Making predictions
You can make predictions about the sentiment of tweets in a file using SAIL. But before that you will have to satisfy the following prerequisites:
- Create an input folder with tab separated files containing the tweet text and other info.
- Let us assume that the tab separated file has the following 3 columns:
$ cat input/data.txt
text user followers
This is an amazing day zeroday 20013
This is bad weather funworks 543343
Obama for the win prezcrat 233After opening the executable, you will be presented by the following screen:
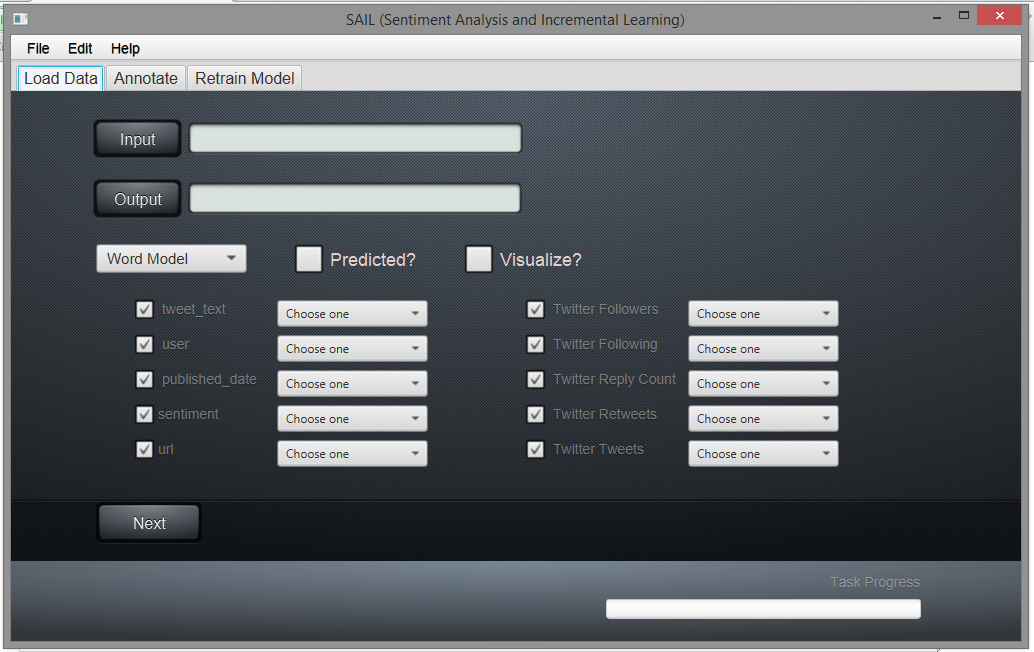
- Select the input folder and an output folder.
- Select the column labels from the respective drop downs options. (Make sure that the correct column containing the tweet text is required to be mapped to the tweet_text label)
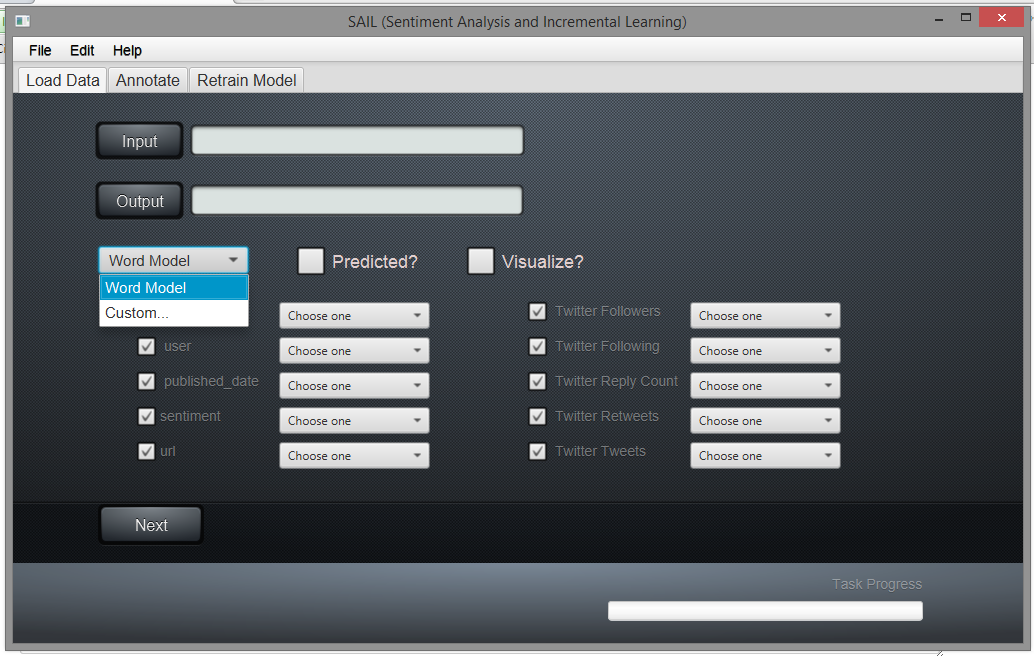
- You can either make prediction using a default model trained by us on SEMEVAL 2013 dataset or you can give a path to a model trained by you using steps in Train Model page.
The screen should look similar to the one below.
 The next page will show you the predictions like this:
The next page will show you the predictions like this:

If your input folder contains multiple files then predictions for each file can be seen by selecting the respective file from the drop down above.
The output folder has the following structure:
$ ls output
Features labled models original updatesEach folder is used for storing the various output files generated by SAIL.
- Features - Stores an intermediate representation of the input file having only the extracted features.
- labled - Stores only the tweets, features and their labels
- models - Stores an updated models trained using SAIL.
- original - Stores the output in the original input file format with the labels and features as extra columns.
- updates - Stores the updated labels by the user used for updating the model.