SIP-58 - Named Tuples #72
Conversation
Co-authored-by: Jamie Thompson <[email protected]>
|
|
||
| Looking at precedent in other languages it feels like we we do want some sort of subtyping for easy convertibility and possibly an implicit conversion in the other direction. | ||
|
|
||
| The discussion established that both forms of subtyping are sound. My personal opinion is that the subtyping of this proposal is both more useful and safer than the one in the other direction. There is also the problem that changing the subtyping direction would be incompatible with the current structure of `Tuple` and `NamedTuple` since for instance `zip` is already an inline method on `Tuple` so it could not be overridden in `NamedTuple`. To make this work requires a refactoring of `Tuple` to use more extension methods, and the questions whether this is feasible and whether it can be made binary backwards compatible are unknown. I personally will not work on this, if others are willing to make the effort we can discuss the alternative subtyping as well. |
There was a problem hiding this comment.
Can you summarize the discussion here? There were four options (named <: unnamed, unnamed <: named, no subtyping, unnamed =:= names with _n names) and someone reading this SIP should be able to understand the pros and cons of each and why one selection was chosen, even if they may not agree with the choice
|
|
||
| This revives SIP 43, with a much simpler desugaring than originally proposed. | ||
| Named patterns are compatible with extensible pattern matching simply because | ||
| `unapply` results can be named tuples. |
There was a problem hiding this comment.
Can we make user defined class instances support named pattern matching without conversion to named tuples? I feel like "pattern matching without allocation" has been a direction Scala has been going into, with name-based pattern matching and Scala's new pattern matching desugaring, and forcing people to allocate a named tuple to support named pattern matching feels out of place
There was a problem hiding this comment.
Unapply could also return some case class, or an option of it. That would work as well for named matching. The only corner case where case classes don't work but tuples do is if there's only one name. See the discussion in SIP 43, which is quite involved.
There was a problem hiding this comment.
So for normal pattern matching, my understand is that it's dependent on the ProductN trait. That means that it is not hardcoded to case classes and tuples, but even normal classes/traits can benefit from zero allocation pattern matching as well. Please correct me if I'm wrong
Would normal classes/traits have some trait they can implement to support names pattern matching in the same way? Or is this a known limitation that we are consciously deciding to live with?
There was a problem hiding this comment.
ProductN is no longer a thing in Scala 3. An unapply can return a Product trait. That's typically the argument itself, which means no allocations. If the argument is a case class (the most common case), we can do named pattern matching on it. If not, we don't have the names, so it's not possible.
There was a problem hiding this comment.
I guess my question is: given positional pattern matching has a Product trait, that positional Tuples implement, should named pattern matching also have a NamedProduct trait that NamedTuples implement?
At least superficially, I can imagine
NamedProduct[N <: Tuple] extends ProductwhereNis a tuple of string literalsNamedTuple[N <: Tuple, +V <: Tuple] extends NamedProduct[N]- Define named pattern matching on
NamedProduct, so thatNamedTuples get it for free due to inheriting fromNamedProduct, but user-land normal classes and traits can inherit fromNamedProductand get it as well
I'm not saying we should do this, just that it seems like the natural way of extending the existing Product/Tuple/positional-pattern-matching relationship to NamedTuple/named-pattern-matching. So even if the answer is "no this cannot work" or "maybe it can work but we can always do it later in a follow up" it deserves to be called out explicitly as a design decision
There was a problem hiding this comment.
It's an interesting suggestion. A product match looks for the presence of _1, _2, ...., selectors. If the scrutinee implements NamedProduct , we could then alternatively use the associated names in patterns and selectors instead. But the problem is we can't abstract over it. If we want to have a generic type that reflects names and types, we are back to NamedTuple.
Maybe someone could try that out, see whether it would work? I agree we can do it independently later.
|
|
||
| We also considered to expand structural types. Structural types allow to abstract over existing classes, but require reflection or some other library-provided mechanism for element access. By contrast, named tuples have a separate representation as tuples, which can be manipulated directly. Since elements are ordered, traversals can be defined, and this allows the definition of type generic algorithms over named tuples. Structural types don’t allow such generic algorithms directly. Be could define mappings between structural types and named tuples, which could be used to implement such algorithms. These mappings would certainly become simpler if they map to/from named tuples than if they had to map to/from user-defined "HMap"s. | ||
|
|
||
| By contrast to named tuples, structural types are unordered and have width subtyping. This comes with the price that no natural element ordering exist, and that one usually needs some kind of dictionary structure for access. We believe that the following advantages of named tuples over structural types outweigh the loss of subtyping flexibility: |
There was a problem hiding this comment.
Do structural types truly always need dictionaries? Can we have e.g. a synthetic trait for every structural member, such that
def x: {def foo: Int, def bar: String}desugars to
package scala.structural
trait WithFoo[T]{ def foo: T}
trait WithBar[T]{ def bar: T}def x: scala.structural.WithFoo[Int] with scala.structural.WithBar[String]The scala.structual traits could/would be duplicated by various compilation runs, but they would all be the same implementation, and so the duplicate classpath entries would be benign since they would all resolve to the same interfaces
There was a problem hiding this comment.
That has been tried from time to time by us and others. I believe one such paper is: https://dblp.org/rec/conf/oopsla/GilM08.html
But nothing ever materialized. Generally, creating globally visible classes on the fly is a can of worms.
Also, we still need a traversal principle, which named tuples give us, but structural types don't.
There was a problem hiding this comment.
What's a traversal principle?
There was a problem hiding this comment.
A way to inductively visit all the members of a type at the type level, typically using a match type.
| Named tuples are in essence just a convenient syntax for regular tuples. In the internal representation, a named tuple type is represented at compile time as a pair of two tuples. One tuple contains the names as literal constant string types, the other contains the element types. The runtime representation of a named tuples consists of just the element values, whereas the names are forgotten. This is achieved by declaring `NamedTuple` | ||
| in package `scala` as an opaque type as follows: | ||
| ```scala | ||
| opaque type NamedTuple[N <: Tuple, +V <: Tuple] >: V = V |
There was a problem hiding this comment.
Is there any way we constrain the N type parameter more, given that it can only be literal strings, and not arbitrary types like the V paramater next to it? NamedTuple[(Int, Boolean), (Long, Double)] should be illegal right? As should NamedTuple[("foo", "bar", "qux"), (1, 2)] since the two tuples have to be the same length?
There was a problem hiding this comment.
The compiler checks that all labels are string literals. But we can't encode such a constraint in the type bound.
There was a problem hiding this comment.
I think the question is since we are relying on opaque types to represent NamedTuples, what stops the user from creating a badly formed NamedTuples manually or via macros? The Scala 3 compiler protects us from creating bad trees, but it won't in this case, unless the checker special-cases NamedTuples opaque types in its checks.
There was a problem hiding this comment.
the consequence would be like passing around Tuple instead of a concrete case
There was a problem hiding this comment.
It's probably worth listing out in the proposal all the "magic" constraints and checks that we are adding here, since they are not part of the normal type system and would be special-case support for scala.NamedTuple . From what I understand:
N <: Tuplemust only contain literal stringsN <: TupleandV <: Tuplemust have the same lengthN <: Tuplecannot contain duplicates
Is that all, or are there other constraints I'm missing?
There was a problem hiding this comment.
In fact, those constraints are not enforced by the compiler. You can form arbitrary NamedTuple types yourself. There's no additional magic. It's just that they won't fit any named tuple value you write if they are ill-formed.
There was a problem hiding this comment.
I think this would be a good occasion to add a TupleOf[T] (with the semantics TupleOf[T]<: EmptyTuple | T *: TupleOf[T]) to the standard library
While not necessary, it would make the meaning of N clearer (even if it is renamed to something else)
|
|
||
| 2. Should there be an implicit conversion from named tuples to ordinary tuples? | ||
|
|
||
| ## Alternatives |
There was a problem hiding this comment.
An earlier version of this discussion modelled named tuples as tuples whose members wereNamedValue types, basically a "array of structs" type in contrast to the current proposals "struct of arrays" approach.
What were the pros and cons that resulted in the current approach being chosen over that one? It seems to me that the "array of structs" approach better models the requirement that the names are all literal strings and that there are the same number of names and values?
There was a problem hiding this comment.
there was the problem that each element of the tuple has to be unwrapped explicitly from its label, so sometimes the syntax would do it automatically - e.g. pattern extractor, but manual selection needs unwrapping, e.g. compare tup(0).value and tup.x
|
There are a lot of good suggestions to add more sections to the proposal, but I am out of time to do this. Maybe someone else wants to help? There's an implementation to play with to experiment and find out more. |
| Named tuples are in essence just a convenient syntax for regular tuples. In the internal representation, a named tuple type is represented at compile time as a pair of two tuples. One tuple contains the names as literal constant string types, the other contains the element types. The runtime representation of a named tuples consists of just the element values, whereas the names are forgotten. This is achieved by declaring `NamedTuple` | ||
| in package `scala` as an opaque type as follows: | ||
| ```scala | ||
| opaque type NamedTuple[N <: Tuple, +V <: Tuple] >: V = V |
There was a problem hiding this comment.
I think this would be a good occasion to add a TupleOf[T] (with the semantics TupleOf[T]<: EmptyTuple | T *: TupleOf[T]) to the standard library
While not necessary, it would make the meaning of N clearer (even if it is renamed to something else)
content/named-tuples.md
Outdated
| register(person = ("Silvain", 16)) | ||
| register(("Silvain", 16)) | ||
| ``` | ||
| This follows since a regular tuple `(T_1, ..., T_n)` is treated as a subtype of a named tuple `(N_1 = T_1, ..., N_n = T_n)` with the same element types. On the other hand, named tuples do not conform to unnamed tuples, so the following is an error: |
There was a problem hiding this comment.
The proposed named tuples are pretty close to shapeless records in principle (just with new syntax at the type and value level to define them). But, the subtyping relationship is the opposite.
E.g. where (FieldType["foo", Int], FieldType["bar", String]) would be a subtype of (Int, String), in this proposal the equivalent to the former (foo: Int, bar: String) would be a supertype of the latter (Int, String).
I think the named value as a refinement of the unnamed value makes a lot more sense. But in the proposal, there are instead special rules to allow the subtyping relationship to be backwards without total insanity.
Please take a look at FieldType and the very successful (ignoring the symbol-vs-string issue) decade-long history of named tuples (i.e. records) in shapeless, before making a decision here.
@milessabin I wonder if you have an opinion about this.
|
would name tuples be incubated as experimenta feature for a period of time? guess there could be more feedback after people start to play with them would really like to see how they play with type level programming |
Every new Scala feature is first approved for experimentation, before it is approved to be shipped. The time between those milestones is at least a month, and should be longer for controversial features or features that interact with significant parts of the language. What is approved as experimental is only testable under a nightly or snapshot versions of the compiler and usually involves enabling some flag or importing |
| ```scala | ||
| city match | ||
| case c @ City(name = "London") => println(p.population) | ||
| case City(name = n, zip = 1026, population = pop) => println(pop) |
There was a problem hiding this comment.
Should we require a trailing * e.g. case City(name = "London", *) => to make it clear that we are only matching a subset of fields?
Is there some way to do named-pattern-matching against zero fields? This is different from case c: City because it's unapply based rather than isInstanceOf-based, and is more convenient than writing case City(_, _, _) => which is the status quo
There was a problem hiding this comment.
Is there some way to do named-pattern-matching against zero fields? This is different from
case c: Citybecause it'sunapplybased rather thanisInstanceOf-based, and is more convenient than writingcase City(_, _, _) =>which is the status quo
I also think that case City(*) is useful and would opt for that kind of syntax almost always than _ : City. This can be a different SIP, unless we require that indeed we need a trailing * if not all fields are specified.
There was a problem hiding this comment.
I am not fond of explicit * here. The situation for me is analogous to named function arguments. We don't use * there either to make clear that we have given all names and it's OK to use defaults for the rest. For pattern matching, the default is simply _, i.e. wildcard and no binding.
Also, I think almost all named pattern matches will be partial. That's the whole point. If I have a full match for e.g. Person, then I would likely write:
case Person(name, age)and not
case Person(name = name, age = age)So in that sense, the fact that it is a named pattern match also indicates that it is partial, and the * would just be annoying and redundant.
There was a problem hiding this comment.
Agreed. We should avoid reference to _1, _2 in the SIP. As far as I can see, that's the case currently.
| case (name, age) => ... | ||
|
|
||
| Bob match | ||
| case (name = x, age = y) => ... |
There was a problem hiding this comment.
Is something like this allowed?
case (name, age = y) =>Does named tuple pattern matching require fields be in the right order? The section on Pattern Matching with Named Fields in General mentions named pattern matching on case classes does not care about the order of fields, but it's not clear whether than applies to named tuples as well
Should it care about order? Elsewhere, we discuss how one of the defining characteristics of named tuples is that they are ordered. Given that, it seems strange that you can construct different named tuples that are not equivalent to each other e.g. (name: String, age: Int) and (age: Int, name: String), but match the same pattern case (name = x, age = y) => because pattern matching ordering does not consider ordering
There was a problem hiding this comment.
case (name, age = y) is currently not allowed. Named fields do not need to be in the right order.
Not caring about order comes from the named pattern matching part, and behaves the same for case classes and named tuples. So order matters for construction but not for named deconstruction.
| We propose to add new form of tuples where the elements are named. | ||
| Named tuples can be types, terms, or patterns. Syntax examples: | ||
| ```scala | ||
| type Person = (name: String, age: Int) |
There was a problem hiding this comment.
What happens if someone writes the following:
type Person = (name: String, name: String)Is this a syntax error, type error, or something else? The runtime implementation of (String, String) doesn't care about names, but then when someone calls .name the compiler cannot know which tuple entry it is referring to
There was a problem hiding this comment.
It's a type error. It's listed in the Restrictions section of the SIP.
| object NamedTuple: | ||
|
|
||
| opaque type AnyNamedTuple = Any | ||
| opaque type NamedTuple[N <: Tuple, +V <: Tuple] >: V <: AnyNamedTuple = V |
There was a problem hiding this comment.
I probably need help from someone else to review this part; this sort of more advanced type-level computation is beyond my expertise
There was a problem hiding this comment.
As an appendix, it would not need to be reviewed in depth. It just gives additional info that an implementation of NamedTuple with a useful API is possible. It's premature to freeze that API, so I believe the NamedTuple API itself should not be part of the SIP, except for things that are explicitly mentioned (like the NamedTuple and From types).
| - All tuple operations also work with named tuples "out of the box". | ||
| - Macro libraries can rely on this expansion. | ||
|
|
||
| ### Computed Field Names |
There was a problem hiding this comment.
I like this feature since it makes Selectable a lot nicer to use. Combined with NamedTuple.From, it makes it possible to create powerful proxy types like the Expr example in the appendix.
However, there's something a bit odd about using NamedTuple (where the order of the elements matters) to define the members of a Selectable (where there is no ordering). This is fine as long as we can construct a NamedTuple that contains the members we'd like to select on, but if we rely on NamedTuple.From we're limited to the parameters of case classes and tuples because they have a notion of ordering but other types don't.
To lift this limitation, I think it'd be useful to define another magic operator to construct a NamedTuple from the public fields of a class or trait, the elements of the generated NamedTuple should be sorted alphabetically so that reordering vals in a class would keep being a source and binary compatible change:
trait Base:
val y: Int = 3
class Foo extends Base:
val z: Int = 1
val x: Int = 2
NamedTuple.FieldsOf[Foo] =:= (x: Int, y: Int, z: Int)There was a problem hiding this comment.
To lift this limitation, I think it'd be useful to define another magic operator to construct a NamedTuple from the public fields of a class or trait
If we add this, I don't see why NamedTuple.From cannot be used for both. Or at least a more clear name that will highlight the difference (FieldsOf does not).
|
@kyouko-taiga I changed the stage label to stage:implementation - as that is required by our state transition diagram (and the script that generates the sips website): |
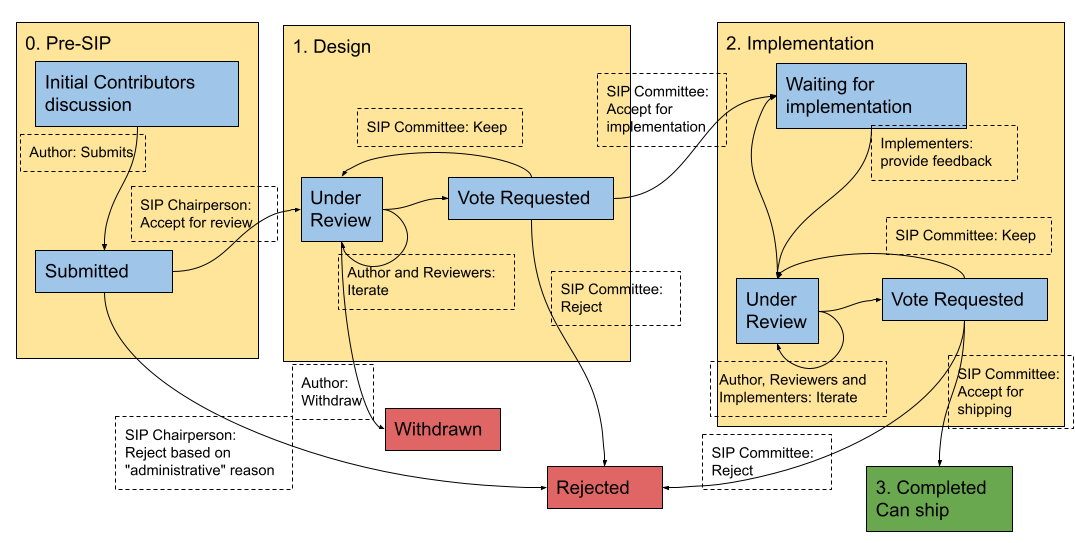
|
A few points raised at the last SIP meeting:
|
|
Disallow some opaque type aliases in match type patterns #20913 |
Does that mean that the design has been accepted by the SIP Committee? If that’s the case, it would be good to merge the PR so that the proposal gets its own page like e.g. https://docs.scala-lang.org/sips/polymorphic-eta-expansion.html. |
Only as experimental. Not final yet. |
|
@lihaoyi can we vote to accept this tomorrow? |
|
Sure let's vote |
|
It would be good if the recommendations of each assignee could be stated here prior to the vote. |
|
I agree. Could the assignees update the agenda? |
|
I recommend YES to accept. |
|
I recommend accepting this proposal |
This is the promised SIP for named tuples