This repository is made in attempt to implement the U-Net paper. We implemented the convolutional neural network architecture given in the paper. There are 32 classes in total.
- Minimal implementation of the U-Net
- Complete Readme
- Visualizing output of the model
- Adding different metrics to evaluate performance
Semantic segmentation refers to the process of mapping/classifying each pixel in an image to a class label. It can also be referred to as image classification for pixels in an image. Its primary applications include autonomous vehicles, human-computer interaction, robotics and photo-editing tools. It is very useful for delf-driving cars in which contextual information of the environment is required at each and every step while traversing the route.
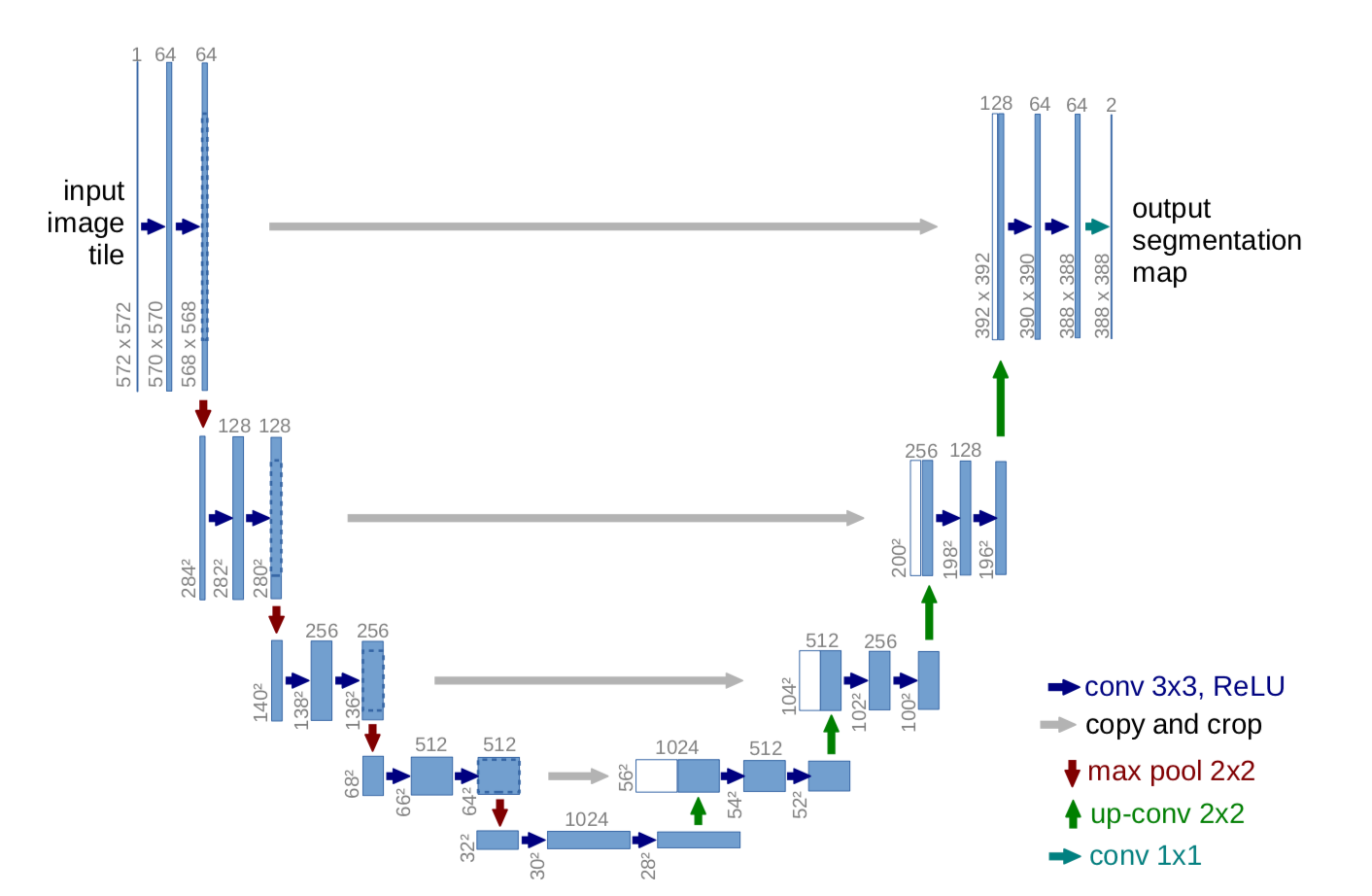
The network architecture mentioned in the U-Net paper is used. The first half of the U-Net is an encoding task and the second half is a reconstruction task. To get the confidence scores in the form of a probabilities, we use the softmax activation function at the output layer. And then we choose cross entropy loss as our error function.
The Cambridge-driving Labeled Video Database (CamVid) is the first collection of videos with object class semantic labels, complete with metadata. The database provides ground truth labels that associate each pixel with one of 32 semantic classes. The dataset can be found here.