gh-119786: Move parser doc from devguide to InternalDocs #125119
Conversation
|
Are we also removing this from the devguide? I would be sad to lose the rendered version with admonitions and other graphical features. |
|
Also, this guide and the GC guide have helped plenty of contributors learn how the parser works and I am concerned that moving this to an |
|
We're moving all the internals documentation to the cpython repository so that (1) it's versioned (2) it gets updated in the same PR as the code. For now I am replacing the devguide doc by a link to the new place. Eventually the cpython doc will be the single source of truth re internals and people will be directed here from the devguide. |
|
This is the devguide PR for now: python/devguide#1431 At some point the devguide can just point to https://github.com/python/cpython/blob/main/InternalDocs/README.md |
I tried to preserve the rendering style, with admonitions as block quotes, etc. Is there anything in particular you see that is missing? |
No, I think you made a good job translating the document to markdown format, is just that I am a bit worried that this will reduce visibility and readability (raw markdown file vs a rendered webpage). Also, for other docs there were images and reading those in markdown files will a much worse experience. I don't want to push back strongly on this or hold on this so if you want to land go ahead. I think that moving this to the CPython repo makes sense but I am worried that we are going to sacrifice aspects of the current docs that I still think they are important. |
|
For reference, in https://devguide.python.org/internals/garbage-collector/ there are several images that if we move to a markdown file cannot be viewed properly and will have to be opened separately. I feel that these aspects have not been discussed (or at least I haven't seen the discussion anywhere) and I feel that I didn't had the opportunity to voice my opinion before this work started |
|
When you open a markdown file in GitHub it renders it, you're not reading raw markdown. It will look like this: https://github.com/python/cpython/blob/6b9e52b91ff5ce2327e9372d41e69f253cdb309b/InternalDocs/parser.md |
Ah ok, this looks better than what I was thinking. Will images be rendered inline as well? |
|
|
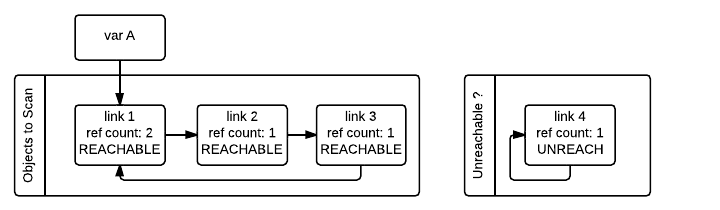
|
Oh, thanks for confirming! My biggest concerns don't apply anymore then. I have reviewed the markdown version with the link and I am happy with it so feel free to land. Thanks a lot for the patience :) |
|
Thanks! I'll hold off merging in case I manage to get someone with better markdown foo to review and perhaps make some formatting improvements. |
|
Sorry for the noise 😬 thought maybe adding suggestions to batch would make it easier if you chose to accept them |
Yes it normally is! We actually crossed wires in this case, I was make these changes in parallel because @pablogsal just sent me a link about this. |
|
re: grammar expressions as a table, this is a quick and dirty copypasta into columns but wdyt? | Expression | Description | Example |
|-----------------|---------------------------------------------------------------------------|------------------------------------------------------------------------|
| `# comment` | Python-style comments | N/A |
| `e1 e2` | Match `e1`, then match `e2` | `rule_name: first_rule second_rule` |
| `e1 \| e2` | Match `e1` or `e2` | `rule_name[return_type]:`<br>` \| first_alt`<br>` \| second_alt` |
| `( e )` | Grouping operator: Match `e` | `rule_name: (e)`<br>`rule_name: (e1 e2)*` |
| `[ e ]` or `e?` | Optionally match `e` | `rule_name: [e]`<br>`rule_name: e (',' e)* [',']` |
| `e*` | Match zero or more occurrences of `e` | `rule_name: (e1 e2)*` |
| `e+` | Match one or more occurrences of `e` | `rule_name: (e1 e2)+` |
| `s.e+` | Match one or more occurrences of `e`, separated by `s` | `rule_name: ','.e+` |
| `&e` | Positive lookahead: Succeed if `e` can be parsed, without consuming input | N/A |
| `!e` | Negative lookahead: Fail if `e` can be parsed, without consuming input | `primary: atom !'.' !'(' !'['` |
| `~` | Commit to the current alternative, even if it fails to parse (cut) | `rule_name: '(' ~ some_rule ')' \| some_alt` |Details
|
|
Maybe wrap the longer descriptions into multiple lines? @pablogsal do you like this? |
There was a problem hiding this comment.
I recommend using H3 level as suggested here since it will allow more granular open/collapse in editors and is easier to read when rendered.
I typically would only have 1 H1 level (the title) and H2 for subsections. Since we are using H1 for subsections here moving them to H2 level would mean all the headings would need to be one lower. I'm not sure that's worth the effort so I left as is.
Co-authored-by: Carol Willing <[email protected]>
|
I like @JacobCoffee's table too but I would make it 2 columns (instead of 3) if you go the table route so that the example visually follows the description. |
InternalDocs/parser.md
Outdated
|
|
||
| ``` | ||
| primary: atom !'.' !'(' !'[' | ||
| ``` | ||
|
|
||
| ### ``~`` | ||
|
|
||
| Commit to the current alternative, even if it fails to parse (this is called | ||
| the "cut"). | ||
| Commit to the current alternative, even if it fails to parse (this is called |
There was a problem hiding this comment.
Nice @iritkatriel. It may make sense to have a brief description on line 273 so the ~ stands out a bit more.
There was a problem hiding this comment.
Turns out these indents are not rendering in markdown as I hoped they would. Maybe table is better.
There was a problem hiding this comment.
https://gist.github.com/JacobCoffee/5e577dc91115cd401afebd54d0eb1a0b is sort've how 2 columns would look. I don't like that you lose the large chunks of descriptions like we had in ~ (In this example,...), but also didn't like the blob of text in the cell for description being so large. 😬
There was a problem hiding this comment.
That's certainly better than what we currently have. I'd remove the " Example:" in each of the boxes.
Yeah, I think it reads nicely |
Co-authored-by: Ezio Melotti <[email protected]>
Co-authored-by: Jacob Coffee <[email protected]>
|
Thank you everyone! |
|
Thanks @iritkatriel for making this happen. I do like the 2 column table. Thanks @JacobCoffee. |
Co-Authored-By: Adam Turner [email protected]
Co-Authored-By: Carl Friedrich Bolz-Tereick [email protected]
Co-Authored-By: Carol Willing [email protected]
Co-Authored-By: Erlend E. Aasland [email protected]
Co-Authored-By: Ezio Melotti [email protected]
Co-Authored-By: Hugo van Kemenade [email protected]
Co-Authored-By: Itamar Ostricher [email protected]
Co-Authored-By: Julien Palard [email protected]
Co-Authored-By: Mana [email protected]
Co-Authored-By: Muhammad Mahad [email protected]
Co-Authored-By: Ned Batchelder [email protected]
Co-Authored-By: Pablo Galindo Salgado [email protected]
Co-Authored-By: slateny [email protected]
Co-Authored-By: wookie184 [email protected]