A Tensorflow 2.0 port for the paper TabNet: Attentive Interpretable Tabular Learning, whose original codebase is available at https://github.com/google-research/google-research/blob/master/tabnet.
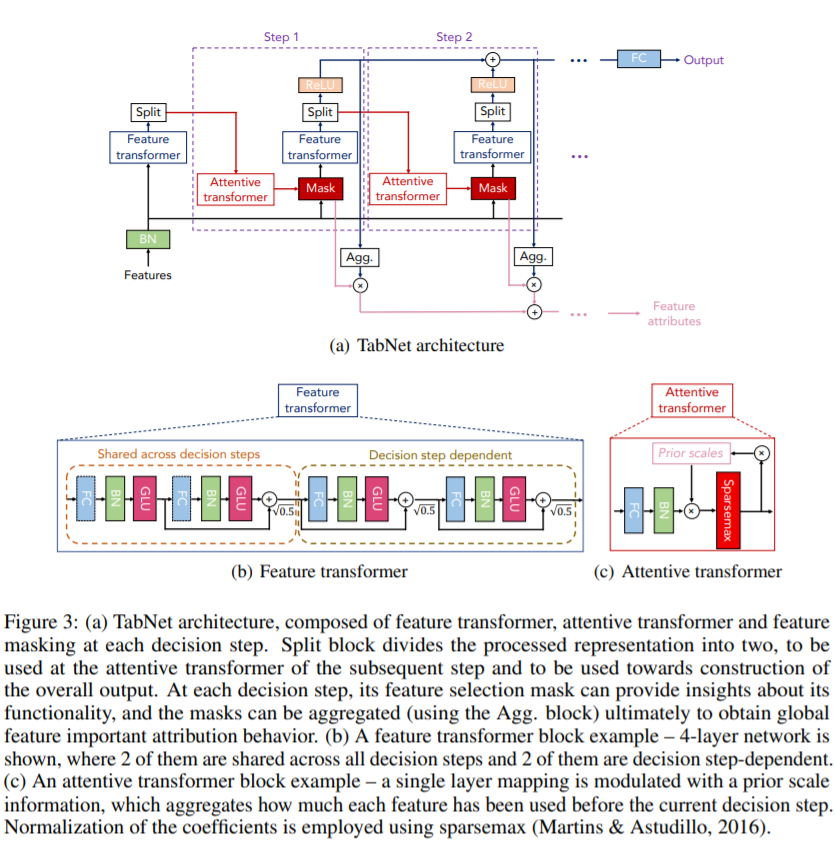
The above image is obtained from the paper, where the model is built of blocks in two stages - one to attend to the input features and anither to construct the output of the model.
There are two major differences from the paper and the official implementation.
-
This implementation offers a choice in the normalization method, between the regular
Batch Normalizationfrom the paper andGroup Normalization.- It has been observed that the paper uses very large batch sizes to stabilie Batch Normalization and obtain good generalization. An issue with this is computational cost.
- Therefore Group Normalization (with number of groups set as 1, aka Instance Normalization) offers a reasonable alternative which is independent of the batch size.
- One can set
num_groupsto 1 forInstance Normalizationtype behaviour, or to -1 forLayer Normalizationtype behaviour.
-
This implementation does not strictly need feature columns as input.
- While this model was originally developed for tabulur data, there is no hard requirement for that to be the only type of input it accepts.
- By passing
feature_columns=Noneand explicitly specifying the input dimensionality of the data (usingnum_features), we can get a semi-interpretable result from even image data (after flattening it into a long vector).
- For latest release branch
$ pip install --upgrade tabnet- For Master branch.
$ pip install git+https://github.com/titu1994/tf-TabNet.gitAs Tensorflow can be used with either a CPU or GPU, the package can be installed with the conditional requirements using [cpu] or [gpu] as follows.
$ pip install tabnet[cpu]
$ pip install tabnet[gpu]The script tabnet.py can be imported to yield either the TabNet building block, or the TabNetClassification and TabNetRegression models, which add appropriate heads for the basic TabNet model. If the classification or regression head is to be customized, it is recommended to compose a new model with the TabNet as the base of the model.
from tabnet import TabNet, TabNetClassifier
model = TabNetClassifier(feature_list, num_classes, ...)Regular TabNets can be stacked into various layers, thereby reducing interpretability but improving model capacity.
from tabnet import StackedTabNetClassifier
model = TabNetClassifier(feature_list, num_classes, num_layers, ...)As the models use custom objects, it is necessary to import custom_objects.py in an evaluation only script.
The masks of the TabNet can be obtained by using the TabNet class properties
feature_selection_masks: Returns a list of 1 or more masks at intermediate decision steps. Number of masks = number of decision steps - 1aggregate_feature_selection_mask: Returns a single tensor which is the average activation of the masks over that batch of training samples.
These masks can be obtained as TabNet.feature_selection_masks. Since the TabNetClassification and TabNetRegression models are composed of TabNet, the masks can be obtained as model.tabnet.*
Note: Due to autograph, the outputs of the model when using fit() or predict() Keras APIs will
generally be graph based Tensors, not EagerTensors. Since the masks are generated inside the Model.call() method,
it is necessary to force the model to behave in Eager execution mode, not in Graph mode.
Therefore there are two ways to force the model into eager mode:
- Get tensor data samples, and directly
callthe model using this data as below :
x, _ = next(iter(tf_dataset)) # Assuming it generates an (x, y) tuple.
_ = model(x) # This forces eager execution.- Or another choice is to build a seperate model (but here you will pass the
dynamic=Trueflag to the model constructor), load the weights and parameters in this model, and callmodel.predict(x). This should also force eager execution mode.
new_model = TabNetClassification(..., dynamic=True)
new_model.load_weights('path/to/weights)')
x, _ = next(iter(tf_dataset)) # Assuming it generates an (x, y) tuple.
model.predict(x)After the model has been forced into Eager Execution mode, the masks can be visualized in Tensorboard as follows -
writer = tf.summary.create_file_writer("logs/")
with writer.as_default():
for i, mask in enumerate(model.tabnet.feature_selection_masks):
print("Saving mask {} of shape {}".format(i + 1, mask.shape))
tf.summary.image('mask_at_iter_{}'.format(i + 1), step=0, data=mask, max_outputs=1)
writer.flush()
agg_mask = model.tabnet.aggregate_feature_selection_mask
print("Saving aggregate mask of shape", agg_mask.shape)
tf.summary.image("Aggregate Mask", step=0, data=agg_mask, max_outputs=1)
writer.flush()
writer.close()- Tensorflow 2.0+ (1.14+ with V2 compat enabled may be sufficient for 1.x)
- Tensorflow-datasets (Only required for evaluating
train_iris.py)