This blogpost will go through a very attractive alternative for gathering data for a given specific application. Regardless of the type of application, this blogpost seeks to show the reader the pontential of synthetic data generation with open-source resources such as Blender. This is the link to the full blogpost: https://federicoarenasl.github.io/Data-Generation-with-Blender/.
Indeed, the need to gather data and label it in a short amount of time is one that hasn't been exactly solved when it comes to real-life data. This is why, to tackle this problem, we must turn to synthetic data generation which, with the right amount of code, can provide both the labels and the features needed to train a deep learning model later on.
In this case, we focus on an object recognition problem, and we generate the data using Blender and its scripting functionality.
For this project we are going to generate the data to recognize the wooden toys shown in the images below. In order to do this, we are going to create an algorithm that takes pictures of all of the objects in the same configuration as in the pictures, and also outputs the labels corresponding to the bounding boxes of the location of each object in each image.






The classes we wish to recognize are the following:
Pink flower
Blue square
Green star
Yellow hexagon
Orange lozenge
Pink oval
Blue rectangle
Green circle
Orange triangle
The algorithm mentioned above is going to be implemented in Python in the rendering software Blender. Blender is an open source software used for multiple rendering applications ranging from animation to product design. This software is going to allows to create realistic renderings of the objects seen above, while allowing us to access the position of each object too, a key feature for the labelling to be done. The renderings are as shown below:
Finally, we run a program that draws the outputted labels to the outputted images in order to verify that these labels are correctly pointing to each of the objects.
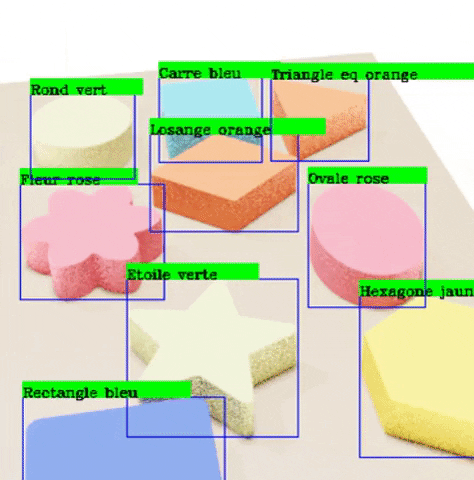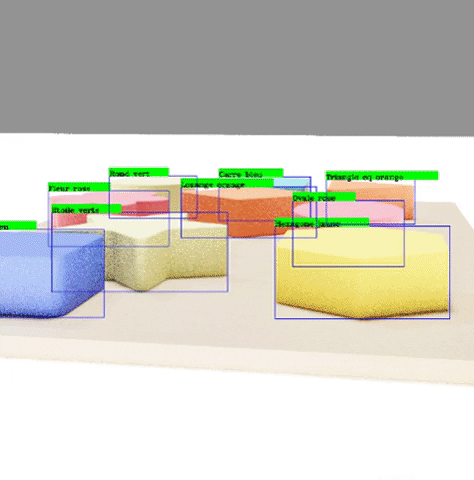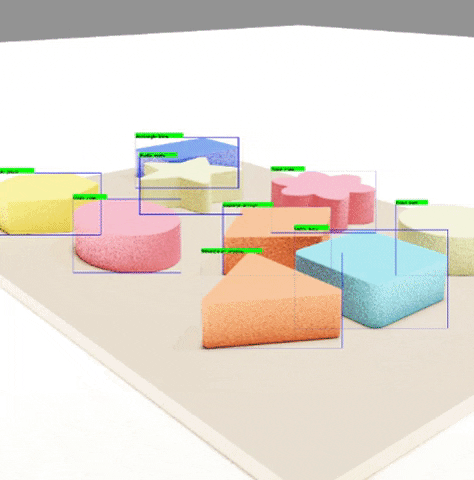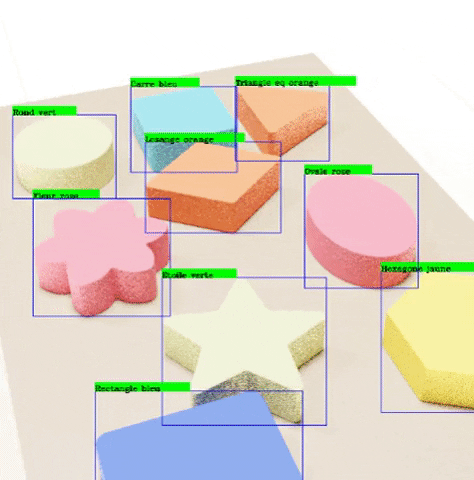
The recognition results are satisfactory taking into account that it took us around a week to obtain the data and train our models, with low-capacity computers. This means that the scalability of synthetic data generation is very good. With better resources, we can train our algorithms with a lot more data, and even more photo-realistic.

A demonstration of the algorithm working on synthetic test data can be seen below and the full video can be found here.
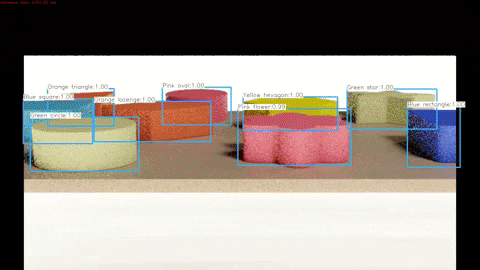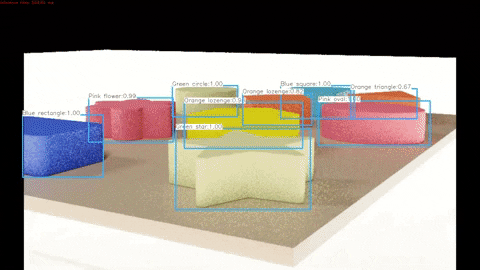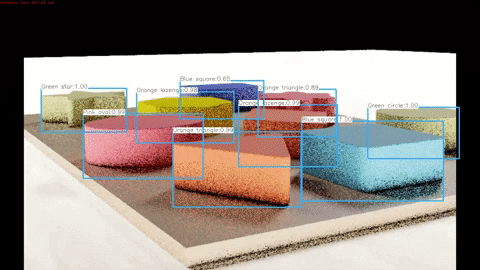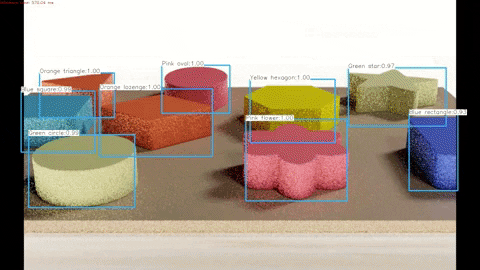
A demonstration of the algorithm working on real test data can be seen below and the full video can be found here.

.