python bindings
- Talk with James about Python bugs, especially related to numpy
Victor
- Test code and documentation for DOT
Kurt
Ethan
James
From last time
Gary
- (./) Tell Vincent to put ORB in
Radu
Alexander
Vadim
Victor
- Get stitching to have test and doc
Kurt
Ethan
James
Agenda
- Release status
- GSoC status
- Post release preliminary plans
Minutes
-
SIFT
- Previously we used a previous version of Andrea’s / | VLFet until it moved to GPL. This was an accurate but slow implementation. And it has problems for Android build. Moved to:
- Rob Hess’s code which is 10x faster, maybe just a bit worse in performance, but we can tune if needed.
- Bug hackathon.
- 21+11+3+2 = 37 bugs fixed so far.
- Putting an index table in the doc chapters is also on the list.
- Ana started the tutorials, but is using C not C++.
- Future work
- Color constancy/color balance (see http://www.eecs.harvard.edu/~ayanc/color-constancy/source.html )
- de-noising, noise estimation
- stereo camera — normalize color between the two cameras
- estimating illumination and its direction
- Estimating objects from specularity and lighting direction
Vadim
# (Fixing bugs) The bug-fixing hackathon week started. 21 tickets have been closed by myself + Ilya, Maria and Alexander fixed quite a few. # (Documentation) The documentation checking script is in progress; it reports some false alarms which I'm trying to eliminate now. Our tech writer continues the second pass through the documentation. Next week is supposed to be the documentation improvement hackathon. # (GSOC) Alexander continues with MLL Python samples; knearest sample has been written, 2 bugs in Python wrappers have been found (and already fixed). Salman is slowly starting with OpenCL project. The work will be done in a separate branch not to affect preparations for the release. Plans: # continue to clean the bug tracker. # finish the documentation check script. Prepare for the documentation hackathon.
Victor
OpenCV descriptors: Replaced Vedaldi's SIFT implementation by Rob Hess's SIFT implementation (#1029) due to license issues and speed. precision-recall curves for several OpenCV descriptors, including both SIFT implementations, on different images (graf, trees and wall) are attached to the message. The comparison of running times for Vedaldi and Hess implementations is below: | Vedaldi's SIFT | Rob Hess's SIFT | detection time per image 1000x700 | 1906 ms | 1105 ms | description time per keypoint | 0.83 ms | 0.23 ms | The regression test for detectors and descriptors (detector_descriptor_evaluation.cpp) has been ported to gtest. [*Maria*] OpenCV bug fixing: fixed compilation errors with Eigen3 (#805), fixed drawKeypoints (it has assumed upward y-axis direction in keypoint orientation drawing), resolved tickets #727, #552, #573, #950. CMake scripts were modified for compiling OpenCV using MinGW in static mode. [Maria, Alexander] More tickets closed: obsolete: #920, #259, #685, #874, #410 fixed: #1063, #886, #797 worksforme: #1049, #118 invalid: #961 [Ilya] Howard algorithm: A simple modification of Howard algorithm finally allowed estimation on new_college precise enough for sba to close the loop. The algorithm uses 3d<->3d matching to estimate pose on a maximal clique, and then refines it by recalculating the pose on inliers within the clique. Then the pose was further refined using sba, similar to pe3d. The refinement on inliers produces a huge difference on new_college sequence, causing loop closure. An image of an example trajectory is attached. The algorithm running time is comparable to pe3d, but can be significantly sped up. [Alexander] Other: Anatoly and Victor participated in nVidia GPU Technology Summit in Israel. Anatoly gave a 40 minutes talk on opencv and gpu module, and Victor did a 15 min OpenCV overview in a parallel track. There was a lot of positive feedback on the talks and tons of questions on opencv. Anatoly cold hardly get lunch, talking to people for two hours after his talk.



Alexy Spizhevoy (GPU)
Accomplishments & statuses: 1) OpenCV & GPU Implemented first version of GPU Canny (2-10x speedup). Fixed several bugs in SURF_GPU. Integrated stream support to NPP wrappers. 2) Image stitching Reduced memory requirements in multi-band blender, it now creates border of 2^number_of_bands size approximately, instead of fitting source images to the final image size. Fixed bug in initial focal length estimation, it's quite stable now. Replaced brute-force matcher with FLANN matcher (in CPU mode). Implemented two gain compensation methods (full image and block-based). Added more flags into stitching app, added preview mode, help message. 3) Auto-calibration No update. Plans: Continue with Canny on GPU. Resume auto-calibration activity.
Action Items
Gary
Radu
Vincent
Alexander
Vadim
Victor
Kurt
Ethan
James
From last time
Gary
Radu
Vincent
- Revert python bindings to use the standard ones.
Alexander
Vadim
- Talk with Vincent about python bindings
- Talk with James about Python bugs, especially related to numpy
Victor
- Test code and documentation for DOT
Kurt
Ethan
James
Agenda
- Python bindings
- Release schedule
- Future plans:
- color constancy
- lighting direction
- de-noising, analysis
Minutes
- If Qt not turned on in cmake, no Qt will be linked. If you do not have Qt on your system, it won’t compile
- gtk also
- Release still on schedule
- DOT inclusion is postponed since not optimized yet
Vadim
# (Fixing bugs) The bug-fixing hackathon is semi-over. Ilya, Alexander, Maria and me took part in it. Alexander and Maria continue fixing bugs. 37 bugs have been fixed, some more are in progress. The total number of open trac tickets has been decreased to 290. Many of them are enhancement requests, there are quite a few duplicates etc. but we will probably need another hackathon week to clean bug tracker a bit more before the release. # (Buildbot, tests, coverage) Buildbot has been extended to measure function coverage (see buildbot.itseez.com, report from the "coverage" builder) [Alexander] Previously disabled highgui tests have been put back into the testing loop [Andrey] # (Documentation) Documentation update hackathon has been started. 9 trac tickets related to the documentation have been closed [Ilya] Documentation check script has been finished [*Vadim*]. Here is the summary of its work: undocumented functions in core: 296 -- most false since many small functions that are for internal use only undocumented functions in imgproc: 42 undocumented functions in calib3d: 58 undocumented functions in features2d: 388 -- most of these are false since the interface exists for all functions but is documented only once. undocumented functions in video: 50 undocumented functions in objdetect: 86 undocumented functions in highgui: 25 undocumented functions in ml: 311 such big numbers are obviously false alarms, because the parser found a lot of tiny methods in the internal-use-yet-exposed classes (especially in core and ml). In features2d, for example, the script did not take into account that all the methods in various detectors, descriptors and matchers need to be documented only once. Perhaps, some "whitelist" or "blacklist" file should be added to make the script ignore certain classes and methods. # (GSOC) Alexander put as much as 4 Python samples to SVN (letter_recog.py (classification), gauss_mix.py (EM demo), coherence.py (advanced image processing), browse.py (advanced highgui use)). Salman is working on OpenCL reimplementation of GpuMat. (Miscellaneous) Maria was on vacation for 3 days (moving to the new apartments)
Anatoly (GPU)
Accomplishments & statuses:1) GTS Israel 201# Talk at the conference about OpenCV on GPU.
· There was many questions
· Got positive feedback from NVidia guys
2) OpenCV GPU and CUDA # 0. Switched our code to the new release.
· Updated GPU Module to use new stuff in NPP# 0 and CUDA# 0 (all asynchronous functionality, cudaDeviceSynchonize, etc.)
· Updated OpenCV GPU Wiki. More detailed installation guide (merged ours and Craig Duttweiler’s pages there), FAQ etc.
· Removed Multi-GPU manager since it is not necessary with CUDA# 0. Multi-GPU samples were rewritten.
· Tested GPU module under Windows and Linux with CUDA# 0 on GT275
o Found new issue for Face Detection for under ubuntu64 for GT27# Logs and dumps were sent to Anton.
3) OpenCV GPU on MacOS. Compiled and tested it.
· Prepared detailed description of MacOS compilation.
· Fixed several compilation issues (that ffast_mat workaround, samples compilation).
· Found issues (filed tests and a crash).
o May be this is CC1.1 problem, not just MacOS. So going to test OpenCV GPU for old cards also.
4) PCL
· Tried to look into the HLBVH code Joe send me. Can’t understand it quickly, need much more time. Learned what is SAH optimization and some papers about KD-tree on GPU.
· Implemented Octree building on GPU, but found a bug when I started profiling it. Trying to find the bug.
Assuming that the bug does not influence on performance, I can give some performance numbers for Octree building.
PCL on CPU: 300K points 23ms, 3M points 216ms.
on GPU: 300K points 60ms, 3M points 118ms.
I am implementing Octree with my own structures, using some ideas from the HLBVH paper of 2010. I decided to do so because it is simpler, and I have understanding how to implement radiusSearch.
Sure the performance is not final. I guess main problem for the small dataset is a kernel calls overhead. Approach from the paper of 2011 eliminates it (task queues). Just need to understand how to do it.
5) Auto-calibration
· Studying of libmv. This is a SfM and auto-calibration library, they have auto-calibration algorithm implemented.
· Started implementation of general infrastructure for auto-calibration (finished bipartite graphs, convenient representation of reconstruction,…), some parts of code are based on libmv.
Just one notice. Auto-calibration complete implementation may take month or two. This problem includes some 3D reconstruction problem.
User will have to take a photos of close well-textured 3D object from different sides (landscapes are not suitable).
Joe, you said you had pinged guys which have pattern-less camera calibration implemented. Do you have any update?
6) Other
· Some help to Tegra team with OpenGL demo application. The Vlad has some skills and experience in OpenGL.
· Minor optimization and improvements stitching application
Plans:
1) OpenGL demo for Android
2) More OpenCV GPU testing (different platforms, configurations and hardware, multi-GPU mode). Also test GruphCuts from NPP# 0.
3) Build binaries for all platforms OpenCV GPU and place them in opencv_extra and svn.
4) Continue work on Auto calibration and PCL.
Action Items
Gary
Radu
Vincent
Alexander
Vadim
Victor
Kurt
Ethan
James
From last time
Gary
Radu
Vincent
Alexander
Vadim
- Talk with Vincent about python bindings
- Talk with James about Python bugs, especially related to numpy
Victor
- Test code and documentation for DOT
Kurt
Ethan
James
Agenda
- Release
- GSoC
- New Plans
Minutes
- Trip: Intelligent Vehicles
- Talk, lots of questions
- Plan object recognition strategy when Victor is here.
- Victor here June 26 for a week.
- Monday NVidia
- Release
- Another week of bug solving
- Seems still on time for June 20th
- Android Java interface will not be ready. Release for Android will maybe be separate.
- C and C++ level and camera API is OK
- Java bindings are not complete. Samples working. No docs. Another month for Java bindings.
- Android Java interface will not be ready. Release for Android will maybe be separate.
- Kinect calibrated with another camera
Vadim
# (Fixing bugs) Since the bug fixing hackathon did very well, the team decided to spend one more thing one the same fun stuff. Maria fixed 15 bugs, Ilya - 8 (+some docs), Alexander - 9, Vadim - 21. # (Buildbot, tests, coverage) A lot of build problems on various platforms (partially coming from trac, partially discovered on our buildbot and workstations) have been resolved, especially mingw (32-bit and 64-bit) support. 5 test failures have been fixed too, 10 are remained to be fixed. [Alexander] # (Documentation) Our technical writer continues the second round of the docs review. Most hyperlinks are now in-place. Doc checking script has been fixed to lower the number of false alarms. Some missing descriptions have been added. Now the numbers are (last week numbers => this week numbers): undocumented functions in core: 296 => 213 undocumented functions in imgproc: 42 => 2 undocumented functions in calib3d: 58 => 8 undocumented functions in features2d: 388 => 367 (should be much lower, indeed) undocumented functions in video: 50 => 0 undocumented functions in objdetect: 86 => 80 undocumented functions in highgui: 25 => 23 undocumented functions in ml: 311 => 86 # (GSOC) Alexander added calibration and video capturing samples. There is no any noticeable progress on OpenCL - perhaps, there will be after the release when all the infrastructure is set up and the student will be just adding functions, which should be rather monotonous task.
Anatoly Baksheev
1) PCL Octree· Spend some time for finding the bug in Octree without success. It appears only with CUDA profiler and kernel that crashes is too simple to contain a bug (possible Thrust or CUDA profiler bug).
· Investigated bottlenecks of the implementation. I think it’s kernel call overhead and a lot of small portions of work that can’t workload GPU entirely. I stopped development in this branch.
· Understood code Joe send earlier with task queues. And found idea of global sync barrier from Duane Merrill’s code (the fastest radix sort author).
· Started I implementation parallel octree building with tasks queues and only single kernel call. In order not to debug on GPU:
a) Implemented quasi-parallel prototype on CPU, tested and fixed bugs.
b) Implemented and tested radius search on CPU for my data structure
2) GPU Module
· Fixed gpu::cvtColor according to changes in SVN r5324 for CPU.
· Fixed bothersome BFM warning ( nvcc cannot tell what pointer points to shared or global ) with PTX insertion!
· Tested GPU module (old cards, Multi-GPU, different systems). Some issues for Ubuntu3# Guess will fix before release.
· Tested GraphCuts from NPP# 0. Now it does not return TEXTURE_BIND_ERROR, but still fails with KERNEL_EXECUTION_ERROR. May be we don’t understand something. It would be nice if we can write to GraphCut’s author directly (Timo Stitch?).
· OpenCV Release is planned next Monday. We decided to:
c) Construct and publish binaries with GPU support for windows. Without CUDA Toolkit binaries (300Mb). So users have to install CUDA toolkit to run GPU.
d) Tarballs for Ubuntu and for MacOS (sources).
e) Mark in Release Notes, that GPU Module is beta or RC for MacOS due to lack of testing.
f) Point in Release Notes, that Face Detection/NPP_staging tests fail and here might be issues. (Linux64/Cuda40/GT275, MacOS/CUDA40/9400M, for GTX470/Windows only integral images)
3) Auto calibration
· Finished working on auto-calibration infrastructure.
· Implemented projective reconstruction for arbitrary number of views (RMS error is about 1 on Wedham College dataset: http://www.robots.ox.ac.uk/~vgg/data/data-mview.html)
· Implemented dense protective bundle adjustment. (Sparse BA will be later).
· Implemented linear auto-calibration (intrinsic camera matrices estimation) via DIAC estimation (dual image absolute quadric). Currently it’s unstable and returning matrices vary much from run to run.
Issues:
a) On some datasets projective reconstruction shows high RMS error probably due to noise and incorrect matches. Increasing matching confidence threshold helps, but it removes too much matches sometimes (with small number of matches projective reconstruction algorithm can’t work).b) Dense protective BA works slow (a few seconds per iteration on big datasets, but quite fast on small ones, depends on number of points in reconstruction) and it doesn’t decrease error.
4) Other
· Helped Tegra team with OpenGL demo application
· Fixed incorrect behavior with different scales in opencv_stitching
Plans:
· OpenCV GPU Release· Finish single grid Octree building. Investigate bottlenecks.
· Try to increase linear auto-calibration stability. Implement metric BA. Implement protective reconstruction upgrading to metric one for further using with metric BA.
· Canny (currently 2-10x speed-up), BFM radius Search optimization, equalizeHists (used for LBM Face Detection), etc.
Other:
I will be on vacations from 20 of June till 2 of July (Altai mountains tracking trip).
Action Items
Gary
Radu
Vincent
Alexander
Vadim
Victor
Kurt
Ethan
James
From last time
Gary
Radu
Vincent
Alexander
Vadim
- Talk with Vincent about python bindings
- Talk with James about Python bugs, especially related to numpy
Victor
- Test code and documentation for DOT
Kurt
Ethan
James
Agenda
- Release
- Book
- Plans
Minutes
- Release
- Release candidate is out now, see change log
- Tutorials are in trunk, release is from branch rc# 3
- Bug tracker
- 205 bugs left down from >400.
- 30-40 are “major” defects
- rest are enhancements, patches or minor defects
- 205 bugs left down from >400.
- New FLANN is slated to go into # # 1 since it’s too much code too close to release deadline
- # # 1 will include new Android stuff (most notably, Java bindings to make OpenCV fully useful on Android).
- Some optimization as well.
- Stitching is in the new release.
- Cheatsheet is updated.
- Rest of the week:
- Second pass of documentation, merging into one file
- Docs … will soon have 5 manuals: C++, C, Python, Python old and Java
- Want to autosync strip off headers, plug into rst (using documentation script)
- Have tables of all the python functions
- all the declarations will eventually be tabs
- Want to autosync strip off headers, plug into rst (using documentation script)
- Can we rsync opencv.itseez.com to opencv.willowgarage.com/documentation
- Make difference between cv::Mat and cv::Mat_ (just adds simple pixel access I(x,y) instead of I.at(x,y))
- Other types without underscore Rect, Point, Size are integer. Rect_, Point_ Size_ can contain any type
- Turning on SSE4 does not auto turn on SSE #
- Future
- Make OpenCV smaller
- Link statically, only used function are in executable
- Can there be a dynamically linkable core that is small? This relates also to the Khronos standard.
- Need to establish this “core”
- Book: Could easily overlay python with C++ functions
- Samples are
- Plans
- Proposal to expand use of dynamic code generation with python — eliminate intermediate code in C++, would go to OpenCL directly which would run on GPU, CPU or to CPU on Sandybridge chips.
- Code written in Python would then run 10x faster, say than hand crafted C code. This could also be done in other languages. Write algorithms in vector form (image algebra book, Ritter).
- Calibration and other functionality. Intern implemented LePetit’s solvePnP
- Bundle adjustment, model slignment
- Push on object recognition. Line-Mod into Ecto, new quick quasi 3D features, transparent objects, model capture
- Make OpenCV smaller
Alexey Spizhevoy (GPU)
GPU module
Configured buildbot on machine with GPU (Ubuntu, 64bit).
Fixed building of GPU module under MacOS i38#
Refactored GPU module tests:
Print information about cards.
Run tests on all cards in system.
Split NVidia.multitest on several subtests.
Asked Timo Stich about issues in graphcut, he confirmed bug in NPP and said it works correctly, just returns error code.
OpenCV # 3rc preparations is almost finished, binaries will be available today here http://sourceforge.net/projects/opencvlibrary.
Plans:
Fix out of memory errors in performance sample on machines with weak GPU, add multi-gpu support.
Implement filters for big kernel size (ticket #1134).
Implement gpu::equalizeHist.
Add GPU based graphcut into opencv_stitching (later).
Stitching:Added wiki page with usage and simple samples: http://opencv.willowgarage.com/wiki/opencv_stitching.
Auto-calibration
Updated inlier/outlier classification step (point is inlier if it’s possible to get some sub-reconstruction with low reprojection errors for all views where point is visible).
Added poor points removal after each iteration in projective reconstruction algorithm, it increased stability a lot.
Fixed some bugs in projective to metric upgrading step.
Built SBA library, installed PCL library (for viewing point cloud).
Issues:
After linear auto-calibration step and upgrading projective reconstruction to metric I get similar intrinsic matrices for all cameras after RQ decomposition (as expected), but sometimes result matrices differ in sign at some elements.
Stability of projective reconstruction is quite good, however there are bad datasets where it’s difficult to find good initial pair.
Often upgrading of projective reconstruction to metric gives poor or reverted visual results (however reprojection error is small) if we use linear auto-calibration only.
Plans:
Fix bug with incorrect signs in intrinsic parameters after upgrading to metric reconstruction.
Implement refinement of metric reconstruction (i.e. parametrized via intrinsic and extrinsic parameters) using SBA library. I think I’ll use some pieces of code from Bundler application.
Sample image 001.jpg from dataset and respective point cloud college.png (built by 5 images) after linear auto-calibration and upgrading projective reconstruction to metric one are attached.PCL octree:
No noticeable update, development is paused because Anatoly Baksheev is on vacations from June 20 till Jule #


Action Items
Gary
- Talk with Nathan about rsync ’ing opencv.itseez.com to opencv.willowgarage.com/documentation
Radu
Vincent
Alexander
Vadim
Victor
Kurt
Ethan
James
From last time
Gary
Radu
Vincent
Alexander
Vadim
- Talk with Vincent about python bindings
- Talk with James about Python bugs, especially related to numpy
Victor
- Test code and documentation for DOT
Kurt
Ethan
James
Agenda
- Release left overs
- Docs/book stuff
- Priorities
- Object Rec
- Khronos
- we have a window of opportunity, we should use it - - Android slimmed down version subset of Khronos
Minutes
- Full # 3 release is out
- Switch opencv to Git soon
- Need to automatically copy new documentation to opencv.willowgarage.com/documentation site
- Khronos
- Data structures are the first part GPU vs CPU
- CPU: easy pixel access
- GPU needs some kind of map for pointers for pixel access and then do unmap
- Data structures are the first part GPU vs CPU
- Question is whether we can make an image algebra that can cover existing and new functions.
Victor
OpenCV Release OpenCV # 3rc has been released on June 21st, OpenCV # # 0 final has been released on July 4th (or July 3rd PST time). The announcements are: # 3rc: http://tech.groups.yahoo.com/group/OpenCV/message/81325 # # 0 final: http://tech.groups.yahoo.com/group/OpenCV/message/81509 The list of major changes is here: http://opencv.willowgarage.com/wiki/OpenCV%20Change%20Logs Highlights of this release are: * Much, much better documentation, which is for now hosted at http://docs.opencv.org and updated nightly. * Buildbot is now working very well, building and testing OpenCV in many different configurations. * Better android support with camera module, demos etc. (with more stuff to come in # # 1) * Improved GPU module and the new opencv_stitching application that can run on CPU only, but can utilize an NVidia GPU when it's available. * New calibration pattern, new feature descriptors BRIEF and ORB. * Improved and stabilized Python support, now with complete documentation with growing number of samples (the latter is the ongoing GSoC project) Improved Documentation 3 reference manuals have merged together. Grammar, style of the look of the documentation has been significantly improved, thanks to the professional technical writer. 121 Fixed Bugs The whole month the team has been working on fixing bugs and improving documentation. 121 tickets in OpenCV bug tracker have been closed during June, bringing the total number of open tickets to just over 200 (including minor bugs, enhancements requests etc.)
Vadim
# (OpenCV release: # 3 is finally done!) OpenCV # # 0 final has been released. The announcement is here: http://tech.groups.yahoo.com/group/OpenCV/message/81509. The main work has been done on the documentation - merging several reference manuals into one, and on the preparing windows package. Also, a few bugs in the # 3rc have been fixed. See below on each of the items. # (Documentation) The 3 reference manuals, covering C, C++ and Python, have been merged together. Besides, the new-new Python interface is put there too. It's all available now at http://docs.opencv.org. Thanks to the shared description it will now be much easier to maintain the documentation. Besides, the Java interface description can be semi-automatically integrated there as well. Our technical writer made some final touches to the documentation and reviewed the new material, added after merging the reference manuals. # (Windows package) The huge problem on Windows, when using Microsoft compilers, is that different versions use different, incompatible runtime and applications built in debug have to link debug versions of DLLs, otherwise it will crash. I submitted a poll: http://tech.groups.yahoo.com/group/OpenCV/surveys?id=3051965, asking people what they want, and they appear to want pretty much everything. My multiplying all the needed variants: 4 compilers x 32-bit/64-bit x debug/release x static/shared x TBB on/off we get 64 variants of OpenCV! Plus we need at least 3 different Python wrappers. By excluding VS2005 and setting TBB=on in the case of DLLs we can bring this number down to 24 variants. Then the first package has been built, it was ~300mb archive. After a few days of tweaking make scripts, stripping debug information, making universal ffmpeg plugins, building Python wrappers statically (so they are absolutely self-contained), and by using a better compression the package has been brought down to ~100mb, which has been uploaded to SourceForge as opencv-# # 0-win-superpack.exe. It is not an installer, just a self-extracting archive. # (Bug fixing) 8 tickets have been closed this week. # (GSOC) Alexander added 8 more Python samples. OpenCL project is stuck. Some first code is received, but it mostly a stub thing. Will make another attempt to motivate Salman to do something better. * _*Anatoly Baksheev*_ * 1) opencv_stitching · Optimized building of warping maps using GPU in opencv_stitching. As result we have 2x speedup ( 40sec -> 20sec) for the whole compositing pipeline in case of spherical warping 12 Mpx photos. · Optimized pyramid-related stuff with GPU and got ~ 2x speed-up for it. This does not have big impact on total pipeline time. o May be will re-implement after, because we expected >10x (speed-up of Gaussian Blur on GPU), but got only 2x. It seems that CPU pyramids are hardly optimized (hardcoded blur 5x5 that is mixed with sampling, etc.), so we can get ideas for GPU here. 2) Auto calibration & reconstruction · Implemented synthetic datasets generation framework (opaque spheres and cubes from points, rigid camera matrices, "photos" with keypoints and correct matching). · Started implementation of tests for the whole auto-calibration pipeline. We want to cover the code with a lot of tests in order to find most computationally unstable parts of it. Issues: · Found that reconstruction pipeline can't handle scene with a cube and 15 cameras around the cube in the (OXZ) plane (it can't continue after half of images). 3) PCL · Implemented octree building with global barrier. Caught a lot of bugs, but not all. (Some blocks of octree structures exactly match with tested CPU prototype, but total number of nodes differs). · Approximate work time for 870k points ~10ms (without memory allocations etc.). This may change in future after bugs will fixes. PCL Octree is built for 75ms. Kirill Garanzha claims 8.1ms for HLBVH in his paper. Plans: · Find root cause of problems in reconstruction pipeline. Continue testing of auto-calibration. · Catch all bugs in octree implementation, refactor and clean code, trivial optimizations ( reduce memory allocations, etc.). o Implement radius search on GPU. · [low priority] Try to port original CPU pyrUp/ pyrDown implementation. · [low priority] Add support of different interpolation and border modes into gpu::remap, as it's one of hotspots.
Action Items
Gary
- Talk with Nathan about rsync ’ing opencv.itseez.com to opencv.willowgarage.com/documentation
Radu
Vincent
Alexander
Vadim
Victor
- Get ftp site for copying documentation and access for us to automatically copy
Kurt
Ethan
James
From last time
Gary
Radu
Vincent
Alexander
Vadim
- Talk with Vincent about python bindings
- Talk with James about Python bugs, especially related to numpy
Victor
- Test code and documentation for DOT
Kurt
Ethan
James
Agenda
- Python bindings
- Khronos
-
SFM/Bundle adjustment, SLAM
- What is where
- GSOC reviews in
- Autodoc update
Minutes
-
SLAM in kforge
- mega-slam
- multi-slam
- Bundle adjustment
- One for image stitching camera focus stays on the same 3D point so homography works for any 2 images (in image stitching app)
- OpenCV has LM solver for camera calibration etc … bundle adjustment is just sparse LM (fast way of doing LM optimization)
- GPU does dense LM taking advantage of the GPU
- No bundle adjustment for monocular slam
- For stereo SLAM, use the bundle adjustment in ROS, but has problems. (vslam stack).
- vlsam: pose est has SFM, 3Dto3D R,T finder, SBA (sparse bundle adjustment), place recognizer … might make use of.
- Also see http://openslam.org/ visual odometry and slam systems
- vlsam: pose est has SFM, 3Dto3D R,T finder, SBA (sparse bundle adjustment), place recognizer … might make use of.
- Khronos
- Need to update the document
- Vadim did experiments with OpenCL
- Experimented with python bindings for OpenCL
- Compose code in the form of a text string and then OpenCL compiler computes
- For matrix multiply 1000×1000. OpenCL did 15x faster on GPU than OpenCV matrix multiply on CPU
- On CPU it was 10% slower
- Vadim did experiments with OpenCL
- Need to update the document
- Android — need to get back to Rodrigo who is getting back early August (when I go on vacation …)
- Train up high value classifiers
- Line-mod
Vadim
# (Bug Fixing) Despite that # # 0 is out, there are still quite a few (>200) open tickets in the bug tracker, plus the new bugs are reported on a regular basis. So, the work on cleaning the bug tracker continues. 14 tickets have been closed last week. # (Python bindings) cv module (previous-generation bindings) has been embedded into cv# Users of the cv module should replace: import cv in their code with import cv# cv as cv This is the only change to be made. After the change all our Python samples and tests run fine. With the change we further improve OpenCV compile time and reduce the footprint of binary packages, especially on Windows, where cv.pyd and cv# pyd are built statically (i.e. they contain the whole OpenCV), so by getting rid of cv.pyd we reduce the package size noticeably. # (Optimization) There have been several reports that OpenCV has a few performance regressions, comparing to 1.x and # 0. One of such report was about calcOpticalFlowPyrLK. The C++ version was several times slower than the C version. Last week the code has optimized using SSE2 and parallelized using TBB. As a result, the new implementation is >9x faster than the previous C++ implementation and ~2-3x faster than the C version. The C version has been dropped and replaced with a thin wrapper on top of C++ function. # (GSOC) Alexander added 5 more Python samples, covering optical flow, motion templates, contours and face detection. OpenCL project is very slowly emerging. There is the first code drop in ocl branch, but it is far from being usable yet.
Victor
Model capture. Vslam has been enhanced to support bag files in tod format (synchronized topic with points, image_color, camera_info). Experiments with kinect bags show good camera trajectories but inconsistent point clouds. We are working to explain the latter [Alexander] Several experiments with Meshlab to create a CAD model from a point cloud. Kinect was connected to Meshlab with an experimental plugin from the Meshlab trunk. Experimented with MeshLab to create a model of an object (it has several algorithms of surface reconstruction from a point cloud). Attached is the constructed model of the blue bowl when the object is captured from several close viewpoints (cloud.png, model# png) [Ilya] Experimented with the rgbdslam ROS package developed by the University of Freiburg to get a point cloud of an object. It seems to work well for a large textued environment but accuracy is insufficient for creating a model of a small object. For example, we got several close point clouds of the object instead of single one. So the created model has a lot of artifacts (in the best case) -- see gicp.png. [Ilya] Buildbot: changed script for uploading OpenCV HTML documentation to the FTP using ncftpput. Uploading time is decreased from 1.5 hours to 20 minutes. Now we uploading OpenCV trunk documentation to thehttp://docs.opencv.org/trunk, release version is still available on http://docs.opencv.org. Buildbot user interface has been moved to a separate workstation to minimize response time. [Andrey, Alexander] OpenCV: Resolved the tickets #1206, #1179, #1162, #108. [*Maria*] Other: the paper by Victor Eruhimov and Wim Meeussen "Outlet detection and pose estimation for robot continuous operation" was accepted for IROS 2011. Maria was on vacations till July 8th.
Anatoly Baksheev
1) OpenCV GPU· Fixed compile-time error in BFM test (it was revealed under ubuntu x64 in debug mode).
· Fixed mean-shift filtering in response to Yahoo Group question, so that it support CC <=1.1 now
2) PCL Octree
Accomplishments & statuses:
· Fixed bugs in parallel octree building on GPU. So now I have working version. Speed-up is data and parameters dependent and varies in 10x-30x range.
· Implemented radius search on CPU that uses Octree downloaded from GPU. This is preferable for several single queries. ~2x faster for best parameters.
· Implemented but not debugged parallel batchRadiusSearchGPU. I guess I found efficient way to process leafs. Paused the activity in order to refactor and integrate code to PCL.
· According to Radu’s request, refactored code a lot, dropped unused functionality, and prepared for PCL commit, integrated into PCL build system, write several simple tests, etc.
Interface is nice, but code inside is far from production quality. But I will commit today or tomorrow in order to get feedback from other PCL team.
Some performance numbers:
Data set:
871k points (uniformly distributed), volume size 1024f * 1024f *1024f.
10k queries for readiusSearch, with radius uniformly distributed in [0..1024f/15f].
Parameters:
For PCL Octree, resolution = 25f. Such resolution provides the best search performance. Build or search time rises drastically to seconds if change this.
For my OpenCV Octree contributed in 2009, max_points_per_leaf = 20, max_levels = 10.
For GPU octree, max_points_per_leaf = 10 (hardcoded), max_levels = 10 (doesn’t support other at all).
Hardware: GTX470 vs. Core i5-760 # 8Ghz
Build time: PCL – 232ms, OpenCV 351ms, GPU – 19ms(build) + 11ms (download to CPU for radius search there).
Numbers don’t include point cloud construction time and upload to GPU.
Radius search: PCL 650ms, OpenCV – 383ms, OctreeGPU.radiusSearchCPU (CPU search using downloaded octree) – 382ms.
Please note that PCL returns vector of distances, but my implementations don’t.
Plans of PCL:
· Finish batchRadiusSearchGPU.
· Optimization of Octree building and batchRadiusSearch. (Have a lot of ideas).
· Bring code to production quality.
· Probably start knnSearch?
· May be try parallel brute force GPU radius search to understand how and where octree helps (fast to implement).
Also I have ideas to investigate possibilities of fusion octree building with SRTS radix sort into one algorithm. I guess there might be very good finds and performance like 4ms to build 871k points. But I think I don’t have time for it.
3) Auto calibration
Accomplishments & statuses:
· Tried gold standard triangulation described in Multiple View Geometry (Zisserman) instead of one described in Pollefeys’s tutorial. It doesn’t affect results very much.
· Fixed bugs in merging based and incremental projective reconstruction pipelines. Both now work correctly on synthetic datasets without noise.
Just some numbers for merging based reconstruction pipeline. We use synthetic datasets, i.e. out data is without measurement noise.
Linear auto-calibration for initial K = (Description: image.png ) = (Description: image.png ) returns K_result = (Description: image.png ), while ground truth = (Description: image.png ).
Adding small Gaussian noise (mean=0, stddev=0.1) changes results in the following way:
a) for cube dataset calibration matrices are different for different cameras (e.g. mean of focal length=434, stddev=267),
b) for sphere dataset results are much better (focal length mean=743, stddev < 1, i.e. returned results are correct).
Increasing noise (stddev = 1) makes results for cube dataset even worse, results for sphere datasets are still good (focal length mean = 707, stddev = 18).
For incremental projective reconstruction pipelines final reprojection error is higher and auto-calibration works worse.
Issues:
· Spent two days trying to make work simple auto-calibration described in “A Simple Technique for Self-Calibration” paper. No success. Perhaps Lev.-Marq. method isn’t good enough for such purposes (quasi-Newton method is used in the paper).
· Implemented auto-calibration technique is still unstable on noised/real data. Many researches also states that and trying to do something with it. There are few candidates to be implemented in papers.
Plans for Auto Calibration:
· Try non-linear refinement of auto-calibration results proposed in “Robust Metric Reconstruction from Challenging Video Sequences” paper. Authors say it stabilizes auto-calibration process (they use the same linear auto-calibration as I).
· Try to improve merging based reconstruction pipeline by implementing robust merging scheme described in “Accurate Camera Calibration for Off-line, Video-Based Augmented Reality” (they use MLESAC with non-linear refinement). For now I have linear merging only.
· Try to apply any open source implementation of quasi-Newton method for another auto-calibration technique (from “A Simple Technique for Self-Calibration”).
Action Items
Gary
- (./) Talk with Nathan about rsync ’ing opencv.itseez.com to opencv.willowgarage.com/documentation
- Send out reminder for GSOC reviews
- Tell Radu
- Help Maria get on kforge for the line-mod code
Radu
Vincent
Alexander
Vadim
Victor
- (./) Get ftp site for copying documentation and access for us to automatically copy
- Write Kurt for access to kforge code
Kurt
Ethan
James
From last time
Gary
- (./) Talk with Nathan about rsync ’ing opencv.itseez.com to opencv.willowgarage.com/documentation
Radu
Vincent
Alexander
Vadim
Victor
- (./) Get ftp site for copying documentation and access for us to automatically copy
Kurt
Ethan
James
Agenda
- OpenNI “sucks” when rectified. Patrick solved this for ROS
- OpenCV V2 started … convert code to C++
- Khronos?
-
SFM
- Talk to Vincent about SFM, stitching and blending code
- GSOC intern working on libmv
- Other themes of the next release?
- Object recognition
- specialized cascades for humans
- human recognition via MS method with the kinect
- Line-mod?
- Good module working with kinect
- Khronos
- API
- Object recognition
Minutes
- Linemod
- Does quite well, but multiple limitations
- No save, no multiple obj in same frame, occlusion problems, not modular (parts based), needs help in auto-generating scale and rotation, scaling the learning
- Sparse template, how to scale?
- The code is really just one big main function, the functions are not modular, they are mixed gradient+
- File bug report on openni drivers when rectified
- libmv as basis of SFM in openCV
- Releases
- Next patch release has Java binings and some Android demos and bug fixes
- Android or Desktop or both this release?
- # 4 Plans
- line mod
- tod
- sfm
- Cendric had reimplemented MS pose detector for kinect
- Next patch release has Java binings and some Android demos and bug fixes
- MS computer vision summer of code
**
Vadim
# (FLANN) FLANN 1.6 has been re-integrated to trunk. "miniflann" template-less and Python-, Java-friendly interface has been introduced. It is 99% compatible with the normal FLANN interface (in Index::radiusSearch() call 1 extra parameter needs to be passed to fix the remaining 1% of issues). Now FLANN can be accessed from Python. # (Bug fixing; Python bindings) 11 track tickets have been closed. Several modifications have been made to Python bindings, OpenCV headers, and the bindings generator to make it more consistent with the upcoming Java bindings. # (SVN => Mercurial) Since OpenCV development becomes more and more distributed; 3 teams at Itseez are working on it, plus there are GSoC projects and some new functionality is being developed at WG, it makes sense to transfer OpenCV repository to a distributed code management system, such as GIT or Mercurial. Andrey and Alex made seminars about the tools, from which Mercurial appears like a good first candidate to consider. Since code.ros.org does not support Mercurial, we've created experimental OpenCV project a kforge.ros.org (with the help from Eitan), where I uploaded the converted Mercurial repository. If we manage to migrate our bug tracker there (or, as an alternative, just fix it down to zero size :) ), we can migrate to kforge.ros.org and enjoy distributed development process. # (GSOC) Alexander (Python samples) has passed mid-term evaluation and continues working on the samples (and even doing some fixes in Python bindings). Salman (OpenCV+OpenCL) failed. # (OpenCV functionality and API for the standard) Just started working on the document. First version should be expected by the beginning of the next week.
Victor
Model capture: vslam stack has been adapted to take data from kinect (image+point cloud as opposed to 2 images from a stereo camera). The code works on bag files captured by kinect, but there are a few issues: 1) kinect depth map can be obtained from 0.5m, and the color camera is low quality so often we don't get enough texture to track the object through the whole bag file. We have plugged into vslam a pose estimator that uses a circle grid template finder to initialize camera pose. However the template is not seen on all frames. 2) Even when we calculate camera trajectory based with the template finder, we get few points in the point cloud since we track only textured features. Here we will have to move to an ICP-based dense bundle adjustment (talked to Nikola about this). [Alexander] Experimented with 3D scene reconstruction using Kinect RGB Demo showed similar results to the rgbdslam package: it can create a good model of a large textured environment but the accuracy is insufficient for object modelling. Experimented with point clouds registration using Meshlab and Scanalyze (developed in the Stanford by Kari Pulli and Matt Ginzto). A dataset with 8 Kinect images of the 'objects on a table' scene was created. The step between frames is approximately 45 degrees so they span all 360 degrees of viewpoints. Point clouds have been registered using 3D coordinates only. Automatic registration from Scanalyze has not succeed so they were roughly aligned manually (later it will be done by VSLAM) and then are registered globally by Meshlab. The result is in registration.png attached. The model of the whole scene has been created using Meshlab: smooth.png, triangulation.png. [Ilya] Untextured object detection. Experimented with LineMod code to study the algorithm capabilities for textureless object detection problem. 1) Trained detector online and detected some objects using original code (it gets rgb image and depth map from Kinect). - The detection is robust given 3 objects (see orig_linemod.png). - The algorithm for segmenting the foreground object does not work on our bag files -- the points within a rectangle around the object are required to be textureless and lie in the same plane. - It is not designed to detect several objects of the same class, selecting a single hypothesis with the maximum confidence. - An ability to save a trained detector is not implemented in original code (it's very inconvenient to retrain a detector every time). 2) We have modified LineMode code to run it on plates_cups_and_bowls base (this base has been used to test DOT): - Tried to replace Kinect rgb and depth images by the corresponding images and point clouds from the training base. The object mask was obtained from the tod masker (we set rgb pixels masked as "background" to the constant color). - Implemented the detection hypothesis filter that allows several detections per training frame. - An example detection is in the attachment (linemod-detection.jpg). The results are much better than what we had with DOT. In the most of cases an object existing in training base was detected correctly or as very similar object. [*Maria*]





Anatoly Baksheev (GPU)
1) PCL Octree · Implemented batchRadiusSearch on GPU. Did several optimization iterations. Speed-up is about ~10-20x. Found and fixed ~5 difficult bugs. · Fixed compilation issues under Ubuntu. · Updated the code to product quality, refactored tests, and committed changes. 2) Auto calibration Implemented: · Added non-linear refinement into auto-calibration process. · Replaced RANSAC with MSAC in reconstructions merging code. · Implemented robust version of auto-calibration. It tries different subsets of projective cameras. · Added a priory information handling into SBA process (zero skew, principal point at image center). SBA library doesn't allow to change cost function in easy way, so had to add extra terms via "virtual" points and its projection code. Research & studying · Found the explanation why projective reconstruction (and as result auto-calibration results) can be poor on some Oxford datasets in the paper "The Problem of Degeneracy in Structure and Motion Recovery from Uncalibrated Image Sequences" (only or almost only co-planar points is degeneracy case for fundamental matrix estimation). Guess it explains poor results on the synthetic cube dataset, because the first image in the sequence is cube face. · Tweaked parameters a lot. Now both merging and incremental based reconstruction pipelines return quite good projective reconstructions, which can be used for auto-calibration on non-degenerate datasets. On non-degenerate cases it never fails, but auto-calibration quality depends very much on initial intrinsic parameters. Issues: · Wedham College is the best dataset amongst all Oxford datasets. Other ones requires hard parameters tweaking or contain degeneracies. It will be hard for user to create images sequence without critical motion subsequences, degeneracies, with optimal base-line, and so on. Think about using video for camera calibration, because video contains redundant data and good sequences for reconstruction can be extracted from it automatically (e.g. one method is described here "Robust key frame extraction for 3D reconstruction from video streams"). Plans: · Still have some optimization ideas to check for both Octree building and batchRadiusSearch (low priority). · Add possibility to pass array of pcl::PointXYZ to OctreeGPU. Or may be other point types from PCL CPU part. I didn't do it before, because of unclear OctreeGPU user's needs. · Think if it is possible to implement knnSearch on GPU efficiently. Think what else I can implement on GPU from PCL::Octree CPU functionality. And talk with Radu about next PCL task. · Find/create video datasets for autocalibration. · Implement extraction of good image sequences from video. Other: · Most of OpenCV team including me will be on vacations for Computer Vision Summer School (by MS Research) in Moscow for a week since 27 of July.
Action Items
Gary
- (./) Talk with Nathan about rsync ’ing opencv.itseez.com to opencv.willowgarage.com/documentation
- Get Ethan to file a bug report on openni drivers
- Have Vincent talk sfm with Victor et al
Radu
Vincent
Alexander
Vadim
Victor
- Write Stephan and CC the rest about refactoring the linemod code
Kurt
Ethan
James
From last time
Gary
- (./) Talk with Nathan about rsync ’ing opencv.itseez.com to opencv.willowgarage.com/documentation
- (./) Send out reminder for GSOC reviews
- (./) Tell Radu
- (./) Help Maria get on kforge for the line-mod code
Radu
Vincent
Alexander
Vadim
Victor
- (./) Get ftp site for copying documentation and access for us to automatically copy
- (./) Write Kurt for access to kforge code
Kurt
Ethan
James
Agenda
- Lots of documentation does not index well on opencv.itseez.com
- example search on logpolar, or getaffinetransform click on the link, it only goes to the top of the section, not to the logpolar description
- What functions are not in C++? Logpolar is one.
- It would be nice to include in the documentation, what headers go with what
- HoG Filter — in GPU, test is in C++, right?. Which exact algorithm?
- Same for Latent SVM … might want to use this.
- Plans
- Line-mod, too many people?
- Itseez move to sparse features??
- People detection
- vSLAM
- Model capture
Minutes
- Documentation
- Some functions (Camel case), the search results go to the top of the page, not to the function
- This is a case sensitive Java script problem
- Don’t know how to fix …
- Some functions (Camel case), the search results go to the top of the page, not to the function
- Good to get linemod in, Patrick working on it
- How to scale is the research issue
- Making a tracker out of it is also a bit of research for how to use a que of templates
- Kinect
- Rectified images glitch
- Want a way to register a better camera with the kinect
- Nice to get projector-camera(kinect) registration
- Converted 2, 4, 5, 6, half 7, 8, 9(1), 10 (easy)
- 3 (Adrian), 11, 12, 13
-
HOG
- C++ and GPU, but no documentation in C++
- Dalal and Triggs detection part. Our descriptors == standard ones so we can use their SVM vectors (linear SVM)
- Felzenschwalb
- We just implement the detection part.
- We don’t have training code and the format that we use is different and no conversion tools
- Needs images and bounding boxes and it produces several SVM (each part: size rectangle, weights of the part)
- Template with 2 views with 5 parts, would need 12 rectangles and 12 vectors
- OpenCV wants sizes of main rectangles and parts, and the decision vectors for main templates and parts
- University work
- Cascade version of Felszenschwalb is nearly done
*
- Cascade version of Felszenschwalb is nearly done
Vadim
# (OpenCV functionality and API for the standard) The document has been prepared and sent last week. It is also attached to the report. It lists the most important OpenCV functions and algorithms. Each algorithm is ranked in terms of computational complexity and potential scalability. # (OpenCV book v2) Converted samples from ch5, ch6 and ch8, as well as parts from ch7 and ch10. # (SVN => Mercurial) The migration is on hold, since Nathan should make a dump of our bug tracker. # (Bug fixing) 6 bugs have been fixed + a formatting of opencv2refman.pdf has been fixed and improved. # (OpenCL) Continued exploring OpenCL. The abstraction layer for OpenCV is being written that will cache compiled kernels between function executions and probably even between program executions.
Victor
Linemod: Implemented saving/loading of linemode templates to .xml. Probably, this implementation and file format will be changed after linemode existing interfaces refactoring or by other reasons, but we need persistence functions to speed up our experiments with linemode. We don't store the algorithm parameters, because we works with the default now. Implemented another hypotheses generator that returns multiple hypotheses per location. The previous algorithm returned a single hypothesis for each location and often mixed up similar objects. Now linemod returns all classes that have high score for a specific location (see hyp_several.jpg). [*Maria*] Model capture: We were able to get a trajectory of a kinect and the corresponding point clouds from VSLAM. Two patterns with grids of circles are used for pose estimation that is plugged into VSLAM through standard posest::PoseEstimation interface (instead of pe3d). VSLAM generates a single bundle-adjusted point cloud but it is not enough for us since the cloud contains only textured points found by a feature detector. A planned solution is to have an ICP-based bundle adjuster but meanwhile we use Meshlab for this: the point clouds from each frame are transformed into the same reference frame according to the position found by vslam, then they are exported to meshlab that has its own global registration algorithm. This is how we get a dense point cloud and then create a triangulated model. Several details: - Experimented with ORB detector/descriptor within vslam framework. Got similar inlier count in comparison with FAST/Calonder, FAST/SURF. - Added filtering of the table and background - Added working with two circle grid templates for full object scanning. - Picked up SimpleBlob detector parameters, after that the detection rate of the circle grids is ~99% [Alexander, Ilya] Issues with Kinect: Kinect noise was analyzed by performing a following experiment: a flat empty wall in the office was captured by Kinect several hundred times after sunset and standard deviations of depths in each pixel were computed. It was found a Kinect has a specific pattern of noise consisting of several vertical bands (std.png, black is zero deviation and white is 10 mm). Also it was found that the first measurements are the most noisy: the noise can be reduced by waiting 30s before capturing Kinect data (stdWithWait.png). Then the accuracy of Kinect relative to distance was estimated by taking mean of these standard deviations (accuracy.png). So practical recommendations for object modelling are: # Put object at 0.5 - 1 meters away from a Kinect. # Capture one frame and wait 30s before capturing following frames. Unfortunately, the pattern of Kinect noise looks unpredictable so we can't use it to filter out noisy measurements. [Ilya] Experiments with kinect superresolution: we made an an attempt to reconstruct higher-frequency 3D details from a series of kinect frames. Farneback is used for dense optical flow, the algorithm is similar to S. Schuon, C. Theobalt, J. Davis, S. Thrun, LidarBoost: Depth Superresolution for ToF 3D Shape Scanning, CVPR 2009. See animated gif sr.gif for results (800 images were acquired from almost the same viewpoint and images were resized with # 71 factor). This algorithm can be applied to get a depth map with high-resolution but currently it has too many artifacts on textureless areas.
Anatoly
1) OpenCV GPU· Implemented cv::gpu::pow (for images). Investigated differences with CPU implementation (GPU is smarter and better) and corrected tests.
2) PCL Octree
· Redesigned internal structure of OctreeGPU, so that now it uses aligned pcl::PointXYZ. Before conversion to pcl::gpu::PointXYZ was required. In future I am going to follow this design and suggest Radu doing the same.
· Implemented version of batchRadiusSearchGPU that uses separate radius for each query in passed batch.
· Implemented approxNearestSearchHost and approxNearestSearchBatchGPU. GPU batch version ~50x faster than Octree on CPU but returns slightly worse results:
o for 1/3 of queries results are closer than from PCL,
o for 2/3 farther . Let Dpcl = distance(query_point, results_pcl_cpu), Dgpu = distance(query_point, result_pcl_gpu). Average(Dpcl Dgpu) = 13, when Octree voxel size = 102# f x 102# f x 102# f;
· Added tests and performance tests for new functionality.
· Started brainstorming how to implement exact knnSearchBatchGPU.
3) Auto calibration
· Implemented robust key frame selection scheme according to “Robust key frame extraction for 3D reconstruction from video streams” paper. On dataset we found (Medusa video sequence) it leaves too few frames to start reconstruction. More parameters tweaking is required.
· Implemented naive 2 views auto-calibration (closed-form solution using fundamental matrix only, according to “The Geometry of Multiple Images”). Going to compare it with our auto-calibration framework.
· Implemented optical flow based matcher, as it can be useful in video sequences auto-calibration.
· Measured auto calibration accuracy data on some real/synthetic datasets. Conclusions:
o Auto-calibration consists of two steps: finding projective reconstruction and upgrading it to metric one. The second step works ideally on good projective reconstruction from first step.
o Auto-calibration works very good on synthetic datasets, if the datasets aren’t degenerate and doesn’t contain critical motion subsequences. Focal length and principal point coord. relative error is 1-3% (some tables attached).
§ We spend some time investigating why our previous synthetic sphere dataset had such degenerate cases.
o There is only one good real dataset Merton College III (screenshot below) among four tested, where auto-calibration produces stable results (tables attached). Other datasets are not so good, perhaps due to degeneracies and/or small baseline.
o Issues are, most likely, in projective reconstruction step (first step). So going to debug it and investigate other approaches of finding projective reconstruction.Plans:
· Debug auto-calibration on synthetic and real datasets (in order to find not bugs, but different degenerate cases, sacrifices of accuracy, etc.)· Brainstorm how to implement Octree knnSearchBatchGPU
· Discuss with Radu PCL GPU interface.
· (low priority) Implement fast pyrUp, pyrDown on GPU (current trivial GPU implementation isn’t faster than CPU one, because the CPU version is super-optimized). Required for opencv_stitching on GPU.
Other:
· OpenCV team will participate for Microsoft Computer Vision Summer School in Moscow for a week since 27 of July.
Action Items
Gary
Radu
Vincent
Alexander
Vadim
Victor
Kurt
Ethan
James
From last time
Gary
- (./) Talk with Nathan about rsync ’ing opencv.itseez.com to opencv.willowgarage.com/documentation
- (./) Send out reminder for GSOC reviews
- (./) Tell Radu
- (./) Help Maria get on kforge for the line-mod code
Radu
Vincent
Alexander
Vadim
Victor
- (./) Get ftp site for copying documentation and access for us to automatically copy
- (./) Write Kurt for access to kforge code
Kurt
Ethan
James
Agenda
- Most people still on August vacation, just some updates
Minutes
- Version 2 of Learning OpenCV now has
- Complete code conversion (for V1 functions)
- 2 chapters written of ~13
- # # 1 release to support Java/Android
- ~100 bugs fixed since release
- ~30 bugs fixed in August
- New tutorials (up to date is on)
- http://docs.opencv.org/trunk/
Vadim
# (OpenCV # # 1; bug fixes) All the past 3 weeks have been spent in preparations to # # 1, which should be out in a day or two. 26 tickets in the bug tracker have been closed + 2 crashes in our tests have been fixed. # (Planar subdivisions in C++) Planar subdivision have been ported to C++. The previous C interface has been extended with some useful functions, like "get the list of triangles", "get voronoi cells". Delaunay sample was converted to C++. # (Contributions) Alexandre Benoit contributed the code with retina model (http://www.lis.inpg.fr/pages_perso/benoit/resultats_demos.html.en). It was put to contrib module. Marian Zajko contributed support for Ximea cameras (www.ximea.com). The code has been put to highgui module. # (GSOC: Python Samples) 3 new samples added: HOG people detector, flann and camshift. Started the work on creating shell (meta-demo, that will contain a list of samples with their descriptions).
Victor
Model capture: experiments with vslam and various combinations of detectors/descriptors still show unstable tracking that results in a point cloud with multiple copies of the object or parts of the object (such as cup handles). Experiments with DWO-SLAM also show poor tracking quality. We have integrated tracking with circles grid templates into both slam codes to improve pose estimation, and this improves the quality of the final point cloud but still is not enough for model capture. Untextured object detection: Captured a larger dataset of 27 untextured objects in TOD format, including metal knifes and forks. Experiments with linemod on this dataset are on the way. Transparent object detection: captured a dataset of 12 transparent objects. Stereo data was captured using a painted copy of each object (see attachment). Experiments with 2D edge model fitting on this dataset are on the way. OpenCV: Improved CMake script finding OpenNI (#1190, #1252), fixed memory leak in SIFT wrapper (#1288), implemented read/write methods for classes SimpleBlobDetector and DenseFeatureDetector and added an ability to create their objects using FeatureDetector::create method (#1290). Other: Victor is on vacations till August 29.
Anatoly Baksheev
Accomplishments & statuses:
1) OpenCV GPU· Minor refactoring & fixes(gpu test failure on empty test data, moved GpuMat class to separate header file, etc.)
2) OpenCV stitching
· Minor stitching optimization & refactoring’s (improved buffer reuse, updated command line interface to allow user to turn off bundle adjustment, etc)
· Implemented optimized version of gpu::BruteForceMatcher::knnMatch for k == 2 (~2x speedup). This improves stitching performance for low- and middle- resolution images.
· Added saving of matching graph in DOT format.
· Added CameraInfo class (for future handling initial values of rotation matrix).
3) PCL Octree GPU
· Added support of pre-Fermi (emulation of some Fermi-intrinsic, modified kernel launch configuration, etc.). This was done according to Andreas Mutzel’s request.
· Implemented and debugged knnSearchBatch for OctreeGPU. K is fixed to 3# Current implementation works significantly slower (>10x) than CPU version. Profiling and trying to optimize it.
4) Auto calibration
· No update. Last status was: algorithms works on synthetic datasets, but don’t on real data.
· Plans to find-read-try other approaches of constructing projective reconstruction. May be prepare summary of the project when Victor returns from vacations.
Plans:
· Continue Octree::knnSearchBatchGPU optimization.· Read the following paper: “From Pictures to 3D: Global Optimization for Scene Reconstruction” by Manmohan Krishna Chandraker about SaM and global autocalibration, maybe try to implement some ideas.
· Add handling of rotation matrix initial values into opencv_stitching, because they are available on mobile devices from sensors (we talked about it with Peter Karasev).
· Re-Implement fast pyrUp, pyrDown on GPU. Required for porting some left components of opencv_stitching on GPU.
· Optimize memory usage in gpu::BruteForceMatcher::knnMatch when k == #
Action Items
Gary
- (./) Talk with Nathan about rsync ’ing opencv.itseez.com to opencv.willowgarage.com/documentation
- Get Ethan to file a bug report on openni drivers
- Have Vincent talk sfm with Victor et al
Radu
Vincent
Alexander
Vadim
Victor
- Write Stephan and CC the rest about refactoring the linemod code
Kurt
Ethan
James
From last time
Gary
- (./) Talk with Nathan about rsync ’ing opencv.itseez.com to opencv.willowgarage.com/documentation
- (./) Send out reminder for GSOC reviews
- (./) Tell Radu
- (./) Help Maria get on kforge for the line-mod code
Radu
Vincent
Alexander
Vadim
Victor
- (./) Get ftp site for copying documentation and access for us to automatically copy
- (./) Write Kurt for access to kforge code
Kurt
Ethan
James
Agenda
- Release
- Khronos
- Xilinx
- GSoC
Minutes
- # # 1
- Java interface for Android
- Desktop Java possible with additional work
- 100 bug fixes
- New version of FLANN
- Improved python bindings and more samples
- Java interface for Android
- Android team will soon have performance monitors
- This will help us optimize performance on Android
- 3D reconstruction
- Andew Davis approach: form real
- Replicate Kinect Fusion
- 3-4 papers with promising results
- CTG — high quality dense reconstruction
- For sure we need bundle adjustment
- Differences between algorithms Jacobians analytic or numeric
- Monocular vs Stereo settings
- Talk with Kurt
- Intern with Xilinx doing vSLAM? Also camera and projector systems
- Alexxander B. To evaluate his student while he’s on vacation … Demos with this
- iOS … commits … don’t know. Aug 18th commit was latest. Need reports
- Tutorials went pretty well — both students passed of course.
Vadim
# (OpenCV # # 1) OpenCV # # 1 is out. 7 more tickets have been closed. # (GSOC: Python Samples) Alexander Mordvitsev created preliminary version (to be polished this week) of the demo shell that lists the samples. User can see description of each sample and run it. # (Sparse Bundle Adjustment) Started yet another attempt to implement sparse bundle adjustment in OpenCV. The goal is to replicate functionality of sba package (http://www.ics.forth.gr/~lourakis/sba/). The algorithm core that inverts the sparse (J'*J+mu*I) matrix has been written and debugged.
Victor
Model capture: results with KLT+ICP tracker have been improved after parameter tuning. However the model is still far from perfect (see attached examples of captured models camera_model.jpg and cup_model.jpg). Tracking fails when texture is insufficient, noisy cloud, insufficient accuracy of trajectory obtained from template pose estimation. Transparent object detection: evaluated the edge pose estimation algorithm on transparent objects. If the initial pose is not too far away from the ground truth and the clutter is limited, the pose is successfully reconstructed. Attached are images of a point cloud of a transparent glass together with symmetry axis that shows pose: originalAxis.png -- initial pose, finalAxis.png -- final pose. Untextured object detection: evaluated linemod on white_objects base (this is a base of 12 painted transparent objects). - Test data: We have 2 test bases for such objects: transparent and painted. We used painted test base. Implemented the masker for the test base to evaluate the detection rate. The masker registers point clouds of objects from all test images (of a given bag file) in abstract reference system, filters out the table and outliers and clusters the filtered point cloud on several objects, then projects each cluster to each test camera pose to get the masks. This masker works correctly if objects are sufficiently large and not too close to each other. With some manual postprocessing now we have a test set with correct object masks. -Test system: Implemented an evaluation system for object recognition on given format of test base. Evaluation is performed for linemod with 2 types of hypotheses filers: one hypothesis per location and several hypothesis per location. The results for one hypothesis per location are below. Obviously, linemod is a good choice for classifying a limited number of untextured objects. Also, find attached examples of objects recognized by linemod (1-# jpg). Legend: count - Count of given class objects in the test base (in all test images). confusion matrix - Row index corresponds actual object; column index - detected object. TPR - True positive rate = correct detected objects / count FDR - False discovery rate = incorrect detections / all detections O_FDR - False discovery rate on objects of incorrect class = incorrect class's detected objects / all detections BG_FDR - False discovery rate on background = background detection as object / all detections count conf. matrix TPR O_FDR BG_FDR FDR background nan [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0] sour_creem 70 [35, 2, 0, 0, 0, 0, 0, 33, 0, 0, 0, 0] 0.5 0.054054055, 0, 0.054054055 small_bowl 86 [0, 64, 0, 0, 0, 1, 0, 0, 0, 21, 1, 0] 0.74418604 0.030303031, 0, 0.030303031 salad_bowl 33 [0, 0, 30, 0, 0, 0, 0, 0, 0, 2, 1, 0] 0.90909094, 0.23076923, 0, 0.23076923 form 44 [0, 0, 9, 37, 0, 0, 0, 0, 0, 0, 0, 0] 0.84090906, 0, 0, 0 cup 33 [0, 0, 0, 0, 17, 0, 0, 16, 0, 0, 0, 0] 0.5151515, 0, 0, 0 wineglass 77 [0, 0, 0, 0, 0, 62, 0, 8, 0, 0, 1, 0] 0.8051948, 0.015873017, 0, 0.015873017 bottle 63 [0, 0, 0, 0, 0, 0, 59, 0, 2, 0, 0, 0] 0.93650794, 0.048387095, 0, 0.048387095 glass 70 [0, 0, 0, 0, 0, 0, 0, 70, 0, 0, 0, 0] 1, 0.48148149, 0, 0.48148149 bucket 35 [2, 0, 0, 0, 0, 0, 3, 0, 33, 0, 0, 0] 0.94285715, 0.083333336, 0, 0.083333336 sushi_bowl 44 [0, 0, 0, 0, 0, 0, 0, 0, 0, 44, 0, 0] 1, 0.36231884, 0, 0.36231884 tiny_bowl 77 [0, 0, 0, 0, 0, 0, 0, 0, 1, 2, 70, 0] 0.90909094, 0.04109589, 0, 0.04109589 bank 63 [0, 0, 0, 0, 0, 0, 0, 8, 0, 0, 0, 54] 0.85714287, 0, 0, 0
Anatoly Baksheev
Accomplishments & statuses:1) Auto calibration
· Tried another non-linear refinement of autocalibration results (according to “Multiple View Geometry”). It doesn’t improve results significantly.
· Implemented autocalibration algorithm described in “Untwisting a projective reconstruction” by D. Nister (2004). It gives visually satisfactory results on almost all Oxford datasets (projective reconstructions were obtained via modifying ground truth metric reconstructions). Focal length accuracy is about 10..15% (for any reasonable start guess). On the “corridor” dataset this method fails.
· Started investigation MATLAB implementation of autocalibration algorithm described in “Globally Optimal Af?ne and Metric Upgrades in Strati?ed Autocalibration” by M. Chandraker et al. (2007).
2) PCL
· Did some profiling and performance bottleneck investigations for exact knnSearchBatch for GPU. Main bottleneck is sorting with is expensive for thread and warp.
· After talk with Radu decided to freeze exact knnSearch development until I have good idea how to make it faster. Current implementation of knnSearch is 30x slower than CPU’s. But radiusSearch and approxNearestSearch are 20x and 50x faster respectively.
· Learned some of 3D features for point clouds and PCL interface/code for this. Started implementation of PFH, FPFH feature calculation.
3) OpenCV GPU
· Optimized some primitive functions (threshold, etc.) as far as users from Yahoo groups complain for low speed-up. (It is really not high for small and average resolutions, because CPU version is super-fast and works several milliseconds).
o Added TransformFunctorTraits in order to manage transform function behavior for different functors.
o Optimized some primitives functions that use transform (20-30% speedup).
o Optimized some of color conversions for cvtColor (30-50% speedup). And fixed minor bug.
· Discussed how to implement optimized version pyrUp, pyrDown for GPU, but have not started it yet. Hope it will be 4x faster.
Plans:
· Finish PFH, FPFH, finish test for this, profile and check performance.
o Possible I need to write different version of kernels for cases: many/average/few neighbors.
· Evaluate Chandraker’s autocalibration algorithm on synthetic and real datasets.
· Implement optimized version pyrUp, pyrDown and use it in stitching on GPU for 12Mpix images.
Other:
· BTW, someone suggested background-foreground detection on GPU in our Feature Request Form. This is one point from our plan.
Action Items
Gary
Radu
Vincent
Alexander
Vadim
- Email Kurt about bundle adjustment approaches
Victor
Kurt
Ethan
James
From last time
Gary
- (./) Talk with Nathan about rsync ’ing opencv.itseez.com to opencv.willowgarage.com/documentation
- Get Ethan to file a bug report on openni drivers
- Have Vincent talk sfm with Victor et al
Radu
Vincent
Alexander
Vadim
Victor
- Write Stephan and CC the rest about refactoring the linemod code
Kurt
Ethan
James
Agenda
- Bundle
- Line mod sync up
- Transparency
- Pose
- Model capture
- Tracking
Minutes
- Linemod
- API and algorithms
- Separate out pyramid scales
- Suited for tracking, not so good for recognition
- We have set up a linemod google doc to coordinate
- Keep pose + point cloud (train and test). Then use ICP with 3D to 3D fitting
- Model capture
- Ethan’s method
- 2 dot patterns, one inverted from another
- Track’s poses
- Stores just the ones that are far enough from each other so that we don’t flood the bags
- These go into a database
- Can then use the db for model creation
- Use targets and merges the points together using Mike Krainian’s surfals which gets rid of small noise and it gives nice aligned normals
- This is then run through meshlab using Poisson to get a mesh
- Problems: Doesn’t take into account the object itself
- DWO slam (uses ICP etc to do alignment beforehand)
- Poisson tends to over smooth but we use to get water tight meshes. Surfals give better reconstruction
- Want to get a good pipeline together
- Maybe use DWO slam and then use sufals prior to
- Ethan’s method
- Transparent
- Initial view based pose
- minimize distance between training and test edges
- But can get ambiguities — need multiple view
- Bundle adjustment. Do like SBA but this is GPL, so rewritten SBA from scratch
- Our SBA is usable from JAVA and other languages since we avoid callbacks (which make it very hard to use with other languages).
- PTAM uses SBA
- Our SBA is usable from JAVA and other languages since we avoid callbacks (which make it very hard to use with other languages).
- vslam can work with mono or stereo (has many dependencies … too much code). dwo slam is simpler and assumes 3D data (Nicoli’s code). Does bundle adj based on ICP
- Schedules of trips to US for IROS.
Vadim
# (GSOC) GSOC 2011 has been finished. Python samples are already in the repository. And I also committed hybrid tracker by Alexander's student Pushkar. The tracker is based on the paper H. Zhou, Y. Yuan, and C. Shi, Object tracking using sift features and mean shift, Computer Vision and Image Understanding, vol. 113, no. 3, pp. 345 352, 2009. Video of the OpenCV implementation of the hybrid tracker is here: http://www.youtube.com/watch?v=gIcCDG_Qq6w # (Sparse Bundle Adjustment) Finished SBA implementation; started transforming findFundamentalMat(), findHomography() and calibrateCamera() in order to employ this new engine and debug it (obviously, in those functions the geometry is fixed). The next step would be to reproduce the PTAM tracker.
Victor
Model capture: Implemented an automatic pipeline for model capturing using meshlabserver and meshlab scripts. Different objects require various parameters for surface reconstruction, so I plan to run some scripts with different parameters and choose the best model manually. Also sometimes meshlab throws different exceptions ant its behavior changes from run to run. An example of automatically created mesh is attached (msvc.png, msvc_model.png). Pose estimation with a grid of circles was integrated into dwo-slam as an initial approximation of the transformation between frames. It helps with poorly aligned parts of an object in some cases. Untextured objects: pose estimation has been added to linemod. - Training was modified to store the object point cloud for each template of the train base. - Implemented pose estimation: having a patch in test image for detected object we assume that the test point cloud for this patch corresponds to the train point cloud of template and calculate rotation and translation between test and train clouds (3D to 3D). - Results of pose estimation (3D to 3D) on two test images are in the attachment (linemod_pose_1.png). The image shows a test point cloud together with training point clouds corresponding to the recognized objects with pose calculated from linemod. Transparent objects: - Reduced noise in the created model of an object by applying k-partite matching. It removes spurious edgels on contours and this is important for accurate pose refinement by edges. See the model of an object before k-parite matching (beforeKPM.png) and after (afterKPM.png). - Implemented an automatic system for evaluating pose estimation algorithm, now we have a dataset of 8 transparent objects. The attached graph (results.png) shows the percentage of successful refinements (refinement is successful if the final pose is not more than 15 degrees and 3 cm away). The main problem of the current algorithm is convergence to wrong poses which fit test edges well. For example, see a test image (testImage.png) and a refined pose (refinedPose.png). Edges are fitted well but it is the wrong pose (see pointCloudPose.png, the view from aside, green is the table and red is the object). This problem is similar to a PnP problem for an object with linear size much smaller than the distance to the camera. It is hard to solve it without additional assumptions.
Anatoly (GPU)
1) Auto calibration· Tried M. Chandraker’s method. It works on his datasets and mine synthetic dataset. But the method fails on Oxford datasets, even on reconstructions from Oxford page. Spent some time trying to resolve this issue — no success. Author noted that the method isn’t robust and the conditioning of the involved solvers is numerically sensitive. Tried data normalization — didn’t help. Perhaps the root cause is in the presence of noise/outliers. Deeper investigation is required.
· Implemented projective factorization algorithm from “Multiple View Geometry”. If we use keypoints/matches from Oxford dataset it provides reconstruction quality high enough to get autocalibration accuracy in <20% of focal length via D. Nister algorithm (it works like it was described in the prev. report, but it continue fails on the “corridor” dataset).
· Replaced the whole reconstruction step with projective factorization based code, here are autocalibration results (principal point and skew are assumed to be known):
Wedham College
Oxford
1148,98
1135,24
537,27
393,08
0
result
1084,27
1083,58
538,98
400,72
-0,38
error
- 63%
- 55%
0.32%
1.94%
0,38
Merton College II
Oxford
1157,69
1163,53
471,91
350,56
0
result
1132,65
1129,59
464,61
356,98
1,14
error- 16%
- 92%
1.55%
1.83%
1,14
Merton College III
Oxford
1032,57
1043,9
555,53
394,64
0
result
1216,54
1217,04
561,26
399,67
1,88
error
1# 82%
1# 59%
1.03%
1.27%
1,88
focal x
focal y
p.p. X
p.p. Y
skewThis is the best results on real datasets. This method requires that all feature are visible from each frame in dataset.
2) PCL
· Implemented simplest version of Point Features Histograms (PFH) and Fast PFH (FPFH) at low level (i.e. they do receive nn-indices, but don’t compute inside). They are not well-tested.
o Implemented simple tests. Debugging the features now. Learning visualization capabilities in PCL at the same time.
o Started looking in normal estimation. Going implement it for my interface.
o Issue: can’t profile my code if OctreeGPU is used for neighbors search before. CUDA Profiler reports an error.
· Thinking of PCL GPU design in common with accounting Channel conception in PCL# 0. Reorganized and refactored GPU code, submitted draft to PCL# 0-draft branch.
o GPU containers moved to separate pcl_gpu_contaners module. Containers interface refactored, simplified and documented (doxigen). It’s possible to compile pcl_gpu_containers with/without CUDA (just error at runtime) => PCL# 0/core can use this module in ChannelFactory, for example, if it is necessary (another design approach: ChannelGPU are constructed only in GPU part).
o Added pcl_gpu_utils (device layer) module and implemented/moved (from Octree) some device function there for future reuse. Plans to extract/implement more functionality there.
o Simplified interface of Octree Gpu.
3) OpenCV GPU
· Resolved ticket #134# Re-implemented result normalization in gpu::matchTemplate to make sure it handles degenerate cases like the CPU version.
· Optimized pyrDown and pyrUp (now it works 17-25x faster than CPU version). Now can use it in opencv_stitching to accelerate high resolution panorama rendering with GPU.
· Refactored BruteForceMatcherGPU (moved some utility functions to device layer).
· Optimized memory usage in BruteForceMatcherGPU::knnMatch when k==#
· Updated docs accordingly.
Gary suggested implementation pyrUp/pyrDown with non-power of 2 last week. Simple blur/resize-based implementation can be done very quickly, but will it give good speed-up?!
Need to think about it. Will put in our plan.Plans:
1) Auto-calibration· Test autocalibration pipeline on other Oxford datasets.
· Try feed new reconstruction pipeline output to M. Chandraker’s method.
· Refactor code, remove obsolete code.
2) PCL
· Normal estimation on GPU.
· Profiling, testing, optimization features. After it, implement high level classes (interface close to CPU).
· Implementation of repack utilities (SOA <→ AOS, pcl::Normal → float3 or float4]) because such repacks are faster on GPU than on CPU. And will be very useful in future.
3) OpenCV GPU
· Update opencv_stitching with new gpu functions (knnMatch, pyrUp, pyrDown). Add support of different types and interpolations modes to gpu::remap (it is also used in stitching).
· Implement separable filters for big kernel size (ticket #1134). Now we support ksize <= 16 only.
Other:
· New user suggestion: Random Trees on GPU by PhD student from BMW group at Munich (in our Feature Request Form).
Action Items
Gary
Radu
Vincent
Alexander
Vadim
- Email Kurt about bundle adjustment approaches
Victor
- Sync up on model capture with Ethan
- Ask Alexander
Kurt
- Send Victor what Hinterstoisser is doing with model capture
- Help Victor sync up on model capture
- Send pointers to Ecto
Ethan
- Sync up with Victor (DWO slam) on model capture
- Send Victor pointers
James
From last time
Gary
- (./) Talk with Nathan about rsync ’ing opencv.itseez.com to opencv.willowgarage.com/documentation
- Get Ethan to file a bug report on openni drivers
- Have Vincent talk sfm with Victor et al
Radu
Vincent
Alexander
Vadim
Victor
- Write Stephan and CC the rest about refactoring the linemod code
Kurt
Ethan
James
Agenda
- Model capture
- Hinterstoisser’s registered 2D codes
- Ethan’s dots and inverted dots
- Victor’s dwoslam
- LineMod
- Is this API OK?
- Transparent items
- Next in object rec
- IPhone port
- How to make LatentSVM
Minutes
- Model capture
- Alexander Shishkov sent Ethan an email about how dwo slam works. Alexander is on vacation this week
- See email ‘’"code for model capturing with dwoslam"’’
- Alexander Shishkov sent Ethan an email about how dwo slam works. Alexander is on vacation this week
- Linemode
- Pose refinement … cohere into a toolbox?
- Solve PnP
- LePetit’s — has code online
- Version with Ransac
- edge refinement … toolbox in ROS for doing this
- Pose refinement … cohere into a toolbox?
- Transparent object
- edge refinement/pose refinement using Nlopt
- Has clutter problems, but if it is in weak clutter, pose is good
- edge refinement/pose refinement using Nlopt
- Iphone port
- Almost done
- needs tutorial on how to write an app with opencv on iPhone
- works with simulator
- Need to register as Apple developers
- Sparse bundle adjustment
- Works well on test datasets sba package.
- Extending to unknown cameras, PTAM like functionality.
- Phase correlation is in trunk with docs, tests, sample code. Thanks to Will Lukas!
Victor
Untextured objects: The format of the linemod storage was improved. All trained templates for all object classes were saved in one xml-file before. Now templates for each class are saved in their own folders. It allows to run the algorithm with a subset of train objects. It also eliminates the problem of very large xml file reading. Evaluation of pose quality was implemented. Currently it does not take into account the symmetry of objects (11 from 12 objects of our base have symmetry), so two poses that differ by a rotation around symmetry axis are considered different. Analyzed linemod interface proposed by Patrick. It looks fine at the first reading except that trained templates for all classes are stored in the same xml-file. Transparent objects: Oriented chamfer matching was adapted for work with contours of the object. It increased ratio of successful pose refinements on ~10% on average. Multiple cameras were used in pose refinement by creating a stereo pair of EOS 40D cameras. Multiple images reduced ambiguity of poses (see an example in attachments). Currently the main problem is ambiguity between correct pose and upside-down pose because objects are nearly cylindrical. OpenCV on iOS: A sample by Xiaochao was reproduced on iPhone simulator. Other: Alexander is on vacation this week. Attachments: linemod: linemodPoses.png -- examples of poses returned by linemod. transparent objects: init.jpg -- initial pose left.jpg -- refinement by the left camera alone right.jpg -- refinement by the right camera alone both.jpg -- refinement by using both cameras
Vadim
# (Contributions) Will Lucas contributed phaseCorrelate() function: http://en.wikipedia.org/wiki/Phase_correlation # (GSoC) While GSoC 2011 is officially finished, Alexander is still working on Python bindings and the samples. He has added wrappers for the feature detection and descriptor matching framework from features2d module. # (Sparse Bundle Adjustment) The simplest case (calibrated camera, compensated distortion) has been debugged on couple of test cases from SBA package. Now the code is being extended to support unknown camera matrix and distortion parameters in order to calibrate camera in parallel with the geometry reconstruction.
Anatoly (GPU)
Accomplishments & statuses:1) Auto calibration
· Tested current camera autocalibration pipeline on other Oxford datasets and wrote short summary.
· Tested projective factorization algorithm with M. Chandraker’s autocalib method — it still provides poor results.
2) Opencv GPU
· Fixed tickets: #1344 (compilation), #1353(minor bug in CudaMem::createMatHeader), #1323 (small image size checks for SURF_GPU)
· Implemented gpu::remap for all types & flags. (we need it for stitching on GPU)
o Added BORDER_REFLECT and BORDER_WRAP extrapolation support GPU module.
o Added Filter Functors (nearest, bilinear) to device layer.
· Found 1st NVCC bug, investigated, created simple repro-case and submitted it (id872731).
3) Opencv stitching
· Turned opencv_stitching application into OpenCV module + sample. Started simplifying stitching interface for end users. Going to speed 3 days for this. [Tegra team request. They’ve got a lot of user requests on their forum].
· Investigated opencv_stitching failure on photos taken from Android. The reason is wave correction step (that just shifts panorama before rendering): If mobile photos are taken with portrait orientation → vertical straightening is required. But the step tries to make horizontal panorama, and as result it returns bad rendering position on sphere. This was repaired by disabling wave correction by default. Probably will implement vertical wave correction step.
· Optimized blending & panorama rendering with to gpu::remap/gpu::pyrDown/gpu::pyrDown in opencv_stitching. Whole stitching pipeline is ~ 3x faster now for 12MPix images.
4) PCL
· Implemented and debugged normal estimation on GPU for non-organized point clouds. Simple optimization iteration. Guess can make faster, want to see its fraction of time in ComputerNormal – ComputerFeatures pipeline before.
· Found 2nd NVCC bug during normal estimation debugging. Simple repro-case creation is very hard. Guess it’s similar to bug in NPP_ Staging::IntegralImages. At least workaround is the same extra _threadfence_block() intrinsic.
· Debugged FPFH in order to reach results similarity with CPU code.
a) Found that in CPU code: FPFH = sum(SPFH * Wi), where Wi sqrt_distance, but according to manual here, it should be distance (not sqr).
It is a bug in PCL?
b) Despite of replacing fast math intrinsic with full precision functions (sqrt, atan2, cos, sin, etc), I can’t reach byte-wise similarity between CPU & GPU. The same point can vote in different neighboring bins on CPU and on GPU (different computational error).· Started debugging PFH.
Plans:
· Refactor stitching module. Add tests and docs. Fix wave correction step in stitching sample. Add support of rotation initial guess into stitching sample (example, from compass on Android device).· Implement separable filters for big kernel size (ticket #1134). Now we support ksize <= 16 only.
· PCL: profiling, testing, optimization features. After it, implement high level classes (interface close to CPU).
· Implementation of repack utilities for PCL because such repacks are faster on GPU than on CPU. And will be very useful in future.
Action Items
Gary
- See where Ethan is on dwo slam from Alexander
- Talk to Marius about scaling linemod using wta coding
- Try to find transparent object recognition paper(s)
- Check with Suzanne about intern house for Victor and Vadim
Radu
Vincent
Alexander
Vadim
Victor
Kurt
Ethan
James
From last time
Gary
Radu
Vincent
Alexander
Vadim
- Email Kurt about bundle adjustment approaches
Victor
- Sync up on model capture with Ethan
- Ask Alexander
Kurt
- Send Victor what Hinterstoisser is doing with model capture
- Help Victor sync up on model capture
- Send pointers to Ecto
Ethan
- Sync up with Victor (DWO slam) on model capture
- Send Victor pointers
James
Agenda
- No real meeting today, Vadim is onsite, Victor just left
- SLAM dwo
- Latent SVM: NNSU Felzenszwalb team about adding docs, samples, tests and TRAINED classifiers
- Look into putting back documentation comments
- make it clear how to get or not get opencv_extra
Minutes
- No official meeting today, just notes. Vadim is onsite and Victor just left.
- Vadim and Gary are working on improvements to the ORB descriptor, basically
- Making FAST even faster and maybe innately more resistant to finding edges TBD. We also may work on repeatability … but not at the cost of making FAST SLOW.
- Using ideas from Google’s (‘’Yagnik, Strelow, Ross, Lin’‘s) Power of Comparative Reasoning paper to boost ORB’s discriminability .
- We may also use separable Gaussian blur instead of integral images which may help with rotation tolerance TBD
- It is obvious, that since we estimate moments at corners anyhow, these could be used to do a full affine instead of just rotation correction. Trades off with speed, but might be worth it.
- Work to scale Linemod is underway, Gary reimplemented to whole algorithm to make it easier to experiment with.
- Unclear as yet whether scaling (by which I mean slower than linear slow down with increasing numbers of object learned) will work with these kinds of sparse features.
- LSH and NN type methods are dubious.
- Will use the kind of pyramid tree that seemed to work with BiGG.
- There will be a push for transparent objects as is “apparent” from these recent meeting notes.
- Gary is going to add some gradient methods late this week/early next to add to the NAN and pose fitting.
- This will be followed by some as yet secret sauce to make transparent object recognition and pose reliable.
- Possibly see RSS which is the target for this effort.
- TOD underwent major improvements thanks to Ethan and Vincent — it is now very stable in pose recognition and much more able to find objects even with the terrible kinect RGB camera. Speeding it up and getting it on the robot for grasping is this week’s goal.
- Trained models for LatentSVM are now in opencv_extras. Documentation is restored. Work is underway to get the cascade version in. Hope to optimize this — it may be good for general objects such as chairs, shelves, etc
Victor
TRANSPARENT OBJECT POSE: Created a new dataset with 5 transparent objects captured by the calibrated Kinect and the EOS 40D stereo pair. Kinect is used as a glass detector: # The approximate object contour is extracted from a Kinect depth map by using its NaN values. # This contour is refined using the Kinect RGB image by applying the GrabCut algorithm. OpenCV snakes and GrabCut were compared on several images for this task (for example see contours.png) -- GrabCut is the winner. # Our pose estimation algorithm is run using the refined contour as test edges and the computed pose is returned as the initial pose which is refined using the stereo data. Sometimes the algorithm returns an upside-down pose instead of the correct one. To avoid such problems we added an additional optimization step that uses the upside-down pose as an initial pose. The pose is estimated correctly in 79% of cases. The table below shows pose errors for each of the objects. This error includes the constant displacement between the training and test object poses, a more precise measurement is on the way. [Ilya] ---------------------------------------------- object std dev of std dev of rotation (rad) translation (m) ---------------------------------------------- bank 0.0744 0.0083 bottle 0.0787 0.0131 bucket 0.0855 0.0104 glass 0.0723 0.0058 wineglass 0.0905 0.0117 ---------------------------------------------- mean 0.0803 0.0099 MODEL CAPTURE: The first implementation of ICP-tracker based on the paper of Kok-Lim Low "Linear least-squares optimization for point-to-plane ICP surface registration" (and partially on the paper of Yang Chen "Object modeling by registration of multiple range images") was finished. Some experiments on comparison the implemented ICP-tracker, dwo-slam and a method based on fiducial markers were made to choose more stable approach. Test system was implemented to evaluate R, t obtained by the ICP-tracker and dwo-slam. Quality was evaluated on the basis of the method using fiducial markers (circles grid) due to its better stability. So far ICP tracker shows worse performance (33% of large errors in pose compared against 6% from dwo-slam). Further experiments with ICP tracker (in particular, parameter tuning) are on the way. [Alexander] LATENT SVM: The documentation for C interfaces of latent SVM was restored from SVN history (it was lost in updating OpenCV documentation). Converted it to rst format (from LaTeX). The trained VOC2007 database models and the conversion script from Felzenszwalb's format to OpenCV's were added to opencv_extra/testdata/cv/latentsvmdetector/. Implemented C++ interface wrapper for latent SVM detector (cv::LatentSvmDetector). Added support of several models (C interface doesn't support this feature). Implemented sample for it in /samples/cpp/latentsvm_multidetect.cpp. Tests and documentation for cv::LatentSvmDetector methods were added. [*Maria*] LINEMOD: Moving our applications (for training and evaluation linemod) to the refactored linemod implementation is in progress. [*Maria*] OPENCV: - A chapter on a cascade classifier training was added to OpenCV user guide [http://docs.opencv.org/trunk/doc/user_guide/ug_traincascade.html]. [*Maria*] - Updated Buildbot to 0.8.5 version. Fixed problems with svn synchronization on MacOS. - Fixed #1030, #1319, #1330, #1372, #1392, #1406 tickets. - Fixed bug with using external ZLIB library (rev. 6829). - Modified Buildbot scripts, now the latest installers for OpenCV are copied to our file-storage nightly. [Alex, Andrey] OTHER: Maria was on a sick leave on Thursday (October 6).
Vadim
# (Feature Detectors) FAST detector has been optimized with ~# 5x speed up (depending on the image and the parameters). The new implementation is also much more compact and easier to extend with more complex tests on the corners (as there is no hard-coded decision tree). # (Feature Descriptors) Extended Hamming distance has been added in the case when the elements of a descriptor may take values other than 0, 1 (so that they take more than 1 bit each). This is to extend ORB descriptor using "WTA (winner-takes-all) hash" technique.
Anatoly Baksheev
1) Video stitching demo· Prepared beta1 and beta2 of the demo. Implemented calibration helper (scripts + utils). Prepared detailed readme.txt.
· Integrated GPU face detector into the RT stitcher demo. Implemented naive seam correction to placing seam through faces.
· Implemented estimation of projection plane distance (at faces). Tried to triangulate face centers using them as pairwise matches. Rays going from cameras through face centers are almost parallel, so distance can’t be estimated accurately enough. Even averaging over all image pairs doesn’t help. Implemented experimental version of gradient descent method for projection plane distance estimation, where cost function is the sum of distances between warped face centers.
· Integrated multi-band blending to the pipeline.
As result we have beta2 and recorded video that demonstrates how algorithm works.
Issues:
· Performance of RT stitcher with smart seams and plane estimation is about 1..2 FPS.· Demo supports only one face.
2) PCL
· Implemented and debugged PPF, PPFRGB, PPFRGBRegion, PrincipalCurvatures. PFHRGB. Tested similarity with CPU results. Features returned are very close. No ideas for optimization. Can commit this to public repository right now.
· Implemented but not well tested VFH. Going to commit after testing.
· Started reading Kinnect Fusion paper, learning ICP, etc.
3) OpenCV GPU module
· Implemented brute force approach for cv::gpu::convolve for small kernel sizes.
· Implemented OpenCV-like API (namedWindow/imshow/pointCloudShow/waitKey) in our GLUT-based GUI library (highgui_gpu, we use it for demos). That speed-ups development and debugging demos we can display intermediate results using OpenGL by one string of code. Now it is separate from OpenCV, but It can be converted to OpenCV module very easily.
· Fixed bug in BROX (appeared after our fixes, reported by Anton).
Plans:
1) Learning Kinnect-based 3D reconstruction from the paper. Seminar at Itseez.2) Investigate convolve performance for Fermi on different datasets. Final comparison of updated functions with Libjacket.
3) Possibly create wrapper for Brox.
4) Discussions about unified command line interface for samples.
Action Items
Gary
Radu
Vincent
Alexander
Vadim
Victor
Kurt
Ethan
James
From last time
Gary
- (./) Figure out what Vadim/Victor should work on while here
Radu
Vincent
Alexander
Vadim
- (./) Edit the download guide to make it clear how to get or not get opencv_extra
- Talk with NNSU Felzenszwalb team about adding docs, samples, tests and TRAINED classifiers
- Look into putting back documentation comments
Victor
Kurt
Ethan
James
Agenda
- Travel dates
- Improving calibration
- Khronos
- Registration code
- Iphone port
- Better website
Minutes
- Travel.
- VE: Tue→SF→AR Until Thrus.→Mon (26). Sept 30→Oct 8
- VP: Oct 4→16
- Vadim on vacation.
- Xilink may fund fpga interns. Could be used for
- Camera-Projector combos
- Point cloud massage from
- Close range depth sensing
- Cameras with basic feature pre-processing such as linemod. Daisy? HoG?
- Cameras with basic pattern or event detection build in. Tracking.
- Camera-Projector combos
- Khronos
- We have another rev of the proposal. Moving forward.
- Need to decide in what form we will join Khronos? As OpenCV.org? Perception.org?
- Better website. We are overdue for an overhaul.
- Dot pattern calibration
- Ethan will send his VTK calibration renderer for helping develop the calibration pattern.
- This will be a great general utility
- Iphone OpenCV port compiles, not independently tested on iPhone yet.
Anatoly (GPU)
Accomplishments & statuses:1) Opencv GPU
· Added performance tests for gpu module. This tests are intended to track performance difference between revisions. If after our fix (refactoring) something become worse we catch it.
· Added bicubic filter to device layer.
· Fixed bug in gpu::remap on win32 (workaround for nvcc bug). Fixed bug in stitching in GpuSurfFeaturesFinder (missing upright parameter).
· Implemented gpu::resize for all types & flags.
2) Opencv stitching
· First iteration of stitching module refactoring (moved all into detail namespace, added simple class Stitcher, added sample).
· Spend some time to discussions of stitching API with Tegra team. Communicated with Peter Karasev. He’s going to contribute stitching sample which can handle rotation initial guess / timestamps.
· Fixed link bug in stitching module under Windows.
3) Video Stitching Demo
· Created demo app which stitches video from fixed cameras. Several iteration of its optimization. As result blending works up-to 80fps on 3 Full HD images.
· Tested on web cameras, found poor quality on web-cameras. Investigating.
4) PCL
· Found and fixed 2 bugs on gpu::Octree & FPFH. Finished debugging PFH.
· Implemented high-level classes for Normal estimation (indices & surface support). Added indices support to OctreeGPU:: radiusSearch.
· I am near to finish high-level classes for PHF & FPFH. Just unplanned and urgent video stitching demo took some time. After going to compare performance: CPU [F]PFH + Kdtree radius search vs.at