{kind=link}
A simple, planar self-organizing map with methods similar to clustering methods in Scikit Learn.
sklearn-som is a minimalist, simple implementation of a Kohonen self organizing map with a planar (rectangular) topology. It is used for clustering data and performing dimensionality reduction. For a brief, all-around introduction to self organizing maps, check out this helpful article from Rubik's Code.
There are already a handful of useful SOM packages available in your machine learning framework of choice. So why make another one? Well, sklearn-som, as the name suggests, is written to interface just like a clustering method you would find in Scikit Learn. It has the advantage of only having one dependency (numpy) and if you are already familiar with Scikit Learn's machine learning API, you will find it easy to get right up to speed with sklearn-som.
Using sklearn-som couldn't be easier. First, import the SOM class from the sklearn_som.som module:
from sklearn_som.som import SOMNow you will have to create an instance of SOM to cluster data, but first let's get some data. For this part we will use sklearn's Iris Dataset, but you do not need sklearn to use SOM. If you have data from another source, you will not need it. But we are going to use it, so let's grab it. We will also use only the first two features so our results are easier to visualize:
from sklearn import datasets
iris = datasets.load_iris()
iris_data = iris.data[:, :2]
iris_label = iris.targetNow, just like with any classifier right from sklearn, we will have to build an SOM instance and call .fit() on our data to fit the SOM. We already know that there are 3 classes in the Iris Dataset, so we will use a 3 by 1 structure for our self organizing map, but in practice you may have to try different structures to find what works best for your data. Let's build and fit the som:
iris_som = SOM(m=3, n=1, dim=2)
iris_som.fit(iris_data)Note that when building the instance of SOM, we specify m and n to get an m by n matrix of neurons in the self organizing map.
Now also like in sklearn, let's assign each datapoint to a predicted cluster using the .predict() method:
predictions = iris_som.predict(iris_data)And let's take a look at how we did:
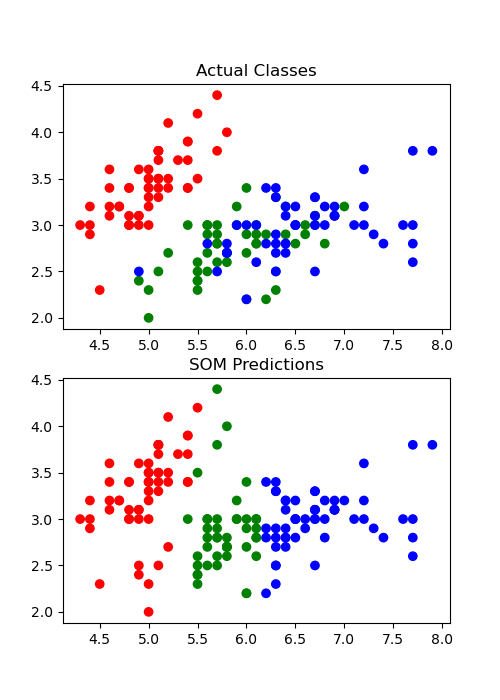
Not bad! For the full example code, including the code to reproduce that plot, see example/example.py at https://github.com/rileypsmith/sklearn-som.
For full documentation, visit the project page on ReadTheDocs.
If you would like to contribute to sklearn-som, feel free to drop me a line or just submit a pull request and I'll take a look. Ideas for future expansion include adding the ability to make higher dimensional self-organizing maps and to use a hexagonal grid rather than a rectangular one. I may get to those expansions at some point.
Also, if you find a bug, please open an issue on GitHub!!