Second work proposed for the subject of Natural Language Processing that consists of making a system that detects the languages of the text given.
Wiki in spanish and Video.
System must support at least 10 languages. Languages must have differences between them. It is advisable to use the corpus Europarl. As minimum system must support Spanish, Italian, French, Portuguese and English.
System must differentiate between train process and evaluation process. For each language, needed at least a corpus with a million of words for training, and about 100.000 words for evaluating.
Systen should not require training for each use.
For evaluating, needs to split evaluating corpus in 1-20 words groups randomly.
Finally, system must calculate percentage of hits and erros. And, it is important that system builds a confusing matrix with 2 dimensions for all languages combinations.
This project has target of supporting following 10 lenguages: english, spanish, french, italian, protuguese, german, greek, danish, netherlander and finnish. But, it supports other languages.
Visual scheme:
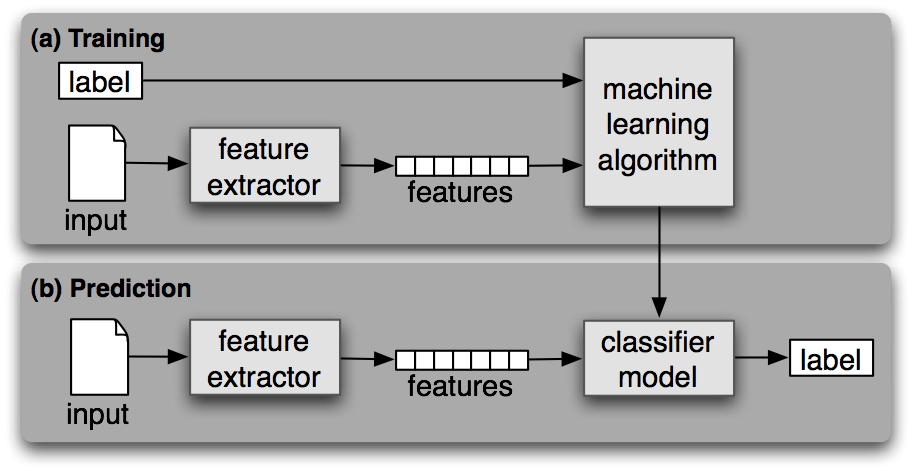
At first, we have to install all packages:
$ pip3 install -r requirements.txt
And, we need to download nltk files:
$ python
>>> import nltk()
>>> nltk.download()
Note that we must have installed Pip, Pip3, Python and Python3.
Previously, we need to have Europarl files in ./europarl_raw. The link is in top of train.py as comment.
Therefore, we need to download wikipedia articles to classification. For that:
$ python3 wikicorpus.py topics.json
Wikipedia script is described in following link.
Now, we are going to run train.py using europarl_raw/ as given below:
$ python3 train.py languages.txt europarl_raw
Finally, we have to run classify.py script to evaluate. Needed model.pickle in same directory:
$ python3 classify.py model.pickle languages.txt ./wikipedia/
Example of output (_classify.py for running with a sentence):
$ python3 _classify.py model.pickle "This is an example."
>>> This is an example. english
Example of output:
| p |
| o |
| r |
| s e t i f s |
| f p n u t g i w d |
| r a g g a e d n e a g |
| e n l u l r u n d n r |
| n i i e i m t i i i e |
| c s s s a a c s s s e |
| h h h e n n h h h h k |
-----------+------------------------------------------------------------------------------+
french | <14.7%> 0.5% 0.3% 0.5% 0.1% 0.2% 0.1% 0.3% 0.3% 0.1% 25.0% |
spanish | 0.3% <12.0%> 0.1% 0.4% 0.1% 0.0% 0.1% 0.0% 0.0% 0.0% 0.0% |
english | 0.5% 0.2% <8.0%> 0.1% 0.1% 0.1% 0.1% 0.1% 0.1% 0.0% 0.7% |
portuguese | 0.1% 0.3% 0.0% <6.8%> 0.0% 0.0% 0.0% 0.0% 0.0% 0.0% 0.1% |
italian | 0.3% 0.2% 0.0% 0.1% <6.4%> 0.0% 0.0% 0.0% 0.0% 0.0% 0.0% |
german | 0.1% 0.0% 0.0% 0.0% 0.0% <6.5%> 0.0% 0.0% 0.0% 0.0% 0.0% |
dutch | 0.2% 0.1% 0.0% 0.1% 0.0% 0.0% <4.0%> 0.0% 0.0% 0.0% 0.0% |
finnish | 0.0% 0.0% 0.0% 0.0% 0.0% 0.0% 0.0% <3.4%> 0.0% 0.0% 0.0% |
swedish | 0.0% 0.0% 0.0% 0.0% 0.0% 0.0% 0.0% 0.0% <3.2%> 0.0% 0.0% |
danish | 0.1% 0.1% 0.1% 0.1% 0.0% 0.1% 0.0% 0.0% 0.2% <1.2%> 0.0% |
greek | . 0.0% 0.0% . . 0.0% . 0.0% 0.0% . <0.0%>|
-----------+------------------------------------------------------------------------------+
Here are some statistics for the full Europarl data:
- Danish : 37,448,363 words
- Dutch : 39,716,639 words
- English : 39,525,473 words
- Finnish : 26,371,785 words
- French : 43,185,127 words
- German : 37,544,028 words
- Greek : 3,377,416 words
- Italian : 38,706,361 words
- Portuguese: 40,186,811 words
- Spanish : 41,264,142 words
- Swedish : 33,314,195 words