Visualizing Hyperparameters Optimization
Machine Learning models are composed of two different types of parameters:
- Hyperparameters = are all the parameters which can be arbitrarily set by the user before starting training (eg. number of estimators in Random Forest).
- Model parameters = are instead learned during the model training (eg. weights in Neural Networks, Linear Regression).
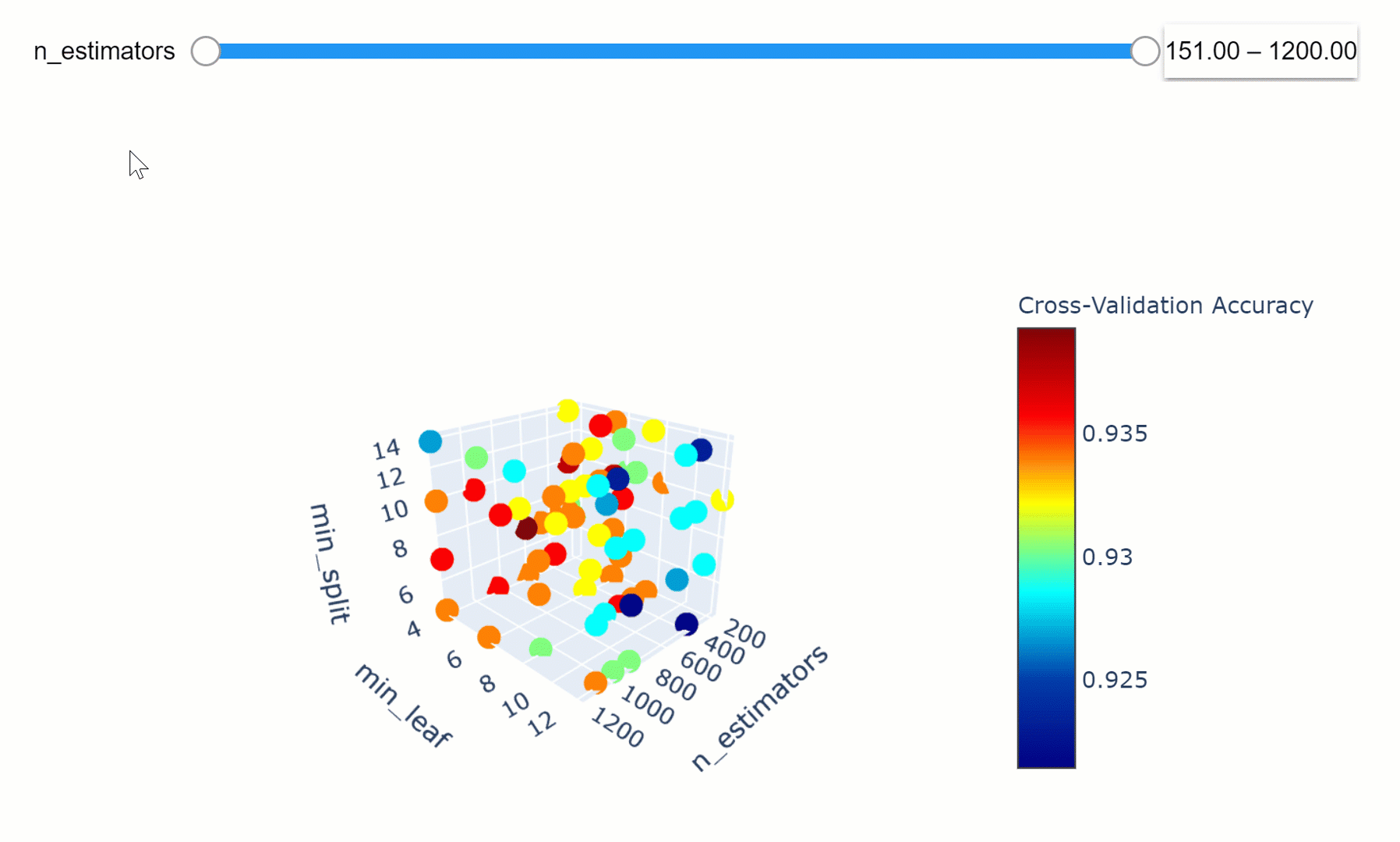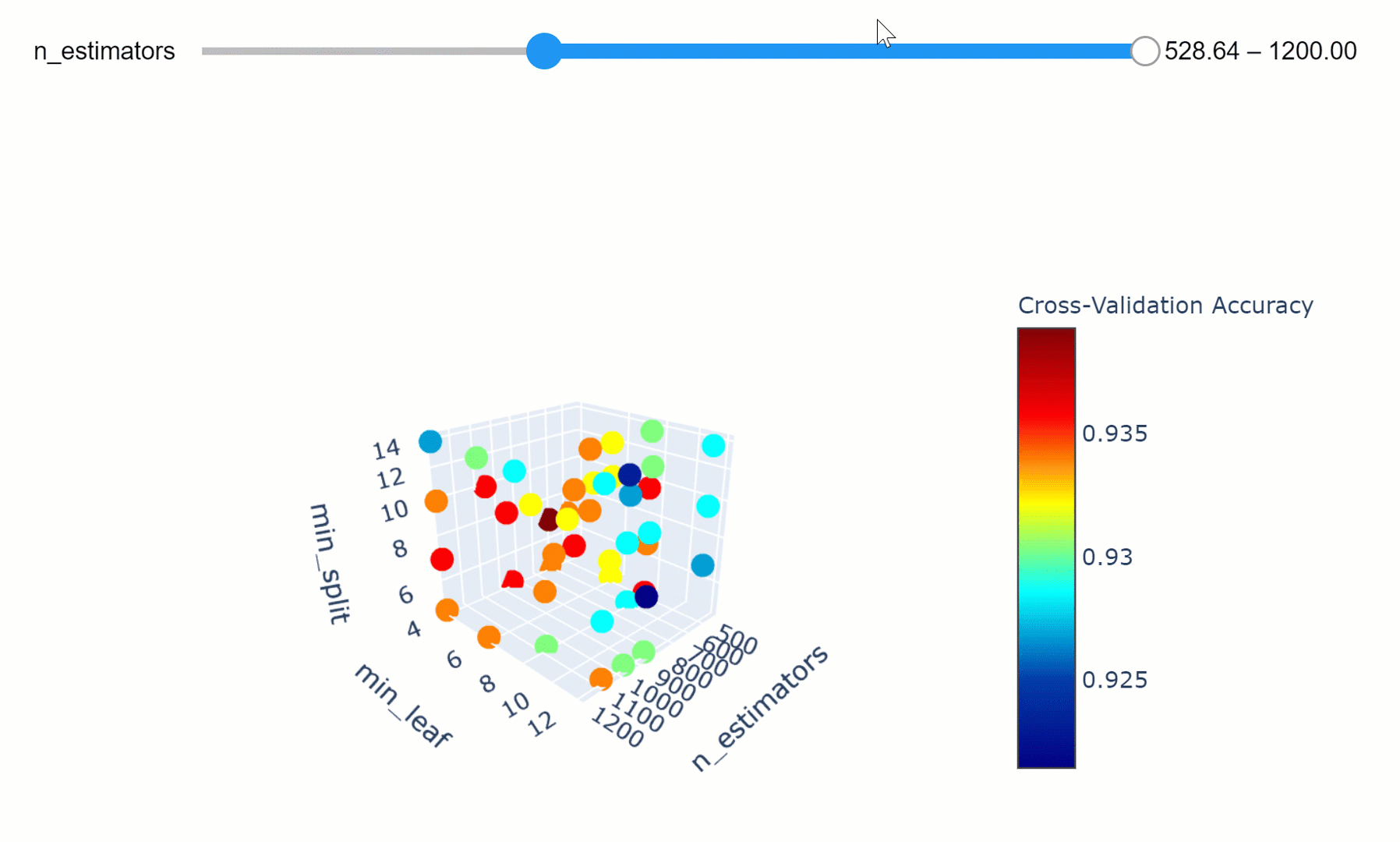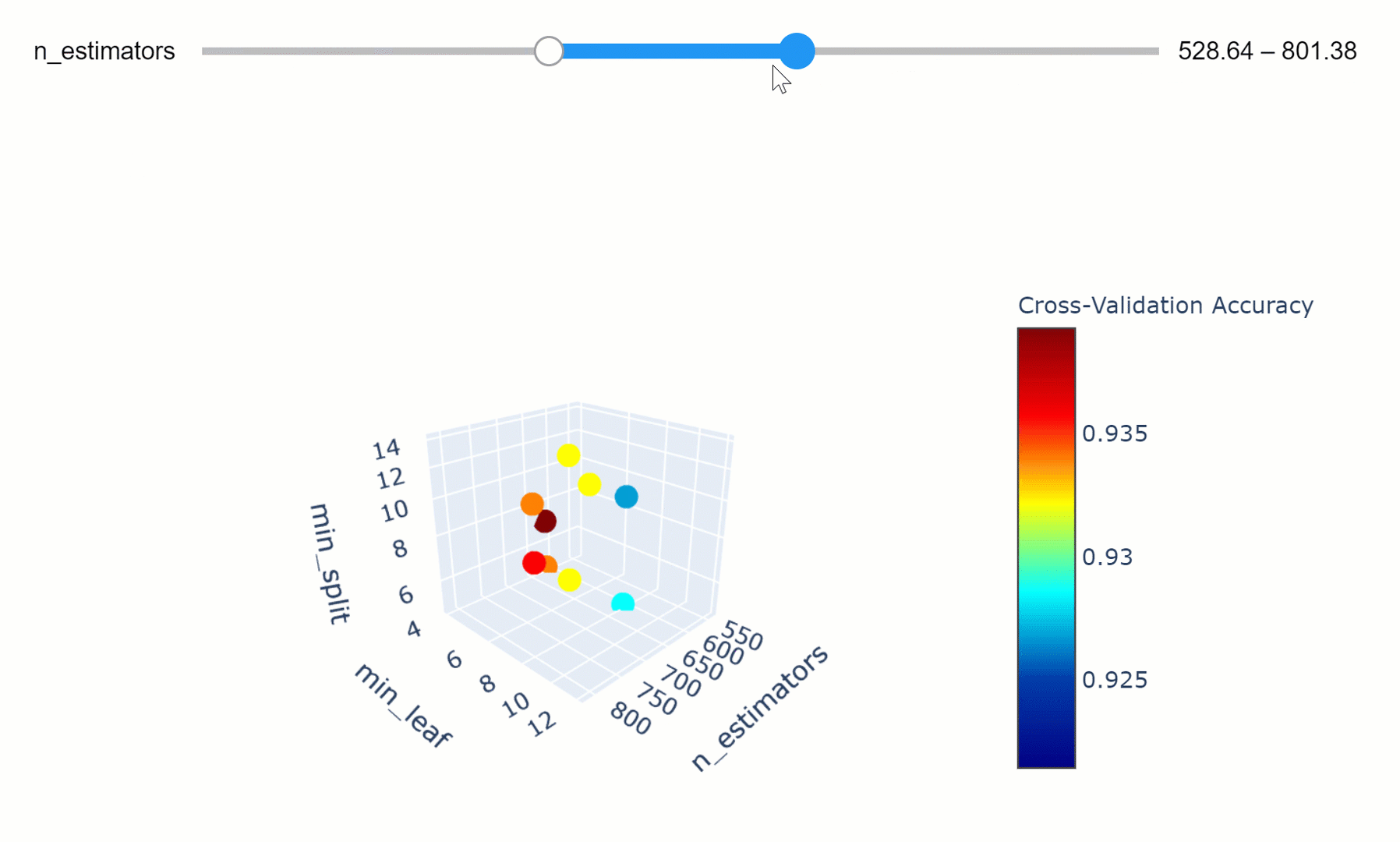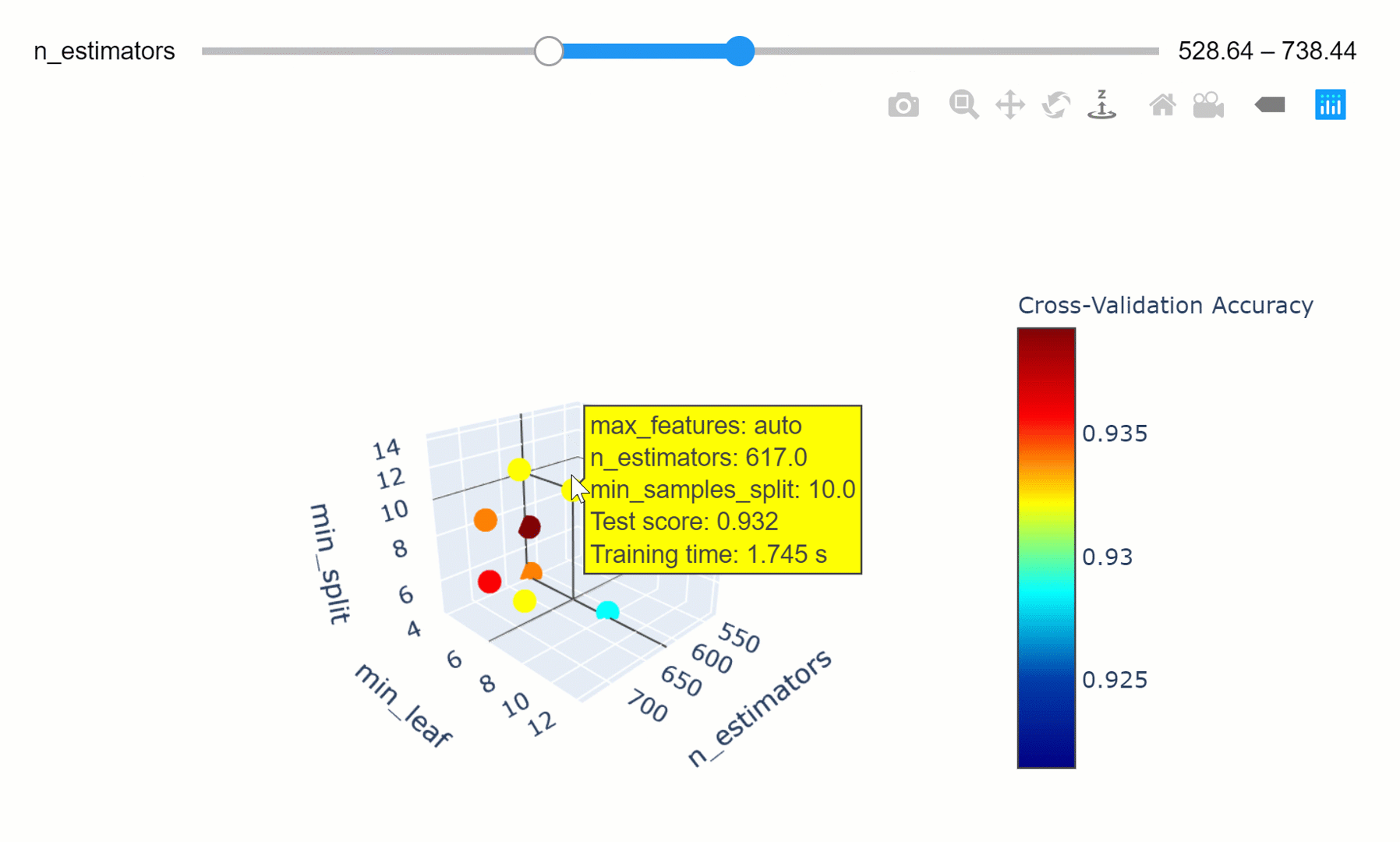
The model parameters define how to use input data to get the desired output and are learned at training time. Instead, Hyperparameters determine how our model is structured in the first place. Machine Learning models tuning is a type of optimization problem. We have a set of hyperparameters and we aim to find the right combination of their values which can help us to find either the minimum (eg. loss) or the maximum (eg. accuracy) of a function. This can be particularly important when comparing how different Machine Learning models performs on a dataset. In fact, it would be unfair for example to compare an SVM model with the best Hyperparameters against a Random Forest model which has not been optimized.
Data Visualization can be used in this ambit in order to understand how changing different hyperparameters in our model can affect its performance and explainability. An in-depth explanation about Hyperparameters search is available in this my Towards Data Science article, while all the code used in this article is available here.