
Word by word audio subtitle synchronization (forced alignemnt) tool and API. Developed under Google Summer of Code 2017 with CCExtractor.
The project is in it’s very early stage and is constantly evolving. The available functions, usage instructions et cetera are expected to refactor over time. It is not production ready but you are welcome to play with it, or better, help improve it! :)
CCAligner can be used as both standalone tool or a library in your own project.
To automatically generate language models, dictionaries and grammars, following dependencies need to be met. The tool has capability to generate them without these dependencies, but the accuracy in that case is not guaranteed. It is highly recommended to work with the dependencies installed.
-
cmuclmtk : to generate vocab and LM. (
install/dependencies/cmuclmtk-0.7.tar.gz) -
g2p-seq2seq : to generate dictionary. (
install/dependencies/g2p-seq2seq)
You will also need to install Perl and move install/quick_lm.pl to the same directory as the CCAligner or a directory that is set in the environment variable PATH.
Steps :
Linux/MacOS
To install cmuclmtk :
-
Navigate to
install/dependenciesdirectory and uncompresscmuclmtk-0.7.tar.gzwhile preserving the permissions :tar xvpzf cmuclmtk-0.7.tar.gz
Original download link : (https://sourceforge.net/projects/cmusphinx/files/cmuclmtk/0.7/cmuclmtk-0.7.tar.gz/download)
-
Navigate to
cmumltk-0.7directory :cd cmuclmtk-0.7
-
Install :
./configure make sudo make install
You may have to run sudo ldconfig to fix errors such as missing shared library.
To install g2p-seq2seq :
-
The tool requires TensorFlow at least version 1.0.0. Please see the installation guide for details. If you are on Linux (x86_64), you may directly run the following :
sudo pip install --upgrade https://storage.googleapis.com/tensorflow/linux/cpu/tensorflow-1.0.0-cp27-none-linux_x86_64.whl
Note : To use g2p with latest versions of TF, download the up-to-date repository from (https://github.com/cmusphinx/g2p-seq2seq). Please note that the recent g2p version brings changes that break few things in CCAligner, so using the supplied version is recommended.
-
Navigate to
install/dependenciesdirectory and uncompressg2p-seq2seq.zipwhile preserving the permissions :unzip g2p-seq2seq-master.zip
-
Navigate to
g2p-seq2seq-masterdirectory and run :sudo python setup.py install
The alternate ways of generating language models, dictionaries and grammars are covered later in the docs.
Windows
To install cmuclmtk :
-
Navigate to
install/dependenciesdirectory and uncompresscmuclmtk-0.7.tar.gz. Build it with thecmuclmtk.slnit provides. -
Copy the compiled files (wfreq2vocab.exe, text2wfreq.exe, text2idngram.exe, idngram2lm.exe) to the same directory as the CCAligner or you can set the directory contains these files to environment variable (PATH)
To install g2p-seq2seq :
-
First, install Python 3.5 (64-bit) and Tensorflow 1.0.0 by your preferred choice of method
-
Navigate to
install/dependenciesdirectory and uncompressg2p-seq2seq-master.zip -
Navigate to
g2p-seq2seq-masterdirectory and run :python setup.py install
-
Please make sure you have all the dependencies installed in case you want to use grammar tools. To disable generating grammar by CCAligner, issue
--generate-grammar no. -
Make sure the
modelfolder andg2p-seq2seq-cmudictare in the directory where you are compiling CCAligner. -
Make sure the subtitles are clean and are in proper SRT format.
-
The wav file should be 16 bit PCM mono sampled at 16KHz. To generate the wav file using a video through FFmpeg, you may :
./ffmpeg -i input.video -bits_per_raw_sample 16 -ar 16000 -ac 1 output.wav
Linux/MacOS
-
Clone the repository from Github using :
git clone https://www.github.com/saurabhshri/CCAligner.git
-
Navigate to
installdirectory and runbuild.sh.cd install/ ./build.sh
-
Align!
./ccaligner <arguments>
Windows
-
Clone the repository from Github using :
git clone https://www.github.com/saurabhshri/CCAligner.git
-
Use CMake to generate project files, and then build it.
-
Align!
.\ccaligner <arguments>
The default output of CCAligner is stored as an XML file. For example, the next command will generate file.xml :
./ccaligner -wav /path/to/file.wav -srt /path/to/file.srt
Generated Output Snippet :
.
.
<subtitle>
<start>12780</start>
<dialogue>I was offered a summer research fellowship at Princeton. </dialogue>
<edited_dialogue>I was offered a summer research fellowship at Princeton</edited_dialogue>
<words>
<word>
<recognised>0</recognised>
<text>I</text>
<start>12780</start>
<end>12911</end>
<duration>131</duration>
</word>
<word>
<recognised>1</recognised>
<text>was</text>
<start>13030</start>
<end>13330</end>
<duration>300</duration>
</word>
<word>
<recognised>1</recognised>
<text>offered</text>
<start>13400</start>
<end>13770</end>
<duration>370</duration>
</word>
.
.
.
</words>
<end>16382</end>
</subtitle>
.
.
-
Clone the repository from Github :
git clone https://github.com/saurabhshri/CCAligner.git
-
Place the
CCAlignerfolder in appropriate directory in your project. -
In your project, simply include the directories and source file you wish to use. You may refer to CMakeLists.txt in the
src/directory to get an idea. The CCAligner tool is built around the CCAligner API.
For example : If you want to use the audio based alignment in your project
//include the header file
#include "recognize_using_pocketsphinx.h"
//Declare the aligner
PocketsphinxAligner * aligner = new PocketsphinxAligner(_parameters);
//Align
aligner->align();
//Print the result
aligner->printAligned("Manual_Printing.json", json);
//delete the aligner
delete(aligner);Complete documentation of the API will be written in docs.
-
Click on video thumbnail or link to watch the video on YouTube.
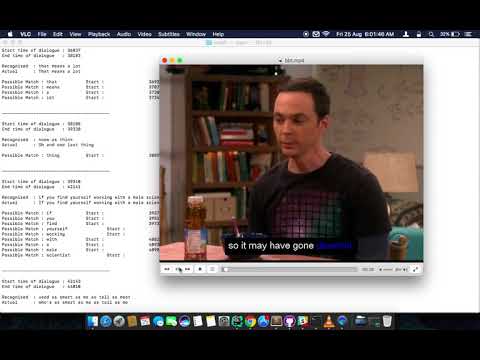
|
Word by Word Audio Subtitle Synchronization - Karaoke Demo 1 (https://www.youtube.com/watch?v=38_27E1PxXA) [Sitcom] |

|
Word by Word Audio Subtitle Synchronization - Karaoke Demo 2 (https://www.youtube.com/watch?v=6VnhC8u_d40) [Ted Talk] |
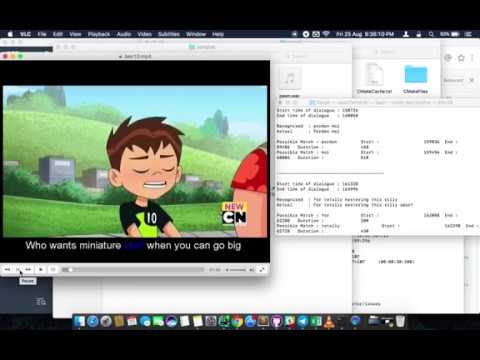
|
Word by Word Audio Subtitle Synchronization - Karaoke Demo 3 (https://www.youtube.com/watch?v=j_zeixo-zJY) [Cartoon Show] |

|
Word by Word Audio Subtitle Synchronization - Karaoke Demo 1 (https://www.youtube.com/watch?v=8tTDX6NZGsU) [Discussion Video] |
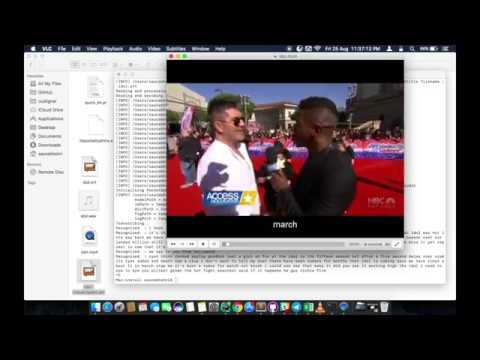
|
Word by Word Audio Video Transcription Demo (https://www.youtube.com/watch?v=tFrf0TVnqIQ) [Reality Show] |
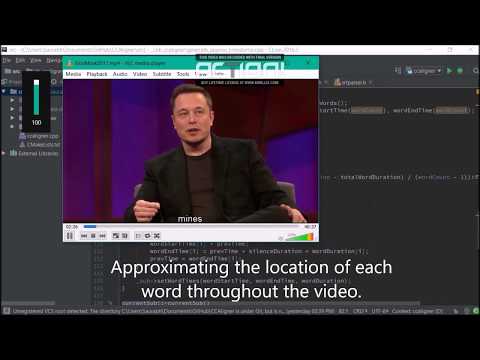
|
Approximate Word by Word Audio Subtitle Synchronization |
The following is a complete list of available parameters that can be passed to CCAligner. Feel free to open a PR if you spot a missing parameter.
-
Input related parameters :
| Parameter | Accepted Values | Description |
|---|---|---|
|
|
Provide path to input audio wave file. Wave file must be 16 bit PCM mono sampled at 16KHz. E.g.: Required : yes. |
|
|
Provide path to subtitle file in SRT format. Please ensure that the subtitle file is clean and in proper format. E.g.: Required : yes. |
|
Audio wave file from stdin or pipe. |
Use this parameter to pass wav file from E.g.: |
-
Output related parameters :
| Parameter | Accepted Values | Description |
|---|---|---|
|
|
Provide name and path to generated to output file. By default the output name is extracted from input file and generated in same location in which the input file is located. E.g.: |
|
|
To choose output format. By default the output format is XML. E.g.: |
|
|
Specify path to logfile for PocketSphinx decoder. By default stores log in E.g.: |
|
|
Specify path to logfile for PocketSphinx phoneme decoder. By default stores log in E.g.: |
-
Alignment related parameters :
| Parameter | Accepted Values | Description |
|---|---|---|
|
|
Use approx aligner instead of audio based aligner. Calculated timing of words based on it’s weight. Super fast and doesn’t involve audio analysis. Please be aware the result is not accurate but approximate. E.g.: |
|
|
Recognise and find phonemes and their timestamps along with words. SRT and Karaoke output can not display phonemes. E.g.: |
|
|
Performs transcription of complete audio instead of searching using timestamps and subs. Use this when timings in subtitles are incorrect or you want YouTube like transcription of video. E.g.: |
|
|
Instruct CCAligner to follow Finite State Grammar while performing recognition. E.g.: |
|
|
Instruct CCAligner to use batch mode of PocketSphinx. May improve accuracy by flushing CMN values. E.g.: |
|
|
Use experimental parameters. May improve accuracy in some cases. E.g.: |
|
An integer |
Determine the extent to which current recognised word is searched in the respective subtitle dialogue. Default value is 3. E.g.: |
|
An integer |
Determine the frontal and rear window from current subtitle timing to perform recognition. The value should be in milliseconds. Default value is 0. E.g.: |
|
An integer |
Determine the frontal and rear window from current subtitle timing to perform recognition. The value should be in number of samples. Default value is 0. E.g.: |
-
Grammar, Language Model related parameters :
| Parameter | Accepted Values | Description |
|---|---|---|
|
|
Parameter deciding if and which type of grammar/lm to be generated. Once you have generated these files, no need to generate them again. They are stored in E.g.: |
|
|
Enter path of acoustic model to be used by aligner. Accuracy highly depends on the acoustic model. E.g.: |
|
|
Enter path of language model to be used by aligner. E.g.: |
|
|
Enter path of dictionary to be used by aligner. E.g.: |
|
|
Enter path of the directory containing FSGs, each FSG with name as starting timestamp of dialogue. E.g.: |
|
|
Enter path of phonetic language model to be used by aligner. E.g.: |
|
|
Generate dictionary quickly without using TensorFlow and seq2seq. Result might not give best accuracy. E.g.: |
|
|
Generate language model quickly without using cmuclmtk. Result might not give best accuracy. E.g.: |
-
Display related parameters :
| Parameter | Accepted Values | Description |
|---|---|---|
|
|
Turns verbosity on and off. Turn off for preventing [info] logs. E.g.: |
|
|
Determine whether to display the recognised words and matching status on stdout or not. E.g.: |
The usual subtitle files (such as SubRip) have line by line synchronization in them i.e. the subtitles containing the dialogue appear when the person starts talking and disappears when the dialogue finishes. This continues for the whole video. For example :
1274
01:55:48,484 --> 01:55:50,860
The Force is strong with this oneIn the above example, the dialogue #1274 - The Force is strong with this one appears at 1:55:48 remains in the screen for two seconds and disappears at 1:55:50.
The aim of the project is to tag the word as it is spoken, similar to that in karaoke systems.
E.g.
The [6948484:6948500]
Force [6948501:6948633]
is [6948634:6948710]
strong [6948711:6949999]
with [6949100:6949313]In the above example each word from subtitle is tagged with beginning and ending timestamps based on audio.
-
Project link on official GSoC web-app : https://summerofcode.withgoogle.com/projects/#5589068587991040
-
Project repository on Github: https://github.com/saurabhshri/CCAligner
-
Weekly blog : https://saurabhshri.github.io
-
Milestones and deliverables checklist: https://saurabhshri.github.io/gsoc/
I haven’t decided the license for the tool yet, but all the individual licenses of libraries and code used can be found under license/ directory.
I have tried my best to ensure that credit and reference is given in the source wherever it is due. In case I have missed any reference/license, firstly please accept my apology. Feel free to reach out to me and I’ll be happy to correct my mistake. 🤝