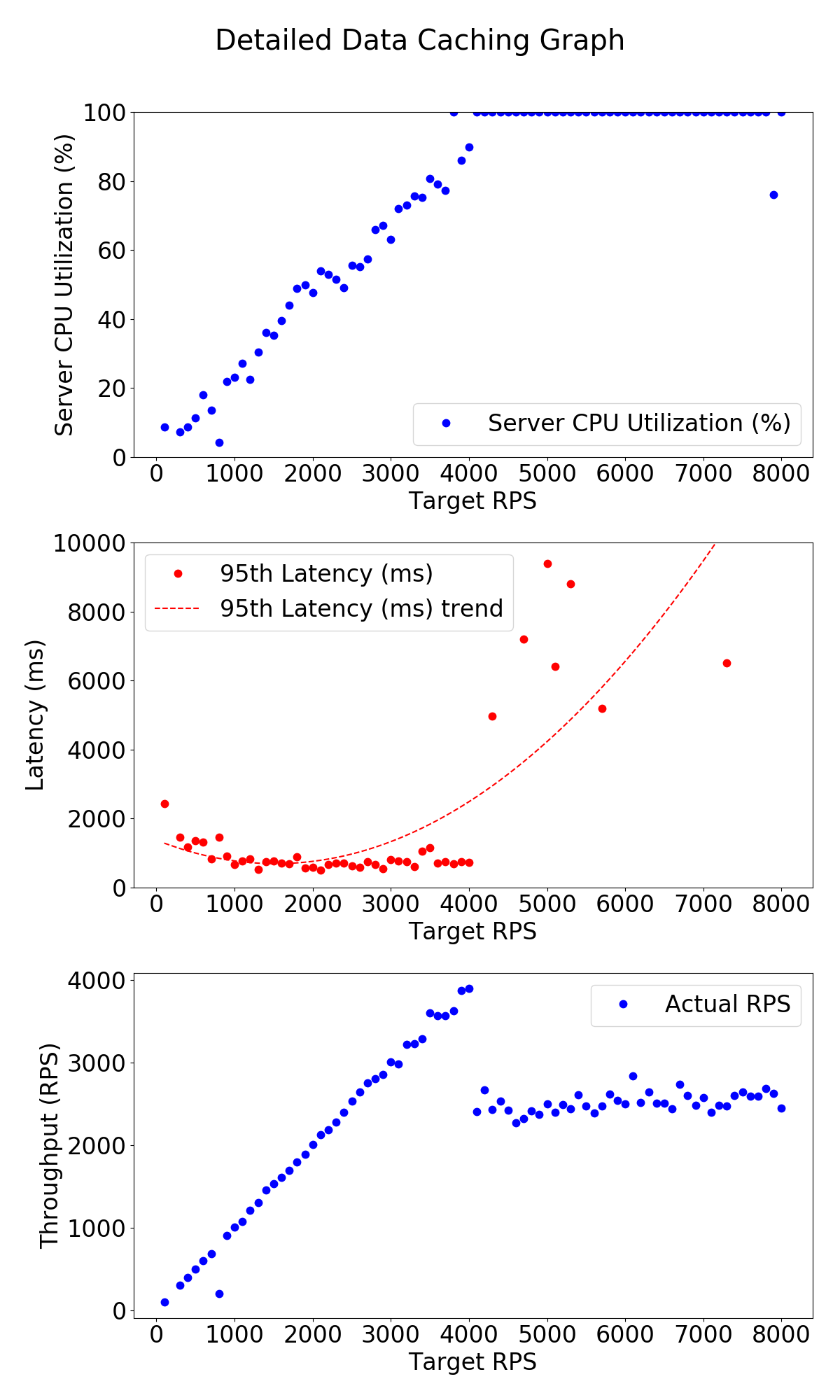
Data Caching
The machine had 4 NUMA nodes and each time we ran the server and client in different NUMA nodes. The server was configured to run at 2.4 GHz.
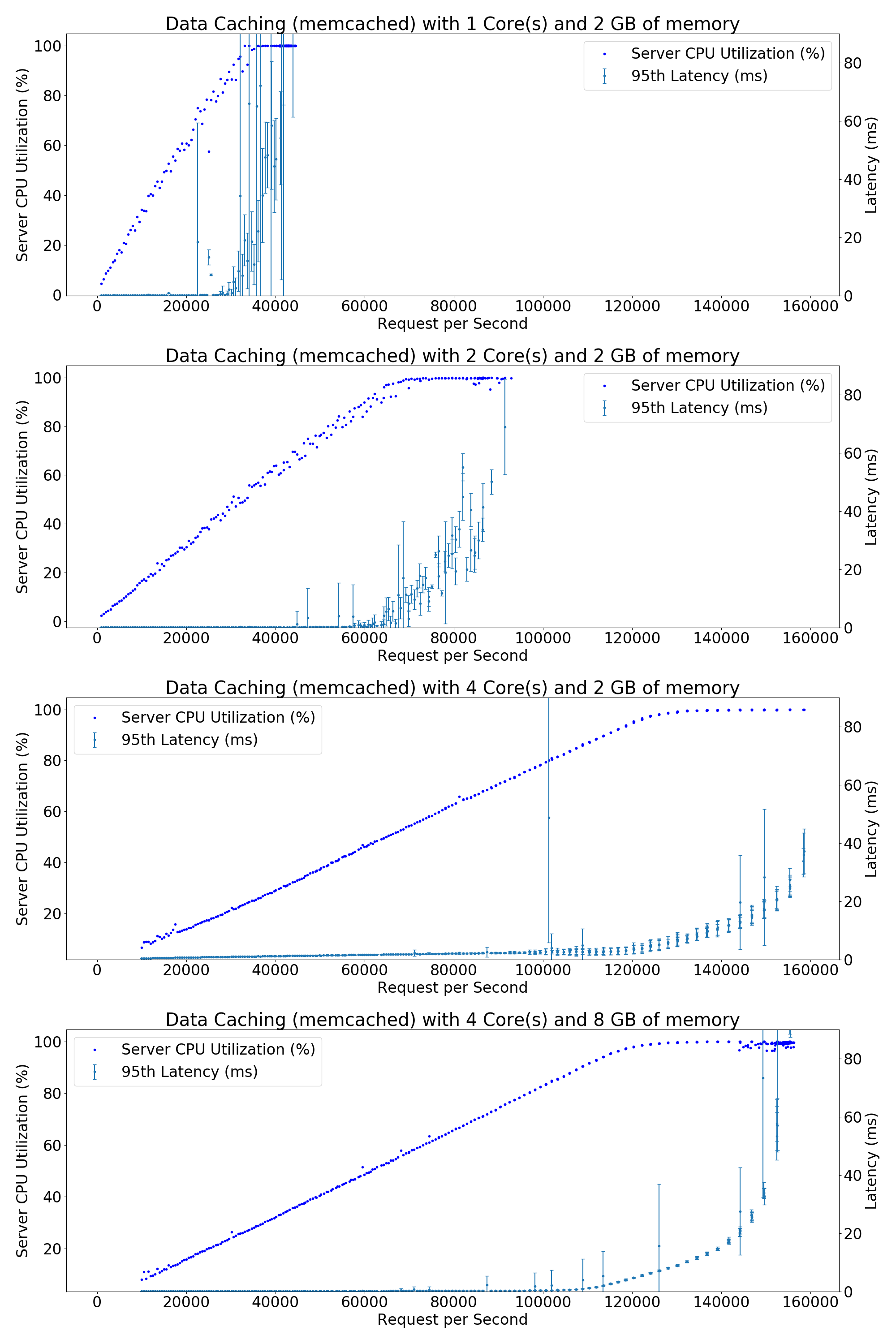
The machine had 2 NUMA nodes and each time we ran the server and client in different NUMA nodes. The server was configured to run at 2.5 GHz with the Intel turbo boost disabled.
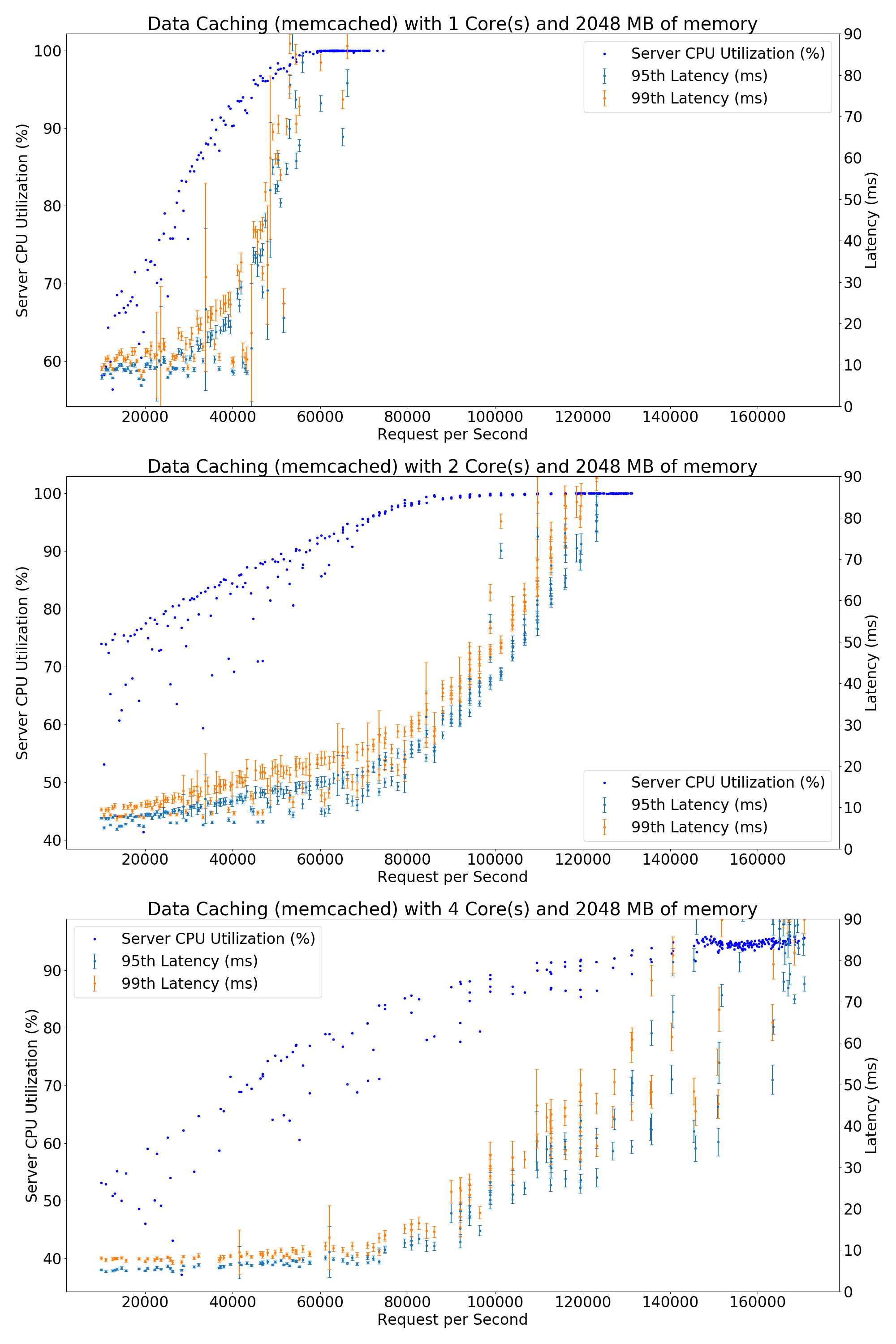
Please note that the errors are normalized regarding the square root of RPS.
Results from running on the x86 machine from PARSA cluster:
 Results from running on the x86 machine from IC cluster (Same with what used for Web Search):
Results from running on the x86 machine from IC cluster (Same with what used for Web Search):
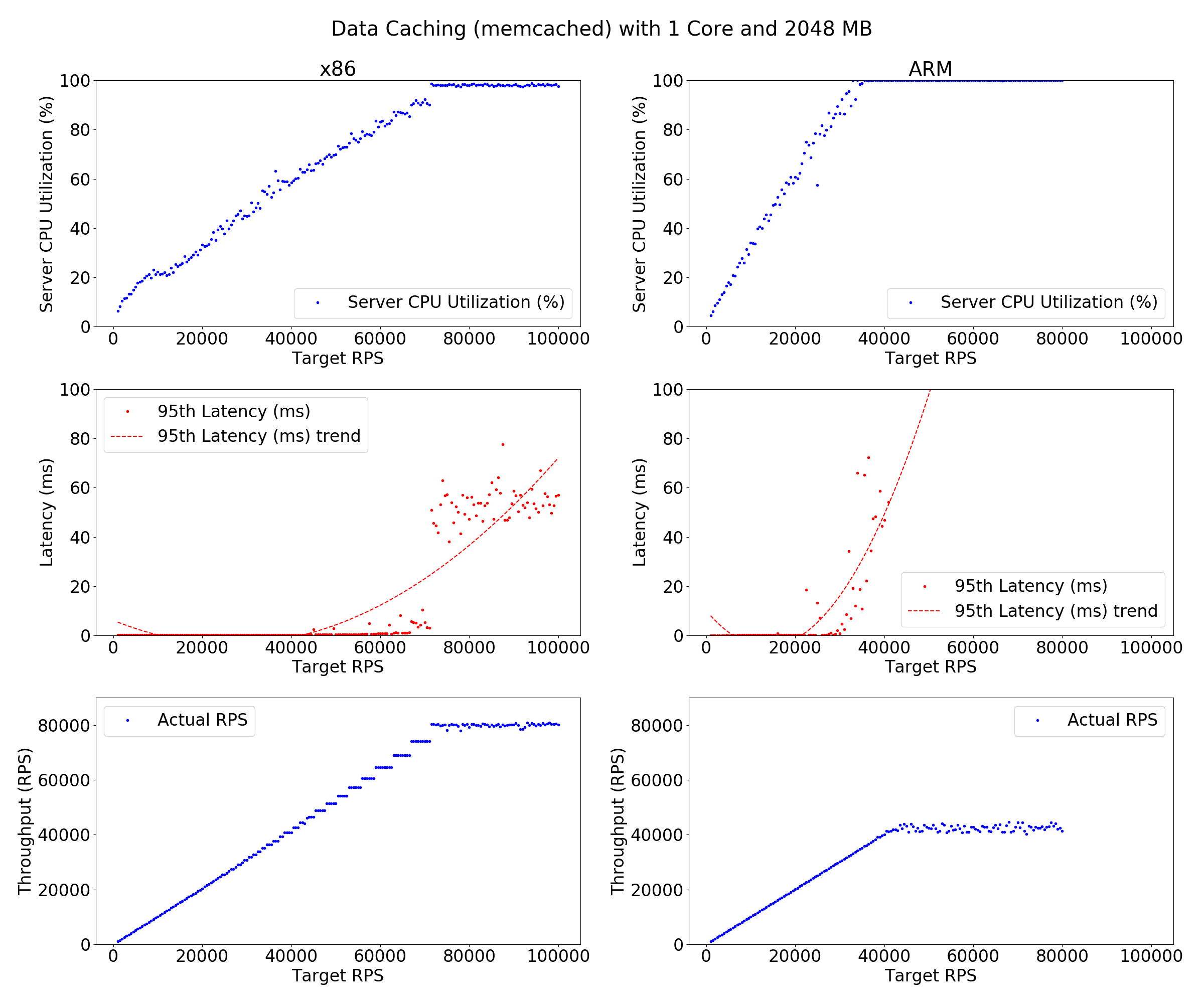
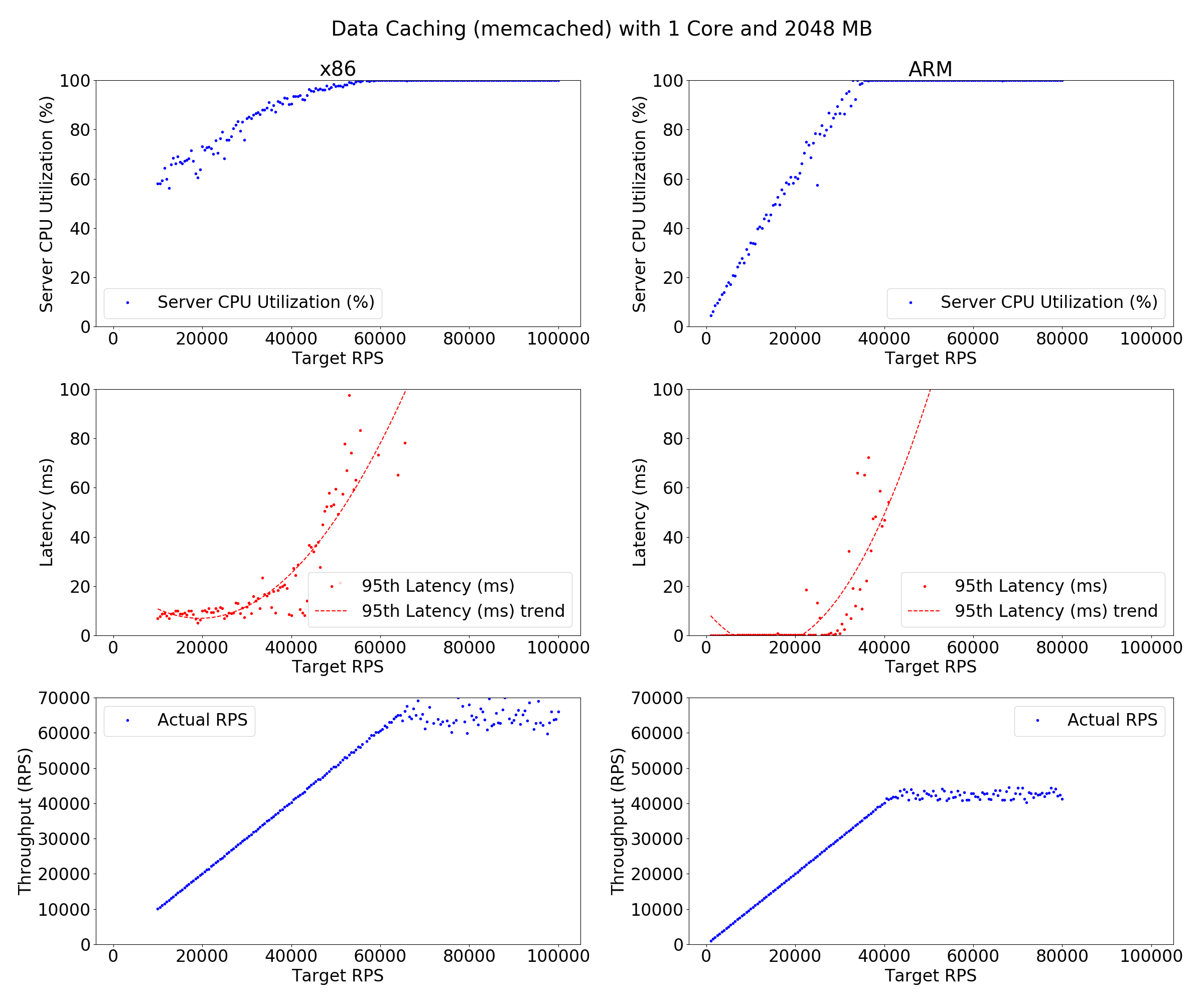
Results from running on Huawei ARM server and IC cluster - 4 cores 2GB:
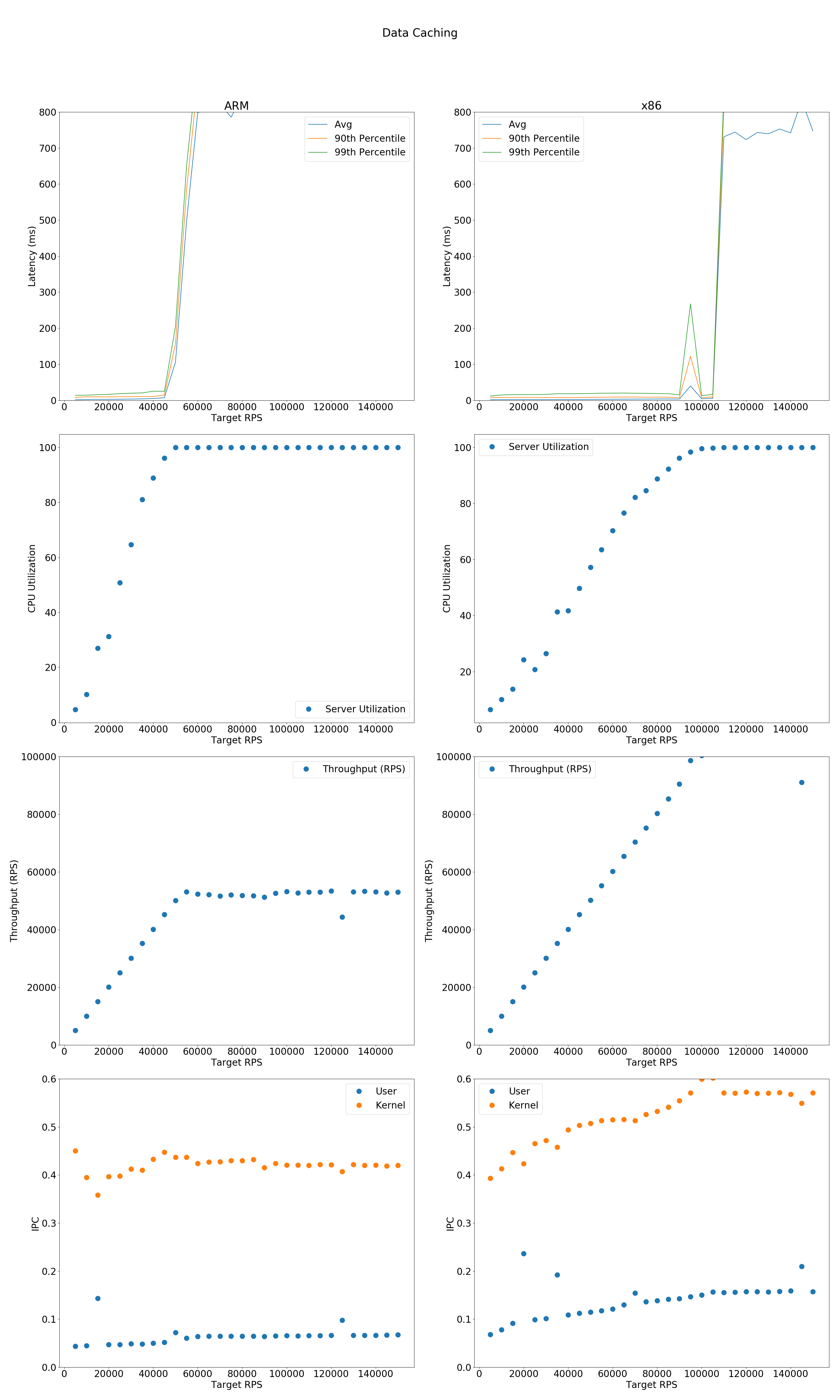 You can download the data for aarch64 or for x86.
You can download the data for aarch64 or for x86.
I plotted for data caching on Qemu using this.
This is not a good graph because I ran it in 2 sessions for the left hand and the right hand but as the CPU utilization is continuous I think it's fine.
I used single threaded Qemu which was using only one host core for the server. I couldn't use the icount option for mrun as I mentioned here.