本质是通过将简要知识串联起来,形成自己的一个技能树、融会贯通。
[TOC]
项目架构 业务技术 架构 项目管理项目实践 缓存设计 消息队列的情景与设计提前准备面试相关回答针对同一个问题,从更深层次的角度去看 面试:全局把控 思维方式,格局,处理事情的态度方法
基础能力设计模式架构能力为什么这样设计,这样设计的好处结合业务思考
JUC、Spring、MySQL、Kafka
学习计划进度表
| 科目 | 进度 | 重点深入 | 备注 |
|---|---|---|---|
| MySQL | ✅✅✅ | ⭐️⭐️⭐️ | |
| Redis | ✅✅✅ | ||
| Kafka | ✅ | ⭐️⭐️⭐️ | |
| 分布式系统 | ✅ | ⭐️⭐️⭐️⭐️⭐️ | |
| 操作系统 | ✅ | ||
| 网络 | ✅ | ||
| JUC | ✅✅✅ | ⭐️⭐️⭐️⭐️⭐️ | |
| Spring | ✅✅✅ | ⭐️⭐️⭐️⭐️⭐️ | |
| JVM | ✅✅✅ | ||
| Netty | ✅ | ||
| 云原生 | ⭐️ | ||
| 软件设计 | ✅ | ⭐️⭐️⭐️⭐️⭐️ | |
| 源码解析 | ✅ | ||
| Dubbo | ❎ | ⭐️⭐️⭐️⭐️⭐️ | |
| RocketMQ、AutoMQ | ❎ | ⭐️⭐️⭐️⭐️⭐️ | |
| XXL-job | ❎ | ||
| 性能优化 | ⭐️ | ||
| 算法 | ❎ | ||
| Go、面试相关 | |||
| nginx、es | |||
| Python | |||
| 大数据 |
25年
-
源码系列
- MyBatis (1-2) ⭐️
- JUC(3-4-5)⭐️
- RocketMQ / AutoMQ ⭐️
- Dubbo ⭐️
-
新知识
-
K8s
-
XXL-job
-
ES
-
-
空闲
- nacos、feign 源码
-
书籍
- 写好代码的书籍
- 代码大全、代码整洁之道、架构整洁之道、重构、编写可读代码的艺术、程序员职业素养、代码的未来、领域驱动设计
-
专栏
- 左耳听风、郭东白的架构课、周志明的架构课、李智慧 高并发架构实战课
- 性能优化-专栏
-
设计方案学习-落地的
- Java 错误100例
进程管理
-
进程&线程&协程
进程是资源分配的基本单位,而线程是程序执行的基本单位(内存占用和线程切换(内核态)。
协程的出现是为了降低线程创建的时间和空间成本,以及回归到同步IO的编程模式。
协程是在用户态下进行切换以及较少的内存占用
-
进程状态
- 创建、准备、运行、结束、阻塞
- 僵尸进程和不可中断进程
- 表示进程正在跟硬件交互,为了保护进程数据和硬件的一致性,系统不允许其他进程或中断打断这个进程。进程长时间处于不可中断状态,通常表示系统有 I/O 性能问题。
- 僵尸进程表示进程已经退出,但它的父进程还没有回收子进程占用的资源。短暂的僵尸状态我们通常不必理会,但进程长时间处于僵尸状态,就应该注意了,可能有应用程序没有正常处理子进程的退出。
-
进程调度算法
- 抢占式&非抢占式
- Round-Robin算法
- 普通进程调度
- 先来先服务
- 短作业优先
- 最短剩余时间优先
-
线程通信方式
- 管道、信号、消息队列、socket
-
PCB

内存管理
-
内存管理方式
-
MMU 内存管理单元,存储在CPU中
- TLB:MMU中高速缓存
-
虚拟内存
虚拟内存是为了保护每个进程所使用的内存空间数据安全。
-
内存泄漏
-
对于进程来说,其实是内核提供的虚拟内存,虚拟内存需要通过页表,由系统映射为物理内存。虚拟内存->页表->物理内存。 进程通过malloc() 申请虚拟内存后,一般不会立即分配物理内存,在首次访问的时候,才通过缺页异常陷入内核中分配内存。
为了提升性能,引入了cache和buffer,cache是为了提升文件读写性能,而buffer是为了提升磁盘的读写性能。 所以整体就是 内存的分配和回收过程。
-
-
分段机制
-
分页机制
-
Swap机制
- 换出 内存不够时,将内存中的数据写入到磁盘
- 换入 内存充足是,将磁盘的数据写入到内存中
-
段页机制
-
多级页表和大页
为了解决页表过多引入多级
-
-
局部性原理
局部性原理分为时间局部性和空间局部性,本质是为了硬件成本与文件读写速度之间的平衡,将高频热点数据存储在高速缓存中。以此提升整体的性能。但是本身也引入了缓存,需要注意缓存命中率与淘汰策略。
-
用户态与内核态、系统调用(中断)
- 上下文切换
- 进程上下文切换(成本高)
- 线程上下文切换(私有数据修改)
- 中断上下文切换
- 中断调用
- 硬中断,快速处理中断
- 软中断,异步处理上半部分没有完成的工作
- 上下文切换
-
实模式与保护模式
实模式:直接操作物理地址,但是不安全、内存不够
保护模式:缺页中断,通过引入虚拟内存及其缺页机制,CPU 很好地解决了操作系统和软件的配合关系。
-
页面置换算法
- 随机页面置换算法
- 最优页面置换算法
- FIFO 算法
- LRU 算法
文件系统

-
索引节点(数据的元信息)、目录项(文件系统树结构)
-
VFS 为了支持各种不同的文件系统,Linux 内核在用户进程和文件系统的中间,又引入了一个抽象层,也就是虚拟文件系统 VFS(Virtual File System)。
-
缓存
- 索引节点缓存、目录项缓存、页缓存、标准库缓存
-
磁盘
- 超级块、索引节点区、数据块区
-
文件系统,通用设块层、设备
-
硬连接、软链接
-
磁盘调度算法
-
文件系统有自己的索引、文件缓存、文件数据结构、文件描述符
网络通信
- 套接字 socket
输入输出系统
死锁
- 产生条件
- 资源互斥 一个资源只能被一个线程使用
- 请求与保持条件 一个线程因阻塞时对以获取的资源不释放
- 不剥夺条件 线程获取的资源 在未使用之前,不能强行剥夺
- 循环等待条件 若干线程之间形成一种头尾相接的循环等待资源关系
- 解决方案、模拟死锁
- 粗粒度的锁
- 锁排序法 按照获取锁的顺序 来依次获取锁
- 设置超时时间
性能优化
-
零拷贝 / pageCache / 异步IO、直接IO
零拷贝是通过减少用户态到内核态数据的拷贝次数,以及提升数据的复制速度,文件从磁盘到内核缓冲区到网络socket缓冲区。
一个正常服务端读文件的案例
-
用户态(read)-> 切换内核态(PageCahce)-> 拷贝第一次到pageCache->内核态切换到用户态->拷贝数据到用户缓冲区中- 两次数据拷贝+一次上下文切换
-
用户态->内核态将数据拷贝到socket缓冲区 再将socket缓冲区拷贝到网卡中 一次上下文切换+两次数据拷贝 -
零拷贝-> 一次上下文切换+2次数据拷贝
-
应用场景
- Kafka高性能IO读写、Netty高性能特点
-
-
而pageCache是操作系统为了提升文件到读写,会先从pageCache中查询数据,如果有直接返回,没有再从磁盘读取数据,而写的过程也是一样的,写入pageCache,然后在同步回磁盘,以及提升读写性能。
- PageCache在大文件情况下,会降低提升访问最近数据文件的读写性能
-
异步IO、直接IO是为了解决大文件在零拷贝下的瓶颈,而推荐使用零拷贝。
COW (Cop On Write)
- IO多路复用

网络基础
- 网络分层结构
- 常见网络协议
物理层
链路层
-
拓扑结构
- 解决环路问题:武林比武 STP
- 掌门遇到掌门、同门相遇、掌门与其他帮派小弟相遇、不同门小弟相遇
-
MAC
- IP是地址,有定位功能;MAC是身份证,无定位功能;
- CIDR 判断是不是本地人
-
交换机与VlAN
- 交换机有自我学习MAC地址的能力,学习结果是转发表
- VLAN:交换机数目多会面临隔离问题,可以通过 VLAN 形成虚拟局域网,从而解决广播问题和安全问题。
-
ICMP与PING
- ICMP全称Internet Control Message Protocol,就是互联网控制报文协议
- 查询报文类型/差错报文类型
-
网关
- 静态路由
- 转发网关 IP不变 MAC改变
- NAT网关 IP和MAC都需要改变
-
路由协议
-
配置路由
-
静态路由
-
动态路由
- 距离矢量路由算法 全局存储
- 链路状态路由算法 求最短路径
-
动态路由协议
- 基于链路状态路由算法的 OSPF
- 基于距离矢量路由算法的 BGP
-
-
ARP
- 已知 IP 地址,求 MAC 地址的协议。
- 1.查看本地ARP表 2.广播ARP请求 3.ARP应答 4.缓存IP-MAC映射
-
CRC 循环冗余检测
- 通过 XOR 异或的算法,来计算整个包是否在发送的过程中出现了错误
传输层
-
TCP
-
丢包、乱序、重传、拥塞
-
顺序问题、丢包问题、流量控制都是通过滑动窗口来解决的。
-
拥塞控制是通过拥塞窗口来解决的。(慢启动+拥塞避免 /快重传+快恢复)
- 拥塞窗口:这是发送端根据自己估计的网络拥塞程度而设置的窗口值,是来自发送端的流量控制。
- 防止过多的数据注入网络中,使得网络中的路由器或链路不至过载
- 慢启动
- 由小到大逐渐增加发送数据量 发送端的拥塞窗口数值,每收到一个报文确认,就加一。指数级增加
- 窗口 cwnd 的增长引起网络拥塞,还需要慢开始门限 ssthresh。
- 当 cwnd<ssthresh,使用慢开始算法; 当 cwnd>ssthresh,,使用拥塞避免算法;cwnd=ssthresh,既可用慢开始算法也可用拥塞避免算法。
- 无论是慢开始还是拥塞避免,只要发送端发现网络阻塞,就将慢开始门限设为出现拥塞时的发送窗口值的一半,然后拥塞窗口为一,并执行慢开始算法。这样做的目的是迅速减少主机发送到网络中的分组数,使得发生拥塞的路由器有足够时间把队列中积压的分组处理完毕
- 拥塞避免
- 当网络中的资源供应不足,网络的性能就要明显变坏,整个网络的吞吐量随之负荷的增大而下降,也就是说对资源的需求超过了可用的资源,因为传输数据是需要资源的。
- 快重传
- 快重传算法规定:发送端只要一连收到三个重复 ack,即可断定有分组丢失,就应该立即重传丢失的报文,而不需要等待为该报文设置的重传计时器超时。
- 与慢开始不同,拥塞窗口不设为 1,,而设为慢开始门限+3*mss(mss:最大报文段)。
-
流量控制和拥塞控制的理解吗?
- 流量控制考虑点对点的通信量的控制,也就是客户端和服务端直接数据传输数据量的大小。
- 拥塞控制考虑的问题是整个网络,是全局性的考虑。
-
-
三次握手
-
四次挥手
- MSL
-
TCP状态机
-
-
UDP
-
格式
- 源端口号+目标端口号、UDP长度、UDP校验和
-
区别:TCP是面向连接的,UDP是无连接的
-
TCP提供可靠交付,IP层其实没有保证数据的可靠性,TCP传输层保证来传输的数据,无差错、不丢失、不重复,并且按序到达。而UDP不保证可靠传输。并且不按顺序到达
-
TCP是面向字节流,发送的是一个一个的流,UDP是一个一个的数据报。
-
TCP具备拥塞控制,也就是会根据丢包以及网络稳定情况进行调整自己发送数据的快慢。UDP其实不管三七二十一,只管发送
-
TCP是一个有状态服务。会明确记录包又没有到达,UDP是无状态的服务。
-
使用场景
- 网络情况比较稳定的情况 或者对于丢包场景不敏感的应用
- 流媒体的协议、实时游戏、IOT物联网等
-
-
套接字Socket
- 基于TCP、基于UDP
- 套接字、多进程、线程、IO多路复用等
应用层
-
HTTP
- 请求行
- HTTP2
-
HTTPS
- 对称加密和非对称加密
- https 其实是由两部分组成:http+ssl/tls,也就是在 http 上又加了一层处理加密信息的模块,服务端和客户端的信息传输都会通过 tls 加密,传输的数据都是加密后的数据。加解密过程: 1)客户端发起 https 请求(就是用户在浏览器里输入一个 https 网址,然后连接到 server的 443 端口) 2)服务端的配置(采用 https 协议的服务器必须要有一塔数字证书,可以自己制作,也可以向组织申请,这套证书就是一对公钥和私钥)。 3)传输证书(这个证书就是公钥,只是包含了很多信息) 4)客户端解析证书(由客户端 tls 完成,首先验证公钥是否有效,若发现异常,则弹出一个警示框,提示证书存在问题,若无问题,则生成一个随机值,然后用证书对随机值进行加密) 5)传输加密信息(这里传输的是加密后的随机值,目的是让服务端得到这个随机值,以后客户端和服务端的通信就可以通过这个随机值来进行加密了) 6)服务端解密信息(服务端用私钥解密后得到了客户端传来的随机值,then 把内容通过该值进行对称加密。所谓对称加密就是,将信息和私钥通过某种算法混在一起,这样除非知道私钥,不然无法获取内容,而正好客户端和服务端都知道这个私钥,所以只要加密算法够彪悍,私钥够复杂,数据就够安全) 7)传输加密的信息 8)客户端解密信息,用随机数来解。
-
流媒体
-
P2P
-
DHCP
- Dynamic Host Configuration Protocol,动态主机配置协议)是一个局域网的网络协议,UDP协议,67号端口
- 作用就是动态分配IP地址
- 工作方式:发现->提供->请求->确认。
数据中心
-
DNS
-
域名解析
-
DNS 是一个分布式数据库系统,存储了域名和 IP 地址的映射关系。
主机向本地域名服务器的查询采用递归查询:如果本地域名服务器不知道被查询域名的 IP 地址,就会以 DNS 客户的身份向其他根域名服务器继续发出查询请求。
本地域名服务器向根域名服务器查询采用迭代查询:根域名服务器会告知顶级域名服务器的地址,顶级域名服务器给出 IP 地址,或者告知下一步应该向哪个权限域名服务器进行查询。
- 客户机->Host文件->本地DNS服务区->根DNS服务器->TLD DNS服务器->权威服务器
- 改善时延性能并减少在因特网上到处传输的DNS报文数量。
-
-
负载均衡
-
-
HTTPDNS
- HTTP+DNS
-
CDN
- 网络加速
- 边缘节点->区域节点->边缘节点
-
数据中心
-
VPN
-
移动网络
云计算网络
- PXE
- 预启动执行环境(Pre-boot Execution Environment
容器网络
ACID、三范式
逻辑架构
- 客户端-》连接池->缓存-解析器、优化器、存储引擎
索引
-
结构:avl b b+树
-
场景、失效、sql索引
-
数据结构
- B+树、Hash、Full-text索引
-
物理存储
- 聚簇索引和二级索引
- 回表操作->覆盖索引避免
-
字段特性
- 主键索引
- 唯一索引
- 普通索引
- 更新和查询,唯一索引没办法使用 change buffer带来的随机读性能
- 前缀索引
-
字段个数
- 单列索引和联合索引
锁
-
全局锁
flush tables with read lock;unlock tables;- 全库逻辑备份
-
表锁
-
表锁
lock tables xx read/write
-
元数据锁
- 对一张表进行CRUD操作时,加的是MDL读锁
- 对一张表结构变更时,加的是MDL写锁
- 目的:保证当前用户对表执行CRUD时,防止其他线程对这个表结构进行变更
-
意向锁
-
当执行插入、更新、删除操作,先对表加上意向独占锁,然后对该记录加独占锁。
-
普通select 不会加行级锁
-
//先在表上加上意向共享锁,然后对读取的记录加共享锁 select ... lock in share mode; //先表上加上意向独占锁,然后对读取的记录加独占锁 select ... for update;
-
快速判断表里是否有记录被加锁。
- 先看有意向锁没,没有在加独占锁
-
-
AUTO_INC锁
-
-
行锁
-
锁定范围
-
InnoDB行锁是通过给索引上的索引项加锁来实现的,只有通过索引条件检索的数据, InnoDB才使用行级锁,否则,InnoDB将使用表锁。
-
记录锁:锁定索引中一条记录
-
间隙锁:锁住一个区间,比如(10,15)
- 可以防止幻读、保证索引间隙不会插入数据
- 间隙锁不会互斥、目的都是防治插入幻读
-
临键锁:记录锁+间隙锁
-
插入意向锁:做insert操作时添加的对记录id的锁。判断当前记录是否添加了间隙锁
-
//对读取的记录加共享锁 select ... lock in share mode; //对读取的记录加独占锁 select ... for update;
-
-
功能
- 读锁
- 写锁
-
对于UPDATE、DELETE和INSERT语句,InnoDB会自动给涉及数据集加写锁
- update
- update where 条件没有索引会 所有记录加上 next-key 锁(记录锁 + 间隙锁),相当于把整个表锁住了
- update
-
对于普通SELECT语句,InnoDB不会加任何锁
-
事物和隔离级别
-
ACID
-
隔离级别
-
脏读 不可重复读 幻读 1. 读未提交 P P P 2. 读已提交 S P P 3.重复读 S S P 4.序列化 S S S
-
-
为了解决可重复读下的幻读问题
- MVCC+间隙锁
- 快照读:MVCC方式解决幻读
- 当前读:next-key lock(记录锁+间隙锁)
- MySQL 可重复读隔离级别并没有彻底解决幻读,只是很大程度上避免了幻读现象的发生。
- 已提交事务++未提交事务+为开始事务
- 快照读+当前读
- trx_id + roll_pointer read_view
- 版本未提交,不可见;
- 版本已提交,但是是在视图创建后提交的,不可见;
- 版本已提交,而且是在视图创建前提交的,可见。
- MVCC+间隙锁
存储引擎
- innodb myisam
- 内存结构
- buffer pool
- change buffer
- 自适应哈希
- log buffer
- 磁盘结构
- 系统表空间->段->区->页(16k)-行数据
- Redo log
- 写入时机 定时、提交写、提交写os cache
- 脏页-> check point解决
- check point 方式
- double write 解决check point写失效问题
- buffer pool
日志
-
InnoDB
-
redolog
- 事务提交成功,buffer pool数据没有写入磁盘,宕机了,可以用来恢复buffer pool数据
- 作用:重做日志,保证数据库持久性
-
undolog
- 事务进行回滚的时候进行操作,恢复buffer pool中的数据
- 作用:回滚日志,用于维护数据库原子性、实现MVCC
-
-
binlog
- 用来恢复数据库磁盘里的数据
- 作用:主从复制、数据恢复等。
- 用来恢复数据库磁盘里的数据
-
一条更新语句,先写 undo、后写redo 和 bin log
SQL优化
-
业务方、表结构设计、sql本身(explain)、索引(男女字段 区分度) 黄金索引三原则
-
覆盖索引、减少回表操作、索引下推、索引失效(组合索引) 最左匹配、函数计算
-
一条SQL执行过程
- server层(连接器、缓存层、分析器、优化器、执行器) 存储引擎层
-
Join优化
- Index Nested-Loop Join:INLJ,索引嵌套循环连接
- Block Nested-Loop Join:BNLJ,缓存块嵌套循环连接
-
最左匹配原则
- 组合索引、order by、group by
- using filesort
- 单路排序&双路排序
- using filesort
- 组合索引、order by、group by
-
分页查询 使用索引字段
-
id 达到最大
- 有自增id 会主键id异常 20多亿
- Row_id (servcer层维护)无自增id 达到最大会覆盖
- Xid 事务id
- Trx_id innodb维护 事务id
-
Count
- 字段有索引:count( * ) ≈ count(1) > count(字段) >count(主键 id)
- 字段无索引:count( * )≈count(1)>count(主键 id)>count(字段)
-
order by
- 全字段排序和rowid排序 区别 是否使用最少字段排序 然后最后查询主键索引树
-
一些原则
- 代码线上、索引后加
- 联合索引进来使用覆盖索引
- 区分度大的字段加索引
- 长字符串使用前缀索引
- where 与 order by 优先where
- 基于慢SQL优化
-
SQL阻塞的原因
- 表锁、MDL锁、行锁、flush锁
-
索引失效的场景
- 类型不匹配 字符串 数字
CAST( xxx AS signed int)
- 表达式计算
- 破坏索引值的有序性
EXPLAIN SELECT * FROM city_info WHERE id + 1 = 2
- 函数使用
EXPLAIN SELECT count(1) FROM city_info WHERE LENGTH(city) = 1;
- like '%xxx'、覆盖索引除外
- 最左匹配
- 字符编码不同
- utf-8 和 utf8mb4
EXPLAIN select d.* from tradelog l , trade_detail d where d.tradeid=CONVERT(l.tradeid USING utf8) and l.id=2;
- 类型不匹配 字符串 数字
高性能
- 读写分离(主从复制)
- 复制方式(带来的数据不一致性) 本质就是快照+操作日志
- 同步复制 :性能不好,不丢失数据
- 异步复制:性能好,但是可能丢失数据
- 半异步复制:性能稍微好,同步至少一台从库机器。
- 复制状态机
- 复制方式(带来的数据不一致性) 本质就是快照+操作日志
- 表数据复制
- 分库分表
- 数据量大就分表,并发高就分库
- 范围分片(容易热点数据)、哈希分片(数据比较均匀)、查表法(性能差)
高可用
高可用依赖的是数据复制,数据复制复制就是从一个库备份数据,然后恢复到另一个库中
-
数据备份:
全量备份 mysqldump -u root -p test > test.sql
增量备份 binlog
-
MySQL HA
方案 高可用 可能丢数据 性能 一主一从
异步复制、手动切换否 可控 好 一主一从
异步复制、自动切换是 是 好 一主二从
同步复制、自动切换是 否 差
建立时间复杂度、空间复杂度意识,写出高质量的代码,能够设计基础架构,提升编程技能
过遍数
1.理解题意 2.尽可能所有的解 3.测试

为什么需要复杂度分析
- 代码执行受到机器外部环境以及数据量规模的影响,不直观
时间复杂度
- 估算一段代码的执行时间
空间复杂度
复杂度
- O(1) 常量级 哈希表的操作
- O(logN) 对数级 二分查找、平衡二叉树、跳表
- O(n) 线性 数组、链表的遍历,二叉树的遍历
- O(nLogN) 快排、归并、堆排序
- O(N^2) 冒泡、插入、选择排序
- O(2^N) 指数级 回溯算法
最好时间复杂度、最坏时间复杂度、平均时间复杂度。其实可以对比接口的响应最大时间,最小时间,平均时间。
均摊时间复杂度
数据结构是为算法服务的,算法要作用在特定的数据结构之上。
数组
- (Array)是一种线性表数据结构。它用一组连续的内存空间,来存储一组具有相同类型的数据。
- 增删改查
链表
-
定义 data\next
-
基本操作
- 遍历、查找、
- 插入
- 头部插入元素
- 尾部插入元素
- 优化点
- 尾部节点,不需要进行遍历 空间换时间
- 虚拟头节点,不需要对特殊情况处理
- 优化点
- 给定节点插入元素
-
链表结构
- 单链表
- 双链表
- 循环链表
- 空间换时间的设计思想
- 在给定位置插入元素 O(1)
-
写好链表的几个要点
-
警惕指针丢失和内存泄露
- 插入操作 注意顺序
-
利用哨兵简化实现难度
-
重点留意边界条件处理
-
画图
-
栈
-
先进后出
- 基于数组和链表结构
-
应用场景
- 函数调用 保存栈帧、表达式求值的应用、括号匹配应用、浏览器前进后退
队列
- 优先队列
树
- BST
- Trie
- 红黑树
- B树
- B+树
哈希表
字符串
- KMP
图
布隆过滤器
堆
LRU Cache
排序
- 快排、归并
二分
搜索
- BSF
- DFS
- 回遡
贪心算法
动态规划
递归
-
编程技巧,一个函数自己调用自己
-
递归函数和函数调用栈
-
堆栈溢出,重复计算
- 备忘录方式 动态规划
-
如何用递归来解决问题
- 发现这个问题
- 规模更小的问题,跟规模更大的问题,解决思路相同,规模不同
- 利用子问题的解可以组合得倒原问题的解
- 存在最小子问题,可以直接返回结果(存在递归终止条件)
- 递归的编写方式
- 假设B C问题已经解决,思考如何解决原问题A
- 发现这个问题
-
递归时间、空间复杂度分析
分治
- 一种思想,分而治之,大问题拆分成子问题,最后在合并子问题的和
位运算
数学
双指针
滑动窗口
目录操作
- cd / pwd / open / mkdir / rmdir / ls
文本操作
- cat、head、tail、less、more、wc -l 查看文件行数
- vim 、rm -rf、find、
系统管理
- su - 切换用户
- sudo 以其他用户身份执行命令
- kill -9 杀死进程
系统资源查询
-
ps、ps -ef、pstree、netstat、df 、top、free
-
IO
- iostat -d -x 1 总体IO
- pidstat -d 1 进程IO
- iotop
-
free
- cache是对文件系统的缓存、buffer是对磁盘的缓存。
-
df -i 索引节点磁盘空间
- cat /proc/meminfo | grep -E "SReclaimable|Cached"
- slabtop
-
系统上下文切换查看
- vmstat 5 //总体监控
- pidstat -w 5 //进程监控
- pidstat -w -u 1 //-w 参数表示输出进程切换指标,而 -u 参数则表示输出 CPU 使用指标
- pidstat -wt 1 // -wt 参数表示输出线程的上下文切换指标
- watch -d cat /proc/interrupts //内核中断指标
-
中断查看
- cat /proc/softirqs
进程管理
- CPU使用率
- 用户CPU
- 系统CPU
- IOWAIT
- 软中断
- 硬中断
- 窃取CPU
- 客户CPU
- 上下文切换
- 自愿上下文切换
- 非自愿上下文切换
- 平均负载
- CPU缓存命中率



- 系统内存指标
- 已用内存
- 剩余内存
- 可用内存
- 缺页异常
- 主缺页异常
- 次缺页异常
- 缓存/缓冲区
- 使用量
- 命中率
- Slabs
- 进程内存指标
- 虚拟内存(VSS)
- 常驻内存(RSS)
- 按比例分配共享内存后的物理内存(PSS)
- 独占内存
- 共享内存
- SWAP内存
- 缺页异常
- 主缺页异常
- 次缺页异常
- SWAP
- 已用空间
- 剩余空间
- 换入速度
- 换出速度



- 文件系统
- 存储空间容量、使用量以及剩余空间
- 索引阶段容量、使用量以及剩余量
- 缓存
- 页缓存
- 目录项缓存
- 索引阶段缓存
- 具体文件系统缓存(ext4缓存)
- IOPS(文件IO)
- 响应时间(延迟)
- 吞吐量
- 磁盘
- 使用率
- IOPS
- 吞吐量(B/s)
- 响应时间(延迟)
- 缓冲区
- 相关因素
- 读写类型(顺序和随机)
- 读写比例
- 读写大小
- 存储类型(Raid级别、本地、网络)



对称加密
非对称加密
集合类
- list
- arraylist linkedlist底层原理 time vs 扩容原理
- set
- hashset
- map
- hashmap 原理 扩容 key是如何计算的 hash冲突
- concurrenthashmap
- put() get() resize() 三个过程细化
- 7/8之间的区别 具体问题细化一下
- HashMap
- hashmap 的数据结构,扩容时机;
- concurrentHashMap 和 hashmap 的区别,为什么前者的 key 和 value 都不能为 null;
- concurrentHashMap 怎么保证的线程安全;
- concurrentHashMap 扩容过程;
字符串
OOP
关键字
异常
- 最佳实践
- 不要把异常吞了,线程池任务抛出 线程会增加
IO
- 字节流、字符流
NIO
- 通道 channel
- 默认阻塞模式
configureBlcking(false)- 阻塞:调用read 或 write ,如果RW不到数据 会等待
- 非阻塞:调用read 或 write ,如果RW直接返回不等待
- FileChannel、DatagramChannel、SocketChannel、ServerSocketChannel。FileChannel
- 异步模式
- channel直接注册到操作系统内核中,内核通知某个channel可读、可写或可连接
- 默认阻塞模式
- 缓冲区 buffer
- 常用buffer
- ByteBuffer、CharBuffer、ShortBuffer、IntBuffer、LongBuffer、FloatBuffer、DoubleBuffer、MappedByteBuffer
- Capacity 容量 创建时设定
- limit 缓冲区当前终点
- position 位置 下一个要RW元素的索引
- mark 标记
- 常用buffer
- 选择器 selector
- 解决轮训判断状态问题,多路复同器,java进行了封装,提供了一个统一的方式。
- 监听的channel注册到selector,底层通过轮训的方式 查询注册的channel 可读、可写、可连接 返回处理
范型
反射
- 作用:创建对象、执行方法、获取类的信息
- 应用场景:框架中,spring bean的生成。以及mvc\mybaits的具体方法的调用
序列化
注解
- 定义注解、标记注解、读取注解
- 应用:替换配置、自定义著丛切换等
动态代理
- 静态代理
- 实现与目标类相同的接口,然后内部包含目标类。可以做一些日志打印、耗时统计等工作
- 动态代理
- 动态运行时生成代理类的字节码,仅仅存在内存中,不会生成对应的class文件。
- 实现方式
- jdk提供的类方式
- 第三方类库,cglib asm assit
- 使用场景
- 框架中,spring aop, Dubbo RPC
- 动态和静态如何理解
- 静态是发生在编译时,动态在运行时
枚举
- SPI机制
- 提供接口、实现类、固定的文件名+实现类
- 原理:通过读取配置文件,使用反射创建类的实例 可拓展性
- 应用场景:boot springfactors\dubbo\jdbc
类加载器/流程
-
1.类加载的整套流程 说一下你的理解。 加载 验证 准备 解析 初始化
-
jvm加载机制 加载过程 加载器 双亲委派模型
-
说一下有哪几个类加载器? boot /ext / app
-
双亲委派了解吗?说一下? 如何判断两个类是否相等
-
类什么时候进行初始化呢?说一下
字节码技术
JVM对象分配回收策略
- a.对象优先eden b.大对象直接老年代 c. 动态年龄判定 d.长期老年 e.空间担保
运行时数据区
-
线程共享:堆、方法区
-
线程独占:程序计数器、虚拟机栈、本地方法栈
-
JVM为什么要分区?那些区域【是否共享】。新、老分别用什么?7.8区别、内存溢出、内存泄漏区别
-
创建对象分配方式
- 1.指针碰撞 2.空闲列表 对象内存布局 对象头、实例数据、对其填充
- 对象访问方式 1.句柄 2.直接指针
- 对象是否垃圾 1.引用计数法 2.可达性分析 四种引用
-
四种引用类型 强软弱虚
垃圾回收算法
垃圾收集器
- GC收集器【串行、并行、并发】
- CMS
-
初始标记
-
并发清理 - 三色标记法
- 漏标和误标
- 增量更新和原始引用 读写屏障解决的
-
重新标记
-
并发清理
-
JMM
- JMM内存模型,先行发生原则
- 原子性、可见性、有序性 volatile 执行重排序
JVM调优
- xmx xms 年轻代 老年代比例
- jps ->进程 jstat->信息 jinfo->配置 jmap->内存映像 jhat->堆转储 jstack->堆栈
生产问题排查
-
当一个Java程序响应很慢时如何查找问题、
-
当一个Java程序频繁FullGC时如何解决问题、
-
如何查看垃圾回收日志、
-
当一个Java应用发生OutOfMemory时该如何解决、
- StackOverflowError
- Java. heap space
- GC overhead limit exceeded
- Direct buffer memory
- unable to create new native thread
- java.lang.OutOfMemoryError:Metaspace
-
如何判断是否出现死锁、
-
如何判断是否存在内存泄露
JVM总体流程为->类加载->运行时数据区创建->内存分配回收策略->GC算法->JVM调优
分工、同步、互斥
并发基础
-
优势、为什么使用
-
进程&线程
-
线程状态\生命周期
-
线程创建
互斥同步
-
synchronized
-
基本使用同步方法,同步块
- 同步方法是通过方法中的access_flags中设置ACC_SYNCHRONIZED标志来实现;同步代码块是通过monitorenter和monitorexit来实现
- 管程模型
-
对象(对象头(markword、类指针、数组长度)、实例数据、对其填充)
-
锁升级 & mark word
-
001: 无锁、101: 偏向锁、00: 轻量级锁、10: 重量级锁
-
偏向锁(只有一个线程)
- 偏向锁延迟
-
轻量级锁
- 轻量级锁所适应的场景是线程交替执行同步块的场合,如果存在同一时间多个线程访问同一把锁的场合,就会导致轻量级锁膨胀为重量级锁
-
偏向锁->无锁 偏向锁->轻量级锁
-
轻量级锁->无锁 轻量级锁->重量级锁
-
锁消除、锁粗化
-
本质:因避免无效的锁竞争,提升整体的并发性能。
-
-
-
ReentrantLock
- ReentrantReadWriteLock
- 通过一个变量去控制两个读写锁的状态,位运算的方式
- 读写锁,锁降级(写锁降级为读锁)
- StampedLock
- 通过版本进行标记,乐观的读
- ReentrantReadWriteLock
线程协作/通信
- join/yield/sleep
- wait/notify/notifyAll
- awit/singal/singalAll
- LockSupport park和unpark
无锁编程
-
CAS、ABA
-
原子类
- 基本类型原子类
- 数组类型原子类
- 引用类型原子类
- 对象的属性修改原子类
-
LongAdder原理
- CAS+Base+Cell数组分散、空间换时间并分散了热点数据
- 应用场景:高并发下的全局计算
- 条件递增,逐步解析 1.最初无竞争时只更新base; 2.如果更新base失败后,首次新建一个Cell[]数组 3.当多个线程竞争同一个Cell比较激烈时,可能就要对Cell[]扩容
-
AtomicLong LongAdder 线程安全 线程安全,有性能损耗 当需要在高并发下有较好的性能表现,且对值的精确度要求不高时,可以使用 性能 AtomicLong是多个线程针对单个热点值value进行原子操作 LongAdder是每个线程拥有自己的槽,各个线程一般只对自己槽中的那个值进行CAS操作 精度 保证精度,性能代价 保证性能,精度代价
-
-
原理、(独占、共享)Countdownlatch/semaphore/cyclibarrier
AQS
-
AQS源码解析整体流程
大概的整体流程是这样的,首先,我们创建三个线程A,B,C。线程A先拿到锁,执行任务。 而B、C一直获取不到锁,不能执行任务。被park。等A指向完毕之后,unpark(B);
lock.lock() 线程A通过CAS 设置上锁。而等线程B去获取锁的时候,CAS获取不到锁。于是进入acquire(1)进入nonfairTryAcquire 再次尝试获取锁,获取不到、直接返回 false。进入addWaiter()将当前节点添加到队列中enq(node),因为t==null ,所以先创建一个哨兵结点。然后第二次自旋,将当前节点Node(ThreadB),添加到队列中。调用 acquireQueued() ,拿到当前节点的前置节点。第三次获取,获取不到。进入 park() 等待。等待线程释放锁, unpark() 操作。而在此时,线程A执行任务完毕,进行 lock.unlock() 操作。执行 release(1) ,通过head节点将下一个节点进行 unpark() 操作。而因为线程B被park()了,所以下一次就可以获取到锁,将队列中的哨兵结点进行修改。
工具类
-
CountDownLatch
-
CyclicBarrier
-
Semaphore
-
AQS共享模式
- Semaphore的加锁解锁(共享锁)逻辑实现
- 线程竞争锁失败入队阻塞逻辑和获取锁的线程释放锁唤醒阻塞线程竞争锁的逻辑实现
-
限流使用
-
-
Future
-
CompletableFuture
- 异步编程+回调
JMM
- 可见行、有序性、原子性
- happens-before规则、缓存结构、内存屏障
锁
- 乐观锁
- 适用场景:读多写少,会认为数据不会修改,性能高。如果出现修改,在使用CAS或者version进行判断。
- 实现方式 version版本和CAS
- 悲观锁
- 适用场景:写多读少,先加锁然后在操作。
- syn和lock
- 公平锁/非公平锁
- 可重入锁
- 死锁
- 写锁/读锁
- 自旋锁->自适应自旋 锁消除 锁粗化
- 无锁->偏向锁->轻量级锁->重量级锁 (syn锁升级)
- 无锁->独占锁->读写锁->邮戳锁 (锁降级)
线程池原理
- 线程池原理,线程池组成,拒绝策略,线程池的工作原理,阻塞队列原理、执行流程
- Future、Callable 带返回值的执行
- 阻塞队列
threadlocal原理
-
原理 :线程间变量隔离
为了解决线程内数据跨方法类的调用,使用类threadlocal,具体就是thread包含一个threadlocal,而threadlocal内部包含一个threadlocalMap对象。key为this (threadlocal) vaule为对应的值。为了保证引用可以被删一个是程序内部使用弱引用,而是通过程序员remove()进行维护删除,以及来保证内存泄露。
为什么需要多线程->解决了那些问题-> 线程状态/创建 -> 如何保证数据的一致性(同步 syn lock/互斥/cas)-> 线程间通信(wait/notify threadlocal) ->相关锁机制 syn锁升级 ->线程工具类 aqs -> CAS/ABA -> JMM -> 线程池->线程停止
并发设计模式
- 终止线程设计模式
- 两阶段终止
- 另外一个线程去判断,t.interted()
- 两阶段终止
- 避免共享的设计模式
- Immutability模式- final (只读)
- Copy-on-write模式
- CopyOnWriteArrayList
- Thread-Specific Storage模式-没有共享就没有伤害
- ThreadLocal
- 多线程版本的if模式
- Guarded Suspension模式
- 保护性暂停 Future.get() 等待
- Baliking模式-
- Guarded Suspension模式
- 多线程分工模式
- Thread-per-Message 模式
- BIO 一个线程一个任务
- Worker Thread
- 线程池模型
- 生产者-消费者模式
- 阻塞队列
- Thread-per-Message 模式
内核态、用户态、DMA、PageCache
socket:本质就是一个四元组(CIp CPORT+ SIP SPORT)
在两端为创建对应的文件描述符(FD)
netstat -natp网络状态lsof打开文件状态
同步:调用者需要等待函数的返回结果,才可以继续执行。(APP自己R/W)
异步:调用者无需等待函数的返回结果,可以继续执行,但是一般都是通过回调函数进行通知。(kernel完成RW 没有访问IO buffer)
同步vs异步:在于被调用者结果的通知方式,同步无需通知,异步需要进行回调。
阻塞:调用放一直等待结果,当前线程刮起,啥都不能干
非阻塞:调用方可以直接处理别的事情。
阻塞vs非阻塞:在于调用方等待消息时候的行为,是否可以做的别事情
BIO:BIO的特点就是在IO执行的两个阶段都被block了。
- BIO阻塞点在于 等待系统调用+将数据从内核缓冲区拷贝到用户缓冲区的阻塞时间点
NIO:NIO特点是用户进程需要不断的主动询问内核数据准备好了吗?一句话,用轮询替代阻塞!
- NIO的阻塞点 在于将数据从内核缓冲区拷贝到用户态缓冲区的阻塞时间点
IO多路复用:多条路 通过一个系统调用,获取其中的IO状态,程序自己对有状态的IO进行RW

信号驱动IO
异步IO
select : 将文件描述符,从用户态拷贝到内核态,然后内核将处理好的IO写入文件描述符中。select使用的是bitmap,判断fd的位置那个置为1了。O(N) 时间复杂度。
select方式,既做到了一个线程处理多个客户端连接(文件描述符),又减少了系统调用的开销(多个文件描述符只有一次 select 的系统调用 + N次就绪状态的文件描述符的 read 系统调用
- 优点,可以避免多次内核态到用户态的fd的拷贝
- 缺点
- bitmap默认是1024 长度,只能处理1024个线程。
- rset每次循环都需要重新置为1,不能重复使用
- O(N)的时间复杂度
poll
- 优点,解决了只能处理1024个线程的问题。
- 以及reset不可重用
epoll
-
多路复用快的原因在于,操作系统提供了这样的系统调用,使得原来的 while 循环里多次系统调用,
变成了一次系统调用 + 内核层遍历这些文件描述符。

C10K 问题本质上是操作系统处理大并发请求的问题。对于 Web 时代的操作系统而言,对于客户端过来的大量的并发请求,需要创建相应的服务进程或线程。这些进程或线程多了,导致数据拷贝频繁(缓存 I/O、内核将数据拷贝到用户进程空间、阻塞), 进程 / 线程上下文切换消耗大,从而导致资源被耗尽而崩溃。这就是 C10K 问题的本质。
操作系统层面
- 文件句柄
Socket/File:Can't open so many files- ulimit -n 默认1024
- 系统内存
- 发送缓冲区和接收缓冲区
- 网络带宽
解决之道
- 应用程序如何和操作系统配合,感知IO事件发生,调度处理上万个套接字
- 应用程序如何分配进程、线程处理上万个连接
- 方式
- 阻塞IO+进程 fork一个子进程处理
- 阻塞IO+线程 创建单独线程处理每个请求
- 非阻塞IO+readliness notification + 单线程
- 非阻塞IO+readliness notification + 多线程
- 异步IO+多线程
- 约定优于配置、低侵入、松耦合、模块化、轻量级、
Spring工厂容器
-
工厂分类
beanFactory接口configurableBeanFactory、AutowireCapableBeanFactory、ListableBeanFactoryDefaultListableBeanFactory- XmlBeanFactory 读取XML配置文件 创建对应的对象
-
ApplicationContext
- ClassPathXmlApplicatonContext、AnnotationConfigApplicationContext
-
BeanFactoryPostProcessor
- 重要的实现子接口
BeanDefinitionRegistryPostProcessor - 加工的是 Spring BD 信息
- 应用场景分析
- 重要的实现子接口
-
BeanPostProcessor
- 加工的是Spring 创建的对象
Spring循环依赖
-
循环依赖是在SpringBean初始化声明周期而产生的问题
整体流程,其实就是A创建的过程中需要B,所以将A对象自己放入三级缓存中,然后去实例化B。 2.B在实例化的时候,发现自己引用了属性A,所以从三级缓存中依此查询,查询一级缓存没有,在查询二级缓存也没有,发现三级缓存有,将A从三级缓存放入二级缓存,并将三级缓存中的A删除。 3.B创建完毕之后,将自己放入一级缓存中。然后A接着创建,直接从一级缓存中获取B。A创建完成,将自己放入一级缓存中。 整个过程其实就是依赖于如果发现是循环依赖的话,通过将对象提前暴露出来(一个半成品对象),存储缓存中,并且scope=singleton。所以可以解决这个问题。
其实不考虑代理对象的话,可以使用二级缓存进行处理。三级缓存其实就是提升生成一个代理对象来使用。
-
存储三级缓存的位置
-
实例化完成
- 添加三级缓存
-
初始化完成
- 添加到一级缓存,删除二、三级缓存
-
查询缓存
- 从三级查询 存储到二级缓存
-
一二级缓存 本身可以解决循环饮用,三级缓存解决的是代理对象问题
-
Bean生命周期
-
BD创建与注册
-
配置Bean的方式 XML、注解
-
本质都是通过newBD来进行创建 无论是注解还是XML方式
-
XML
GenericBeanDefinition -
注解
AnnotationedBeanDefinition -
编码方式
BeanDefinitionBuilder bdb = BeanDefinitionBuilder.genericBeanDefinition(Person.class); AbstractBeanDefinition beanDefinition = bdb.getBeanDefinition();
-
为什么需要BeanDefinitionHolder
- 操作方便,传参数方便
-
在通过注解或者XML 生成DB对象之后,可以编程式修改BD,是一个非常重要的拓展点。BFPP 其实就是修改BD
-
MutablePropertyValues propertyValues = beanDefinition.getPropertyValues(); propertyValues.add("pwd", "123"); ConstructorArgumentValues constructorArgumentValues = beanDefinition.getConstructorArgumentValues(); constructorArgumentValues.addArgumentValues("123");
-
注册到Map中
DefaultListableBeanFactory.beanDefinitionMap key=beanName value=BD
-
-
注册一个bean常见方式
-
注解方式、XML
- 不推荐XML方式,推荐使用@component 程序员自己创建的类型 这种方式
-
@Bean注解
- Spring开发过程建议我们使用注册的方式,别的框架 非Spring 组件,提供的类型,SqlSessionFactory
-
扫描基础包 ClassPathBeanDefinitionScanner(Spring Boot就是这种方式)
-
@Import (这种方式不会暴露给用户,封装细节)
-
应用场景
- 主要是应用框架底层封装,SpringBoot 自动装配
-
@Import(xxxx.class) 不推荐
-
实现
implements ImportSelector 实现方法 添加@Import(xxx.Class)- 有Class文件 推荐使用 SPI机制
-
ImportBeanDefinitionRegistrar 实现接口 自定义BD信息 自己注册- 不存在实际的Class,需要动态字节码技术 运行创建的类型
- MyBatis 接口动态生成
-
-
在实际的工作中,如何选择应该使用哪种方式进行注册一个Bean对象
-
-
Refresh()
- 关注Spring 帮我们创建了几个BD
beanDefinitonMap,即将创建对象的一个模版 - 关注spring 创建了那些完整的对象,已经创建完成
singletonMaps- 提前创建的几个BD,什么时候注册的
- AnnotatedBeanDefinitionReader
- key:internalConfigurationAnnotationProcessor Value:ConfigurationClassPostProcessor
- 作用 : 解决bean注册问题
- 解析 @configuration @compentscan @compentscans @import
- @ImportResource 遗留系统 @PropertySource
- 作用 : 解决bean注册问题
- Key: internalAutowiredAnnotationProcessor Value: AutowiredAnnotationBeanPostProcessor
- 作用 解决依赖注入属性值
- @Autowired, @Value @Inject
- 作用 解决依赖注入属性值
- Key: internalCommonAnnotationProcessor Value: CommonAnnotationBeanPostProcessor
- 作用 生命周期注解
- 解析 @PostConstruct @PreDestroy @Resource
- 作用 生命周期注解
- 事件相关的
- key: internalEventListenerFactory Value: DefaultEventListenerFactory
- Key: internalEventListenerProcessor Value : EventListenerMethodProcessor
- 思考:Spring 尽管从XML架构提升到注解方式,但是底层整体流程没有改变,满足开闭原则,仅仅通过postProcessor进行拓展设计功能。
- 提前创建的几个BD,什么时候注册的
- prepareRefresh
- 初始化标记 设置时间 事件的准备
- obtainFreshBeanFactory
- 获取Bean 工厂
DefaultListableBeanFactory
- 获取Bean 工厂
- prepareBeanFactory ⭐️
- 设置类加载器,为创建对象 或者 反射相关的操作
- 设置EL表达值
- 设置属性编辑器-类型转换器
- 创建一个ApplicationContextAwareProcessor
- 不在工厂启动的时候操作,而是在创建对象的初始化过程中,通过beanPostProcerrorBefore方法完成
EnvironmentAware ResourceLoaderAware ApplicationContextAware- 不要在工厂启动的时候 注入这些aware ,而在对象创建的时候 在注入
- 为什么这样设计: set方法 不会自动注入,需要手动调用,必须放在bean 初始化操作中
- 进行接口类型与实现对象的配对
- Beanfactory -> defaultListableBeanFactory
- 添加工具类
- 系统环境等
- postProcessBeanFactory
- 空实现
- invokeBeanFactoryPostProcessors ⭐️
- 作用:把所有的BeanFactoryPostProcessor 以及BeanDefinitionRegistryPostProcessor的类型,进行注册 并进行调用
- 1.内置
- BeanDefinitionRegistryPostProcerror priorityOrdered
- ConfigurationClassPostProcessor
- BeanFactoryPostProcessor
- EventListenerMethodProcessor
- BeanDefinitionRegistryPostProcerror priorityOrdered
- 2.add方法添加的
- Add 没有注册的 -BD-Map中 但是会执行
- 不会注册的原因 是 注册工厂 需要new 对象,通过add 的方式 已经new了
- 3.@component注解添加
- 会执行 也会注册
- 核心 把业务相关注解的Bean 解析获取 生成BD
- 调用BeanFactoryPostProcessor (修改BD 信息)
- BeanDefinitionRegistryPostProcessor
- ConfigurationCLassPostProcessor
- postProcessBeanDefinitionRegistry
- 根据注解找到bean的注册,生成BD,注册BeanFactory BDMap
- postProcessBeanDefinitionRegistry
- invokeBeanFactoryPostProcessors
- postProcessBeanFactory
- enhanceConfigurationClasses
- 为所有@Configuration 修饰的配置bean 应用时会生成代理对象使用
- 因为配置Bean没有实现任何接口,创建代理的过程中,基于Cglib的形式
- 为什么要对配置bean 要进行代理的处理呢?
- 通过代理可以为@confiruration 注解中的方法 增加@scope相关的功能
- 替换BD的beanClass AppConfig 添加一个代理对象,添加拦截器,设置回调, 这个方法只是代理的@Configuration的配置的BD
- enhanceConfigurationClasses
- 添加BFPP的几种方式
- 默认提供的 ConfigurationCLassPostProcessor
- ctx.addBeanFactoryPostProcessor(xxx)
- 程序员自己的添加的 @Compent
- postProcessBeanFactory
- registerBeanPostProcessors ⭐️
- 注册BeanPostProcessors, 实例话BPP , 本过程会创建BPP的对象,
- BFPP 修改的是BD信息
- BPP 修改的是Bean对象
- 该过程仅仅是注册 不会实际调用。在bean实例话的时候 才会调用
- spring 内置
- AutowiredAnnotationBeanPostProcessor
- CommonAnnotationBeanPostProcessor
- 程序员添加的
- Add (ApplicationContextAwareProcessor、ConfiguatiionClassPostProcessor#importAware、ApplicationListenerDetector)
- spring 内置
- 针对 enableXX 都是通过import 完成注册
- 注册BeanPostProcessors, 实例话BPP , 本过程会创建BPP的对象,
- onRefresh
- finishBeanFactoryInitialization ⭐️
- 通过spring的beanFacpty创建单例对象
- 前置准备工作
- 1.准备BD -> @ConfiruationClassPostProcessor -> BFPP
- 2.准备 BPP
- @AutowiedAnnotationBeanPostProcessor
- @Common
- 需要解决 @Value @Autowired @Resource @PostConstuct @PreDestory 注解
- 关注Spring 帮我们创建了几个BD
-
实例化
- 通过反射的方式 创建对象
-
属性注入
- set xml 、 注解 不同的处理方式
- postProcessProperties 找到属性
- postProcessPropertyValues 属性赋值
-
初始化-循环依赖
- 拓展点
-
使用
-
销毁
-
BeanFactotyAware
- 解决scope = prototype 注入失效的问题
-
BeanPostProcessor
- 完成对象加工,拓展点 统一处理 减少冗余代码
- 可以解耦合处理
AOP原理
-
AOP核心概念
- 代理模式:通过代理类 为原始类 增加目标功能
- 好处:目标类的更好的维护
- 生成代理类是一个过程 , 执行过程是一个过程
-
创建AOP准备工作
-
原始对象 只做核心功能 service
-
额外功能
- 柑橘运行时机 添加额外功能
-
切入点
- 额外功能增加给那些原始方法,切入点决定
-
切面
- XML Advisor
- Aspect @Aspect
-
-
JDK动态代理原理
-
Cglib原理
-
AOP动态代理的实现流程
-
Spring负责原始对象的创建 通过,通过引入一个BPP 去影响bean的创建
- @EnableApsectjAutoProxy
AnnotationAwareAspectJautoProxyCreator- 初始化阶段执行的
-
为什么通过postProcessor 创建AOP
- 更具备语意化
-
事务原理
- 事务 保证业务操作完整性的一种数据库机制 (driver驱动)
- 事务处理
- 单机版本
- 如何保证connection service和dao是同一个 通过threadLocal
- 分布式版本
- 单机版本
- Spring控制事务
- 编程式:TransactionTemplate 模版设计模式
- 声明式:AOP Proxy代理模式 配置文件 或者注解方式
- 事务属性
- 隔离属性 isolation
- 主要解决的是事务的并发,默认ISOLATION_DEAULT 数据库默认设置 传播属性,作为spring事务的默认属性
- Read_UNCOMMITED 读取另一个事务未提交的数据 - 脏读
- Read_COMMITED 读取已提交数据
- REPEATBLE_READ 不可重复读
- SERILZABLE = 幻读的问题
- 主要解决的是事务的并发,默认ISOLATION_DEAULT 数据库默认设置 传播属性,作为spring事务的默认属性
- 传播属性 propagation。 解决事务嵌套问题 ⭐️
- REQUIRED 当前的这个业务方法 外部没有事务 就开启事务,外部存在事务 则融合
- REQUIRED_NEW 当前的这个业务方法 外部没有事务 就开启事务 , 外部存在事务,开启一个新事务,执行完新的事务,还原外部事务继续执行
- MANDATORY 当前这个业务方法外部必须存在事务
- NEVER 当前的这个业务方法 外部一定不能存在事务
- SUPPORED 当前这个业务方法 外部没有事务部 不开启事务,外存存在事务,则融合
- NOT_SUPPERTS 当前这个业务方法 外部没有事务部不开启事务,外存存在事务,则抛异常
- NESTED 内嵌事务
- 超时
- 超时属性 通过超时属性 设置本事务 最长一个等待时间-1 数据库底层决定等待时间
- 只读
- 设置事务为只读,提高事务运行的效率 false
- 异常
- RuntimeException 及其子类。默认回滚
- Exception 及其子类 默认提交
- 隔离级别、传播属性、超时 是不同厂商的支持
- 源码剖析
- 1.事务是依赖于AOP BPP的过程修改的
- 2.Spring 事务的底层 依附于DataSource -> connection -> ThreadLocal中 开启 回滚 提交
- 3.额外功能
- DataSourceTransactionManager (PlatformTransactionManager) JDBC Mybatis
- TransactionAttributes
- 1.BPP 创建代理
- 隔离属性 isolation
IOC原理-刷新方法
- 容器刷新前的准备工作
- bean工厂的创建
- 加载BeanDefinition
- 执行BeanFactoryPostProcessor增强器
- 进行国际化配置
- 多播配置和监听器的初始化
- 实例化bean对象
- 实例化完成后的处理工作
Spring MVC原理
Spring中设计模式
springbootstart加载原理
- 自动装配原理
Nacos
- 服务注册与发现 核心流程 源码
- 配置中心的使用
OpenFeign
Gateway
sentinel
基本概念
-
线程模型
-
核心组件
- Bootstrap\ServerBootStrap
- channel 通过管道进行设置参数
- eventLoop -> 等价一个线程 主要IO操作 普通任务 定时任务
- 组成 selector thread 任务队列
- accept\read\write
- Unsafe -> 主要负责真正的IO操作 read \ wite
- ChannelPipleline (每个线程独立)
- ChannelContext
- ChannelHandler
- 以双向链表进行展示的
- 输入
channelInBound - 输出
channelOutBound
- 输入
channel.writeAndFlush从tail-> 往尾部往前找ctx.writeAndFlush从当前Handler 往后找- 每一个
channelHandler封装在了channelContext(handler事件传播、ByteBuf内存分配器)
- 以双向链表进行展示的
- pipeline什么时候创建的
- 优化
- selector
- FastThreadLocal
- HashWheelTimer
-
拆包\粘包
- 为什么有
- MTU (链路层一次最大传输数据) 、MSS(TCP一次发送最大数据的大小)、滑动窗口(流量控制手段)、Nagle算法(解决频繁发送小数据)
- 是什么
- 拆包:当数据满足了 解码条件时,将其拆开。放到数组。然后发送到业务 handler 处理。
- 粘包:当读取的数据不够时,先存起来,直到满足解码条件后,放进数组。送到业务 handler 处理
- 原因:发送方每次写入数据 < 套接字缓冲区大小
- 接收方读取套接字缓冲区数据不及时
- 解决方案
- 消息长度固定
FixedLengthFrameDecoder- 实现简单,但是比较浪费空间
- 特定分隔符
DelimiterBasedFrameDecoder - 消息长度+消息内容
LengthFieldBasedFrameDecoder
- 消息长度固定
- 为什么有
-
内存管理
- 内存规格
- netty默认申请内存大小16MB Chunk(PoolChunk) 每一次都申请16MB,一个Chunk划分为多个Page(8K)
- Huge : netty大于16MB内存定义Huge大型内存,不做缓存
- Normal: 最小占用的内存 一个Page(8K) 最大16MB(Chunk) 8K倍数增加
- Small Tiny 小于Page的数据单位
- Tiny 最小值16B->498B 每一次都按照16B 每一次增加16B
- Netty内存池 结构的设计及其相关对象
- PoolArena 内存池管理内存的核心 总体的管理者
- Netty采用固定数量的多个Arena 进行内存的分配 每个线程都有一个,多个线程进行共享同一个
- PoolArena 内存池管理内存的核心 总体的管理者
-
其他
源码解析
- 核心组件源码剖析
- 事件循环组
- 读/写请求源码
- 内存管理策略
- 内存池的本质 合理使用有效的内存资源
- 目的 内存少(空间),应用快(时间)、Java中 减少Full GC的STW
- Netty 是如何合理使用内存
- 尽量使用基本类型,不使用包装器
- 尽量类变量 不使用成员变量
- 如何选择 数据相同 推荐类变量 数据不同 推荐成员变量
- 对象复用
- 对象池 线程级别中复用 对象
- 内存的使用进行评估
- 使用零拷贝
- 直接内存、堆外内存(降低GC,提高传输性能)
- Netty 内存池
- 编码器
- 时间轮
- 时间轮是一种理论概念,netty、dubbo、Kafka、Quartz都有自己的实现
- 基本概念
- 总块数 wheelSize
- 每块对应的时间间隔
- 当前所指的时间 currentTime,独立的线程
- 任务 task
- fastThreadLocal
- 内存池
- 重要资源
- 连接 线程 内存池
- 注意点
- 一般配合直接内存使用,堆内内存 堆外内存 效果更好
- 堆外内存 申请和释放都是高成本操作
- 内存池核心设计点
- 高效分配和回收内存
- 线程内复用、线程间共享
- 尽量减少内存碎片、内部碎片、外部碎片
- 内部碎片:内存分配单元 页内有空闲
- 外部碎片:内存分配单元 页之间有空闲
- 内存分配器
- glibc 标准的内存分配器实现 兼容性好
- tcmalloc(thread cacheing malloc)
- Jemalloc 内存规格划分 Small Large Huge
- Buddy 伙伴算法 解决外部碎片
- Slab 内部碎片
- PoolChunkList
- init->00->25->50->75->100
- 添加 minUsage->maxUsage 升级和降级的过程
- 初始化的过程 先找找不到在创建新的
- PoolChunk
- 管理算法 伙伴算法
- 重要资源
- 高性能无锁队列 Mpsc Queue
- 整合Spring
- DataSource->SqlSessionFactory-> @MapperScanner 动态代理 生成Mapper代理实现
- 开源项目学习
- github.com/jd-opensource/sql-analysis
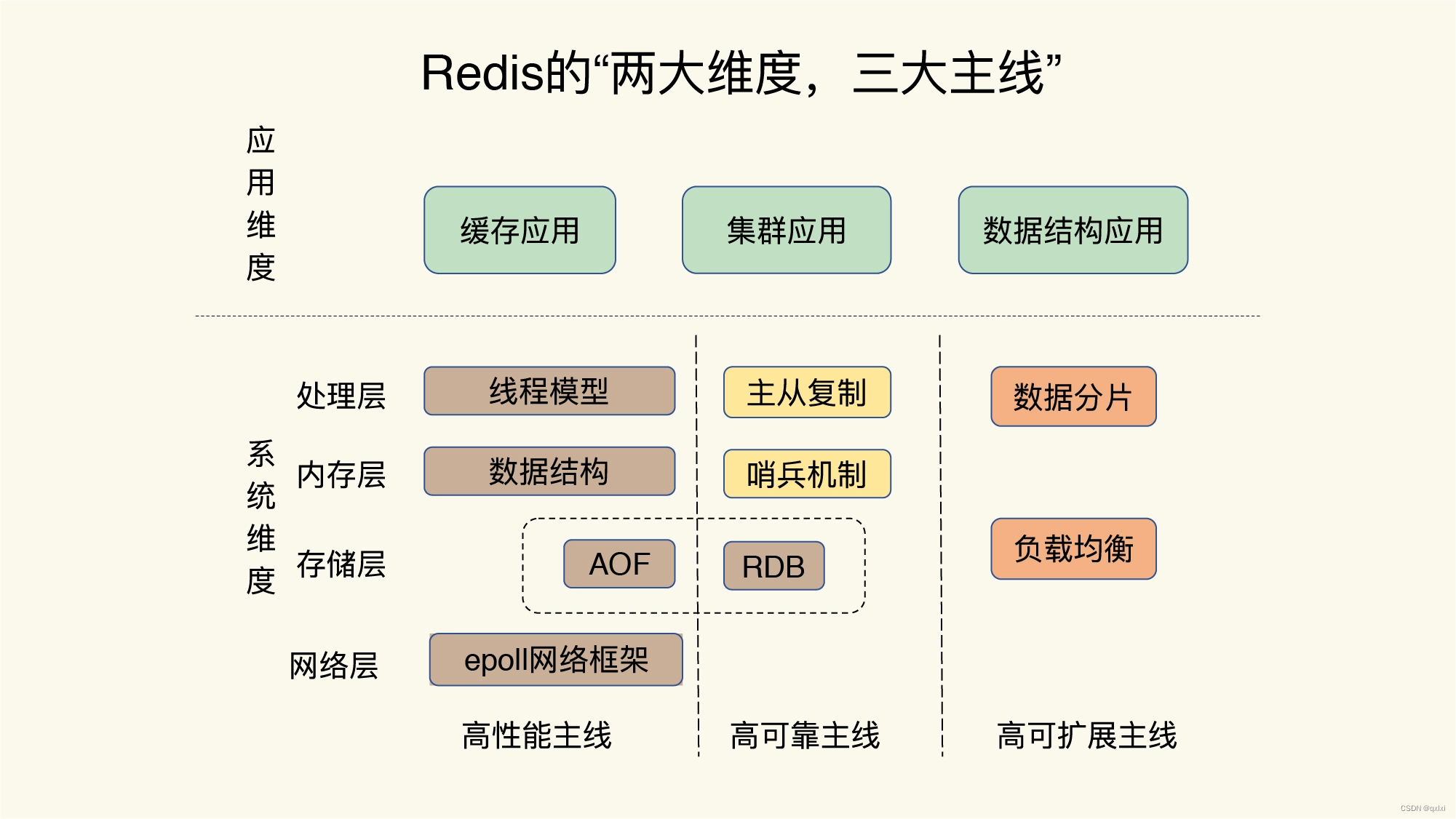
数据结构
-
全局哈希表
- rehash过程
-
数据类型
-
字符串
- int、embstr、raw
-
哈希
- Ziplist、hashtable
-
列表
- ziplist、linkedlist
-
set
- hashtable
-
zset
- Ziplist、跳表
-
-
bitMap、HyperLogLog
高可用
-
数据高可用-持久化
-
AOF
- 追加文件,但是文件太大时 会有重写机制 fork一个线程操作
-
RDB
- save 、bgsave
- 写时复制机制
-
-
主从复制 (实例高可用)
- 第一次全量复制,之后增量复制
- 不保证数据的强一致性
-
哨兵机制 (保证主节点高可用)
-
通过哨兵监控主库心跳,实现主库故障判断和⾃动切换
-
判断主库下线
- 主观下线 , ping 不通
- 客观下线 (减少误判)
- 只要大多数的哨兵实例,都判断主库已经主观下线,主库会被标记为客观下线
- 需要哨兵集群
-
选择主库
- 过滤掉⽹网络状况不不好的从库:down-after-milliseconds * 10 • 剩余从库打分:从库优先级 > 从库复制进度 > 从库ID号
-
通知客户端
其他从库主库已切换新主库
-
高性能
-
单线程模型
-
IO多路复用
-
select、poll、epoll
-
可拓展
- 切片集群
缓存
-
redis内存
- 满了 怎么办? 通过配置设置,超过最大值 写入异常
- redis过期数据删除策略
- 立即删除、惰性删除、定时删除
-
数据双写不一致
-
更新策略
- 先更新缓存,后更新DB - 不推荐
- 先更新DB,后更新缓存- 不推荐
-
删除策略
-
先删除缓存 后更新DB ❌
- 延迟双删
redis.delKey(X) db.update(X) Thread.sleep(N) redis.delKey(X) -
先更新 后删除 ✅
-
-
倾向于删除缓存,
-
最终一致性
- 缓存添加过期时间 业务上需要容忍
-
-
淘汰策略
- LRU
-
击穿、雪崩、穿透
- 雪崩:大量请求打到DB上 随机的过期时间
- 击穿:某个热点key,微博TOP10数据。 提前预热
- 穿透:cache 和 db 都查不到数据
- 布隆过滤器
- 数据结构:bitMap
- 多个hash函数
- 用户不存在,一定不存在
- 使用
- 初始化数组
- 输入数据
- 查询或者更新
- 布隆过滤器
-
BigKey
- 网络IO阻塞、内存不均匀
- key * 、flushdb、flushall
应用场景
-
分布式锁
- Redission
-
消息队列
redis事务和数据库事务区别
- Redis的事务本质是可以一次执行多条命令、并且在这个事务中会序列化执行,按照顺序串行化执行而不会被其他命令插入,不许加塞。
- 原子性
- 中途异常,一半回成功 一半失败
- 一致性
- 隔离性
- 通过watch机制监听是否修改
- 持久性
- AOF和RDB 无法百分百保证数据持久化
- 原子性
消息队列作用
- 异步、削峰、解耦、提升写性能
- 如何理解解耦,比如同步写入下游有ABC,但是通过MQ 可以实现自由拓展CDEF
- 异步:写MQ成功,下游自己获取处理 就是一个异步过程
- 削峰:削的不止消息,还有连接网络等资源
带来的问题
- 消息延迟、系统的复杂度、数据不一致(消息顺序、消息丢失、重复消费、消息挤压、实例高可用、实例高性能)
- 消息挤压如何处理 ?
- 优化性能避免消息挤压
- 发送端性能优化
- 准备数据、序列化数据、之前的耗时
- 发送消息和返回响应网络传输中的耗时
- Broker处理消息的时延
- 消费端性能优化
- 优化消费端程序业务逻辑性能
- 水平扩容,增加消费端并发数据。加机器,分区。
- 发送端性能优化
- 发送快了,消费变慢了
- 监控、紧急消费端扩容、关闭上游系统功能、错误日志、同一条消息反复消费,拖垮整个系统
- 紧急扩容分区和消费数
- 优化性能避免消息挤压
- 避免重复消费
-
MQTT协议,至多一次(丢消息),至少一次(重复消费),恰好一次
-
幂等性
-
Producer幂等
- 事务性producer
- 幂等性 Producer 只能保证单分区、单会话上的消息幂等性;而事务能够保证跨分区、跨会话间的幂等性
-
Consumer幂等
- MVCC、唯一键、set nx
-
- 消息顺序
- 单个partition可以保证,多个partition无法保证
- 方案实现简单,但是性能太差
- 提升消费性能,异步消费
- 大多数业务其实并不是全局有序,而是业务有序,比如先创建订单,后支付。
- 控制有序要求的业务消息按业务要求的顺序发送到一个queue
- 单个partition可以保证,多个partition无法保证
- 消息可靠传输、不丢失
- 发送端采用异步发送,broker端 持久化消息在ack,集群模式 多副本 消费端 处理完业务在消费
异步处理
- 提高系统的稳定性和容错能力,吞吐量,并发能力
延迟队列&定时消息
- 前者是timer后,后者是timer内
Kafka基础架构
-
Cluster
- Broker
- Topic
- Partition
- Partition Leader
- Partition Follower
- Partition
- Topic
- Broker
-
consumer
-
product
-
部署架构:单机模式/集群模式
分区机制
- 作用提升负载均衡、可伸缩能力、提升系统处理写性能
- 策略:随机、轮询(默认方式)、按消息键保序、其他策略、基于地理位置的分区
压缩算法
生产者流程
- main线程、拦截器、序列化器、分区器、sender线程,双端内存队列
Kafka如何实现高性能
- 批量发送、顺序读写提升磁盘IO性能、PageCache加速消息读写、零拷贝技术
Kafka消费者分区分配和重平衡 ⭐️
- Consumer Group是Kafka提供的可扩展且具有容错性的消费者机制
- Consumer实例的数量应该等于该Group订阅主题的分区总数
- 触发rebalance
- 组成员发生变更,减少或者增加
- 订阅主题发生变更
- 定于主题的分区数发生变更
- 避免rebalance
- 弊端
- 影响consumer端TPS、慢、效率不高
- 2类非必要的rebalance
- consumer没及时发送心跳请求,导致踢出 group
- consumer消费时间过长导致
- 减少rebalance
- session.timeout.ms >= 3 * heartbeat.interval.ms
- max.poll.interval.ms
- GC 参数
- 弊端
位移主题
- consumer_offsets 保存kafka消费者的位移信息
- kafka集群中第一个consumer程序启动时,kafka会自动创建位移主题
- kafka使用compact策略删除位移过期中过期消息 避免该主题无限器膨胀
消费者位移
- 格式:key是groupId+topic+分区号,value是offset的值
- 自动提交
- Compact 策略 解决同一个位移保存多份的问题
- 手动提交
- 同步提交
- 比较影响系统TPS
- 异步提交
- 同步提交
副本机制
- 作用:数据冗余-高可用性、高伸缩性-提供读、数据局部性
- 多个副本如何保证数据一致性
- 基于leader的副本机制
- 领导者副本(ISR)
- 提供读写
- 追随者副本
- 同步数据
- 当领导者副本宕机后,有机会成为领导者副本
- 选举问题
- unclean领导者选举
- 数据不一致性 & 服务可用之间平衡
- 领导者副本(ISR)
- 基于leader的副本机制
Kafka多线程消费
- Kafkaconsumer:用户线程和心跳线程
- 用户线程用来处理消息,心跳线程定期给broker发送心跳请求
- 实现方案:
- 1.启动多个线程,每个线程独立的consumer实例
- 2.Worker Thread 模式
Kafka高水位和Leader Epoch原理
- HW:offet+1
- LEO:所有副本最小的LEO
- Leader副本和Follower副本时间上的间隔期,导致消息丢失
- Leader Epoch
压缩算法
- 压缩地方 生产端和broker
- 重新压缩:broker和生产端 压缩算法不一致,broker端发生消息格式
- P 压缩 B 保持 C 解压缩
- 性能和空间的取舍
无消息丢失配置
- 生产端
- 回调发送消息
producer.send(msg, callback)acks = all已提交retries重试
- 回调发送消息
- Broker
unclean.leader.election.enable = false哪些broker有资格竞选分区leaderreplication.factor消息保存几份min.insync.replicas写入副本个数 一般大于1
- 消费端
enable.auto.commit手动提交位移,消费完再提交
- 拦截器
- 生产者和消费者拦截器
Java生产者如何管理TCP连接
- 选择TCP的原因:TCP本身提供的一些高级功能,
- 创建KafkaProducer实例时创建的。更新元数据后 或 消息发送后
- 关闭连接:用户主动关闭、Kafak自动关闭
如何设计一个消息队列
- 存储设计:高可用-数据持久化、顺序读写、零拷贝技术
- 可伸缩:分布式,kafka
- 消息丢失:多主多从,多副本,选择协议
- 网络框架:netty等
为什么Kafka不支持读写分离
- 说白了就是 除了leader分区写功能,其他follwer分区也需要支持读。
- 读写分离本身就有一定的数据一致性风险。
- 读写分离 一定有数据延时
kafka
- producer
- 初始化
- 消息发送
- 元数据更新机制
- sender线程流程
- batch发送
- 消息缓冲区
- consumer
- 初始化配置
- 选举consumer leader
- 协调器分区分配 不同策略
- 拉取消息
- 提交位移
- 各种配置文件
- stream组件
- java客户端
- connect组件
- 服务端
- 日志模块
- 请求处理
- controller模块
- 状态机模块
- 延迟操作模块
- 副本管理操作
- 消费者组管理模块
日志收集、解析、存储、日志检索
- 部署架构
- Config Service提供配置的读取、推送等功能,服务对象是Apollo客户端。
- Admin Service提供配置的修改、发布等功能,服务对象是Apollo Portal(管理界面)。
- Config Service和Admin Service都是多实例、无状态部署,所以需要将自己注册到Eureka中并保持心跳。
- 服务端设计
- 配置发布后的实时推送设计
- 发送ReleaseMessage的实现方式
- Config Service通知客户端的实现方式
- 客户端设计
- 长连接
可观测性
- 从系统对外输出的信息,指标、日志、链路 可以帮助我们了解内部系统状态和运行情况
- 目的:解决当系统和应用出现问题时,可以找到问题的根本原因
- 指标:一段时间内测量的值
- 减少故障的方式
- 避免故障的发生,常态化预防,流程机制,研发、测试、上线流程、验收等流程
- 故障发生,止损,减少故障时长,通过监控及时发现定位故障。
监控需求来源
- 了解数据趋势,知道系统未来某个时间是否出现问题,多项指标监控
- 了解系统的水位情况,为服务扩缩容提供数据支持
- 给系统监控,调优提供放心,比如JVM 堆内存大小
成熟产品
- Open-Falcon、Zabbix、Prometheus、Nightingale
监控基本术语
- 监控指标
http_request_total{uri="/api/placeOrder",method="POST",application="xxx-dog",instance_ip="x",} 10- 指标名称 + 标签 + 样本值 + 时间戳
- 标签方式
- 指标类型
- Gauge - 测量值 ,关注当前值,线程池,CPU使用率变化 固定在一个间隔内
- Counter - 单调递增的值,关注变化量、变化率, QOS
- rate QPS、
- increase 一段增长的值
- Histogram - 直方图 描述延迟分布
- Summary - 摘要类型,客户端计算延迟分布位
- 时序数据库
- 告警
黄金指标
- 延迟:服务请求花费的时间
- 流量:HTTP服务的话就是每秒HTTP请求数
- 错误:请求失败的速率,每秒多少请求失败的
- 饱和度:资源受限情况,CPU使用率
监控分类
- 业务监控
- 端上访问:访问方式、兼容性、内容变更、使用体验
- App:崩溃率、卡顿率、卸载率
- 网页:白屏时间、首屏时间
- 应用监控
- Qps、状态码、请求时间
- 组件监控:MySQL、Redis、Kafka、k8s
- 数据库:QPS、查询耗时、TPS、主从延迟数、连接数、数据量
- 队列:Lag、发送数量、消费数量、分区数
- 缓存:相应时间、命中率、网络延迟时间、使用内存、资源链接、缓存数量
- 资源监控:服务器、网络设备等、基础网络
- CPU、内存、磁盘、网络、IO、句柄
基本架构
- 采集器->时序DB->告警引擎->告警发送->数据展示
- 采集器
- Telegraf、Exporters、Grafana-Agent、Categraf
- 时序数据库
- InfluxDB
监控采集方式
- 即时通讯,钉钉、短信、电话等
-
对特定时间发生事件的文本记录
-
日志功能
- 打印调试,问题定位、监控告警&用户行为审计、信息埋点、追踪数据变化、数据分析
-
日志级别
- Trace、Debug、Info、Warn、Error、Fatal
-
日志框架
-
接口框架
- SLF4J
-
实现框架
- logback、log4j 2.x
-
-
规范
- 线程信息、traceId、时间、机器名
- traceId 如何打印
- MDC.put(x,x)
- 线程切换,使用参数传递 或者 抽象线程池类、
- 系统间调用,header设置traceId 处理
-
哪些地方需要打印日志
- 上下游系统交互的地方,三方系统对接的时候。
- 关键信息链路
- 可能出现异常的地方,打印日志是个技术活
- 业务流程预期不符
-
日志包含信息
- 时间、日志链路、线程名、接口名、方法名、耗时、系统上下文信息、入参、出参
- 通过分布式系统的端到端的路径

-
可维护性、可读性、可拓展性、灵活性、简洁性、可复用性、可测试性、健壮性
- 可维护:对于后续添加修改一个功能是否方便
- 可读性:CR时别人是否可以轻易读懂你的代码
- 命名、编码规范、注释、函数、高内聚低耦合等
- 可拓展性:新增功能是否可以拓展的方式新增类,而不是大幅度修改核心类。代码预留了一些功能扩展点
- 表示我们的代码应对未来需求变化的能力,设计模式解决的就是可拓展性
- 简洁性
- KISS原则,保持简单 思从深而行从简
- 可复用
- DRY
- 面向对象解决
-
多态、继承 写出可复用代码
-
编码规范写出可读性好的代码
-
设计原则指导写出可复用、灵活、可读性、易拓展、易维护代码
-
设计模式指导写出拓展性
-
持续重构->可维护性代码
-
代码是经济的
- 从软件的生命周期谈起,说白了就是后期维护成本,不能仅仅满足功能的前提下,考虑后期维护调整。
-
减少错误的关卡
- 提高程序员的素养、编译器、回归测试、代码评审、代码分析
类型系统
范型编程
面向过程
面向对象
-
什么是面向对象分析、设计、编程
- 其实就是针对类的分析、设计、以及编程,但是使用面向对象语言编程写出来的代码未必就是面向对象风格,可能是面向过程的。使用非面向过程语言也可以写出面向对象风格的代码。
- 分析:搞清楚做什么 设计:如何做 最终的产物就是类、属性方法、类与类的交互
-
封装、抽象、继承、多态
- 封装-信息隐藏和数据访问保护
- 抽象-隐藏方法的具体实现,提高可拓展性、维护性、处理复杂系统的有效手段
- 继承-解决代码复用
- 必须是is_a的关系
- 语法限制
- 多态-提高代码的拓展-复用
-
接口 VS 抽象类
-
基本定义
- 抽象类:不能被实例化、只能被继承、抽象类可以包含属性和方法,也可以包含抽象方法。子类继承抽象类 必须实现抽象类的所有的抽象方法
- 接口:接口不能包含属性和方法实现,类实现接口的时候必须实现接口的所有方法
-
解决什么编程问题
- 抽象类 解决代码复用-和继承关系一样
- 接口 解决解耦合问题 隔离接口和具体的实现,提高代码的拓展性
-
应用场景
- 为了解决代码复用,使用抽象类 - 自下而上的编程方式
- 为了解决抽象问题,使用接口 - 自上而下的编程方式
-
-
基于接口编程而非实现编程
- 应对需求变化而进行设计,将稳定层进行抽象,变化层进行隔离。
-
多用组合而非继承
- 继承可能导致层级太深,影响代码的可维护性
- 继承主要有,复用、is-a关系、支持多态
- 通过组合、接口、委托实现
-
MVC&DDD
-
贫血模型:只包含数据,不包含业务逻辑
- Controller->Vo
- Service->BO
- Repository->Entity
-
充血模型:业务和数据包含在一个类 DDD :重domain 轻service
-
如何选择
- 业务复杂 推荐DDD 业务简单 推荐传统开发模式
-
-
面向对象比面向过程有哪些优势
- OOP能应对更大规模复杂程序的开发
- OOP 风格的代码更加易用、易拓展、易维护
- OOP 人性化 高级 智能
-
OOP和AOP的理解
- 现实世界是复杂的,如果只具备一个对象的基本操作,那么所做的功能有限,所以需要AOP提供增强功能,AOP是对OOP强有力的补充技术
- IOC
- Spring IOC解决的是对象图的初始化和自动状态,已经完整一些拓展点的功能,这部分功能是可复用的。所以Spring 具备可复用性,如果程序员自己去完成这个操作,一来和业务强绑定 耦合性高,二来 这个过程极其复杂 容易出错。IOC 可以帮助你完成自定义的Bean的装配和依赖关系,但是一个系统不可能都被Spring管理,也有一些临时对象,比如xxO之类,一个订单数据等。
函数式编程
原型编程
编程本质
编码规范
-
编码规范的价值
- 降低代码出错的概率,复杂代码容易出现问题
- 提高编码效率 (1.CR)
- 降低软件维护成本,提高代码可读性
-
命名
-
为什么需要命名规范
- 为标识符提供附加的信息
- 使代码审核更有效率
- 提高代码的清晰度和可读性
- 避免不同产品之间的命名冲突
-
哪些地方命名
- 项目名、模块名、包名、对外暴露的接口名、类名、函数名、变量名、参数名
- 重点:见名知意
-
命名多长合适
- 准确达意、变量名可以缩写、函数名要能表达含义
-
利用上下文简化命名
-
命名可读、可搜索
- 简单可读、遵守团队规范
-
接口和抽象类命名
- IUserSerivce\UserSerivce
- UserService\UserServiceImpl
- AbstractConfiruration
-
XO命令
- 数据库 BO、PO
- 业务逻辑
-
-
注释
-
注释其实是有维护成本和阅读成本,代码和注释不一致
- 优化代码 优先 优化注释
-
注释到底该写什么
- 是什么功能、为什么这么做、如何做的
- 总结一些quick start的demo
-
注释是不是越多越好
- 类和函数 要写注意,其他靠命名、提炼函数 变量
-
-
code style
- 类、函数多大比较合适
- 建议:函数不要超过一个显示屏 50行左右
- 一行代码多长
- 不要超过显示屏的宽度 要不然不利于阅读
- 善于使用空行分割代码块
- 对于比较长的函数,或者独立代码块,比如一个函数基本的逻辑、校验数据、处理逻辑、拼接数据 就可以用空行进行分割
- 类的成员变量与函数之间
- 静态成员变量与普通成员变量
- 各函数之间
- 可以让界限更清晰
- 空格缩进、括号另起一行
- 看项目规范,看业界规范,开源项目规范
- 类成员的排列顺序
- 类所属的包名、import类
- 类
- 静态成员变量
- 成员变量
- 静态函数
- 成员函数
- 先public->protected->private
- 有调用关系的放在一块
- 类、函数多大比较合适
-
编程技巧
- 代码分割成更小的单元块
- 具体抽象和模块化思维,一看方法名 不看细节,就知道是干什么的,比如checkParams, parseData 等
- 将复杂的逻辑代码提炼成函数,提高代码的可读性
- 避免函数参数过多
- 函数是否可以拆分成更细粒度的子函数-单一职责
- 超过5个以上函数,可以封装成对象进行传输
- 提升可读性
- 不要用函数参数控制逻辑
- 采用单一职责和接口隔离原则进行。 拆分函数
- 参数为null。可以分拆多个函数
- 函数设计要职责单一
- 移除过深的浅套层次
- 不要超过2层
- 去除多余的 if else
- 使用continue \break return 提前退出
- 调整顺序来减少浅套
- 封装成函数
- 使用解释性变量
- 常量替代魔法数字
- 代码分割成更小的单元块
重构
- 是什么:在保持功能不变的前提下,利用设计思想、原则、模式、编码规范等理论来优化代码,修改设计上的不足,提升代码质量
- 为什么要重构:保证代码质量的有效手段、优秀的代码或架构是迭代出来的、避免过度设计的有效手段,提升代码能力
- 重构什么:大规模重构 系统、模块、代码结构、类与类之间的关系等,小规模重构,类 函数 变量代码级别的重构
- 什么时候重构:持续重构,意识更重要,提升代码质量,把关CR质量
- 大规模重构,油画家执行,分阶段小步快跑,小规模重构 随时做
- 品味很重要,代码的坏味道
- 初级工程师在添加功能,修修补补、修改BUG
- 高级工程师在设计代码结构,搭建代码框架
- 资深工程师为代码质量负责,发现代码中的问题,重构代码。时刻保证代码质量处于可控状态。
- 功能层面,设计层面,可靠性层面等角度出发考虑。
单元测试
- What:单元测试测试对象是类或者函数 是否按照预期方式运行,核心就是逻辑思维能力是否缜密
- 集成测试,端到端的流程测试 一个整体的流程,授信、借款流程等
- Why:
- 优缺点单元测试能有效帮你发现代码中的bug
- 写单元测试发现代码设计上的问题
- 单元测试是集成测试的有力补充,完善的单元测试可以补充集成测试
- 代码重构的过程
- 阅读单元测试 快速熟悉代码
- 单元测试是TDD可落地执行的改进方案
- 如何编写单元测试
- 利用现有的测试框架,Junit、TestNg、Spring Test等
- 覆盖各种输入、异常、边界情况。
- 单元测试不要依赖被测代码的具体实现逻辑
- 编写完功能、必须写单元测试类,不仅仅流程通,还要考虑边界条件。
代码的可测试性
- 代码的可测试性从侧面也反应代码设计是否合理,编写代码除了功能层面,也需要多考虑是否可测试
大重构
-
顶层代码设计的重构,系统、模块、代码结构、类与类之间的关系等
-
分层、模块化、解耦、抽象可服用组件
- 解耦合
- 软件设计与开发最重要的工作就是应对复杂性。
- 重构是保证代码质量不至于孵化到无可救药地步的有效手段,
- 解耦是保证代码不至于复杂到无法控制的有效手段
- 解耦合
小重构
- 类、函数、变量代码级别
单一职责原则-SRP
- 关于单一职责原则,其核心的思想是:一个类,只做一件事,并把这件事做好,其只有一个引起它变化的原因。单一职责原则可以看作是低耦合、高内聚在面向对象原则上的引申,将职责定义为引起变化的原因,以提高内聚性来减少引起变化的原因。职责过多,可能引起它变化的原因就越多,这将导致职责依赖,相互之间就产生影响,从而极大地损伤其内聚性和耦合度。单一职责,通常意味着单一的功能,因此不要为一个模块实现过多的功能点,以保证实体只有一个引起它变化的原因。
-
如何判断类、模块是否单一
- 结合具体的应用场景进行判断
-
实际生活:厕所、厨房 只负责一件事情。做饭
-
开闭原则-OCP
- OCP(Open/Closed Principle)- 开闭原则。关于开发封闭原则,其核心的思想是:模块是可扩展的,而不可修改的。也就是说,对扩展是开放的,而对修改是封闭的。对扩展开放,意味着有新的需求或变化时,可以对现有代码进行扩展,以适应新的情况。对修改封闭,意味着类一旦设计完成,就可以独立完成其工作,而不要对类进行任何修改
- 实现:接口、抽象、多态、设计模式等
- 可拓展&过度设计。 可拓展&可读性 权衡利弊
里氏替换原则-LSP
- 子类对象可以替换程序中父类对象出现的任何地方,并且保证原有程序逻辑的正确性不被破坏
- 多态的区别,多态是面向对象编程中一个特性,是用来在具体代码实现的思路,但是里氏替换原则是一种设计原则,是用来指导继承关系中子类该如何设计,保证子类可以替换父类。
- 子类必须能够替换成它们的基类。即子类应该可以替换任何基类能够出现的地方,并且经过替换以后,代码还能正常工作。另外,不应该在代码中出现 if/else 之类对子类类型进行判断的条件。里氏替换原则 LSP 是使代码符合开闭原则的一个重要保证。正是由于子类型的可替换性才使得父类型的模块在无需修改的情况下就可以扩展。
- 多态是面向过程的特性,一种语法机制,但是LSP是指导方针,用于针对继承模型中,子类如何实现父类中的方法,也就是按照协议设计,功能,输入输出参数,异常,以及可能违反的约定等
接口隔离原则-ISP
- 如果是外部系统依赖不需要的API功能,那么需要把不需要的功能拆分出来。 相反面向对象的接口、函数也都是这样的思想。
- 单一职责针对的是模块、类、接口的设计,接口隔离原则更注重于接口的设计,提供了判断接口是否是单一职责的标准。
- 接口实现类的方式
- UserDao -> UserDaoImpl
- IUserDao -> UserDao
- ApplicationContext
- ClassPathXmlApplicationContext
- FactoryBean
- SqlSessionFactoryBean
- PropertyEditor
- PropertyEditorSupport
- Aciton
- ActionSupport
依赖倒置原则-DIP
-
IOC 控制反转,控制是程序流程由原来的程序员控制,到框架控制整体流程,通过框架的预留点进行拓展实现业务需求。控制反转是一种设计思想,指导框架层面的控制。所以这就是学习Spring框架的时候,除了了解内部运行原理,还需要掌握相关的拓展点,这些拓展点在后续集成的相关框架,以及cloud中都有具体的展现。
对于开发来说,我们看一个类的时候,要先看是否有Override的方法,如果有,那么大概率都是上层父类 或者 接口类实现的。
-
依赖注入:其实就是不通过new的方式进行创建类。而是通过框架内部机制,直接使用。
-
依赖注入框架:Spring就负责将对象的创建、初始化、生命周期进行管理,我们只需要按照对应的配置就可以进行使用。
-
高层不依赖底层细节,高层和底层实现应该依赖于抽象,实现细节依赖于抽象。
- Tomcat和应用 互相依赖于servlet规范
Don’t Repeat Yourself (DRY) 原则
-
重复的含义
-
实现逻辑重复
-
功能语义重复
-
代码执行重复
-
-
代码复用性、代码复用
- 复用性是针对开发者来说,
- 代码复用是针对使用者来说
-
如何提高代码复用性
- 减少代码耦合
- 满足单一职责原则,细粒度代码,通用型比较好,容易被复用
- 模块化
- 业务和非业务隔离 AOP组件 注解等方式
- 封装继承多态
- 设计模式等应用 模版、策略、工厂等设计
Keep It Simple, Stupid (KISS)原则
-
代码的可读性和可维护性
-
不要使用同事不懂的技术
-
不要过度优化
-
不要重复造轮子
Program to an interface, not an implementation
You Ain’t Gonna Need It (YAGNI) 原则
- 不要过度设计
Law of Demeter,迪米特法则 (Law of Demeter)原则
- 最少知识原则
- 不该有直接依赖关系的类之间,不要有依赖
- 有依赖的关系的类,尽量只依赖必要的接口
- 问题:单一职责和迪米特法则关系
- 单一职责从类的自身功能出发,迪米特法则从类关系出发,接口隔离原则 从调用者出发
高内聚,低耦合
-
可以粒度的设计与开发,指导系统、模块、类、函数
-
系统设计时,微服务、框架、组件、类库等设计
-
高内聚:相近的功能放到同一个组件中,不想尽的功能拆分
-
低耦合:类之间的依赖关闭比较简单
- 具体手段
-
封装与抽象:隐藏实现的复杂性,隔离实现的易变性
- 案例:open函数 ,提供易用性,隐藏实现细节
-
引入中间层
-
模块化
-
单一职责、基于接口而非实现编程、依赖注入、多用组合少用继承、迪米特法则
-
- 具体手段
-
生活案例:座椅没有关系 方向盘和轮胎
-
案例:Spring AOP解耦业务和非业务的代码、IOC实现对对象的创建和使用的解耦
业务开发
- 面向对象设计聚集在代码层面 系统设计聚焦在架构层面 针对模块、系统设计 具备普适性,很多设计原则和思想不仅仅可以应用在代码设计中,还可以应用到架构设计中
通用功能开发
- 功能性需求
- 非功能性需求
- 易用性、性能、拓展性、容错性、通用型、小步快跑、逐步迭代
分层开发
- 代码复用、隔离变化、隔离关注点、代码的可测试性、应对系统的复杂性
- 应对需求的复杂度,寻找稳定的不变的东西是系统的核心, 变化的才是需要进行拓展的点
每个设计模式都是特定问题的解决方案,关键在于解决的问题,以及应用场景
单例模式
- 目的:一个类只有一个实例,系统的配置信息类、资源访问冲突的问题
- 实现方式
- 饿汉式、懒汉式、双重检查、静态内部类、枚举
工厂模式
建造者模式
- 目的:封装必要的初始化信息,不通过构造方式进行初始化。
原型模式
代理模式
- 目的
- 不改变原始类接口的条件下,生成代理类,控制访问。
- 静态代理
- 本质是通过代理类持有被代理对象,但是对于实际编程来说的话,不同的类有重复的代码,所以就需要动态生成代理类
- 动态代理
- JDK
- Cglib
- 应用场景
- spring aop代理
- 业务系统的非功能性需求开发
- 监控、统计、鉴权、限流、事务、幂等、日志
- 将附加功能与业务功能解耦合,单一职责
- 代理模式在RPC、缓冲的应用
桥接模式
- 目的
- 接口和实现部分分离,可以独立改变
- 代理针对的是一个类与一个类的处理,桥接模式针对的是一组类与一组类的组合。
- 使用场景
- 不同手机壳和不同的手机 组合 主要解决的是继承爆炸的问题。
装饰者模式
- 目的
- 不改变原始累接口情况,对原始功能增强,比如女人穿衣服。
- 解决的是继承关系过于复杂的问题,通过组合的方式来代替继承,主要是给原始类添加增加功能
- 应用场景
- spring bean的包装 任务的包装、IO类的包装
适配器模式
- 原理,将不兼容的接口转换成兼容的接口,补救设计上的缺陷。
- 实现方式:类适配器和对象适配器
- 类适配器:继承关系
- 对象适配器:组合关系
- 使用哪种方式
- 看接口和目标接口定义相同的多 用类方式 否则就是对象方式
- 目的
- 事后补救策略,适配器提供和原始类不同的接口,代理和装饰者提供和原始类相同的接口
- 应用场景
- 封装有缺陷的接口设计
- 统一多个类接口的设计
- 兼容老版本接口
- 适配不同格式的数据
- 实际应用
- spring mvc中 adapter 实现controller接口、实现HttprequestHadnler、以及实现controller注解的方式 通过不同的适配器调用handlerRequest方法
门面模式
- 目的:解决多接口整合封装的问题,主要是API的集成,比如用户注册接口、短信发送接口。
- 解决问题
- 易用性、性能问题、分布式事务问题
组合模式
享元模式
- 目的:复用对象,节省内存,对象不可变
- 应用:Integer, Long 的缓存区
- 和单例的区别
- 单例是一个类只创建一个对象,享元模式是一个类可以创建多个对象,每个对象被多处代码引用共享。前者是限制对象的个数,后者是达到对象复用,节省内存
观察者模式
- 多个对象依赖于一个对象的动作,就需要使用观察者模式。
- 多个观察者注入到被观察者,被观察者执行动作,然后调用观察者执行。
- 比如:用户注册成功之后,发送WA 或者 邮件通知
- Spring refresh() 事件-多播器->监听器的实现
- google guava event实现
- 原理其实就是一个register 创建一个事件对应的类+方法的集合,然后post的时候 根据不同的事件 反射执行对应的类+方法
模板模式
-
模板模式的本质定义一个框架流程,具体的拓展点可以子类进行实现。具体的功能是复用和拓展,复用是指的是,所有的子类可以复用父类中提供的模板方法的代码,拓展是框架通过模板模式提供功能拓展点,用户不修改框架源码的情况下,基于拓展点就可以实现功能。
-
回调方式
- A调用B ,同时把自己注册给B B调用f调用A自己
- 回调支付,Spring getObject->createBean 三级缓冲的工厂方法
- 区别:模版模式是通过继承实现的,回调是通过组合方式实现的。
-
应用场景
- 拓展:jdbcTemplate、servlet、junit
- 复用:abstractList、io流
策略模式
- 定义、创建、使用
- 解决的问题:解决if、else
- 利用查表法,或者存储Class对象,利用反射调用方法。
- 设计原则和思想其实比设计模式更加普适和重要,掌握了代码的设计原则和思想,比设计模式更重要
- 设计原则和思想是高层次的理论和指导原则,设计模式是根据经验总结出来的编程范式
- 要看场景 如果简单的if esle 逻辑 避免过度设计
- 应用场景
- 文件排序 进行策略化
- spring aop proxy的选择
职责链模式
-
解决的是一个流程问题,通过不同的过滤器进行处理.
-
实现方式
- 基于数组、链表不同的方式
- 构建链表-> 反射方式构建等
-
应用场景
- servlet filter ,spring interceptor
迭代器模式
状态模式
访问模式
备忘录模式
命令模式
解释器模式
中介模式
对比大杂烩
- 适配器VS门面模式
- 适配器模式注重的是兼容性,而门面模式注重的是易用性
- 装饰者VS代理模式
- 从UML的角度看两者是相同的
- 区别:代理是增强的是额外功能的增强,装饰器是本职功能的增强
- eg:注册方法发送邮件,注册方法 添加
封装和抽象
分层和模块化
基于接口通信
高内聚、松耦合
为拓展设计
Kiss首要原则
最小惊奇原则
吹毛求疵执行编码规范
编写高质量的单元测试
不流于形式的CR
开发未动、文档先行
持续重构、
项目和团队拆分
- 互相学习
- 摈弃英雄主义
- 提高代码可读性
- 技术穿帮带
- 团队人员都熟悉
- 打造良好技术氛围
- 技术沟通方式
- 团队自律性
类库:提供一组api,比如junit、guava
框架:提供骨架代码,业务人员在拓展点填充预留业务,DI容器
功能组件:ID生成器、性能计数器
业务无关+复用场景 抽取出来。 业务无关+无复用场景
- 易用性、继承、文档全面、容易上手。性能好,bug少等
如何发现代码质量问题-常规checklist
- 目录设置是否合理、模块规划是否清晰、代码结构是否满足高内聚、低耦合
- 是否遵循经典的设计原则和设计思想(SOLID、DRY、KISS、YANGI、LOD等)
- 设计模式是否应用得当,是否有过度设计
- 代码是否容易拓展、如果添加新功能,是否容易实现
- 代码是否容易服用、是否可以服用已有项目代码或类库,是否有重复造轮子
- 代码是否容易测试、单元测试是否全面覆盖各种正常和异常的情况
- 代码是否易读,是否符合编码规范,比如命名和主食是否恰当,代码风格是否统一
如何发现代码质量-业务需求checklist
- 代码是否实现预期的业务需求
- 逻辑是否正常,是否处理了各种异常情况
- 日志打印是否得当、是否方便debug排查问题
- 接口是否易用、是否支持幂等、事务等
- 代码是否存在并发问题、是否线程安全
- 性能是否有优化空间、比如SQL 算法是否可以优化等
- 是否有安全漏洞,比如输入输出检验是否全面
过度设计&设计不足的权衡
- 软件设计的目的是解决复杂问题,设计思想是心法,设计模式是招式,解决问题才是根本。
- 目的是提高代码质量。
- 结合具体的业务设计,不要脱离具体的场景去谈设计。
- 持续重构可以避免过度设计和设计不足
- 掌握基本理论 理论实践结合 代码质量意识很重要
- 识别最核心需求、以及不要想一步到位
- 设计方案的简单性
为什么学习源码
- 大厂面试问
- 提升阅读代码的功能、输出优质的代码、学习软件设计思想
- 提升技术功底
- 二次开发
- 快速定位线上问题
- 拥抱开源社区
前置基础知识
- 设计模式、数据结构算法、反射、多线程、网络编程
源码学习方式
- 会使用、全局观、不要关注细节、看注释(类、方法、接口)、见名知意、大胆猜测、小心验证、画图、学习路径、坚持
- 推荐路径 集合、并发、spring、mvc、mybatis、boot、Alibaba、bio->netty->kafka
- 性能优化、框架源码、中间件源码、架构设计、云原生、大数据
集合
-
ArrsyList
-
LinkedList
-
hashmap ✅
-
concurrenthashmap
-
CopyOnWriteArrayList
-
LinkedHashMap
线程池 ❌
- ExecutorService ✅
- AbstractExecutorService ✅
- Executors ✅
- ScheduledThreadPoolExecutor
- 阻塞队列
- ArrayBlockingQueue. ✅
- LinkedBlockingQueue. ✅
- PriorityBlockingQueue
- DelayQueue
- LinkedTransferQueue
- SynchronousQueue
AQS
- Synchroneized. ✅
- ReentrantLock. ✅
- ReentrantReadWriteLock
- Condition
- CountDownLatch
- CyclicBarrier
- Semaphore
- ThreadLocal
异步编程
- CompletableFuture
Spring ⭐️ 深入理解
-
IOC容器
-
刷新十三个步骤
-
bean生命周期
- 三级缓存
-
事务
-
AOP
- 静态代理、动态代理
- Cglib 和 JDK代理
- 静态代理、动态代理
-
拓展点
- FactoryBean
- initPropertySources
- customizeBeanFactory
- 自定义标签
- BFPP/BPP
- Before/after
-
常用注解
Spring mvc
- 启动流程,tomcat \ spring \mvc
- 请求处理流程 dispatcher 转发流程
mybaits
- 解析SQL,反射执行目标方法
tomcat
- 启动流程
- 线程模型
- 打破双亲委派模型
boot
- 自动装配
- 初始化过程
- 如何和tomcat集成
cloud
- nacos
- fegin
io
nio
netty
Dubbo:⭐️ 深入理解
Kafka: ⭐️ 深入理解
rocketMq
elk
ZK
automq
Google guava
- 造轮子
https://gitee.com/noear/folkmq
https://github.com/houbb/cache
https://github.com/CN-GuoZiyang/MYDB
https://github.com/wangjs96/A-tutorial-compiler-written-in-Java
架构设计三原则、简单、合适、演化。面向复杂度设计




演进
- 业务上演变->微服务(演进) 【进程内->进程间交互】
- a.链路过长、问题所在的定位
- b.机器问题 服务调用
- c.粒度问题 如何切 抉择
- 难点
- 分布式锁、事务
- 开发以来下游,开发、测试沟通
- 运维挑战、容器云
- 性能问题 调度链路长 网络IO等
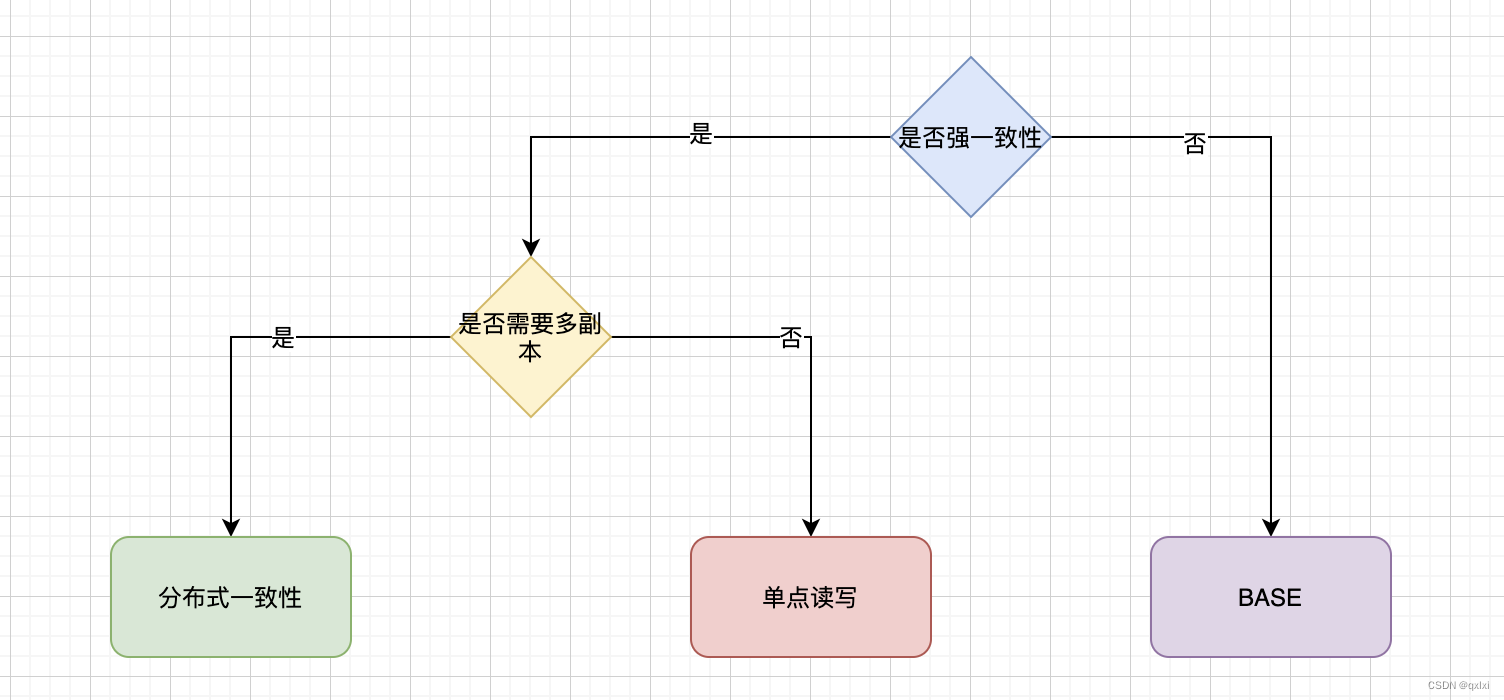
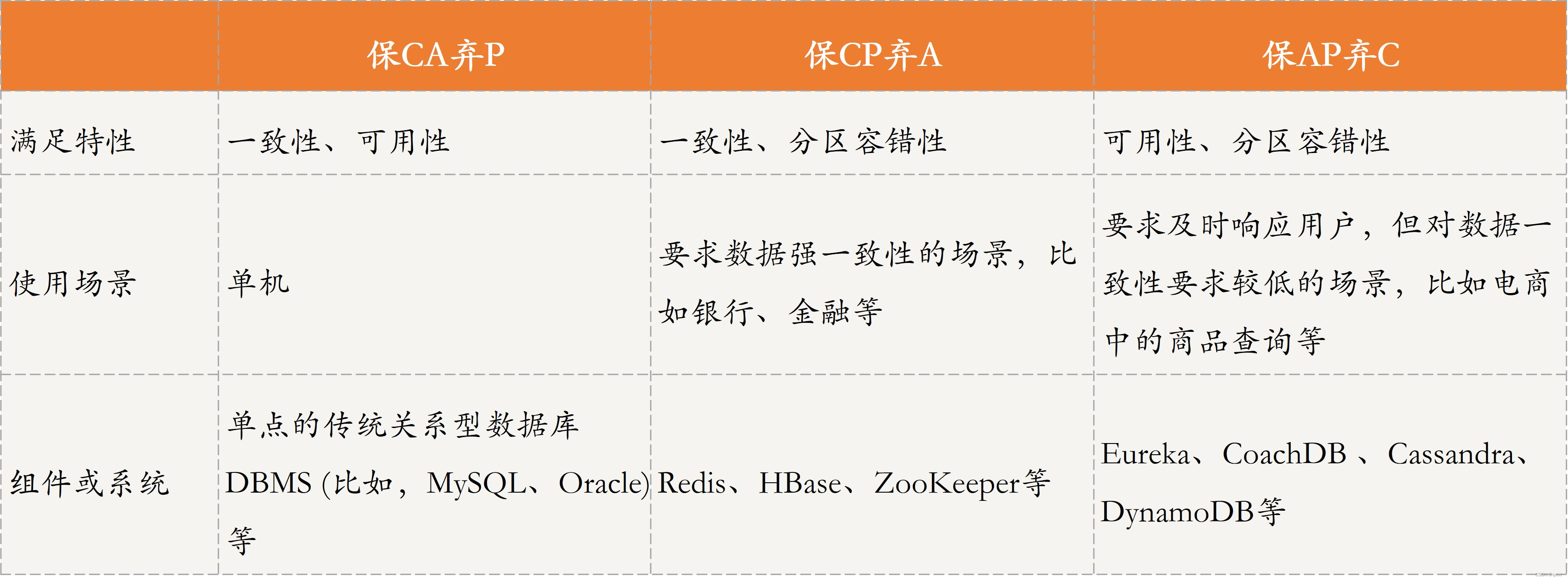
BASE
- Basic Availability:基本可用。这意味着,系统可以出现暂时不可用的状态,而后面会快速恢复。
- **Soft-state:**软状态。它是我们前面的“有状态”和“无状态”的服务的一种中间状态。也就是说,为了提高性能,我们可以让服务暂时保存一些状态或数据,这些状态和数据不是强一致性的。
- **Eventual Consistency:**最终一致性,系统在一个短暂的时间段内是不一致的,但最终整个系统看到的数据是一致的。
CAP
- 一致性 (Consistency) 强调的是各节点间的数据一致
- 可用性 (Availability)
- 分区容错性 (Partition Tolerance) 强调的是集群对分区故障的容错能力
ACID
ACID的目的其实是为了保证数据的一致性,但是这种一致性是强一致性,在单机系统下可以很好的实现,但是放在分布式系统中,我们很难去权衡系统之间可用和数据的强一致性。而[分布式事务]需要通过二阶段提交协议和TCC(Try-Confirm-Cancel)实现。
- 原子性(Atomicity):整个事务操作过程中,要么是整体成功的,要么是整体失败的,不可能出现一半成功一半失败。如果出现异常的话,那么需要进行回滚到最原始的状态。举一个例子来说,比如我们在一个大事物中同时操作了订单和支付的表,那么当出现异常的情况,比如说三方异常或者是内部系统错误,事务会进行回滚到原始的状态。
- 一致性(Consistency): 在事务执行的前后,数据的完整性约束没有破坏。
- 隔离性(Isolation): 两个事务之间不会互相干扰,即一个事务A不会看到另一个事务B的中间数据。
- 持久性(Durability): 当事务完成之后,数据会被持久化到磁盘中,并且出现机器宕机等可以进行数据的恢复
我们知道在分布式系统中不同的业务其实并不需要完全的数据一致性,大对数场景中,我们必须保证的是核心链路的稳定性、可用性,所以BASE其实就是CAP的一个变种。倾向于设计出一个更富有弹性能力的系统。 在分布式系统中故障是不可避免的,当出现分区或者故障的时候,我们应该在设计层面多去考虑可能出现的问题,把故障处理当成功能写入代码中,即Design for Failure。新手与老手的差别就是新手可能会完整基本功能就可以了,但是老手会考虑很多边界问题,不和合法性以及可能出现的各种异常问题。 举一个例子:比如买书,ACID的玩法是将库存锁住,不可能同时多个用户购买,而BASE的玩法是异步处理,可以支持用户抢购。 ACID是酸、BASE是碱,从本质上来说ACID的C强调的是一致性(CAP中C),而BASE强调的是可用性(CAP中A) 关注点也不一样:ACID关注的是数据的完整性,而CAP的C关注的是分布式节点的数据一致性。
FLP
-
很多人知道CAP、ACID、BASE 但是却不了解FLP,这里为了文章的完整性,介绍一下
FLP是分布式领域中非常著名的定理,在异步通讯场景中,即使只有一个进程失败,也没有任何算法能保证非失败进程达到一致性。
限定条件
-
确定性协议:给定一个输入,一定会产生相同的输出。
-
异步网络通讯:同步通信:同时在线,允许超时,异步通信,没有统一时钟,不能时间同步,不能使用超时,消息可任意延时,乱序。
-
所有存活节点:所有存活的节点必须最终到达一致性。
ACID 是数据库事务完整性的理论,CAP 是分布式系统设计理论,BASE 是 CAP 理论中 AP 方案的延伸
两将军
-
两将军问题,主要描述的是有两个军队A和B,分别驻扎在山谷的两侧,同时进攻城市。但是两个军队进攻时间是不确定的,也就是两边军队的Leader没有对发起进攻的时间形成一致。如果任意一方发起,另一方不发起进攻,那么就会失败。想要达成共识的办法就是通过发送信使的通知对方,但是中间的山谷被敌军占领。
假设军队Aleader指派了一名通讯兵去通知军队B 明天8点发起进攻,但是很可能这个通讯兵在中途被敌军擒获。如果没有擒获的话,军队Bleader为保证自己收到消息,需要给军队A发送消息,我已经收到了明天8点一起发起总攻。但是这个通讯兵在路上也可能被擒获。即使两边一次不停的发送也没有办法保证消息自己的通讯兵没有被擒获。所以这个问题是无解的。
说白了,在两将军问题中,信道是不可靠的,但是如果从工程角度解决的话,并不会去尝试解决信道不可靠问题,而是将这个不可靠降低到一个可接受的程度,三次握手机制其实是没有办法保证网络连接的可靠性,只是说在基于网络连接可靠的情况下,通过客户端和服务端的请求-相应-确认机制去确保连接建立成功。
拜占庭将军
- 拜占庭问题其实描述的是在拜占庭,周边有多个军队,想要一起进攻,必须每个军队就进攻/不进攻达成一致,但是再次基础上,军队中存在敌军间谍,会扰乱左右决策的过程,从而导致最终结果不一致。说白了拜占庭问题就是,在已知有敌军间谍的情况下,在忠勇将军的不受判读的影响下如何达成一致的协议。 拜占庭将军问题是两将军问题的升级版本,除了存在故障行为,还可能存在恶意行为。所以一般使用的话在数字货币的区块链技术中需要使用拜占庭容错算法。BFT。
一致性与共识
- 分布式共识就是在多个节点均可独自操作或记录的情况下,使得所有节点针对某个状态达成一致的过程。通过共识机制,我们可以使得[分布式系统]中的多个节点的数据达成一致。
- 一致性强调的是结果,共识强调的是达成一致的过程
Paxos
Raft
ZAB
Gossip
分布式ID
分片
- 分片或者分区的本质是为了解决单机存储和性能瓶颈带来的问题,让分布式系统的计算和存储能力可以线性扩展。而数据复制解决的是数据的高可用
- 水平分片/ 垂直分片 / 混合分片
- 算法:范围分片、哈希分片、一致性哈希分片、基于虚拟节点的一致性哈希算法
复制
- 为保证高可用,数据复制就会涉及到数据之间的拷贝,也就是数据一致性问题
- 单主复制(同步、异步、半异步复制)
- 多主复制
- 无主复制
事务
CP+ACID=》刚性事务 适用于数据层
AP+BASE=> 柔性食物 适用于业务层
-
XA
-
2PC :准备、提交
-
3PC:准备、预提交、提交
-
-
业务补偿
- TCC
- sega
-
最终一致性
- 消息表
- 消息队列
- 最大努力通知
分布式锁
-
具备特点
- 独占性:任何时刻都只能有一个线程持有。
- 高可用:如果是单机点Redis有单点宕机的可能,造成锁无法释放和获取。为保证高可用,一般需要集群模式
- 防止死锁:如果出现锁无法释放的情况下,那么需要有超时控制机制,进行兜底方案
- 不乱入:A锁进行释放不能释放成B锁,B锁释放不能释放成A锁
- 重入性:同一个节点的同一个线程获取后,再次读写共享资源不需要再次获取锁。
-
Redis
-
差评,setnx+expire不安全,两条命令非原子性的
-
死锁(单节点)、锁过期问题、原子性
-
Redlock
-
解决写入key 之后,同步到从节点 之前matser宕机
-
如何保证的
-
客户端只有在满足下面的这两个条件时,才能认为是加锁成功。
条件1:客户端从超过半数(大于等于N/2+1)的Redis实例上成功获取到了锁;
条件2:客户端获取锁的总耗时没有超过锁的有效时间。
-
-
-
-
ZK
-
MySQL
数据存储和检索
- B+树 :读多写少
- LSM :写多读少
- 倒排索引&PageRank :数据搜索

-
缓存
从客户端、CDN、网关、服务端、内存、数据库、文件系统、磁盘和CPU 都可以通过加缓存,来提高访问的速度。
-
负载均衡
水平拓展的技术,通过将用户请求分发到不同的机器上来承担一部分用户流量
-
异步调用
主要通过消息队列来实现,将前段的请求的峰值给肖平,后端按照自己的速度进行处理请求,增加系统的吞吐量,但是实时性就比较差。但是消息队列带来了消息丢失,重复消费,消息挤压等问题。
-
数据分区/镜像
数据分区是通过将数据按照某种维度进行划分,比如地理上,请求最近的数据,但是join和跨库的事务操作复杂度比较高。而数据镜像则是通过将数据拷贝一份,然后任意节点上都可以读写,内部自行同步数据,最大问题就是数据一致性问题。
缓存是提高读的性能,而异步调用是提高写的性能,负载均衡技术主要是通过服务冗余将流量进行分担,在分布式架构中,数据存储是一个重中之重,而一般要么就是使用镜像/复制技术,将数据进行拷贝,读写分离,另一种就是将数据分成多片,每片存储在不同服务器上,这样可以横行提高数据读写能力

-
服务拆分
服务拆分的目的主要是两个,一是隔离故障,二是提高重用性。但是拆分后会引来服务之间依赖通信问题
-
服务冗余
去除单点故障,支持服务的弹性伸缩,以及故障迁移。具体形式可能是主备、主从。
-
限流降级
当系统是在扛不住压力的时候,需要通过限流或者降级的方式来保证核心业务的正常运转,属于技术保护的措施。
接口级别:限流、降级、排队、熔断、超时重试&幂等
-
高可用架构
通常来说高可用架构是从冗余架构的角度来保证可用性,多租户隔离,容灾备份(异地多活/同城多机房、跨城多机房、跨国多机房),或者数据可以在复制保持一致性的集群。
异地多活:同城多机房、跨城多机房、跨国数据中心
基本都是路数都是单机->主从->同城灾备->同城双活
http://kaito-kidd.com/2021/10/15/what-is-the-multi-site-high-availability-design/
冷备:不提供实时服务 热备:提供实时服务
存储高可用:复制(主从、主备、主主)
计算高可用:负载均衡、任务分配、任务分解
-
高可用运维
DevOps中的CI/CD(持续集成、持续部署)一个流程的软件发布流程,足够的自动化测试,相应的灰度发布,线上系统的自动化控制。
- 计数器方式
- 队列算法
- 漏斗算法
- 令牌桶算法
- 基于响应时间的动态限流

-
服务治理
服务拆分、服务调用、服务发现、服务依赖。关键在于对服务调用链路,依赖关系给梳理出来,并对这些服务进行性能和可用性方面的管理
-
软件架构管理
服务之间有依赖关系,有兼容性问题,所以整体服务所形成的架构需要有架构版本管理,整体架构的生命周期管理,以及对服务的编排,聚合,事务处理等服务调度功能
-
DevOps
分布式服务可以快读的部署,但是对测试和运维是一个挑战,包括环境构建、持续集成、持续部署等
-
自动化运维
对服务进行自动伸缩、故障迁移、配置管理、状态管理等一系列自动化运维技术了
-
资源调度管理
应用层的 计算 网络 存储
-
整体架构监控
监控是眼睛,需要对 应用层、中间件层、基础层进行监控
-
流量控制
负载均衡、服务路由、熔断、限流、降级都和流量相关的调度,以及灰度发布等。
分布式五个关键技术
- 全栈系统监控
- 服务、资源调度
- 流量调度
- 状态、数据调度
- 开发和运维的自动化
分层
SOA
微服务
微内核
- 客户端-服务端 数据流走向 web->dns->nginx->tomcat->三方进程->DB
性能指标
- TPS、QPS、吞吐量
架构设计
- 缓存、异步、集群、分片、复制
- 网络层面
- 服务器硬件层面
- 操作系统层面
- JVM性能优化
- 基础组件优化(MySQL、Kafka、Redis)
- 软件架构层面优化
- 软件代码优化
如何优化
- 三要三不要
- 三要
- 查询系统最大性能瓶颈
- 确诊问题根本原因
- 考虑多种情况
- 三不要
- 过度反常优化
- 过早不成熟优化
- 表面的肤浅优化
- 三要
- 十大策略
- 时空转换
- 空间换时间
- 时间换空间
- 并行/异步
- 并行操作
- 异步操作
- 预先/延后处理
- 预先/提前处理
- 延后/惰性处理
- 缓存/批量合并
- 缓存数据和结果
- 合并和批处理
- 算法设计和数据结构
- 更快的算法设计
- 更优化的数据结构
- 时空转换
- 池化技术
- 数据库连接池
- Redis连接池
- 网络连接池
- 对象池
- 微信红包设计
-
AOP 场景
- 接口耗时统计 ✅
- 接口耗时 统计多个接口 ✅
- SQL耗时统计 ✅
- API 鉴权
- Error日志监控报警 ✅
- 接口幂等框架 ✅
- 接口耗时统计 ✅
-
自定义注解
- AOP 加解密 ✅
-
spring retry 重试 ✅
ID生成器
限流框架
灰度发布组件
软件生命周期
CI/CD
Jenkins
构建、测试、部署、维护
基本组件
-
镜像
-
容器
-
ds
-
为什么隔离
- 系统安全、资源隔离
-
虚拟机的区别
用虚拟机实现与宿主机的强隔离,然后在虚拟机里使用Docker容器来快速运行应用程序。
-
实现方式 优势 劣势 虚拟机 虚拟化硬件 隔离程度非常高 资源消耗大,启动慢 容器 直接利用下层的硬件和操作系统 资源利用率高,运行速度快 隔离程度低 隔离实现原理
- namespace、cgroup、chroot
-
-
-
仓库
常用命令
- docker version //查看命令
- docker run hello-world //运行hello world
- systemctl stop docker //停止
- systemctl start docker //启动
- systemctl restart docker //重启
容器数据卷
docker file
- 构建镜像的文本文件
- 步骤:编写-> 构建 -> run
compose
container
network
image
volume
swarm
为什么需要k8s
- 解决容器运行时的管理和编排工作, 创建、调度容器,监控,管理服务
容器编排
- 生产级别的容器编排平台和集群管理系统
部署基本概念(控制和数据面 分离。有点像 计算和数据分离的感觉)
- kubectl 客户端
- Master node
- Api server 核心管理组件以及外部通信
- Etcd 存储资源对象和状态配置
- scheduler 负责容器的编排工作,检查节点资源状态
- controller manager 维护容器和节点资源状态,故障检测、服务迁移、应用伸缩等
- Worker node
- kubelet Node的代理
- docker 容器镜像的使用者
- Kube proxy 网络通信
基础概念
- 集群
- pod
容器运行时接口CRI
容器网络接口CNI
容器存储接口CSI
实时计算 离线计算
技术的本质:技术是为了解决问题,技术解决问题的一种手段。
三角:技术->业务->产品
技术团队管理的本质
- 带好团队
- 做好事
- 团队文化
管理思维|技术思维
- 系统性思维、利他思维、用户思维、trade-off思维
技术管理的能力构成
- 自我管理、商业思维、向上管理、产品思维、同级别管理、跨部门协作、数据思维、业务洞察力、技术敏感和架构决策、项目管理、
闭环思维:事情有开始有结尾。
- Plan->Do->Check->Act
- 核心点
- 有沟通有反馈、建立自我正反馈机制、螺旋上升、常见的闭环
- Why:为什么做这个需求?
终局思维
- 从终点出发 开始倒退 历史或者宏观层面
- 想成为架构师 ,看看架构师需要什么技能 去补齐短板
本质思维
- 溯源、回归原点、回到常识
1.做事认知
- 做事是第一重要的事
- 做事在很多公司被定义做项目或者产品迭代
- 做事流程分为:事前、事中、事后
- 事前
- 我们要做哪些事?哪件先做?优先级?
- 事中
- 如何保证事按照我们计划顺利执行
- 事后
- 复盘抽象出机制以便在相同场景中应用
- 事前
2.如何正确做事
- 事情优先级
- 计划外的事情
- 生产故障 优先级最高
- 需求类,排期
- 收益 vs 损失
- 回归目标本质、沟通
- 延期、知会、不要给leader 惊喜、产品侧同步
3.执行到位
- 目标明确:基于smart原则,是否传达团队所有人员,变更同步。
- 职责清晰:owner 研发 产品 等
- 健全的机制
- 团队人员达成共识和重要节点变更通报
4.流程机制
- 设置关键检查点
- 接口设计涵盖功能性和非功能性
- 接口设计review
- 上线前检查 CR
技术团队交付目标
- 项目快速迭代、持续交付
项目管理流程分类
- 迭代开发、大项目开发
CR
- 代码结构合理性、公公模块抽象复用
- 逻辑思维严谨、完整、足够的拓展性
- 接口设计、边界值、数据量、异常是否合理
- 可读性 注释
- 业务领域知识
技术判断力
- 通过技术领域和非技术领域的长期积累培养出来的技术决策能力
- 对方向的判断
- 对技术方案本身的判断
- 灾备、异地多活
- 饿了么 商户域、物流域、用户域
- 对各种风险的判断
- 技术、团队、政策
如何提升技术判断力
- 工作日常技术和产品工作汇报
- 参与技术方案评审、事故复盘
- 主持和主导顶层设计和规划实施工作
- 持续学习技术
技术债务
- 为了提升开发速度,没有采用最佳方案
定义:有限资源的情况下,通过有效协调或者合理分配资源 完整一定任务
为什么要学习
- 单兵作战到带领团队作战
项目管理的十大认知
- 进度
- 质量
- 核心链路
- 成本
- 人力成本、服务器成本
- 范围
- 风险
- 延期风险、需求合理性
- 沟通
- 信息同步丢失,目标一致
- 采购
- 决策引擎系统的采购 外部系统 三方系统等
- 资源
- 内部资源
- 干系人
- owner
五大过程
- 启动->规划->执行->监控->复盘
- 上线之后 要进行复盘,总结做事方式,问题,不断改进
六大必备技能
-
1.识别干系人
- 目的:寻找支持
- 方法:权利、利益,项目发起人,测试、运维同学等
-
2.避免延期降低交付风险的三个方法
- 识别依赖
- 内部依赖,同组内、其他团队,readly
- 外部依赖、三方系统对接等
- 提前、事前、事中、事后
- 所有事情能提前的都提前做,避免可能出现的异常、阻塞情况
- 找到关键路径
- 有备用方案
- 识别依赖
-
3.如何正确面对需求变更
- 达成共识,变更有代价
- 开发、产品、业务
- 找到变更的源头
- 是否需求不清晰 双方理解不一致导致的
- 通过数据反馈来见少或者控制变更
- 看价值和影响
- 不做有什么影响,缺少价值
- 达成共识,变更有代价
-
4.如何保证正确执行
- 各种方案评审
- Bug 大扫除
- 冒烟测试用例评审
-
5.如何做好项目汇报
- 紧急汇报:事件描述-》影响结果->跟进分享-〉相应措施-》需要的支持
-
6.复盘
- 不要搞成批斗会,暴露团队中的问题
- 持续改进,不断精进
认知升级是不断升级思维模型
- 第一性原理
7人左右小组
- 角色转变:代表自己到代表团队,团队的绩效就是你的绩效,团队的BUG就是你的责任
- 团队管理方式:手把手,亲力亲为
- 团队组织形式:按照方向划分成多个小组(小组长+组员)
- 基础架构组、服务治理组、存储组、基础服务组
- Leader 核心抓手:能帮员工切实解决问题,切记那种只说不做的。
- 问题:团队成员之间不友好
7-50人技术团队
- 角色转变:从手把手、亲力亲为到教练
- 团队管理方式:二级团队、每个团队一个负责任、管理好团队负责人、做好文件传承
- 团队组织形式:按照方向划分成多个部分(部门负责人+部门成员)
- 不同组,前端组、后端组等
- Leader核心抓手:提升部门负责人认知,管理好部门负责人、建立信任关系
50~100人技术团队
- 角色转变:从教练到大方向领导者 VP
- 团队管理方式:三级团队,做好团队领导者,领导好二级部门负责人
- 团队组织形式,二级部门
- 技术中心-业务技术部、技术中心-中台技术部,
- Leader核心抓手,懂哲学、招聘合适人才
一句话就是 展示数据 然后给结论
1.什么是数据敏感度
数据敏感度是业务理解力、客户理解力、数据理解力三者的综合结果
2.培养数据敏感度
拒绝拍脑袋 地基:逻辑思维和推理能力
在项目中沉淀公式,并且即使同一指标,也可能不同的公式。
3.数据分析基础
平均值、数据分布等
4.数据分析目标
通过数据监控,可以很好的反应出业务或者产品状态好坏,尤其上线后 可能带来的影响
5.构建科学的指标体系
明确业务终极目标->业务目标拆分->
查看数据的方法
1.公式法 提现率 = 提现通过人/提现发起的人
2.流程熟悉。 用户注册->进件->授信->提现-还款
3.生态法。 获客
通过数据做决策
1.利用上述方法,建立指标,通过数据指标找问题
2.对产生的原因做假设, 比如是否时间点有上线
3.ab测试 用户分层
-
学习方法
- 学习不应该只是学容易的环节,学习->记忆->应用->输出
- 检测获得了什么、总结规律、避免道德许可
- 学什么?
- 看技术和自己工作的相关度 基础、工作相关的,未来用到的技术。
- 找时间:海绵学习法
- 早上30分钟
- 到公司30分钟
- 通勤1小时
- 睡前30分钟
- 周末 8小时
- 技术深度:链式学习法
- 技术宽度:对比学习法
- 技术广度:环式学习法
- 保证效果:Play 学习法、Teach 学习法
-
学习能力
- 积累、智商、性格
-
学习心态
-
学习本质
- 锻炼能力、提高认知、选择赛道
-
终身学习
- 扎根、
-
内功修炼
- Why
- What
- 
-
编程能力
- 什么是编程能力:
- 熟练使用编程语言、开发类库等工具,思路清晰,面对复杂的逻辑,迅速实现,bug free的代码,利用数据结构与算法写出高效代码,以及灵活使用设计思想,原则和模式,遵从编码规范,易读、易拓展、易维护、易服用的高质量代码
- 什么是编程能力:
-
架构能力
- 当业务或者PM定义清楚需求后,可以分析出技术实现难度、预估性能需求,可能的拓展点,然后利用现有的技术,工具等迁到好处的实现满足业务需求的系统
- 系统层面、子系统设计、模块设计
- 深度和广度的积累
-
攻坚能力
- 从程序员的职业生涯来讲,成长来自解决足够复杂的事情,这需要你有足够高的学习和工作效率,决不能将工作产出绑死在工作时间上
-
业务能力
- 为什么需要了解懂业务
- 更好的理解需求,基于业务可以很好的理解
- 更好的设计方案,结合业务设计方案。
- 团队规划
- 如何提升业务能力
- P5-P6要求是范围是业务功能
- 5W1H8C1D
- 5W
- When(时间)、where(地点)、who(用户)、what、why(遇到什么问题)
- 1H
- How 业务需求的处理逻辑 一个具体的业务流程,比如进件->授信->借款->还款等
- 8C
- 5W1C 关注的是功能属性,8C关注的是质量属性
- 性能、成本、时间、技术、可靠性、安全性、合规性、兼容性
- 1D
- Data。上线后的数据观察
- 业务效果,DAU、MAU、活动参与人数、订单数、成交量等
- 系统效果,TPS、接口性能、响应时间、崩溃率
- 5W
- 5W1H8C1D
- P7-P8要求的范围是业务领域
- AARRR-漏斗模型 以用户为中心,了解用户生命周期为指导思想
- P8-P9 业务战略
- 宝洁战略模型
- P5-P6要求是范围是业务功能
- 为什么需要了解懂业务
-
成事能力
-
至暗时刻
-
技术成长
-
P5
-
P6
- 独立负责端到端的任务
- 技术:掌握团队用到的技术套路,提升技术深度 深入理解背后的技术原理和细节,技术深度
- 重点学习跟当前工作内容强相关的技术点和技术套路,避免贪多求全。深入1,2个
-
P7
-
P8
-
P9
-
-
沟通能力
-
做事原则
- 工作优先级
- 稳定输出,不会随便带出惊吓。
- 事前
- OKR规划法-执行整体规划
- 在于主动思考
- OKR规划法-执行整体规划
- 事中
- 如何设计方案:3C方案设计法-选择实现方案
- 好处:帮助系统梳理一个领域、对每个方案理解得更全面,发现最初的方案和决策标准的问题,提升整体流程和整个团队的工作效率
- 做事的时候至少设计3个方案,选择一个最优的方案执行。大多数人只是提出问题,没有自带方案、或者只有一个方案。
- 准备阶段:避免思维险隘,多个备选方案
- 讨论阶段:和其他人讨论 完善方案
- 决策阶段:
- 如何执行:PDCA执行法-落实具体任务
- Plan-计划
- Do-执行
- Check-检查
- Act-行动
- 如何找到问题源头:5W根因分析法
- 业务分析、技术学习,通过5个连续问题找到问题根本
- 如何应对问题:5S问题处理法
- 明确问题、拆解问题、定位问题、解决问题、落地问题
- 如何设计方案:3C方案设计法-选择实现方案
- 事后
- 4D总结法
- 结果
- 业务团队:业务开发项目、技术优化方案、管理措施
- 中间件团队:系统性能、可用性、成本
- 技术支撑团队:运维和测试,质量、效率和成本
- 数据
- 一切能用量化的,进件率、通过率
- 技术
- 成长
- 业务理解能力、项目组织、带团队的能力、沟通能力 做事方法
- 结果
- 金字塔汇报法
- 结论先行
- 自顶向下
- 归类分组
- 复盘:四线复盘法
- 时间线
- 讲清楚事实、问题发生的经过
- 问题链
- 全面且深入的分析
- 责任链
- 改进线
- 指定可以落地的改进措施、问题的改进计划
- 时间线
- 4D总结法
- 认知
- 什么是认知,你对事物的看法,综合经历、经验、知识、见识,不同的人对同一个事物认知不同。
- 认知不同-> 选择不同-> 结果不同
- 提升认知
- 多学习、输入、跟高手学习、好的环境、
- 认知是隔在成功与我们之间的很大的鸿沟
大厂技术面试考察点
- 基础知识、技术深度、广度、项目经验、团队管理
工作中遇到的那些问题、难点 系统架构图
操作系统
https://segmentfault.com/a/1190000039774784 从根上理解用户态与内核态
- 分布式微服务架构设计
- 登录功能架构设计
- 用户安全架构设计
- 系统日志架构设计
- 系统攻防架构设计
- 系统消息架构设计
- 监控预警架构设计
- 大数据架构设计
- 批处理调度架构设计
- 系统配置架构设计
1.代码解耦性设计 2.自研myabtis 慢sql分析组件,参考京东开源的慢sql组件 3.自研决策树规则引擎组件设计,参考京东帮超级架构师之神的小傅哥的项目 3.自研动态线程池组件设计,参考美团动态线程池dynamic-tp的设计 4自研优雅记录日志组件设计,参考美团优雅记录日志的项目设计 5.自研BCP业务规则平台组件设计,参考转转和美团的BCP平台设计 6.自研业务通用HTTP框架设计,参考dromana社区的开源forest的设计
极客时间看完->读经典书籍
设计模式
- 设计模式、head first设计模式、java与模式