Home
This is a secondary project or study of Mislav Vuletić's daily-expense-manager project with a focus on the processing of the dataset used in the inquest. The goal of Mislav's case study was to process historical daily expenses data with machine learning algorithms to understand and predict an individual's spending behaviour.
$ git clone https://github.com/MasterMedo/daily-expense-manager.gitThe dataset used for the study needed pre-processing and enrichment with data from secondary sources like exchange rates and geolocation data; this was originally done by Mislav who used the pandas package for ETL and analysis in a single program.
It might suffice to persist ETL and analysis workloads through the same program when conducting a personal study, especially with small datasets. But in a business environment, transformational or ETL workloads shouldn't be siloed in notebooks littered everywhere across the organization.
It is a data management best practice to manage ETL workloads or processes centrally and in a unified fashion, especially for mission critical datasets. Data analysts/scientists can access high-quality data for their analysis reliably if a centralized ETL data pipeline is developed and managed by ETL/Data engineers.
Centralizing ETL processes also helps to ensure consistency and accuracy in the data. By having a single source of truth, data can be managed and maintained in a more organized and efficient manner. This can also help to reduce errors and redundancies that can occur when data is managed in a decentralized manner.
An ETL (Extract, Transform, Load) pipeline is essential for getting data from different sources, transforming it into a usable format, and loading it into a data warehouse or other destination.
Overall, a centralized ETL pipeline can help improve the quality and reliability of data, which is crucial for any data-driven organization.
This secondary project solely focuses on the development of an ETL data pipeline to manage the data processing workload for the daily expense analysis program.
This is a python project and it is portable.
$ python3 -m venv .venv
$ source .venv/bin/activate
$ which pip
$ cat requirements.txt
$ pip install -r requirements.txtThe program's configurations are saved in ./config.ini
This project utilizes the petl package on PyPi.
petltransformation pipelines make minimal use of system memory and can scale to millions of rows if speed is not a priority. This package makes extensive use of lazy evaluation and iterators. This means, generally, that a pipeline will not actually be executed until data is requested.
This project also utilizes the geopy package, which is a Python client for several popular geocoding web services, the countryinfo python module for returning data about countries, and the requests module for making HTTP requests.
The period of data collection is year 2018.
$ file=../data/expenses.csv
$ cat $file | petl "fromcsv().cut(*range(0,13)).header()"1 hrk - croatian kuna, amount of money spent in the currency of Croatia,
2 vendor - company that I bought an item/service from,
3 date - DD.MM.YYYY. or DD.MM.,
4 description - specifically what I spent money on (ice-skating, food, bus, alcohol...),
5 meansofpayment - cash/credit-card/paypal,
6 city - lowercase name of the city,
7 category - more general than description e.g. (bus, train, tram) -> transport,
8 currency - three letter code of the currency e.g. HRK, EUR, PLN...,
9 country - lowercase name of the country (shortened name if possible e.g. czechia),
10 lcy - local currency, amount of money spent in the local currency of current transaction,
11 eur - euro, amount of money spent in euros,
12 tags - something that will remind me of the record,
13 recurrence - is the expense likely to be repeated (yes/no)
The data source is file=../data/expenses.csv, please refer to ../scripts/datainspector.sh for the introspection of the dataset.
We have unnamed headers with white spaces delimited by comma in csv file

Over 55% of records in the data source have missing values in features of importance
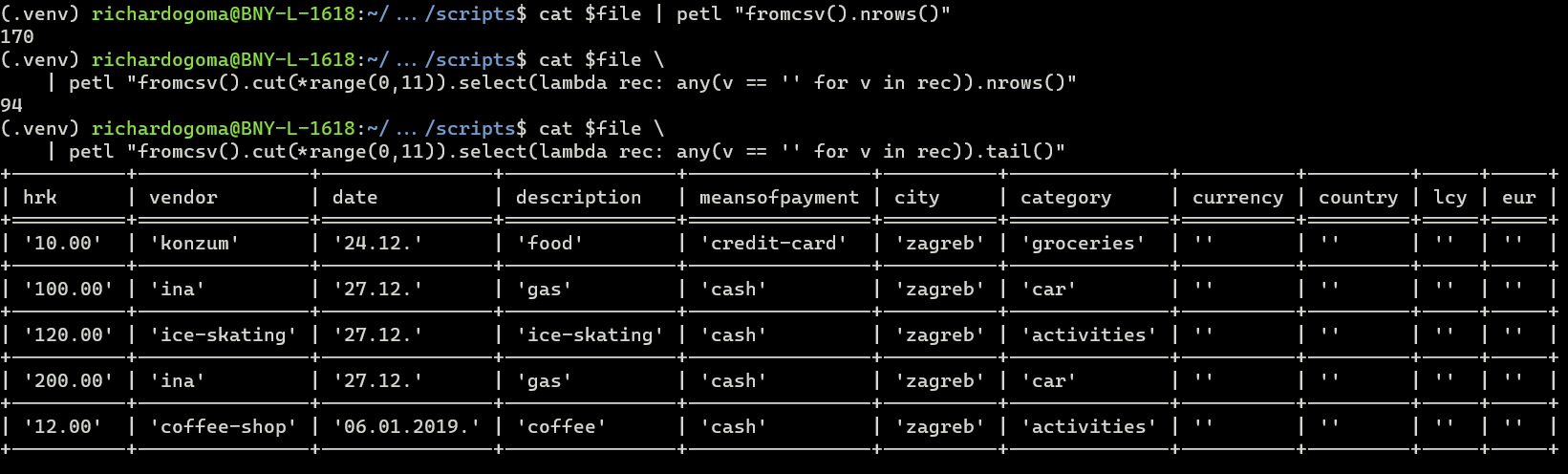
Refer to cat ../data/empties.csv
The format of dates in the date field has to be homogeneous, but the dataset has dates in either dd.mm. or dd.mm.yyyy. format.
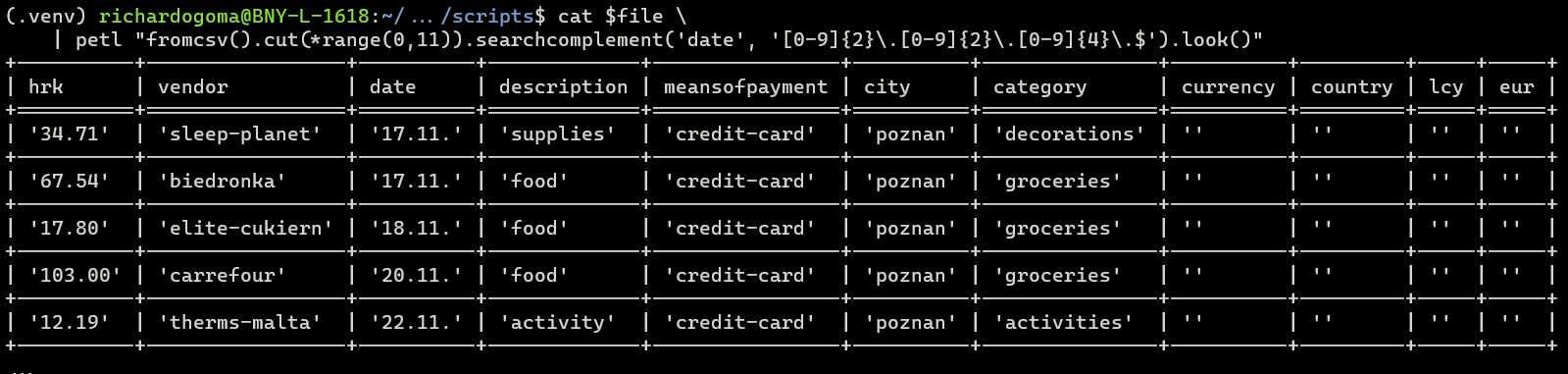
Refer to cat ../data/anomalousdates.csv
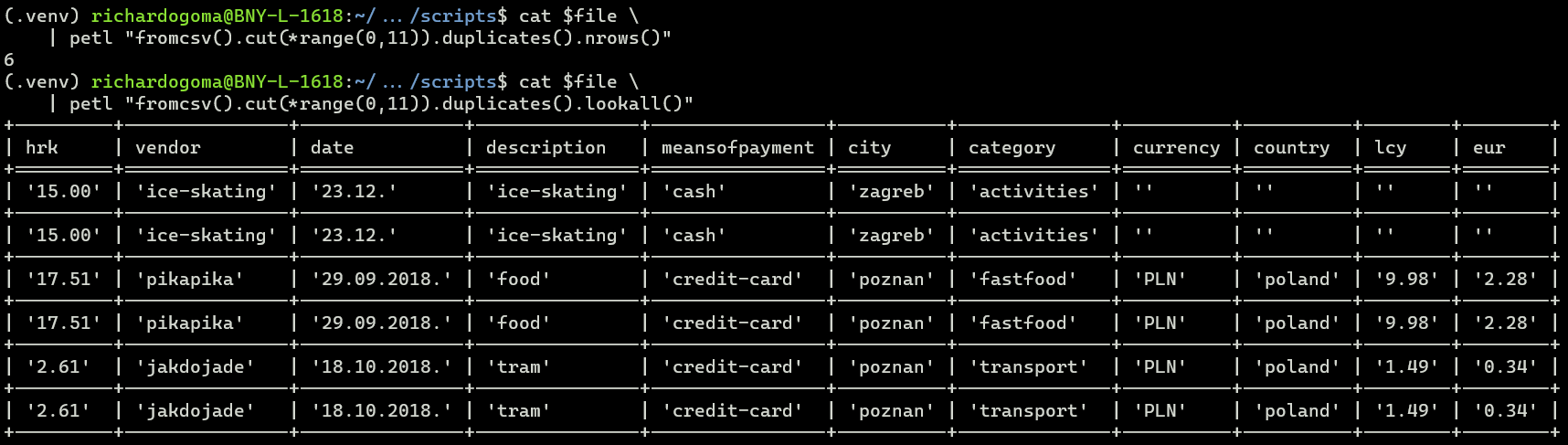
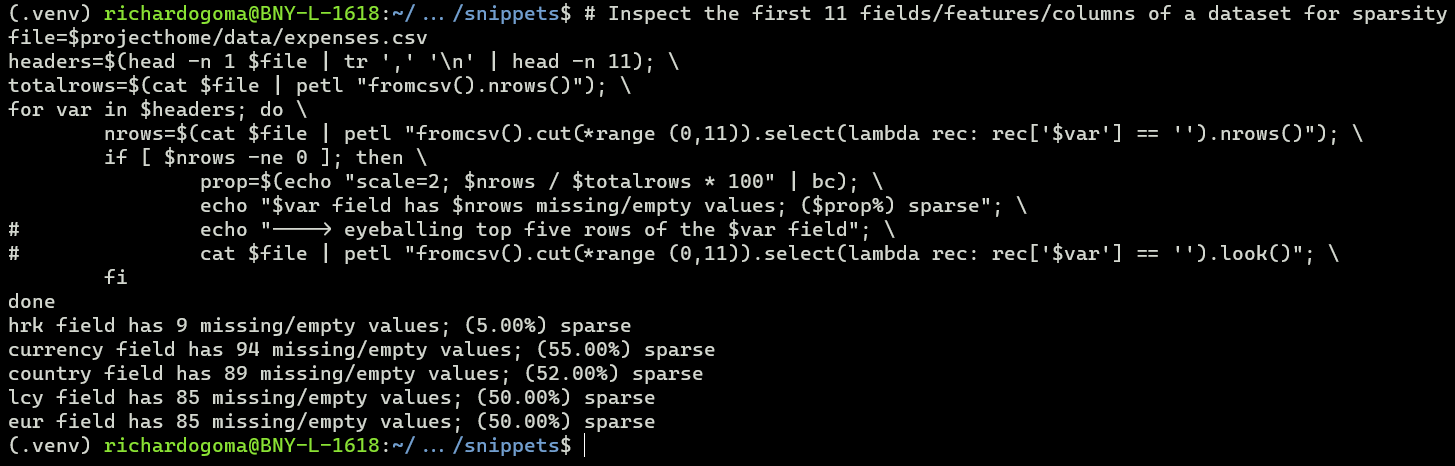

While the currency feature has the highest percentage of data sparsity at 55%, we can source this data from secondary sources (geolocation APIs) using the city and country features.
The study used euros (EUR) as the currency of focus. The missing hrk values would be derived from the lcy (or local currency) field, and finally the missing values in the eur field would be derived via public forex APIs using the hrk field.

Although we don't have such instances in the dataset used for the study, but if we have cases where hrk, lcy and eur features are missing simultaneously, they would be expunged as such records present no value to the expense analysis.
It is expected that the lcy feature would be the only sparse field after enrichment of other features in the pipeline, therefore, the lcy feature would be discarded at the tail end of the transformational pipeline.
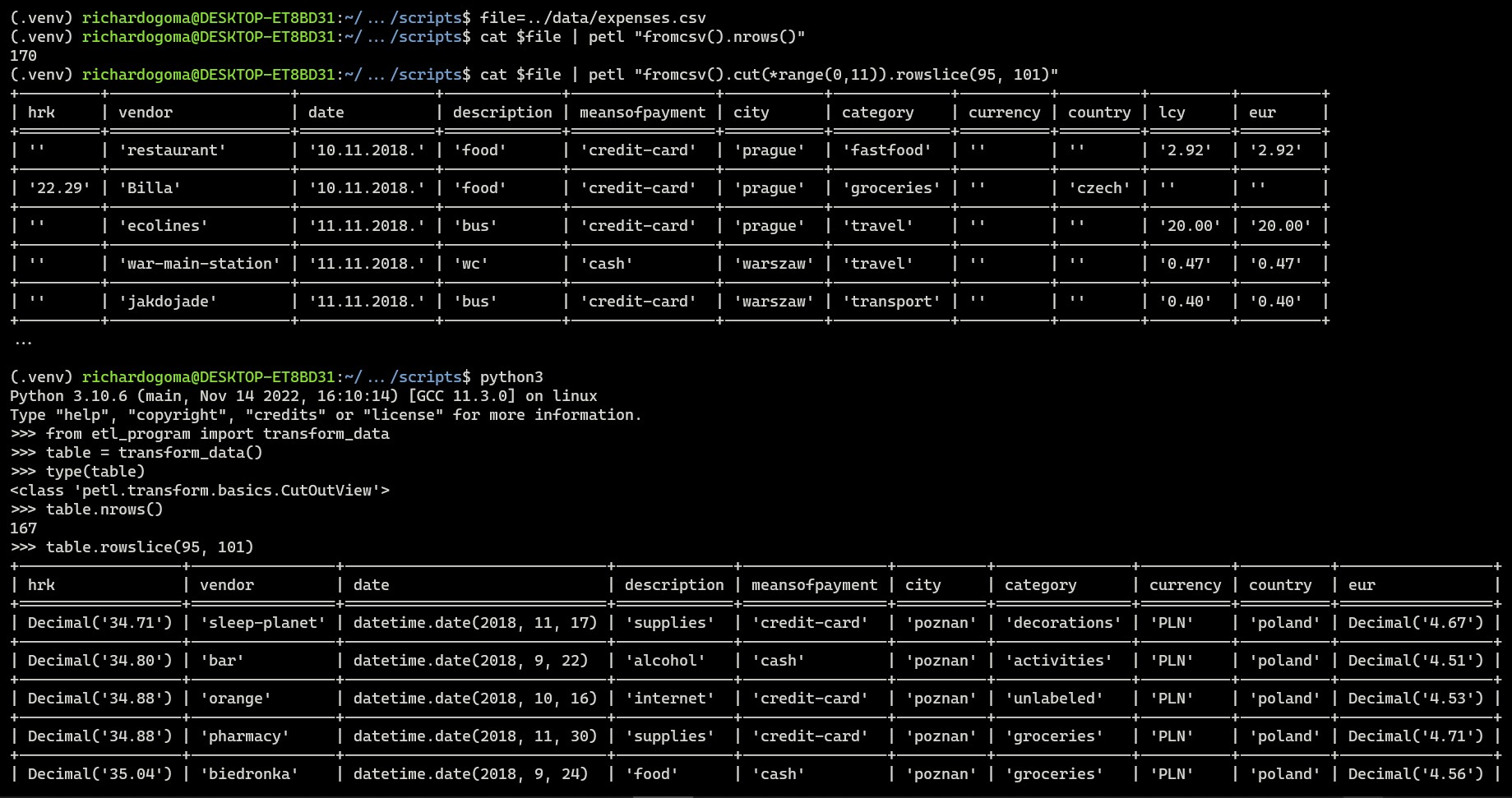
We observe transformations on the rowslice when the transform_data() function is invoked. Proof of concept that the pipeline works as intended.
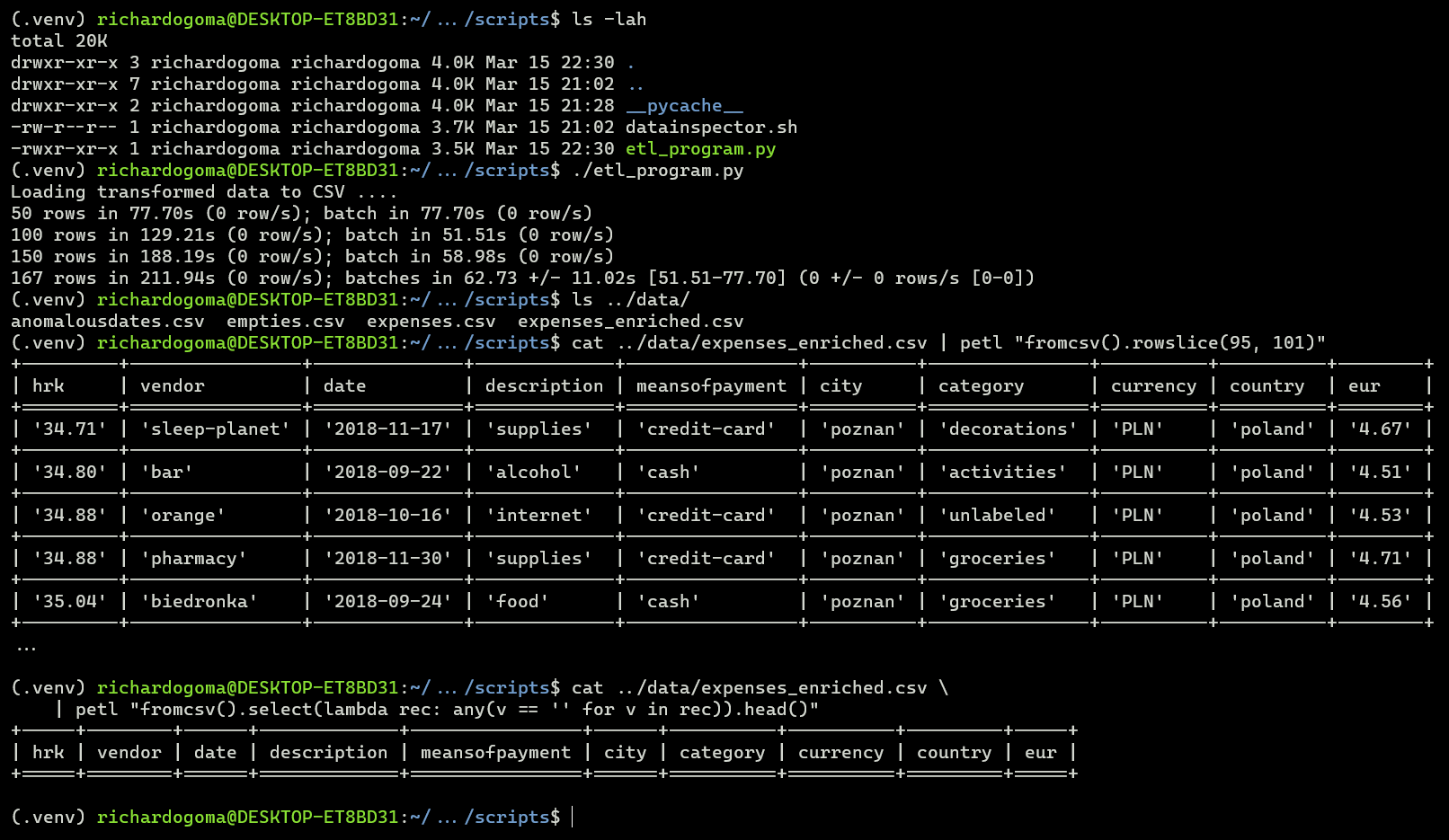
- The program is not a speedy. Costing 211.94secs to process 167 rows is, well? 🤔 However, the program depends on secondary data sources over the internet, and the performance of these sources directly impact the program's performance.
- Proof of concept has been established that the ETL pipeline is effective, maybe not efficient. This holds as there are no longer records with missing values. This is proof that the raw data has been processed effectively and enriched with data from secondary sources.
- According to documentation,
petltransformational pipelines are not scalable if speed is a priority, especially when working with very large datasets and/or performance-critical applications. - The volume of HTTP requests made by the program may need require review, as those secondary data sources over the internet largely affect the performance of this program. For example, the country-currency lookup.
- A proper loading area such as a database is more effective to preserve the transformed dataset's datatype/metadata which cannot be persisted to a flat file.
The goal of this study has been achieved, and proof of concept has been established.