• Input: TITLE
o Example: " Bitcoin exchange seeks U.S. bankruptcy protection"
• Output of classification algorithm: CATEGORY
o Example: Business
df = pd.read_csv('headlines.csv')
df = df[['CATEGORY','TITLE']]
df = df[pd.notnull(df['TITLE'])]
df.columns = ['CATEGORY', 'TITLE']
df.TITLE = df.TITLE.apply(lambda x: x.lower())
df.TITLE = df.TITLE.apply(lambda x: x.translate(str.maketrans('', '', string.punctuation)))
df.TITLE = df.TITLE.apply(lambda x: x.translate(str.maketrans('', '', '1234567890')))
df['category_id'] = df['CATEGORY'].factorize()[0]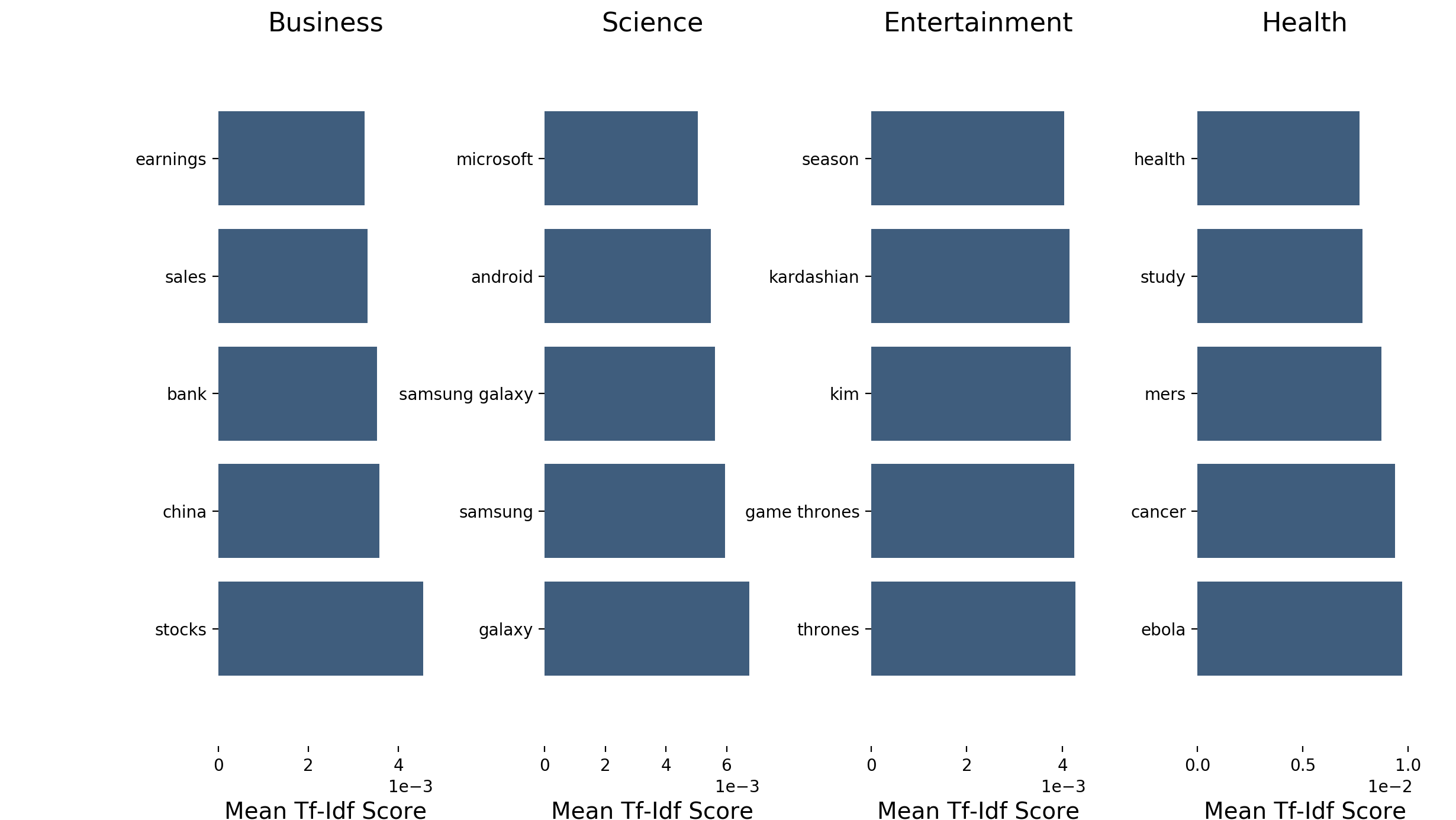
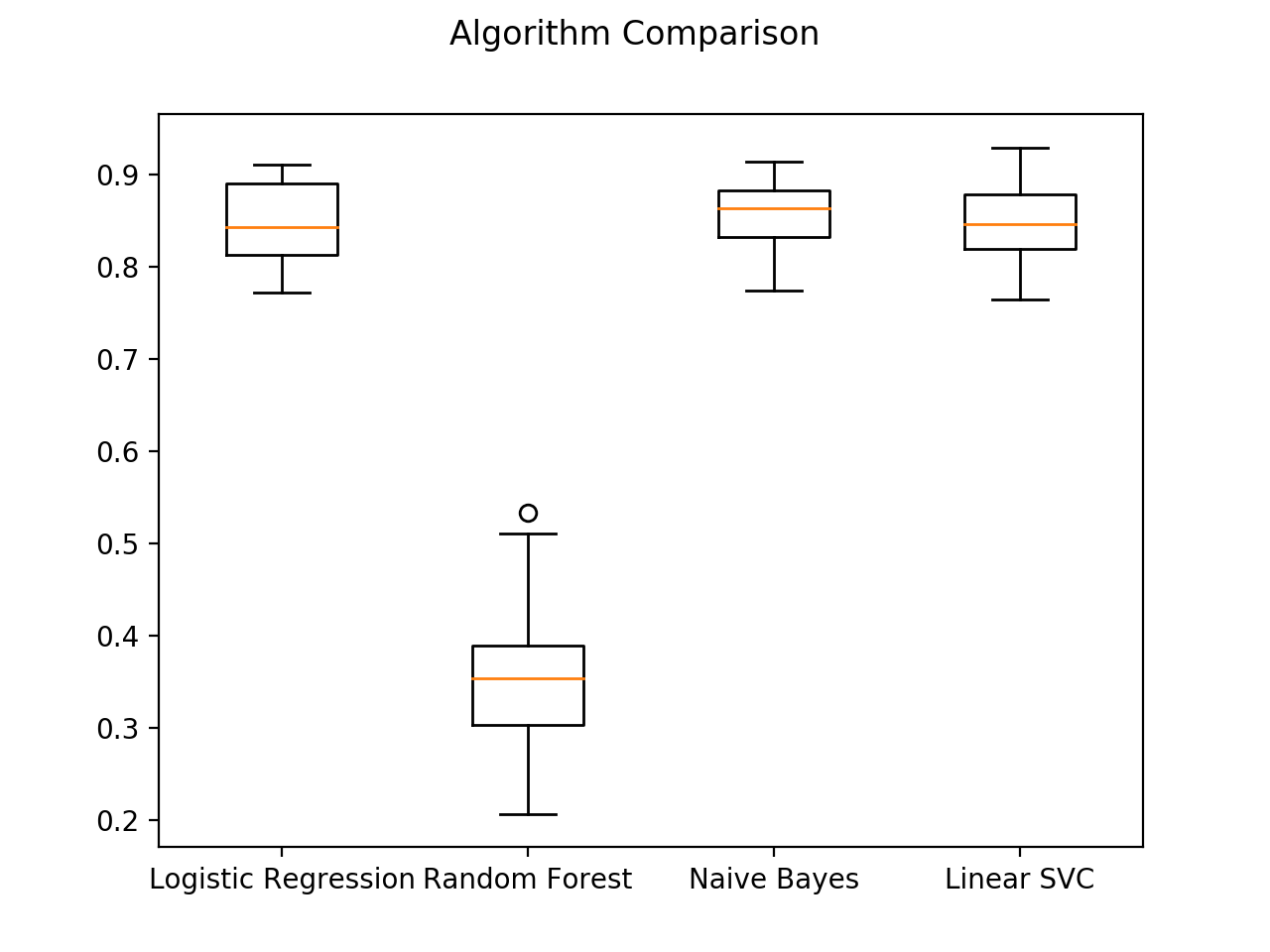
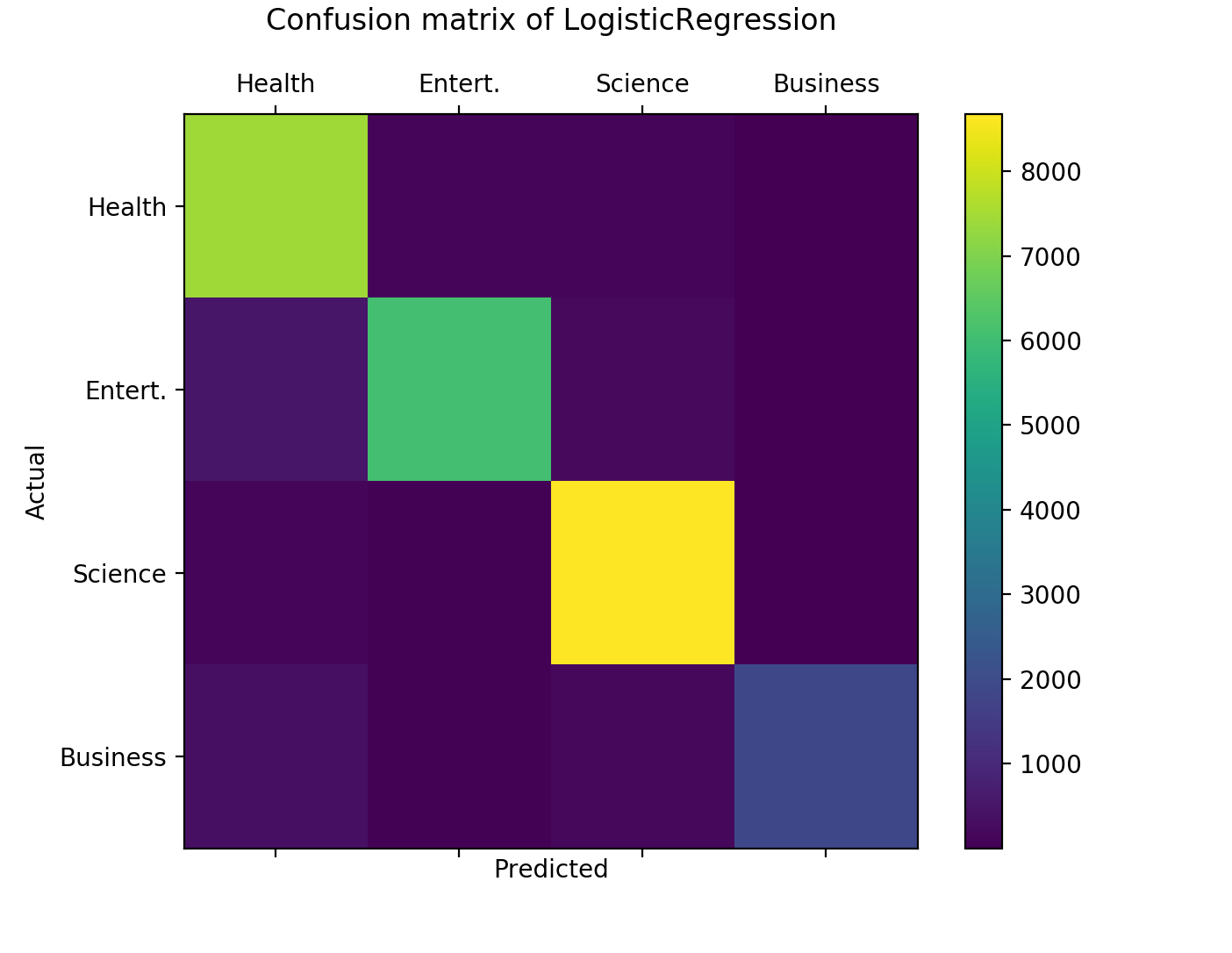
Logistic Regression: Mean Accuracy: 0.847214 Standard Deviation: 0.046154
Random Forest: Mean Accuracy: 0.361110 Standard Deviation: 0.098128
Naive Bayes: Mean Accuracy: 0.855489 Standard Deviation: 0.038743
Linear SVC: Mean Accuracy: 0.849241 Standard Deviation: 0.045773
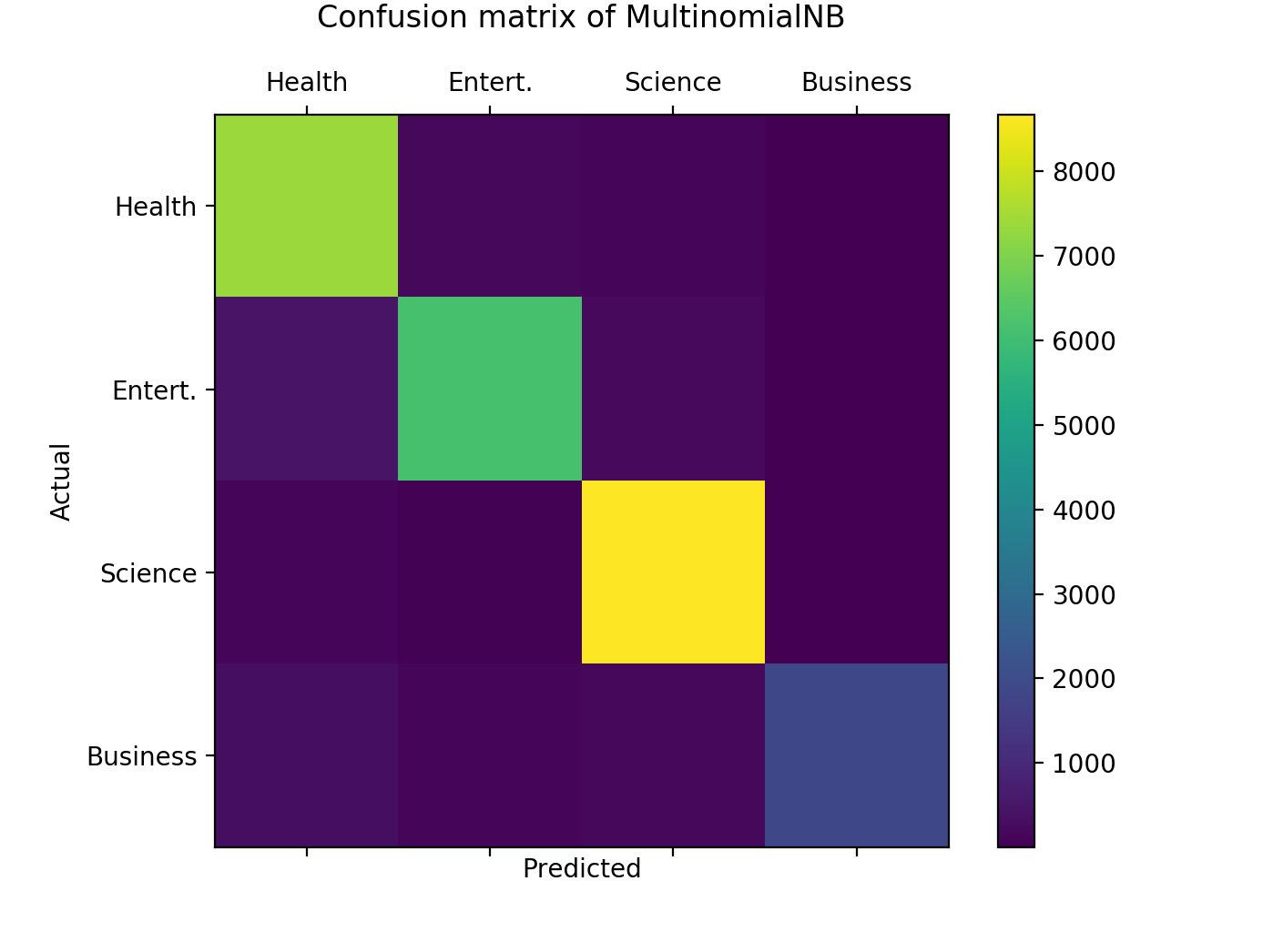
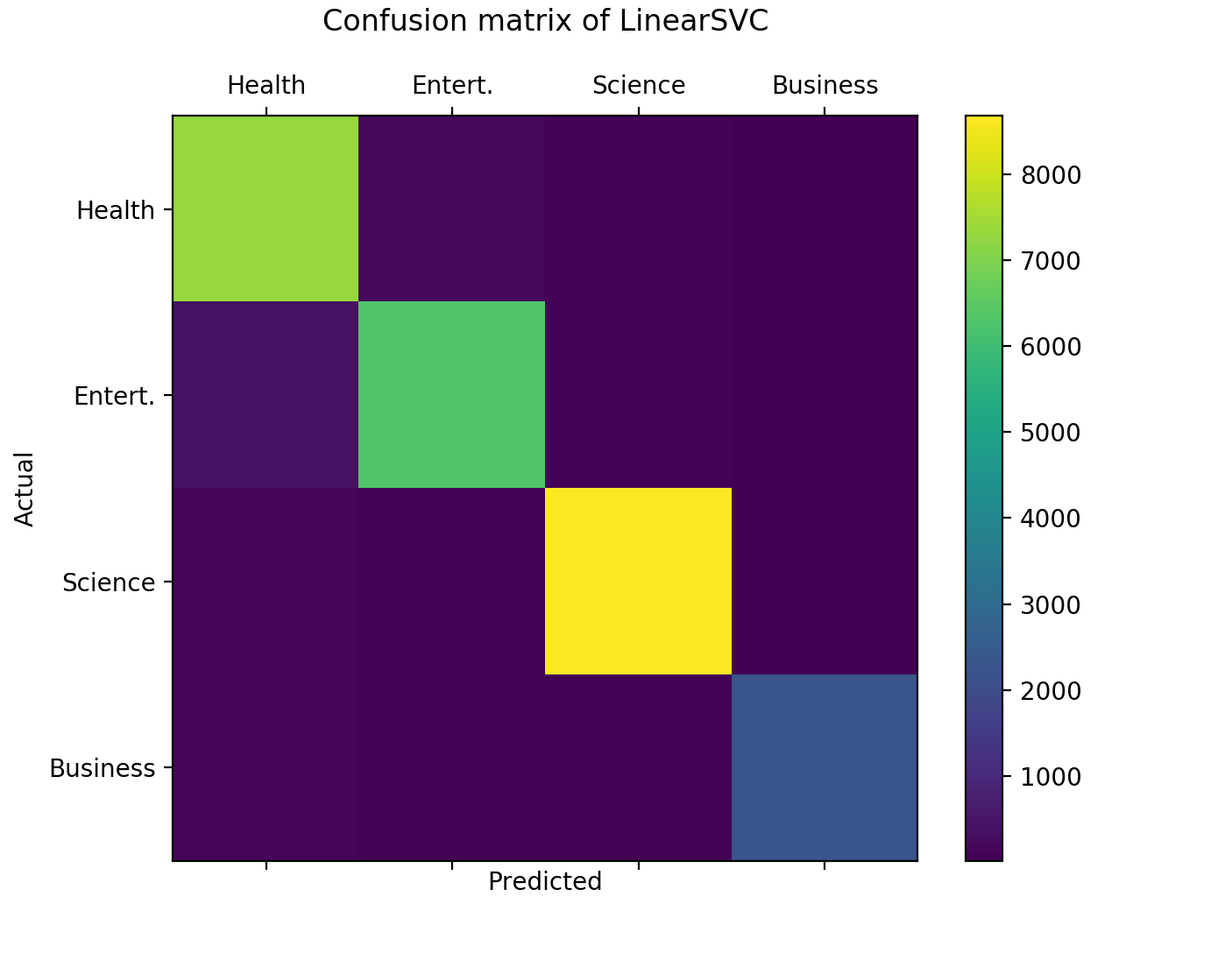

References:
https://towardsdatascience.com/a-production-ready-multi-class-text-classifier-96490408757 https://buhrmann.github.io/tfidf-analysis.html