-
Notifications
You must be signed in to change notification settings - Fork 29
Commit
This commit does not belong to any branch on this repository, and may belong to a fork outside of the repository.
- Loading branch information
Showing
18 changed files
with
347 additions
and
351 deletions.
There are no files selected for viewing
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| Original file line number | Diff line number | Diff line change |
|---|---|---|
| @@ -1,75 +1,66 @@ | ||
| --- | ||
| title: "How to create OCR Text Extraction Addon" | ||
| metadesc: "This article discusses how to create an addon for OCR text extraction for Testsigma app | OCR Text Extraction addon will help you to extract texts from images" | ||
| title: "Create OCR Text Extraction Addon" | ||
| page_title: "Create OCR Text Extraction Addon: Enhanced Test Automation" | ||
| metadesc: "Create OCR Text Extraction Addon seamlessly with our step-by-step guide. Extract text from pages, images, and elements effortlessly. Enhance your testing." | ||
| noindex: false | ||
| order: 17.81 | ||
| page_id: "Create a OCR Text Extraction Addon in Testsigma" | ||
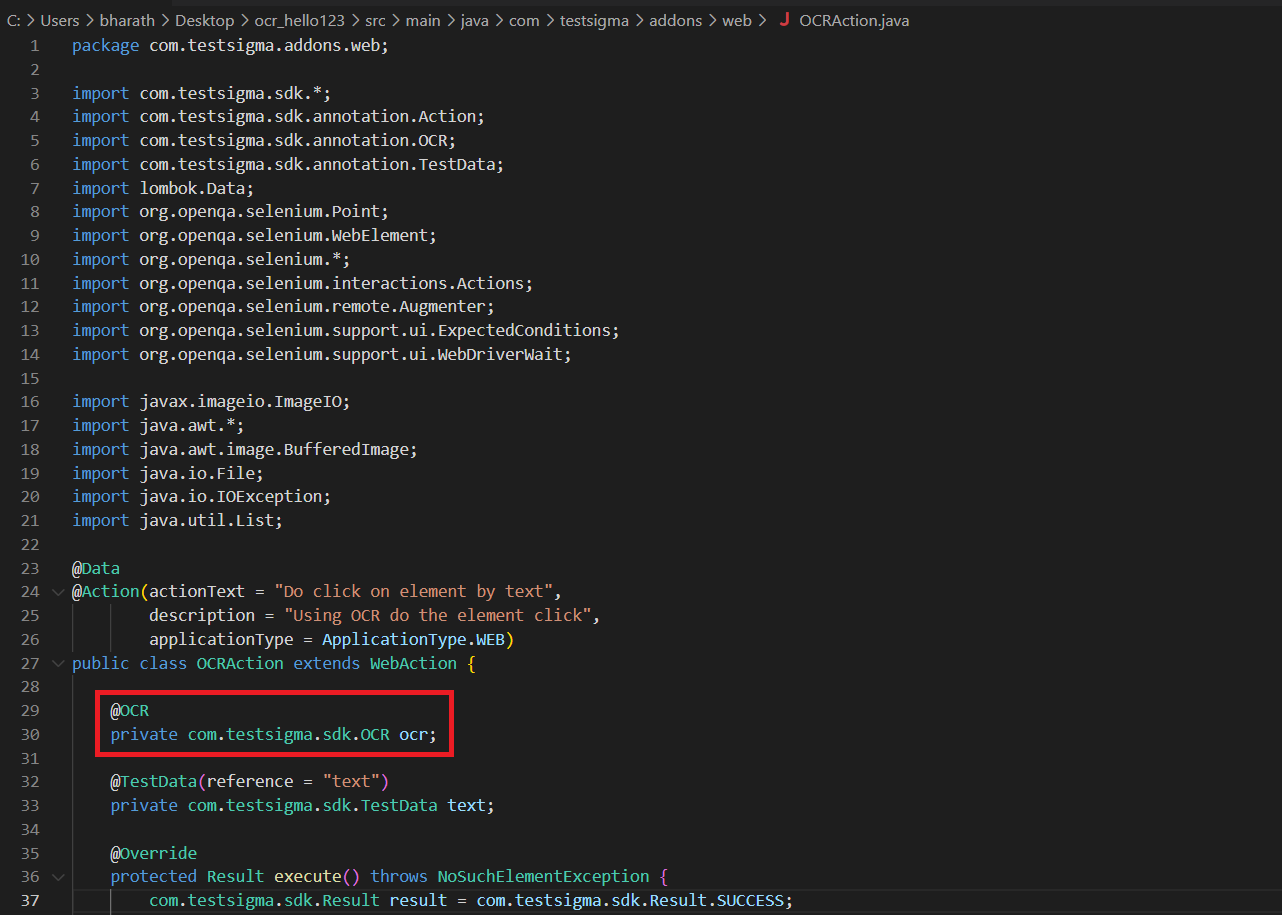
| warning: false | ||
| contextual_links: | ||
| - type: section | ||
| name: "Contents" | ||
| - type: link | ||
| name: "Prerequisites" | ||
| url: "#prerequisites" | ||
| - type: link | ||
| name: "Update the Action Code" | ||
| url: "#update-the-action-code" | ||
| - type: link | ||
| name: "Overview of the method to extract text" | ||
| url: "#overview-of-the-method-to-extract-text" | ||
| name: "OCR Code Update" | ||
| url: "#ocr-code-update" | ||
| - type: link | ||
| name: "Using OCR Addon in a Test case" | ||
| url: "#using-ocr-addon-in-a-test-case" | ||
| --- | ||
|
|
||
|
|
||
| --- | ||
|
|
||
| In this article, we will discuss how to create an addon for OCR text extraction. The creation part for the addon is similar except we set a class that implements the OCR interface. | ||
| This guide will instruct you step-by-step on how to create an OCR Text Extraction Addon for Testsigma. You should set up a class that implements the OCR interface, update the action code, and use the addon in test cases. | ||
|
|
||
| --- | ||
|
|
||
| ## **Prerequisites** | ||
|
|
||
| - To know about the prerequisites for addons, refer to [prerequisites for creating an add-on](https://testsigma.com/docs/addons/pre-requisite-to-create-addon/). | ||
|
|
||
| - To know how to create an addon, refer to [create a Testsigma addon](https://testsigma.com/docs/addons/create/). | ||
| Before creating the OCR Text Extraction addon, ensure you have met the prerequisites for addon development. For more information, refer to the [Creating an Addon](https://testsigma.com/docs/addons/create/). | ||
|
|
||
| --- | ||
|
|
||
| ## **Update the Action Code** | ||
|
|
||
| 1. Unzip the downloaded zip file and open the extracted folder in your favorite IDE as a Java module. This Java module contain the following template files which need to be updated: | ||
|  | ||
|
|
||
| - **pom.xml:** Contains all your dependencies needed to code your functionality. | ||
|
|
||
| - **src folder:** Sample source java files with sample add-on functions. | ||
|
|
||
|
|
||
| 2. From your IDE, import the downloaded Java module as Maven/Gradle. | ||
|
|
||
|
|
||
| 3. The Template Java module contains all necessary dependencies required to develop an Addon. For OCR Text Extraction action, you can add the following to pom.xml. | ||
| 1. Unzip the downloaded zip file and open the extracted folder in your preferred IDE as a Java module.  | ||
| 2. Import the Java module as Maven/Gradle from your IDE. | ||
| 3. Update the following template files: | ||
| - **pom.xml**: Contains dependencies for coding your functionality. | ||
| - **src folder**: Includes sample Java files with addon functions. | ||
|  | ||
|
|
||
| --- | ||
|
|
||
| ## **Overview of the method to extract text** | ||
|
|
||
| - ***extractTextFromPage():*** This method will extract text from an entire page. | ||
|
|
||
| - ***extractTextFromImage(OCRImage image):*** This method will extract text from a specified OCRImage object. | ||
| ## **OCR Code Update** | ||
|
|
||
| - ***extractTextFromElement(Element element):*** This method will extract text from a specific Element object. | ||
| 1. In the pom.xml file, add the necessary dependencies for OCR Text Extraction. | ||
| 2. Update the following methods in the Java module: | ||
| - ***extractTextFromPage():*** Extracts text from an entire page. | ||
| - ***extractTextFromImage(OCRImage image):*** Extracts text from a specified OCRImage object. | ||
| - ***extractTextFromElement(Element element):*** Extracts text from a specific Element object. | ||
|
|
||
| [[info | **NOTE**:]] | ||
| | All three methods mentioned above will return a List of OCRTextPoint objects, which represent the location of the text within the source. | ||
| | All three methods return a List of OCRTextPoint objects, representing the text's location within the source. | ||
|
|
||
| --- | ||
|
|
||
|
|
||
| ## **Using OCR Addon in a Test case** | ||
|
|
||
| Once you publish the addon, the NLPs will be available in the application. Example NLP, 'Click on the ***Element*** by the text ***test-data***'. | ||
|
|
||
|
|
||
|
|
||
| Once the addon is published, NLPs become available in the application. Follow these GIF below to use the OCR addon in Test Cases:  | ||
|
|
||
| --- |
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
Oops, something went wrong.