看到这个题目就使用了搜索引擎搜了一下,大部分是使用 jieba + gensim 的方式, 研究了好几天没有搞懂,后来看了 基于 TF-IDF、余弦相似度算法实现文本相似度算法的 Python 应用 才知道可以不用 gensim 库。
具体步骤如下
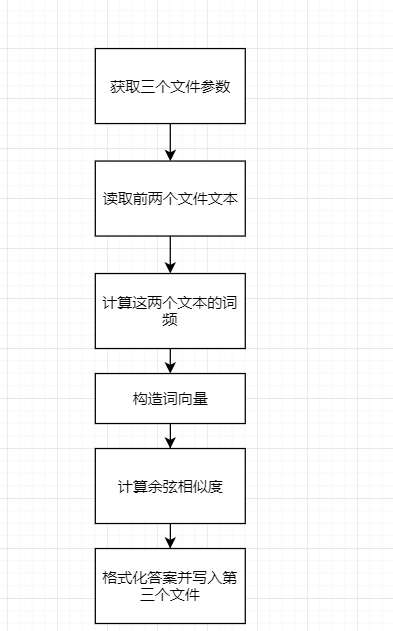
搞懂了之后就比较简单了,打出代码
import os
from typing import List, Dict
import jieba.analyse
import numpy as np
import sys
# 计算主过程
def get_similarity(source_path: str, copy_path: str) -> float:
source_content = read_file(source_path)
copy_content = read_file(copy_path)
source_tfidf_dict = get_tfidf_dict(source_content)
copy_tfidf_dict = get_tfidf_dict(copy_content)
[source_tfidf_list, copy_tfidf_list] = get_tfidf_list(
source_tfidf_dict, copy_tfidf_dict)
return calculate_similarity(source_tfidf_list, copy_tfidf_list)
# 读取文件返回两个文件地址
def read_file(path: str) -> str:
if not os.path.exists(path):
raise ValueError('文件不存在')
with open(path, 'r', encoding='utf-8') as f:
content = f.read()
return content
# 获取一个文本的 tfidf dict
def get_tfidf_dict(content: str) -> Dict[str, float]:
tfidf_dict = {}
for word, tfidf in jieba.analyse.extract_tags(content, topK=0, withWeight=True):
tfidf_dict[word] = tfidf
if len(tfidf_dict) == 0:
raise ValueError('无效文本')
return tfidf_dict
# 获取两个 tfidf dict 的 list
def get_tfidf_list(source_tfidf_dict: Dict[str, float], copy_tfidf_dict: Dict[str, float]) -> List[List[float]]:
source_tfidf_list = []
copy_tfidf_list = []
for item in source_tfidf_dict:
source_tfidf_list.append(source_tfidf_dict[item])
copy_tfidf_list.append(
copy_tfidf_dict[item] if item in copy_tfidf_dict else 0)
for item in copy_tfidf_dict:
if item not in source_tfidf_dict:
source_tfidf_list.append(0)
copy_tfidf_list.append(copy_tfidf_dict[item])
return [source_tfidf_list, copy_tfidf_list]
# 计算结果
def calculate_similarity(source_tfidf_list: List[float], copy_tfidf_list: List[float]) -> float:
source_tfidf_array = np.array(source_tfidf_list)
copy_tfidf_array = np.array(copy_tfidf_list)
return np.dot(source_tfidf_array, copy_tfidf_array, out=None) / (
np.linalg.norm(source_tfidf_array) * np.linalg.norm(copy_tfidf_array))
# 写入文件
def write_consequence_to_file(similarity: float, path: str):
if not os.path.exists(path):
raise ValueError('文件不存在')
with open(path, 'w', encoding='utf-8') as f:
f.write(str(round(similarity, 2)))
def main():
if len(sys.argv) < 4:
raise ValueError('参数缺失')
[source_path, copy_path, ans_path] = sys.argv[1:]
similarity = get_similarity(source_path, copy_path)
write_consequence_to_file(similarity, ans_path)
if __name__ == '__main__':
main()在 main 函数里使用 sys 获取三个文件 ,然后进入 get_similarity 函数,通过 read_file 函数获取前两个文件的内容。
然后进入 get_tfidf_dict 获取他们的词频,再在 get_tfidf_list 获取 词频的有序列表,最后使用 calculate_similarity 获取余弦相似度。
最后用 write_consequence_to_file 把答案写入文件
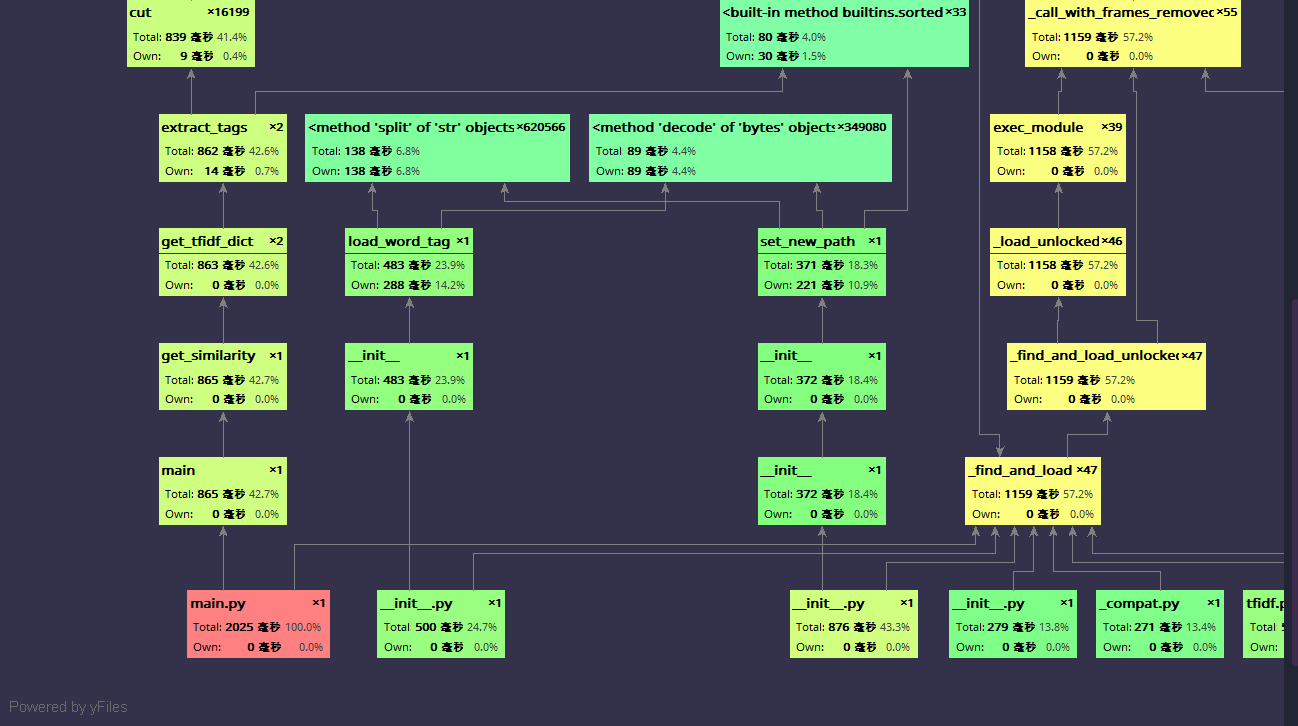
用 pycharm 自带的 profile (pycharm 永远滴神)分析了性能,生成了以下图片。
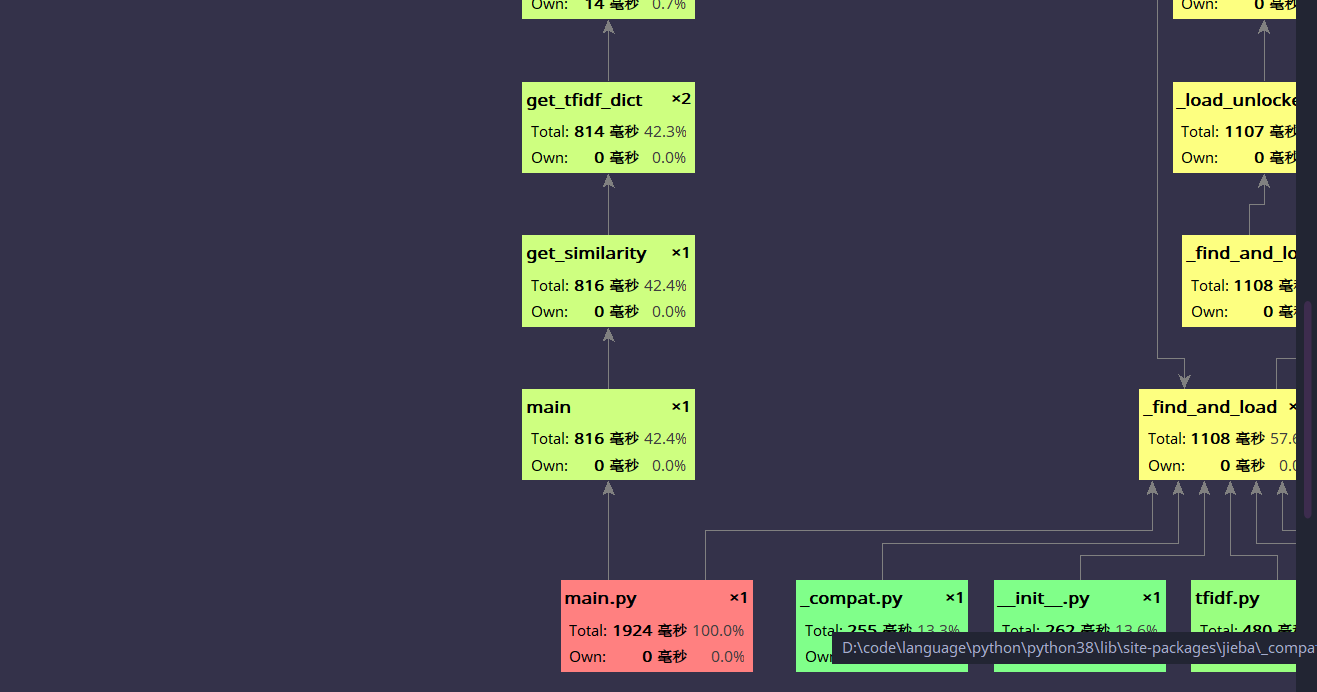
可以看出这个性能还不错,2000ms 左右就能完成,main 函数也没有占用太多的性能,主要是 python 导包的性能确实,main 函数内部主要是 get_tfidf_dict 耗费了太多资源,我就想到了使用 pandas 这个包来计算词频。
# 获取一个文本的 tfidf dict
def get_tfidf_dict(content: str) -> Dict[str, float]:
# tfidf_dict = {}
# for word, tfidf in jieba.analyse.extract_tags(content, topK=0, withWeight=True):
# tfidf_dict[word] = tfidf
# return tfidf_dict
data = pd.Series(jieba.cut(content))
return dict(data.value_counts())把 get_tfidf_dict 改成这样,再使用 profile 发现性能没有差别,所以这个应该是 jieba 分词的时间消耗,难以优化,考虑这样性能就可以了,我就没有继续优化。
单元测试代码
import os
import main
def test():
copy_paths = './copy'
origin_path = './origin.txt'
for path in os.listdir(copy_paths):
print(f'{path}:', main.get_similarity(f'{copy_paths}/{path}', origin_path))
# 参数缺失
res = os.system(f'python main.py {origin_path}')
print(res)
# 无效文本
res = os.system(f'python main.py {origin_path} ./empty.txt ./result.txt')
print(res)
# 文件不存在
res = os.system(f'python main.py ./2.txt ./empty.txt ./result.txt')
print(res)
if __name__ == '__main__':
test()结果如图
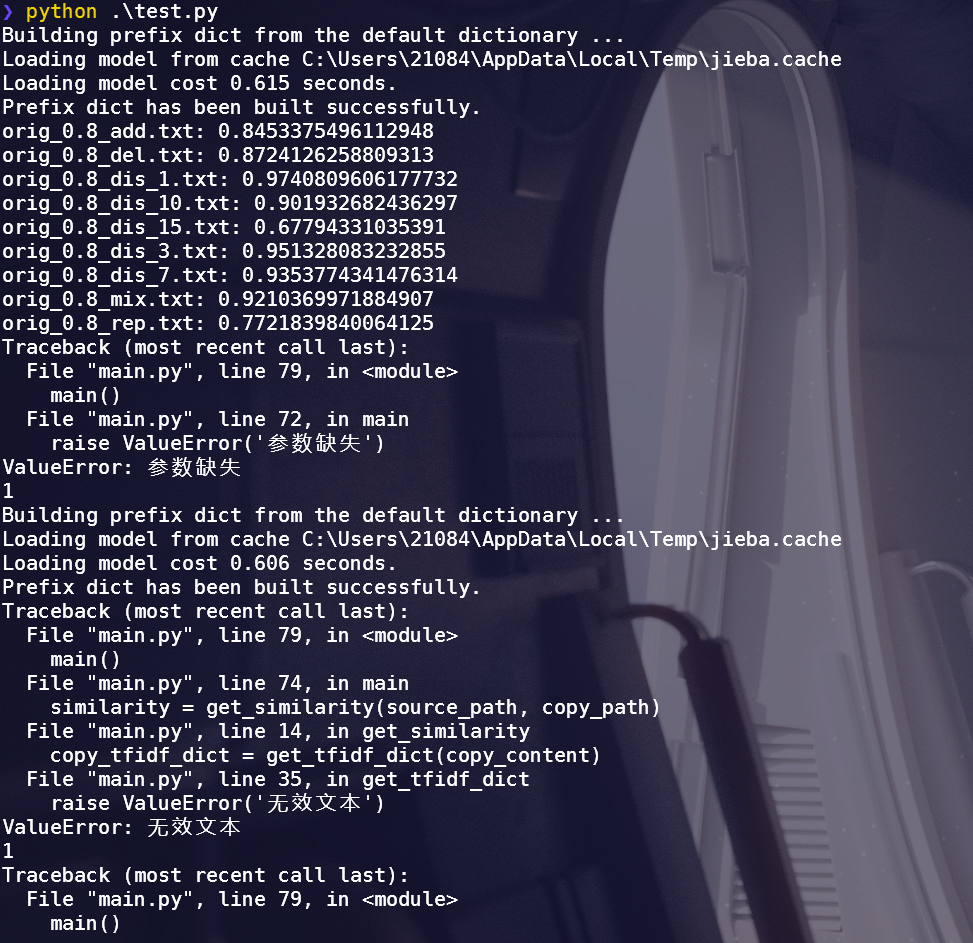

因为我没有多余数据,所以直接使用给的样例数据测试,结果大致再范围内。
我想到了有三种错误
-
参数缺失
if len(sys.argv) < 4: raise ValueError('参数缺失')
-
文件不存在
if not os.path.exists(path): raise ValueError('文件不存在')
-
无效文本
if len(tfidf_dict) == 0: raise ValueError('无效文本')
测试样例在 计算模块部分单元测试展示 有展示
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 20 | 30 |
| Estimate | 估计这个任务需要多少时间 | 10 | 10 |
| Development | 开发 | 60 | 70 |
| Analysis | 需求分析 (包括学习新技术) | 120 | 150 |
| Design Spec | 生成设计文档 | 120 | 110 |
| Design Review | 设计复审 | 30 | 20 |
| Coding Standard | 代码规范 (为目前的开发制定合适的规范) | 20 | 10 |
| Design | 具体设计 | 20 | 20 |
| Coding | 具体编码 | 50 | 45 |
| Code Review | 代码复审 | 10 | 5 |
| Test | 测试(自我测试,修改代码,提交修改) | 50 | 30 |
| Reporting | 报告 | 100 | 100 |
| Test Repor | 测试报告 | 10 | 25 |
| Size Measurement | 计算工作量 | 10 | 10 |
| Postmortem & Process Improvement Plan | 事后总结, 并提出过程改进计划 | 5 | 5 |
| -- | 合计 | 635 | 645 |