
The goal of this repo is to give a soft introduction to Machine Learning through examples and theory using Python. Our task is to predict wether a patient is positive or negative for breastcancer based on a set of 30 numerical feature variables, but the methodology is applicable to any problem of prediction where you wish to predict if a target is true or false based on one or more explanatory variables. If some your custom data comes in the form of groups, e.g. [French, German, Italian, German] you should first google encoding categorical data to change it into numerical input accepted by ML models. This particular problem is often referred to as Binary Classification since the outcome can only be one of two values.
We will be using the popular DS python packages scikit-learn for RandomForest/LogReg classifiers and Pytorch for our Neural Net. Miniconda is recommended but not necessary as it installs python automatically and keeps packages in separate environment per project.
The repo is a favor to a friend with a dataset and keen interest in ML but limited previous experience and is therefore likely best suited towards similar individuals with little to no background in ML or Python.
There is a fundamental difference between the traditional way of solving a system and the ML approach of learning a mapping between input and output. A known truth is that a feedforward network with a single layer is sufficient to represent any function, but what if our model learns a convoluted model that perfectly maps training data but fails to perform on new unseen data? Our model would merely be memorizing the training data without actually learning!
How well a model learns the underlying distribution from training data and translates that to new unseen data is referred to as a models generalization. To properly evaluate a model it is therefore common to set aside some data in a separate test set (and ideally a validation set for NN as the tuning of hyperparameters directly on the test set would introduce a bias). Common splits are roughly 80% Train / 20% Test (80% Train / 10% Val / 10% Test) which is done easily e.g. in scikit-learn sklearn.model_selection.train_test_split(args). We then consider both training and test accuracy and wish to:
- Make training error small
- Make the gap between training and test error small
The previous goals are connected to underfitting and overfitting, which respectively means that a model is not able to learn from the training set (low training accuracy) and that a model fits training data too perfectly without generalizing well to new data. This is controlled by regulating a models capacity. Capacity describes how a model is able to approximate various functions. Too low capacity means a model likely will not be able fit the training set, while too high leaves it prone to overfitting. More specifically, this explains why all problems aren't immediately targeted with the largest most advanced networks one could think of, as being allowed more functions possibly containing a better approximation doesn't guarantee the model will pick it. As a closing remark, the best performing ML algorithm will often be the one with a capacity close to the true complexity of the problem and adequate to the amount of available training data.
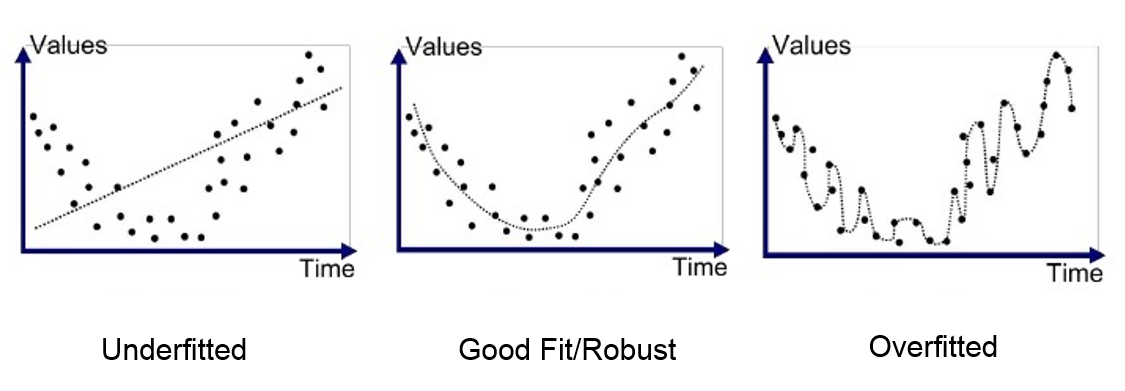
As a rule of thumb, if unable to obtain decent accuracy on the training data the model is not able to properly learn from the available data and more data is not needed. To remedy this, consider a more complex model (i.e. adding more width or depth for NN) until able to overfit on the training data. If however training accuracy is good but testing set accuracy abysmal more data is often beneficial. Finally, if complex models are not even able to learn the training data it is possible that the input needed to predict output is not there and new or higher quality data is needed.
For further reading, see
@Book{GoodBengCour16,
Title = {Deep Learning},
Author = {Ian J. Goodfellow and Yoshua Bengio and Aaron Courville},
Publisher = {MIT Press},
Year = {2016},
Address = {Cambridge, MA, USA},
Note = {\url{http://www.deeplearningbook.org}}
}
Open a new prompt (similar to cmd for conda) by:
pressing start button → searching Anaconda Prompt (miniconda3)
Create a new folder called git and navigate to it:
mkdir git
cd git
Clone this repo to your local git-folder by running:
git clone https://github.com/torjusn/intro_to_classification.git
Create a new conda environment called intro with python 3.10:
conda create --name intro python=3.10
Activate the environment
conda activate intro
Install packages from the requirements.txt file. (If you want to try installing packages on your own, google the package name and use pip install <package>):
pip install -r requirements.txt
Change directory to the classical methods subdirectory and run the main script:
cd classical_methods
python main.py
Check the conda cheatsheet for more help on conda.