tutorial modelling
In this tutorial you will learn how to train 3D object models. You will model objects by rotating them in front of an RGB-D camera. These objects can then be recognised by a recognition component via a ROS service call, or tracked by another component.
- openni drivers:
sudo apt-get install libopenni-dev libopenni-sensor-primesense0 - Qt 4 (http://qt-project.org/):
sudo apt-get install libqt4-dev - Boost (http://www.boost.org/): comes with ubuntu
- Point Cloud Library 1.7.x (http://pointclouds.org/): comes with ROS
- Eigen3 (http://eigen.tuxfamily.org/):
sudo apt-get install libeigen3-dev - OpenCV 2.x (http://opencv.org/): comes with ROS
- Ceres Solver 1.9.0 (http://ceres-solver.org/):
sudo apt-get install libceres-dev - OpenGL GLSL mathematics (libglm-dev):
sudo apt-get install libglm-dev - GLEW - The OpenGL Extension Wrangler Library (libglew-dev):
sudo apt-get install libglew-dev - libraries for sparse matrices computations (libsuitesparse-dev):
sudo apt-get install libsuitesparse-dev
First you have to model all the objects you want to recognise later. You use an offline tool for this, the RTM Toolbox.
- Place the object on a flat surface on a newspaper or something similar. This allows you to rotate the object without touching it. The texture on the newspaper also helps view registration. The pictures below were taken with the object on a turn table, which is the most convenient way of rotating the object.
- Start the modelling tool: ...squirrel_ws/devel/bin/RTMT
- Press "Camera Start": You should now see the camera image

- Press "ROI Set" + click on the flat surface next to the object

- Press Tracker Start: you now see the tracking quality bar top left

- Rotate 360 degrees, the program will generate a number of keyframes.
IMPORTANT: Do not touch the object itself while moving it.


- Press "Tracker Stop"
- Press "Camera Stop"
- Press "Pose Optimize" (optional): bundle adjustment of all cameras (be patient!)
- Press "Object Segment": The object should already be segmented correctly thanks to the ROI set previously
 You can check segmentation (< > buttons), and you can click to wrong segmentations (undo) or add areas.
You can check segmentation (< > buttons), and you can click to wrong segmentations (undo) or add areas. - Press "Object ...Ok"
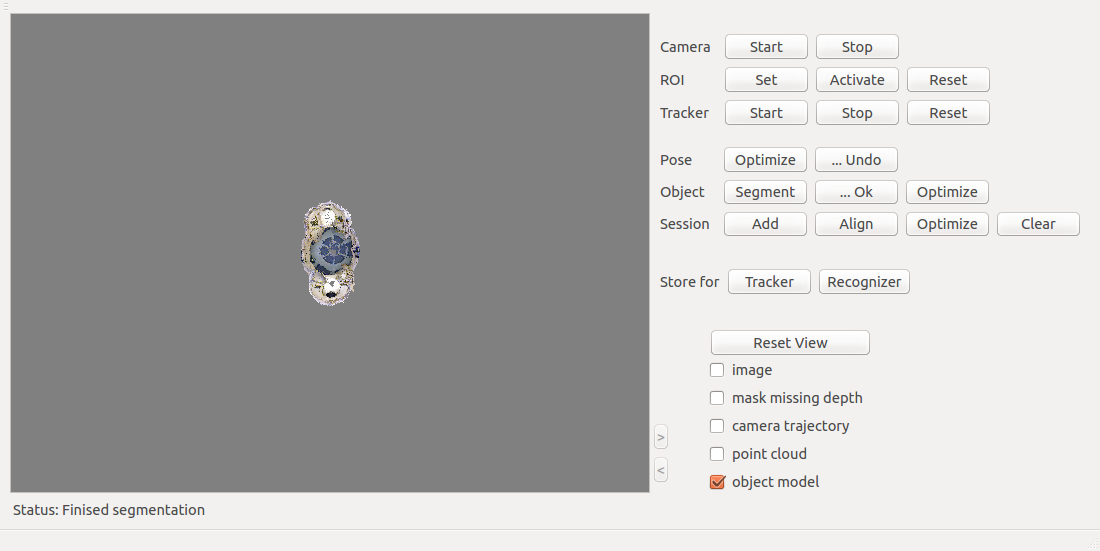

- Press "Store for Recognizer": saves the point clouds in a format for object recognition. You will be asked for an model name.
By default the program will store models in various subfolders of the folder "./data", which will be created if not present. This can be changed in the configuration options (see below). - Press "Store for Tracker": save a different model suitable for tracking
- If the 3D point cloud visualization is activated +/- can be used to increase/ decrease the size of dots
This is a convenient way to model objects with a typical robot. Put the objects on something elevated (a trash can in this case) to bring it within a good distance to the robot's head camera.

- Set data folder and model name:
(File -> Preferences -> Settings -> Path and model name) - Configure number of keyfames to be selected using a camera rotation and a camera translation threshold:
(File -> Preferences -> Settings -> Min. delta angle, Min. delta camera distance)
- If you press any of the buttons in the wrong order, just restart. Recovery is futile.
- If you do not get an image, there is a problem with the OpenNI device driver.
Check the file
/etc/openni/GlobalDefaults.ini, setUsbInterface=2(i.e. BULK).
When referencing this work, pleace cite:
-
J. Prankl, A. Aldoma Buchaca, A. Svejda, M. Vincze, RGB-D Object Modelling for Object Recognition and Tracking. IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), 2015.
-
Thomas Fäulhammer, Aitor Aldoma, Michael Zillich and Markus Vincze Temporal Integration of Feature Correspondences For Enhanced Recognition in Cluttered And Dynamic Environments IEEE International Conference on Robotics and Automation (ICRA), Seattle, WA, USA, 2015.
-
Thomas Fäulhammer, Michael Zillich and Markus Vincze Multi-View Hypotheses Transfer for Enhanced Object Recognition in Clutter, IAPR International Conference on Machine Vision Applications (MVA), Tokyo, Japan, 2015.
-
A. Aldoma Buchaca, F. Tombari, J. Prankl, A. Richtsfeld, L. di Stefano, M. Vincze, Multimodal Cue Integration through Hypotheses Verification for RGB-D Object Recognition and 6DOF Pose Estimation. IEEE International Conference on Robotics and Automation (ICRA), 2013.
-
J. Prankl, T. Mörwald, M. Zillich, M. Vincze, Probabilistic Cue Integration for Real-time Object Pose Tracking. Proc. International Conference on Computer Vision Systems (ICVS). 2013.
For further information check out this site.